MySQL - 查询
MySQL - 查询
# 查询
# 1 外键
定义:外键就是从表中用来引用主表数据的那个字段
CREATE TABLE 表名 (
....,
CONSTRAINT 外键约束名
FOREIGN KEY (字段名) REFERENCES 主表名 (主表字段名)
)
ALTER TABLE 从表名 ADD CONSTRAINT 外键约束名 FOREIGN KEY (字段名) REFERENCES 主表名(主表字段名)
2
3
4
5
6
7
外键约束:确定了从表外键字段与主表主键字段的引用关系,确保从表数据所引用的主表数据不被非法删除,保证从表和主表间的数据一致性。
外键约束的缺点:需要消耗系统资源,不适用于高并发和分布式场景,在大并发的 SQL 操作时(如插入操作),可能因外键约束的系统开销而变得十分耗时,所以 MySQL 允许不使用字段的外键约束,而在系统应用层完成检查数据一致性的逻辑。
# 2 连接
- 内连接:查询结果只返回符合连接条件的结果,关键字如:JOIN、INNER JOIN、CROSS JOIN
- 外连接:查询结果返回某一张表的所有记录,并返回另一张表中符合连接条件的记录,关键字如:LEFT JOIN、RIGHT JOIN
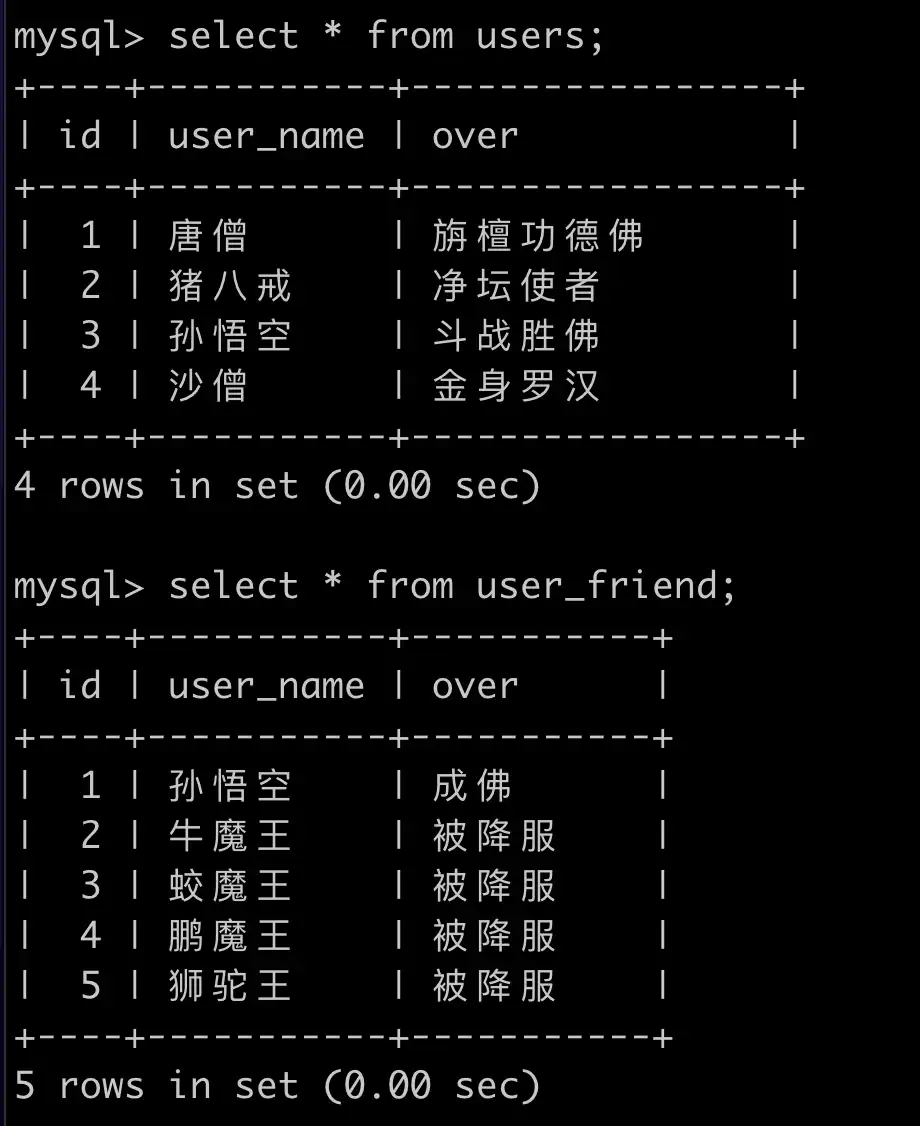
数据准备:
CREATE TABLE users (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_name` varchar(100) NOT NULL DEFAULT '',
`over` varchar(40) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
CREATE TABLE user_friend (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_name` varchar(100) NOT NULL DEFAULT '',
`over` varchar(40) NOT NULL DEFAULT '',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
-- 插入 users 表数据
insert into users(user_name,over) values ('唐僧', '旃檀功德佛');
insert into users(user_name,over) values ('猪八戒', '净坛使者');
insert into users(user_name,over) values ('孙悟空', '斗战胜佛');
insert into users(user_name,over) values ('沙僧', '金身罗汉');
-- 插入 user_friend 表数据
insert into user_friend(user_name,over) values ('孙悟空', '成佛');
insert into user_friend(user_name,over) values ('牛魔王', '被降服');
insert into user_friend(user_name,over) values ('蛟魔王', '被降服');
insert into user_friend(user_name,over) values ('鹏魔王', '被降服');
insert into user_friend(user_name,over) values ('狮驼王', '被降服');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 2.1 内连接(INNER)
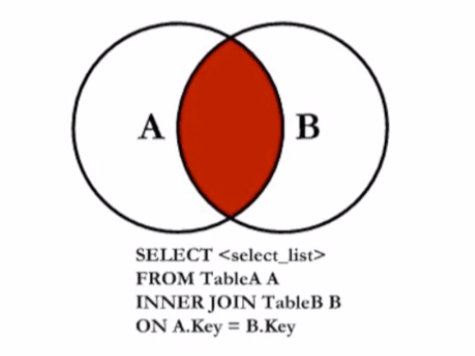
查询 A 表和 B 表中共同的部分
SELECT a.user_name
FROM users AS a
INNER JOIN user_friend AS b ON a.user_name = b.user_name;
2
3
# 2.2 左外连接(LEFT OUTER)
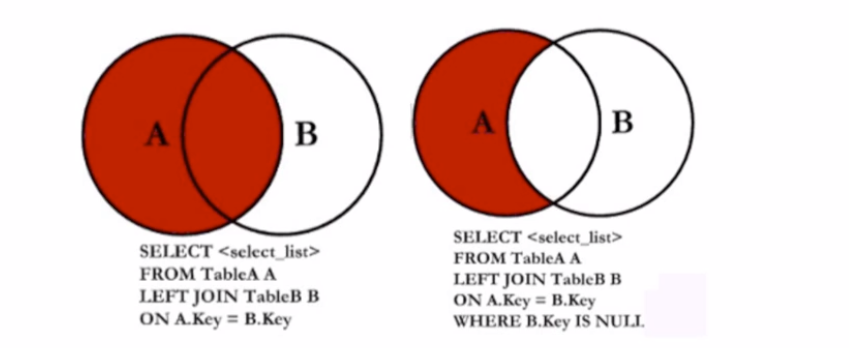
- 根据左表查询,查询结果包含左表所有记录,右表如果没有则所查询的字段使用 null 代替
SELECT a.user_name, a.over, b.over
FROM users a
LEFT JOIN user_friend b ON a.user_name = b.user_name;
2
3
- 查询只存在 A 表,同时存在 B 表的记录
SELECT a.user_name, a.over, b.over
FROM users a
LEFT JOIN user_friend b ON a.user_name = b.user_name
WHERE b.user_name IS NOT NULL;
2
3
4
- 查询存在 A 表中,但不存在 B 表的记录(由于 not in 无法使用索引,通常使用 left join is not null 的方式)
SELECT a.user_name, a.over, b.over
FROM users a
LEFT JOIN user_friend b ON a.user_name = b.user_name
WHERE b.user_name IS NULL;
2
3
4
# 2.3 右外链接(RIGHT OUTER)
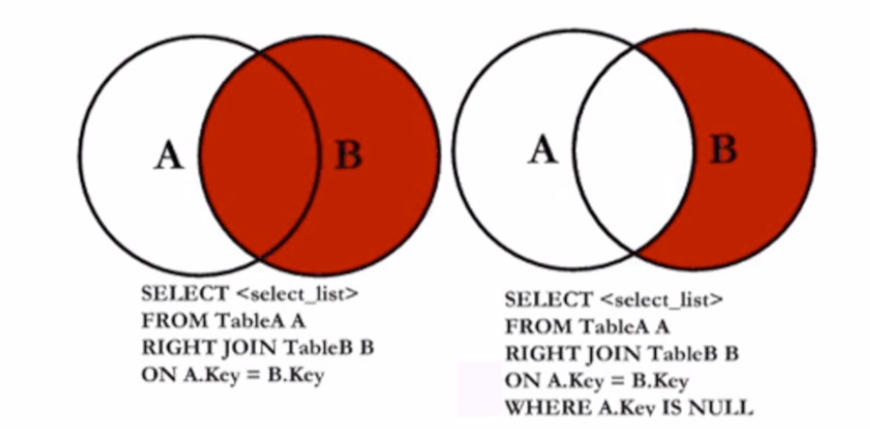
- 查询只存在 A 表,同时存在 B 表的记录
SELECT b.user_name, b.over, a.over
FROM users a
RIGHT JOIN user_friend b ON a.user_name = b.user_name
WHERE a.user_name IS NOT null;
2
3
4
- 查询存在 B表中,但不存在 A 表的记录
SELECT b.user_name, b.over, a.over
FROM users a
RIGHT JOIN user_friend b ON a.user_name = b.user_name
WHERE a.user_name IS NULL;
2
3
4
# 2.4 全外连接(FULL OUTER)
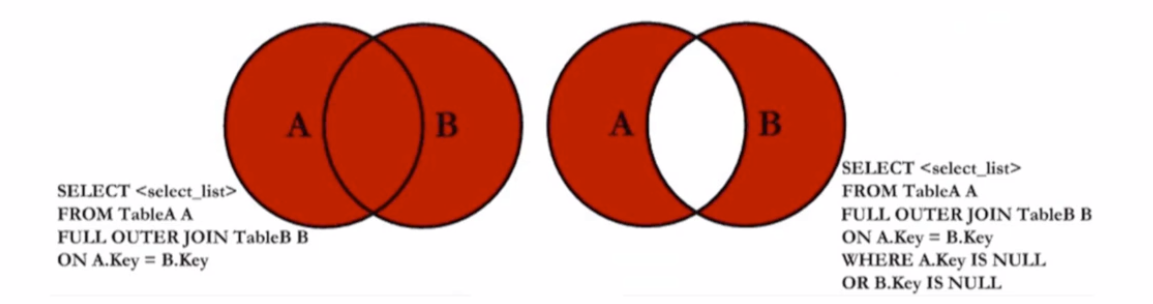
查询存在 A 表和 B 表的所有记录
SELECT a.user_name,a.over,b.over FROM users a LEFT JOIN user_friend b ON a.user_name = b.user_name UNION ALL SELECT b.user_name, b.over, a.over FROM users a RIGHT JOIN user_friend b ON a.user_name = b.user_name;1
2
3
4
5
6
7查询只存在 A 表或只存在 B 表的记录
SELECT a.user_name, a.over, b.over FROM users a LEFT JOIN user_friend b ON a.user_name = b.user_name WHERE b.user_name IS NULL UNION ALL SELECT b.user_name, b.over, a.over FROM users a RIGHT JOIN user_friend b ON a.user_name = b.user_name WHERE a.user_name IS NULL;1
2
3
4
5
6
7
8
9
# 2.5 交叉连接(CROSS)
Cross Join 交叉连接又称笛卡尔连接。如果 A 和 B 是两个集合,它们的交叉连接就记为:A * B
SELECT a.user_name, a.over, b.user_name, b.over
FROM user1 a
CROSS JOIN user2 b;
2
3
# 2.6 聚合查询
WHERE 和 HAVING区别:
- 如果需要通过连接从关联表中获取数据,WHERE是先筛选后连接,而HAVING是先连接后筛选,所以WHERE比HAVING效率更高
- WHERE 可以直接使用表中的字段作为筛选条件,不能使用分组中的计算函数,在GROUP BY 前。而HAVING必须要与GROUP BY配合使用,可以使用分组函数或分组字段作为筛选条件
- HAVING 通常用于数据分组统计时的复杂查询
常见聚合函数:求和函数 SUM()、求平均函数 AVG()、求最大值 MAX()、求最小值 MIN()
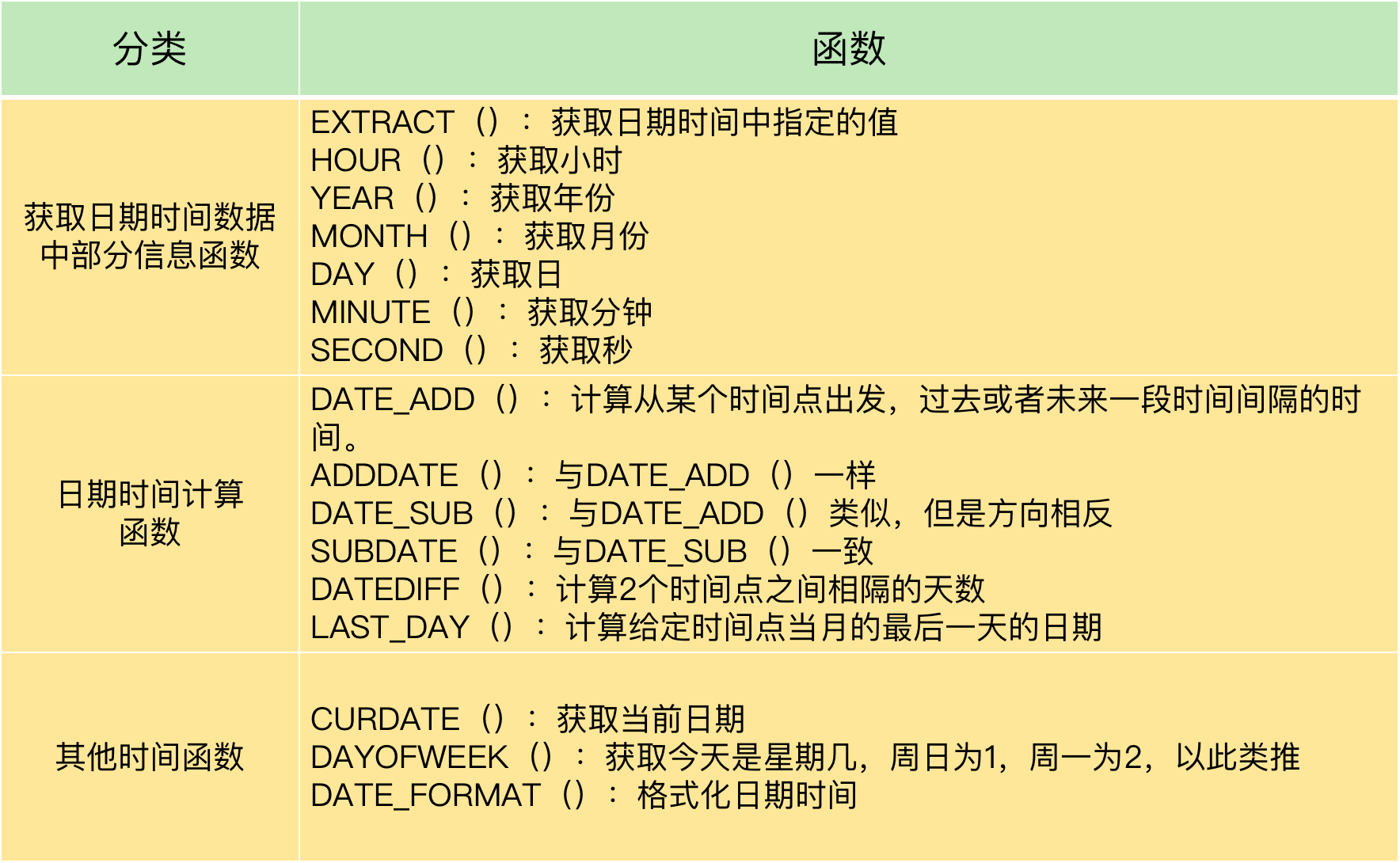
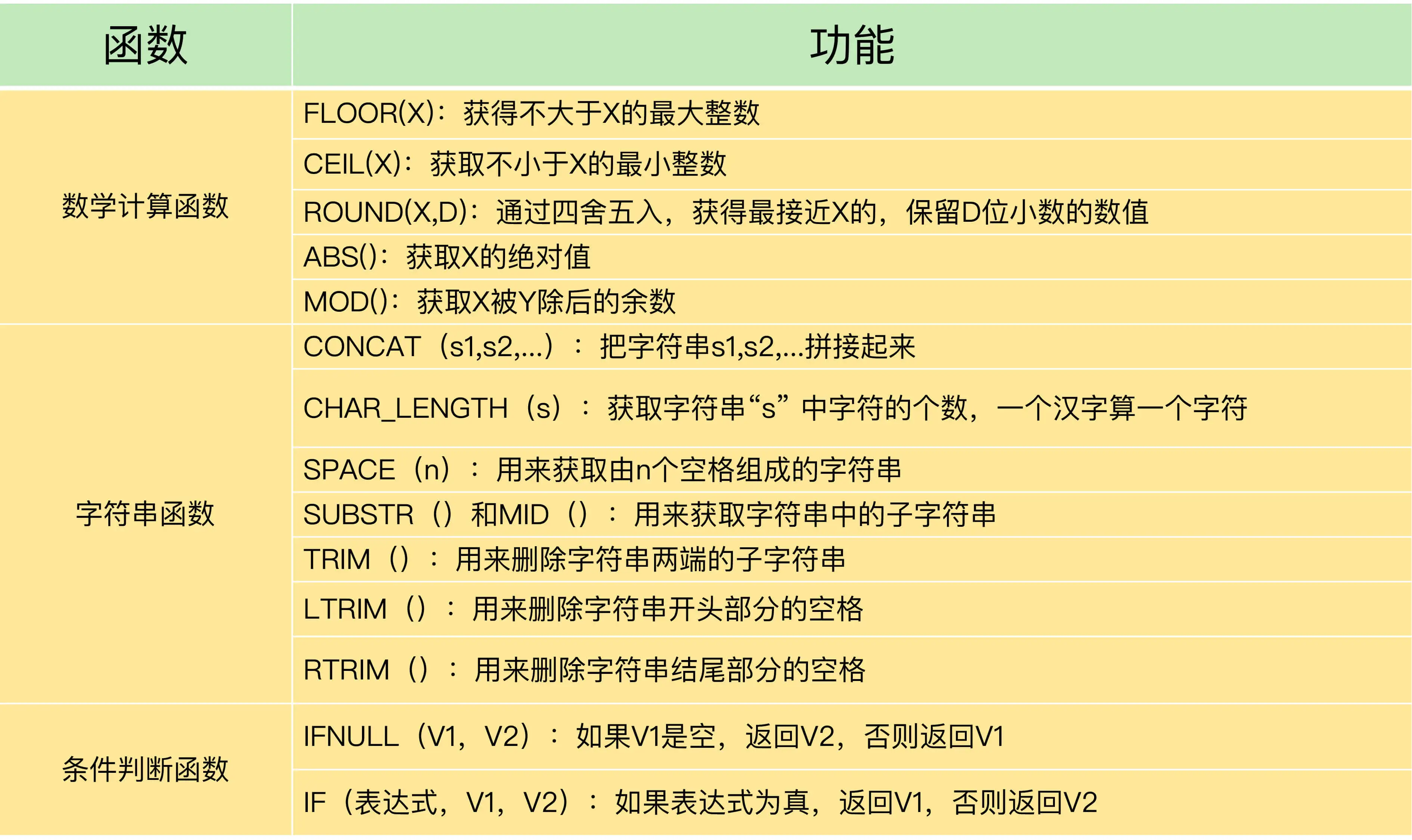
常用函数:
# 3 开发技巧
# 技巧一:如何更新使用过滤条件中包括自身的表?
目的:更新 user1 中的 over 为齐天大圣,条件是 user_name 同时存在于 user1 和 user2 表
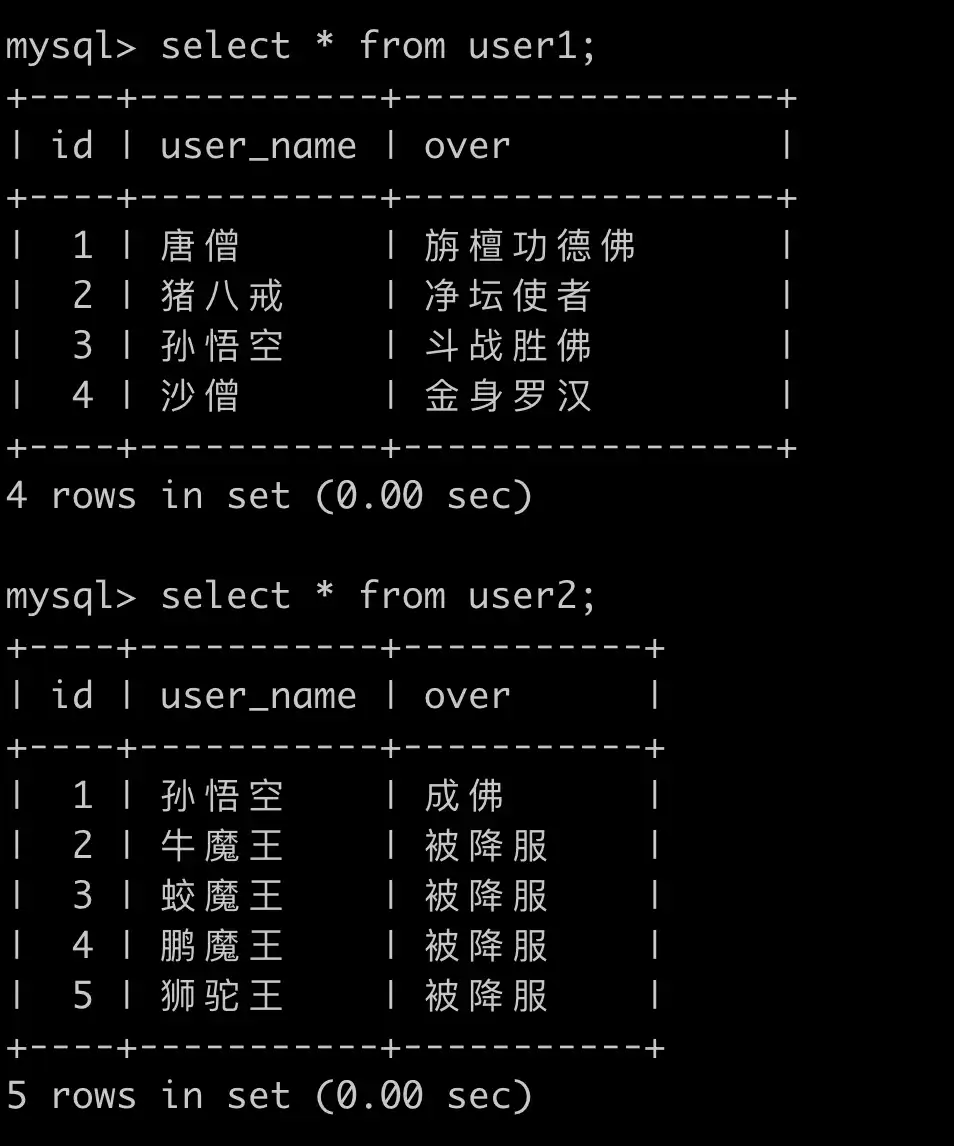
正常思路的写法:
UPDATE user1 SET over = '齐天大圣'
WHERE user1.user_name IN (
SELECT a.user_name FROM user1 a
INNER JOIN user2 b ON a.user_name = b.user_name
);
2
3
4
5
MySQL 错误提示:You can't specify target table 'user1' for update in FROM clause,更新语句的条件语句中不能包含自身的表
使用 Join 实现该功能:
UPDATE user1 a
JOIN user2 b ON a.user_name = b.user_name
SET a.over = '齐天大圣';
2
3
# 技巧二:使用 JOIN 优化聚合子查询
目的:如何查询出四人组打怪最多的日期?(避免子查询)
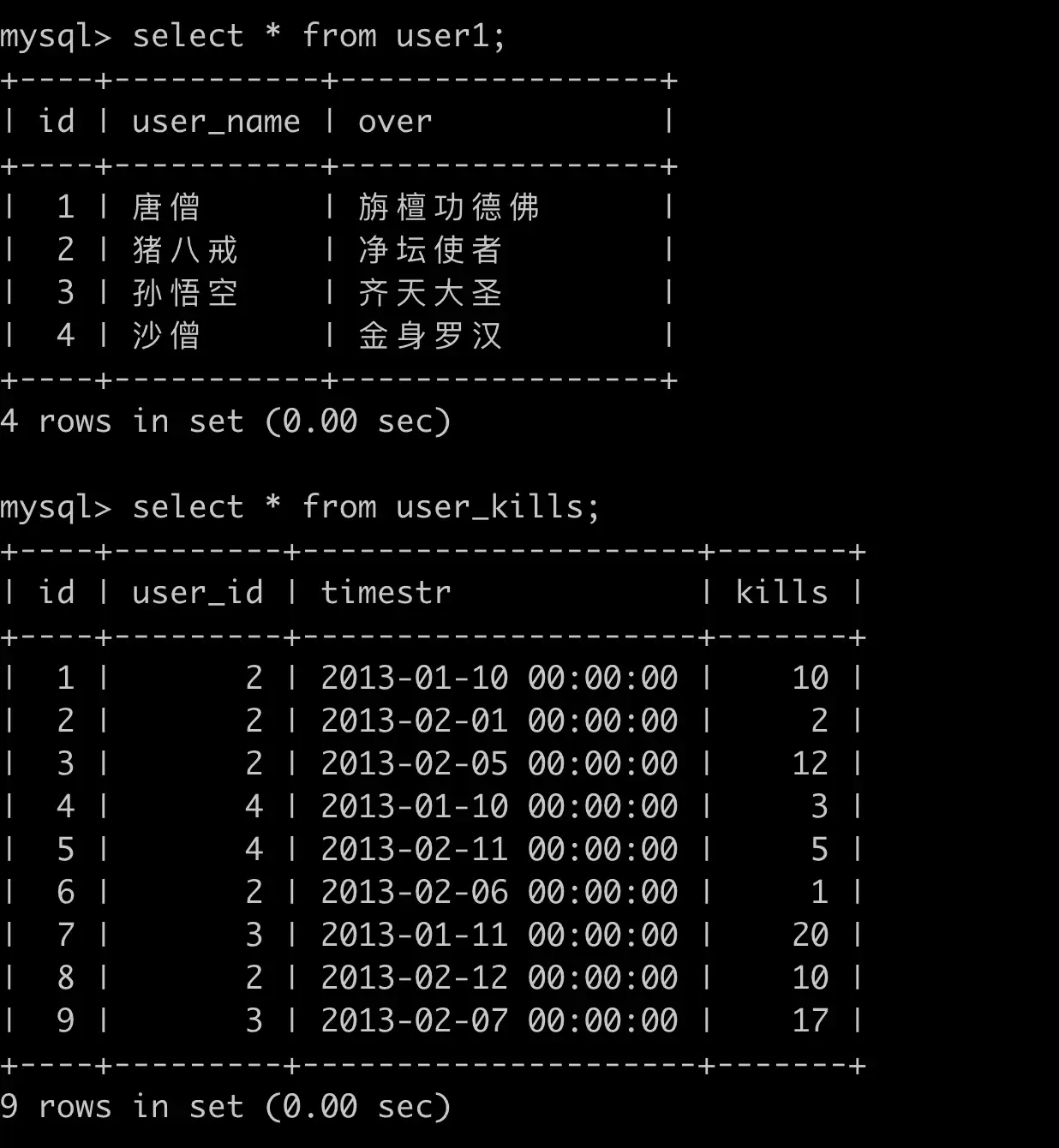
正常思路写法(使用子查询):
SELECT a.user_name, b.timestr, b.kills
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
WHERE b.kills = (
SELECT MAX(c.kills) FROM user_kills c WHERE c.user_id = b.user_id
);
2
3
4
5
6
使用 Join 优化:
SELECT a.user_name, b.timestr, b.kills
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
JOIN user_kills c ON b.user_id = c.user_id
GROUP BY a.user_name, b.timestr, b.kills
HAVING b.kills = MAX(c.kills);
2
3
4
5
6
# 技巧三:查询取景四人组每个人杀怪最多的前两天数据
正常思路是每个人查询一次:
SELECT a.user_name, b.timestr, b.kills
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
WHERE a.user_name = '孙悟空'
ORDER BY b.kills DESC
LIMIT 2;
2
3
4
5
6
Oracle 数据库可使用 row_number() 函数
WITH tmp AS (
SELECT a.user_name, b.timestr, b.kills,
ROW_NUMBER() OVER(PARTITION BY a.user_name ORDER BY b.kills) cnt
FROM user1 a JOIN user_kills b ON a.id = b.user_id
) SELECT * FROM tmp WHERE cnt <=2
2
3
4
5
MySQL 数据库:
SELECT d.user_name, c.timestr, c.kills
FROM (
SELECT user_id, timestr, kills,
(SELECT COUNT(*) FROM user_kills b
WHERE b.user_id = a.user_id AND a.kills <= b.kills) AS cnt
FROM user_kills a
GROUP BY user_id, timestr, kills
) c JOIN user1 d ON c.user_id = d.id
WHERE cnt <= 2;
2
3
4
5
6
7
8
9
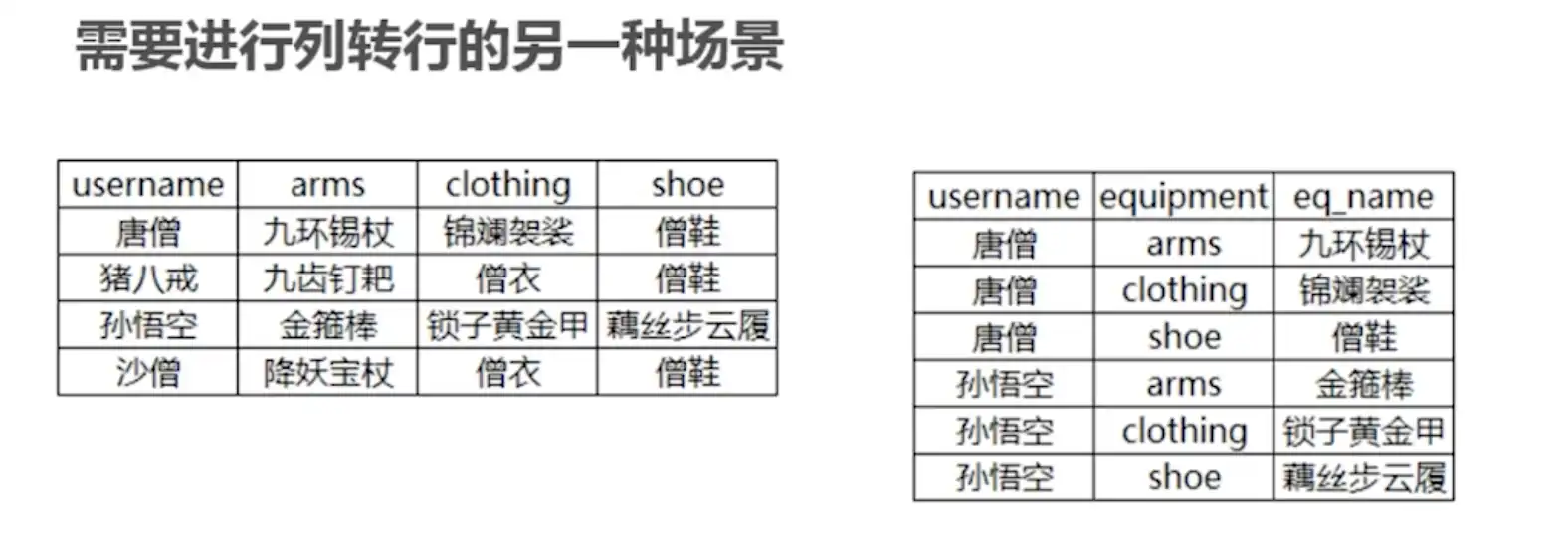
# 技巧四:如何进行行转列
需要行列转换的场景:如下图报表统计、汇总展示等
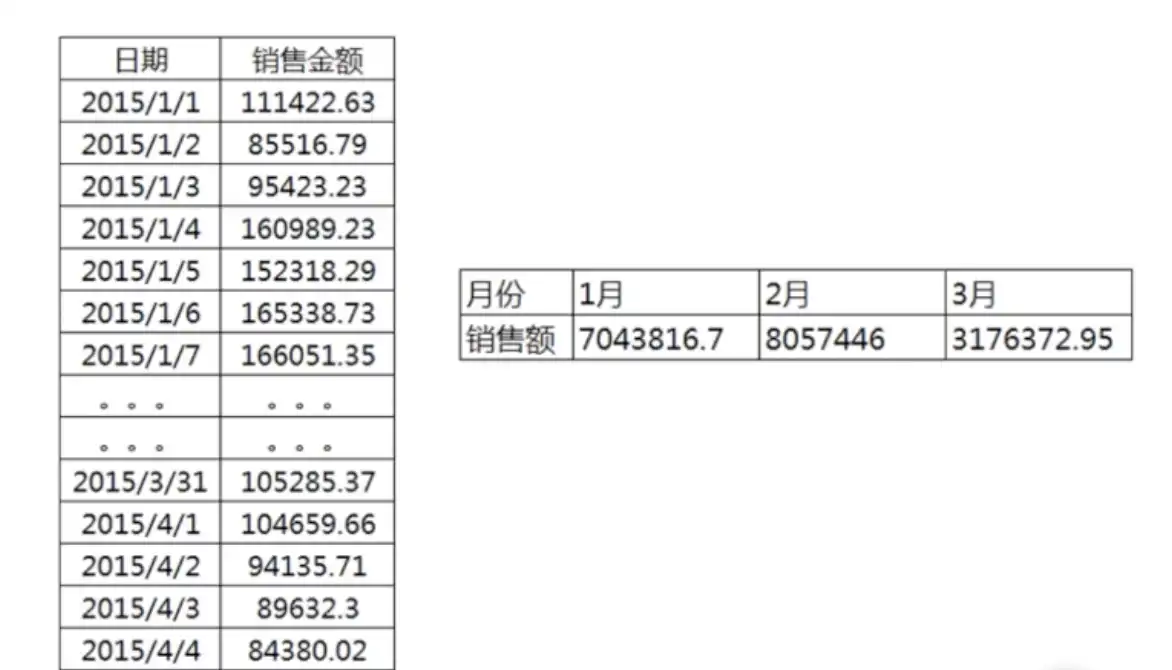
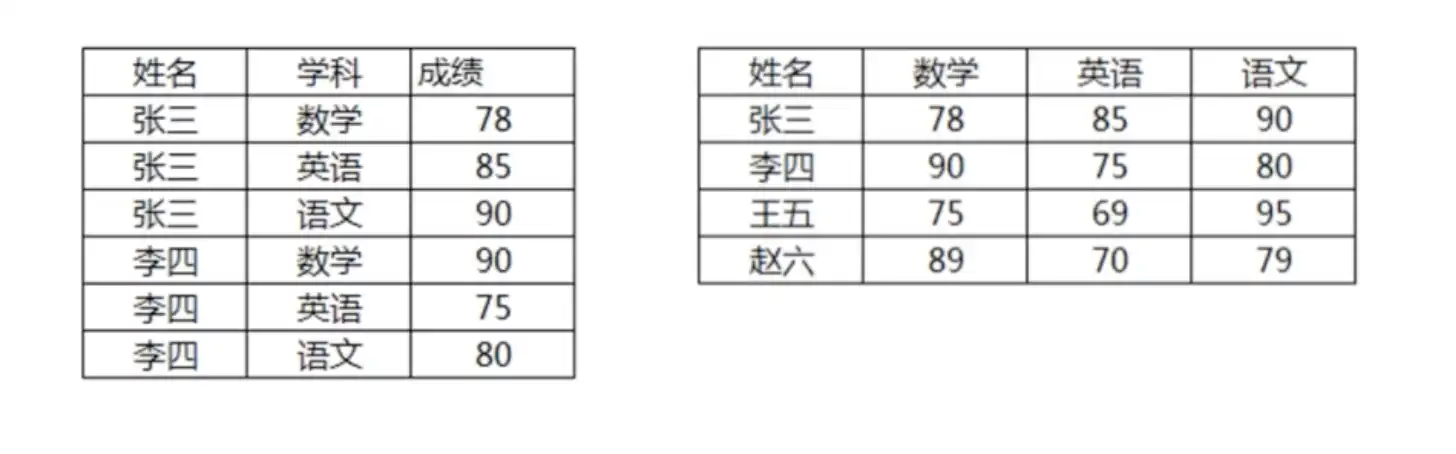
举例需实现如下结果:
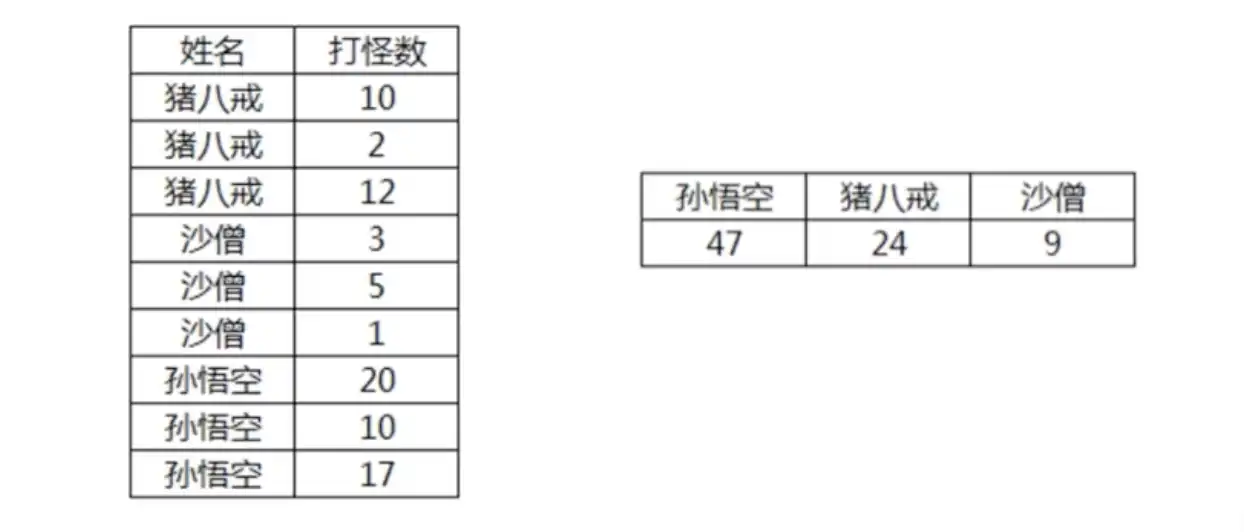
首先行显示查询:
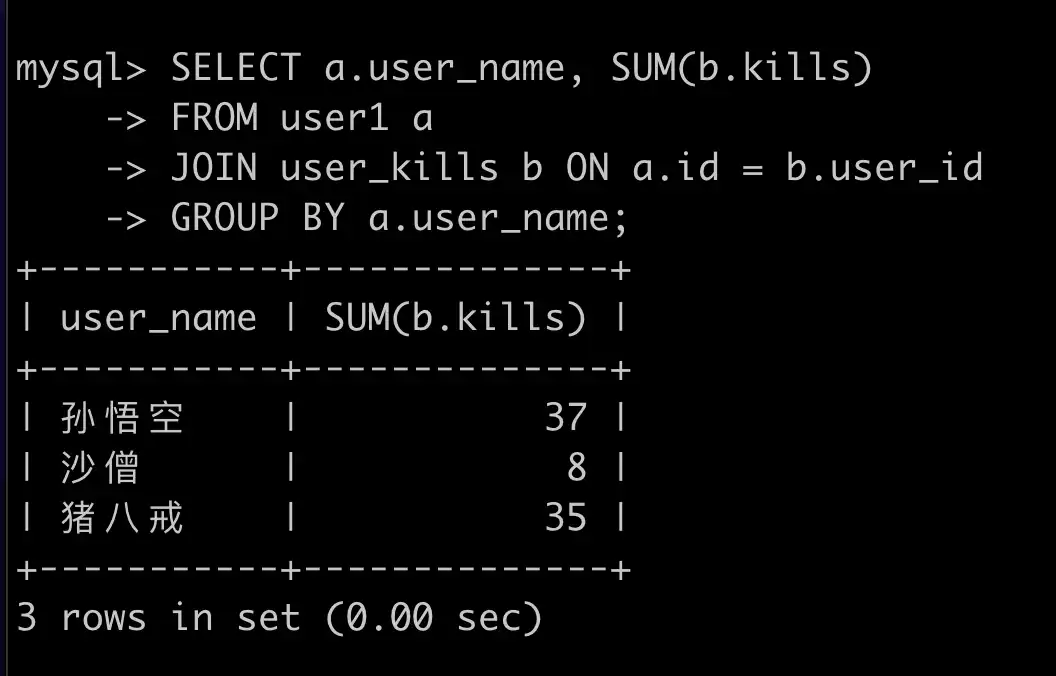
SELECT a.user_name, SUM(b.kills)
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
GROUP BY a.user_name;
2
3
4
查询结果:
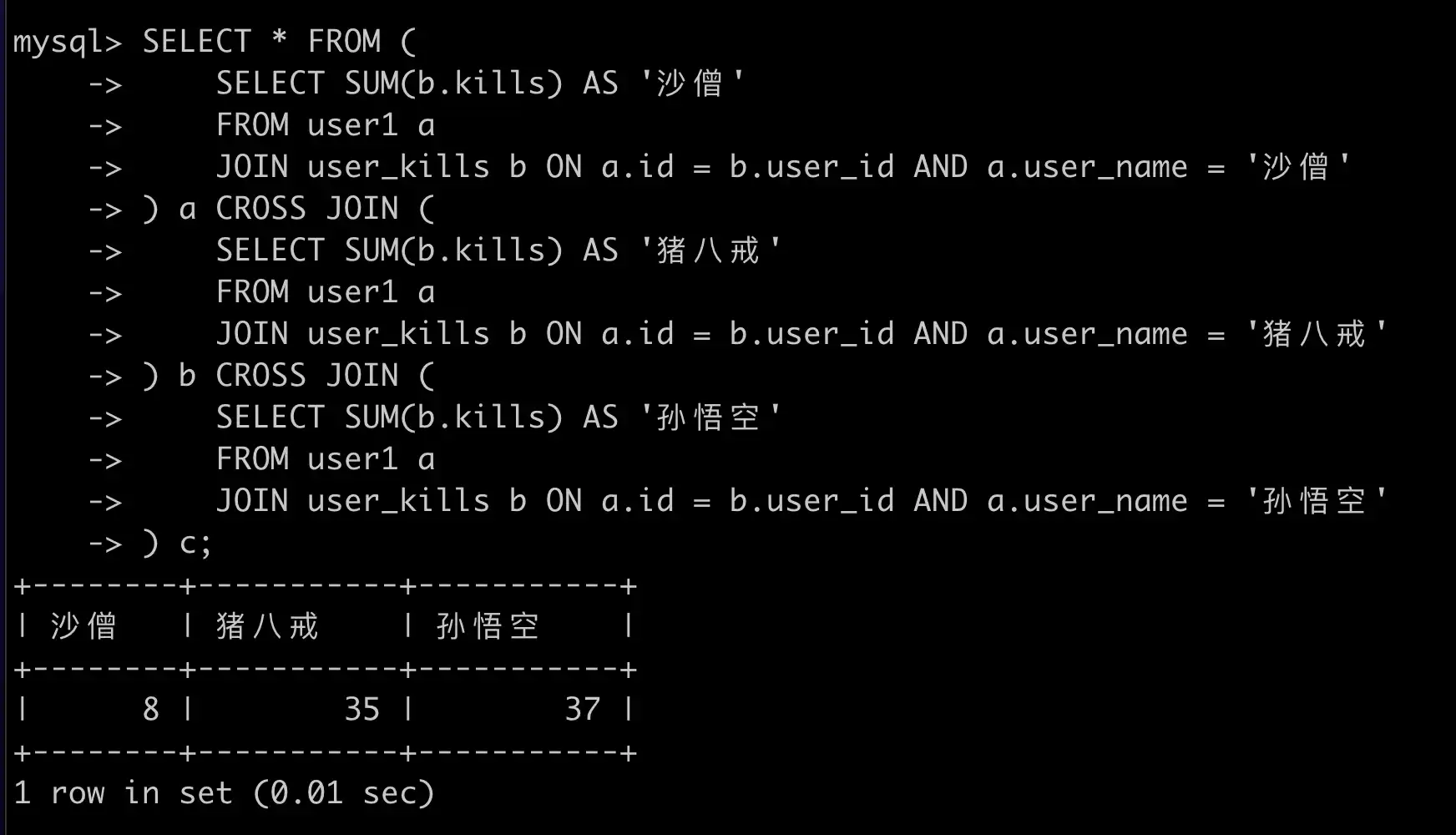
第一种行转列,使用 CROSS JOIN,效率低不适用与多用户,不推荐:
SELECT * FROM (
SELECT SUM(b.kills) AS '沙僧'
FROM user1 a
JOIN user_kills b ON a.id = b.user_id AND a.user_name = '沙僧'
) a CROSS JOIN (
SELECT SUM(b.kills) AS '猪八戒'
FROM user1 a
JOIN user_kills b ON a.id = b.user_id AND a.user_name = '猪八戒'
) b CROSS JOIN (
SELECT SUM(b.kills) AS '孙悟空'
FROM user1 a
JOIN user_kills b ON a.id = b.user_id AND a.user_name = '孙悟空'
) c;
2
3
4
5
6
7
8
9
10
11
12
13
查询结果:
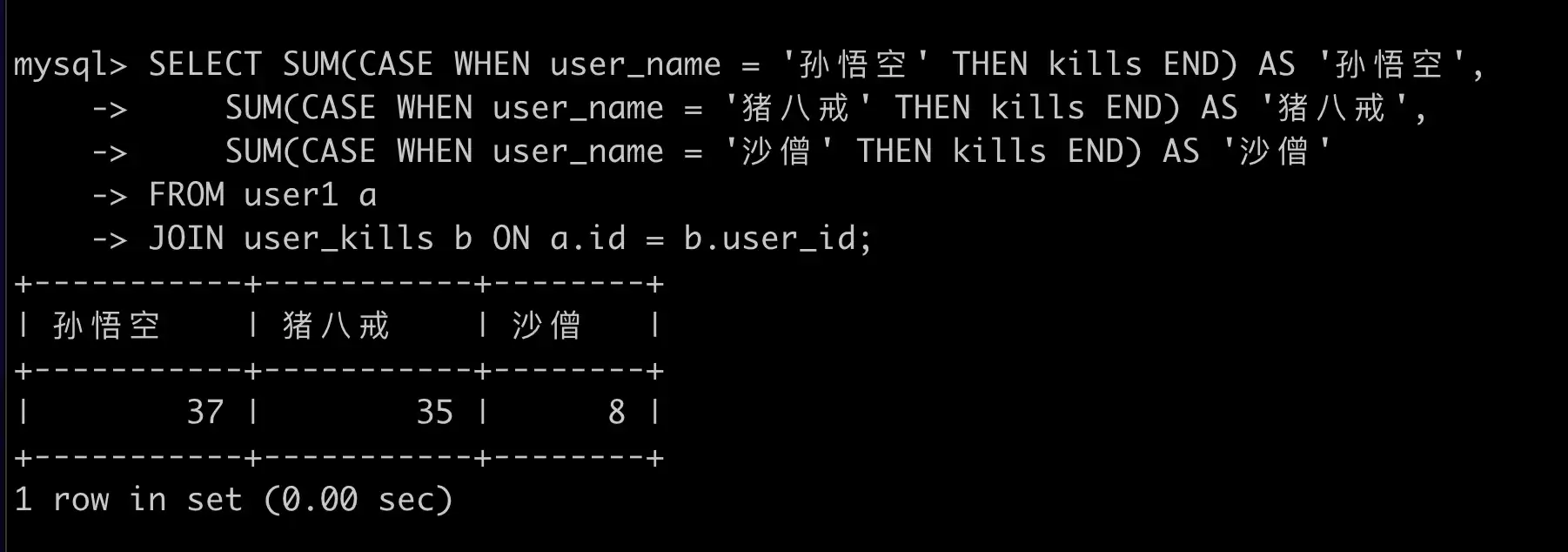
第二种行转列,使用 CASE (推荐)
SELECT SUM(CASE WHEN user_name = '孙悟空' THEN kills END) AS '孙悟空',
SUM(CASE WHEN user_name = '猪八戒' THEN kills END) AS '猪八戒',
SUM(CASE WHEN user_name = '沙僧' THEN kills END) AS '沙僧'
FROM user1 a
JOIN user_kills b ON a.id = b.user_id;
2
3
4
5
查询结果:
# 技巧五:如何进行列转行
需要进行列转行的场景:


例子:
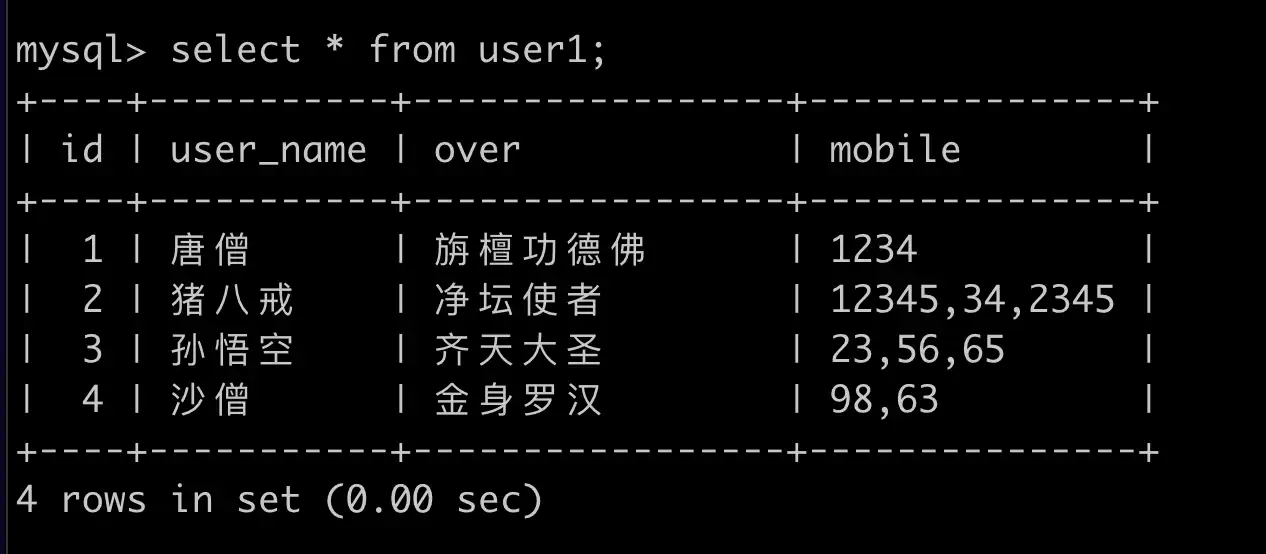
利用序列表处理列转行:
-- 创建序列表
CREATE TABLE tb_sequence(id int(10) auto_increment not null, primary key(id));
INSERT INTO tb_sequence VALUES(),(),(),(),(),(),(),(),(),();
-- 交叉连接 tb_sequence
SELECT user_name,
REPLACE(SUBSTRING(SUBSTRING_INDEX(mobile, ',', a.id), CHAR_LENGTH(SUBSTRING_INDEX(mobile, ',', a.id-1)) + 1), ',', '') AS mobile
FROM tb_sequence a CROSS JOIN (
SELECT user_name, CONCAT(mobile, ',') AS mobile, LENGTH(mobile) - LENGTH(REPLACE(mobile,',','')) + 1 size FROM user1 b
) b ON a.id <= b.size;
2
3
4
5
6
7
8
9
10
查询结果:

其他场景
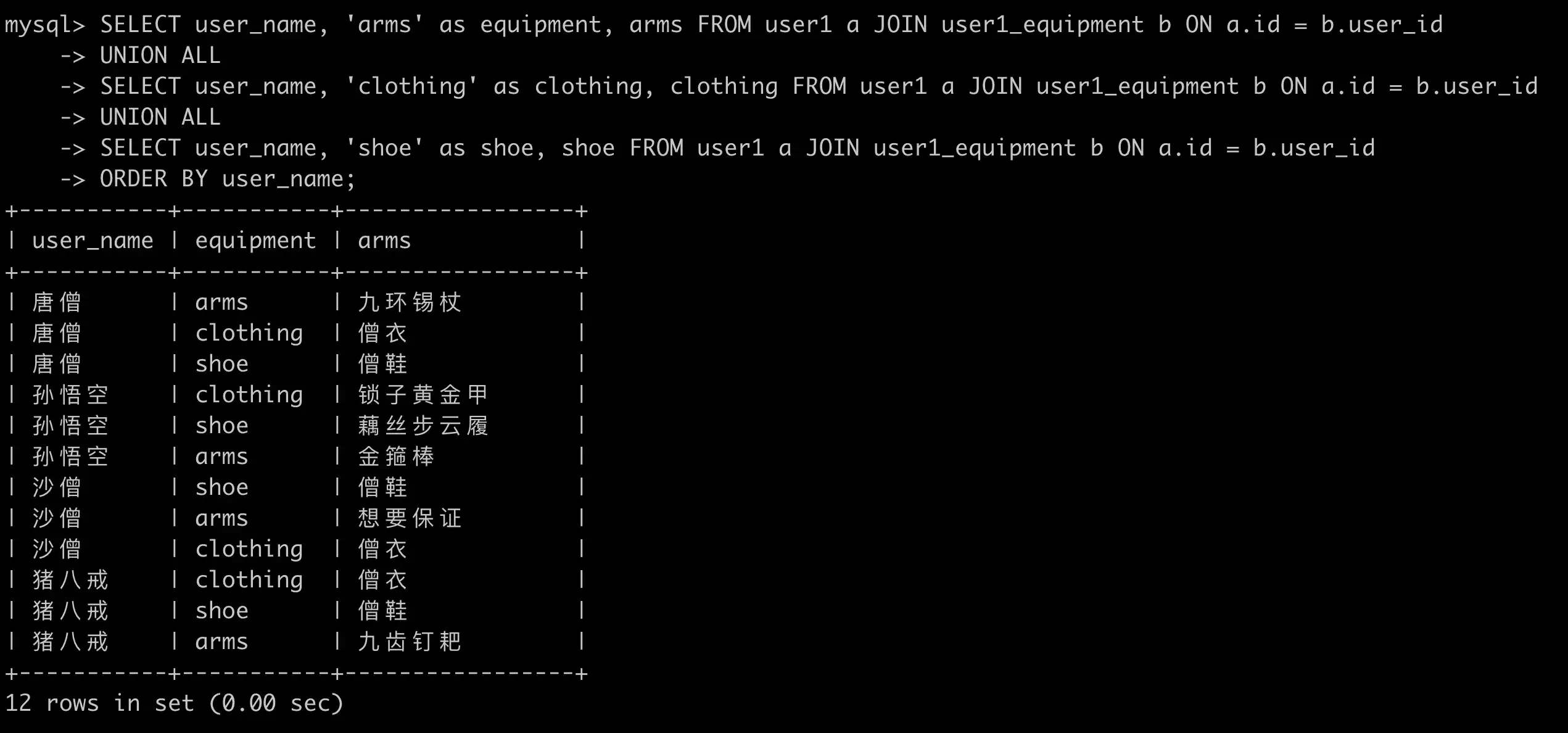
使用 UNION 实现:
SELECT user_name, 'arms' as equipment, arms FROM user1 a JOIN user1_equipment b ON a.id = b.user_id
UNION ALL
SELECT user_name, 'clothing' as clothing, clothing FROM user1 a JOIN user1_equipment b ON a.id = b.user_id
UNION ALL
SELECT user_name, 'shoe' as shoe, shoe FROM user1 a JOIN user1_equipment b ON a.id = b.user_id
ORDER BY user_name;
2
3
4
5
6
查询结果:
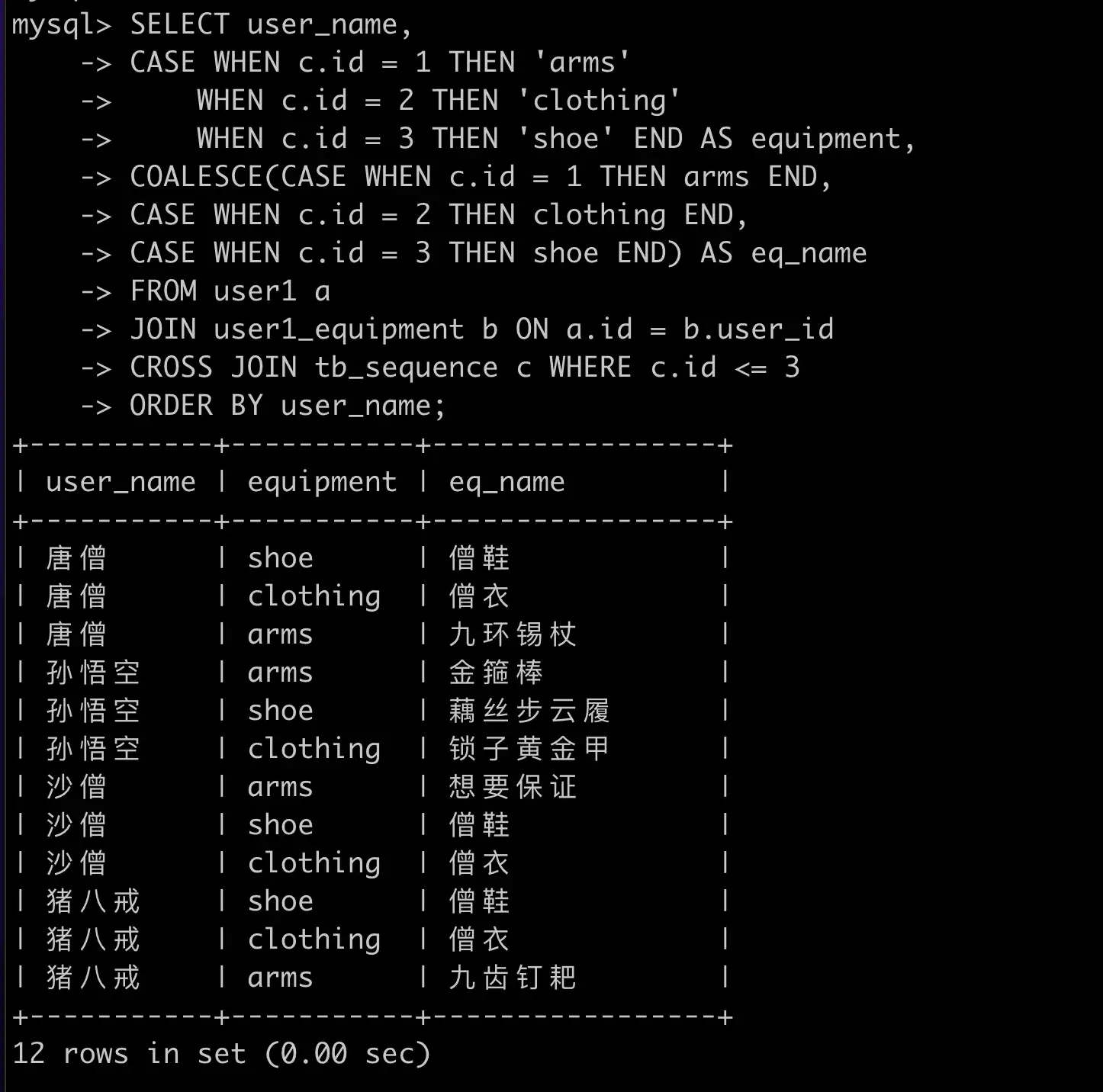
使用序列表实现:
SELECT user_name,
CASE WHEN c.id = 1 THEN 'arms'
WHEN c.id = 2 THEN 'clothing'
WHEN c.id = 3 THEN 'shoe' END AS equipment,
COALESCE(CASE WHEN c.id = 1 THEN arms END,
CASE WHEN c.id = 2 THEN clothing END,
CASE WHEN c.id = 3 THEN shoe END) AS eq_name
FROM user1 a
JOIN user1_equipment b ON a.id = b.user_id
CROSS JOIN tb_sequence c WHERE c.id <= 3
ORDER BY user_name;
2
3
4
5
6
7
8
9
10
11
查询结果:
# 技巧六:如何生成唯一序列
数据库主键:MySQL 生成序列号的方法:AUTO_INCREMENT
业务序列号,如发票号、车票号、订单号等....
优先选择系统提供的序列号生成方式
在特殊情况下可以使用 SQL 方式生成序列号
需求:生成订单序列号,格式:YYYYMMDDNNNNNNN,如 202212230000001
用 MySQL 存储过程来生成特殊的序列号:
DECLARE v_cnt INT;
DECLARE v_timestr INT;
DECLARE rowcount BIGINT;
SET v_timestr=DATE_FORMAT(NOW(), '%Y%m%d');
SELECT ROUND(RAND()*100, 0) + 1 INTO v_cnt;
START TRANSACTION;
UPDATE order_seq SET order_sn = order_sn + v_cnt WHERE timestr = v_timestr;
IF ROW_COUNT() = 0 THEN
INSERT INTO order_seq(timestr, order_sn) VALUES (v_timestr, v_cnt);
END IF;
SELECT CONCAT(v_timestr, LPAD(order_sn, 7, 0)) AS order_sn
FROM order_seq WHERE timestr = v_timestr;
COMMIT;
2
3
4
5
6
7
8
9
10
11
12
13
# 技巧七:如何删除重复数据
产生重复数据的原因:重复录入数据、重复提交等......
利用 Group By 和 Having 从句查询重复数据:
SELECT user_name, count(*)
FROM user1
GROUP BY user_name
HAVING count(*) > 1;
2
3
4
删除重复数据,保留 ID 最大的那条记录:
DELETE a
FROM user1 a
JOIN (
SELECT user_name, COUNT(*), MAX(id) AS id
FROM user1
GROUP BY user_name HAVING COUNT(*) > 1
) b ON a.user_name = b.user_name
WHERE a.id < b.id;
2
3
4
5
6
7
8
# 技巧八:如何在子查询中匹配两个值
子查询的定义:当一个查询是另一个查询的条件时,称之为子查询
场景一:使用子查询可以避免由于子查询中的数据产生的重复
-- 使用 JOIN 可能产生重复数据
SELECT a.user_name
FROM user1 a
JOIN user_kills b ON a.id = b.user_id;
-- 使用 JOIN 可能产生重复数据,添加 DISTINCT
SELECT DISTINCT a.user_name
FROM user1 a
JOIN user_kills b ON a.id = b.user_id;
-- 使用子查询
SELECT user_name
FROM user1
WHERE id IN (
SELECT user_id FROM user_kills
);
2
3
4
5
6
7
8
9
10
11
12
13
14
场景二:查询出每一个取经人打怪最多的日期,并列出取经人的姓名,打怪最多的日期和打怪数量
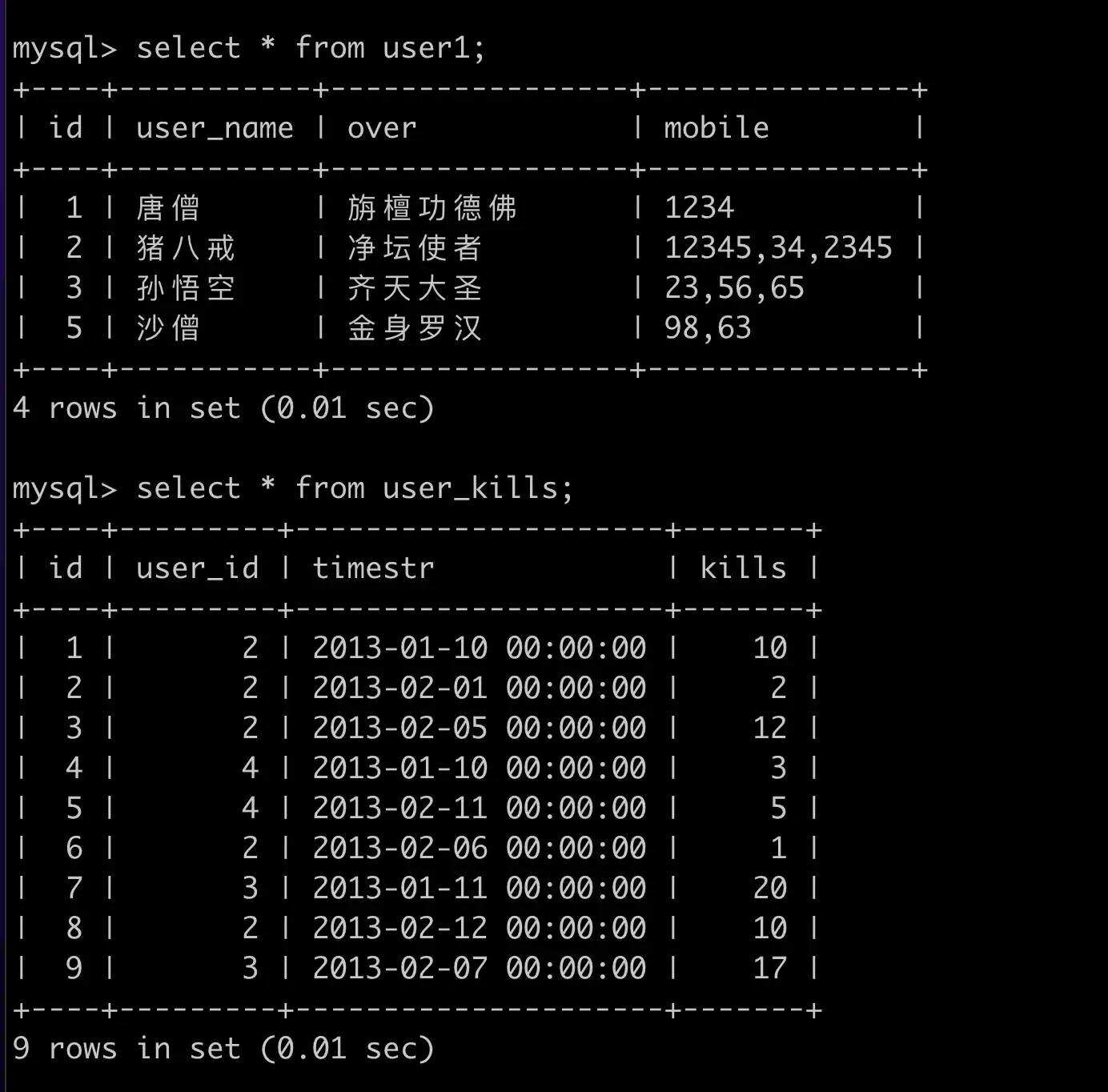
SELECT a.user_name, b.timestr, kills
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
JOIN (
SELECT user_id, MAX(kills) AS cnt
FROM user_kills
GROUP BY user_id
) c ON b.user_id = c.user_id AND b.kills = c.cnt;
2
3
4
5
6
7
8
查询结果:
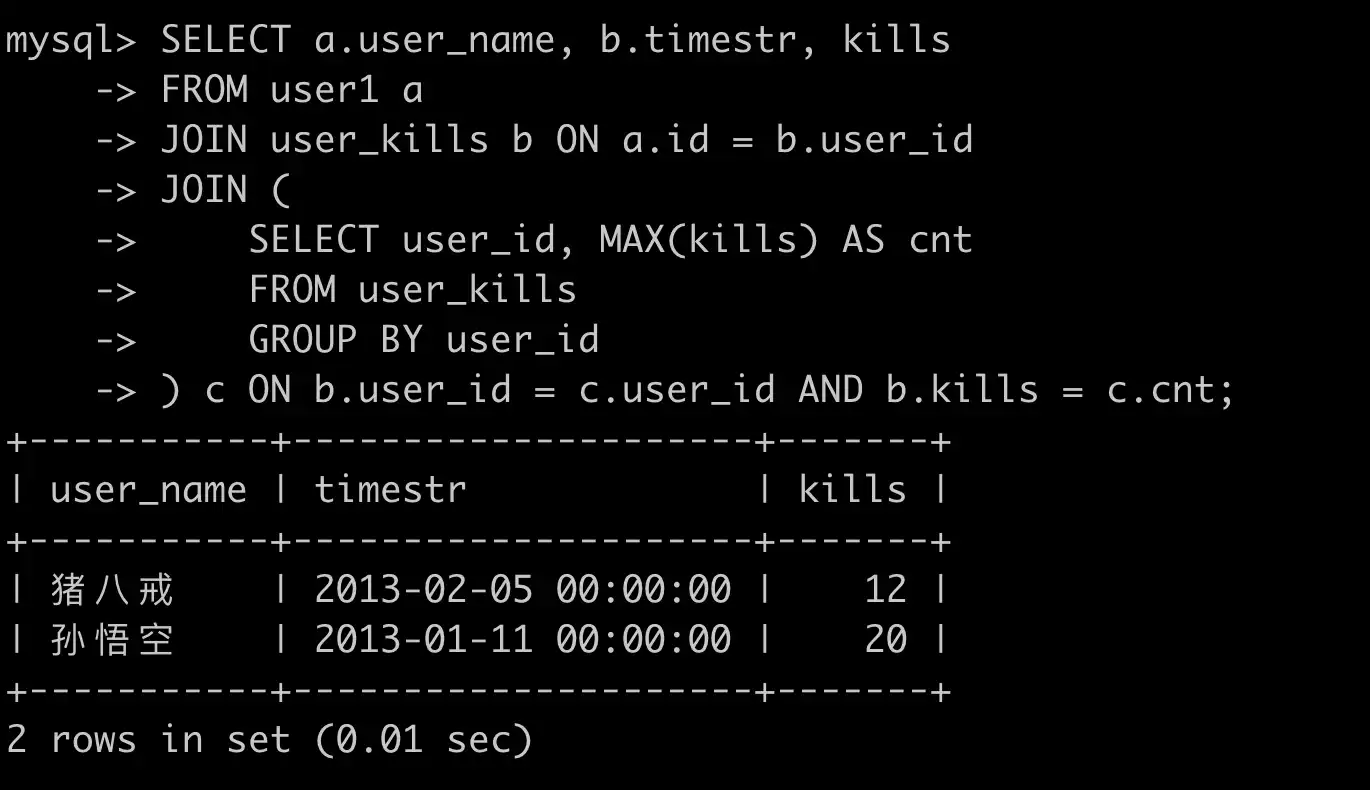
使用 MySQL 独有的多列过滤方式:
SELECT a.user_name, b.timestr, kills
FROM user1 a
JOIN user_kills b ON a.id = b.user_id
WHERE (b.user_id, b.kills) IN (
SELECT user_id, MAX(kills)
FROM user_kills
GROUP BY user_id
);
2
3
4
5
6
7
8
查询结果:

# 技巧九:如何解决同一属性的多值过滤
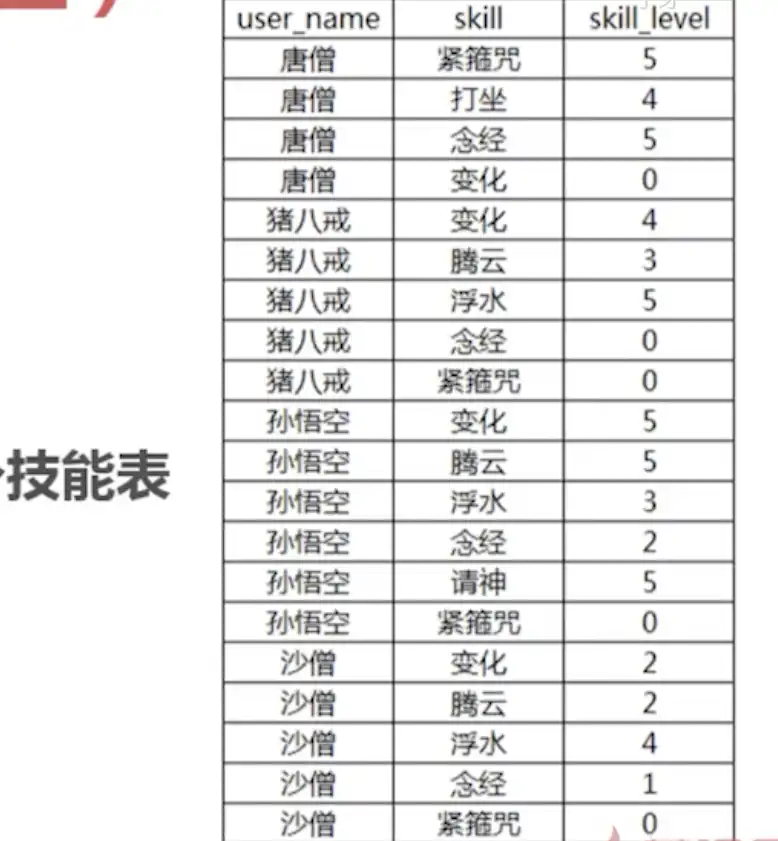
如何查询出同时具有变化和念经这两项技能的取经人?
SELECT a.user_name, b.skill, b.skill_level
FROM user1 a
JOIN user_skills b ON a.id = b.user_id
WHERE b.skill IN ('变化', '念经')
AND b.skill_level > 0;
2
3
4
5
查询结果可见,这种方法查询的是 具有 (变化) 或 (念经) 或 (变化和念经)技能的人
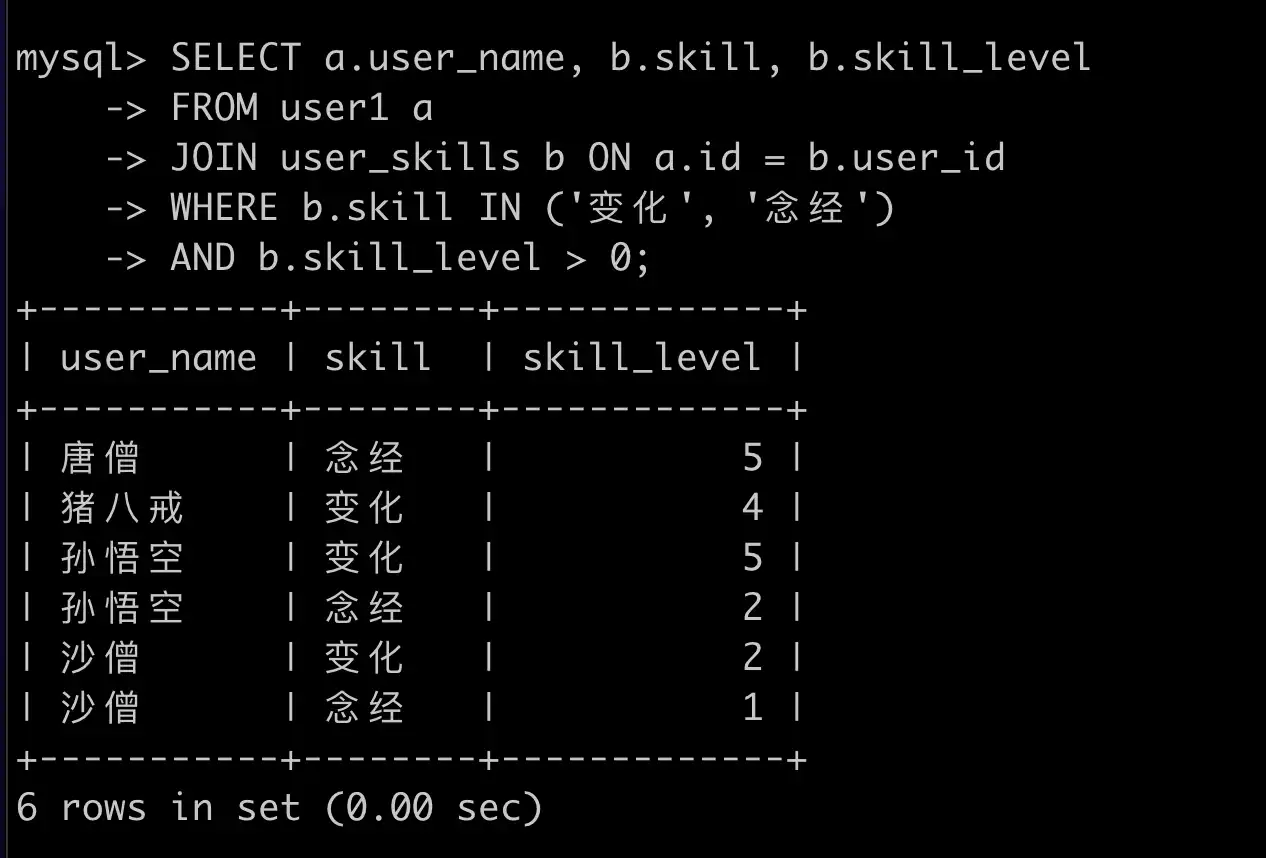
正确方式使用 JOIN 实现:
SELECT a.user_name, b.skill, c.skill
FROM user1 a
JOIN user_skills b ON a.id = b.user_id AND b.skill = '变化'
JOIN user_skills c ON c.user_id = b.user_id AND c.skill = '念经'
WHERE b.skill_level > 0
AND c.skill_level > 0;
2
3
4
5
6
查询结果:
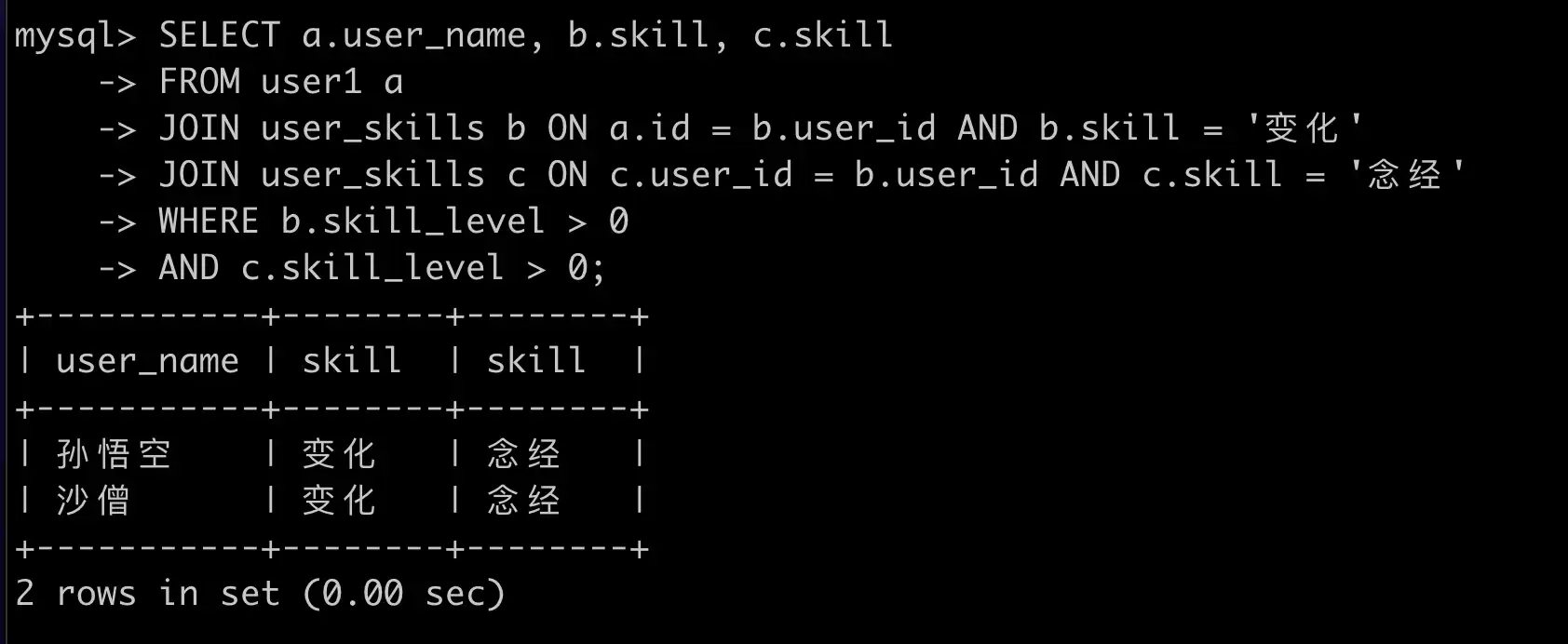
SELECT a.user_name, b.skill, c.skill, d.skill
FROM user1 a
LEFT JOIN user_skills b ON a.id = b.user_id AND b.skill = '念经' AND b.skill_level > 0
LEFT JOIN user_skills c ON a.id = c.user_id AND c.skill = '变化' AND c.skill_level > 0
LEFT JOIN user_skills d ON a.id = d.user_id AND d.skill = '腾云' AND d.skill_level > 0
2
3
4
5
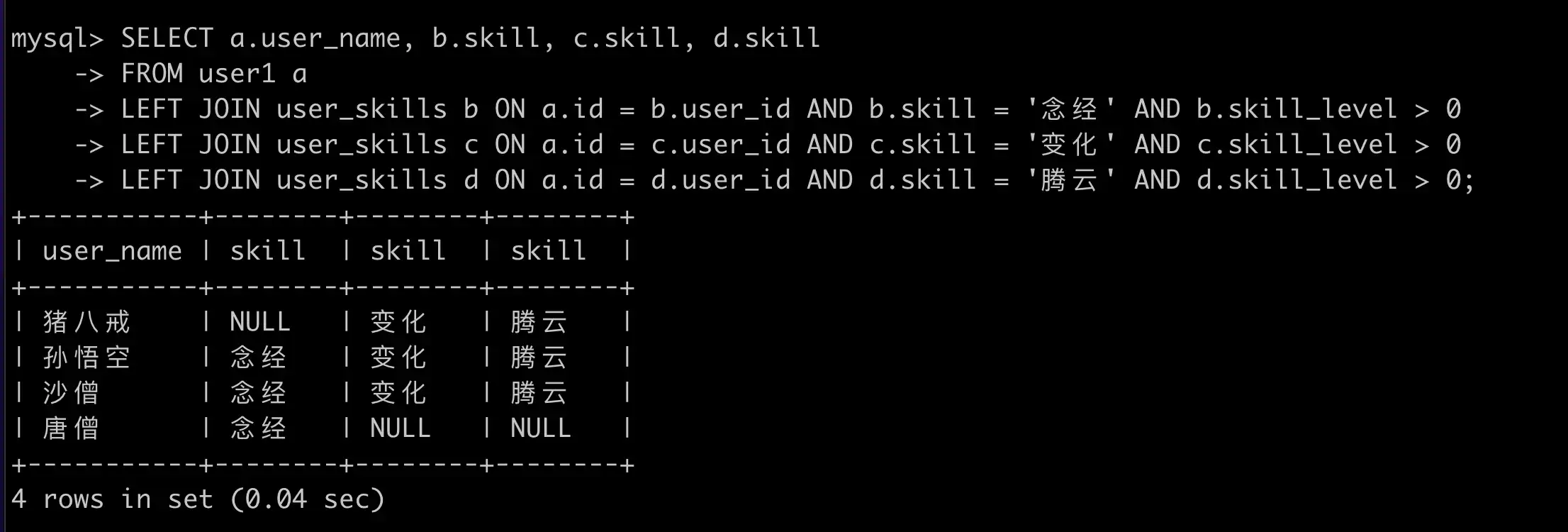
SELECT a.user_name, GROUP_CONCAT(b.skill)
FROM user1 a
JOIN user_skills b ON a.id = b.user_id
WHERE b.skill IN ('念经', '变化', '腾云')
GROUP BY a.user_name
HAVING count(*) >= 2;
2
3
4
5
6
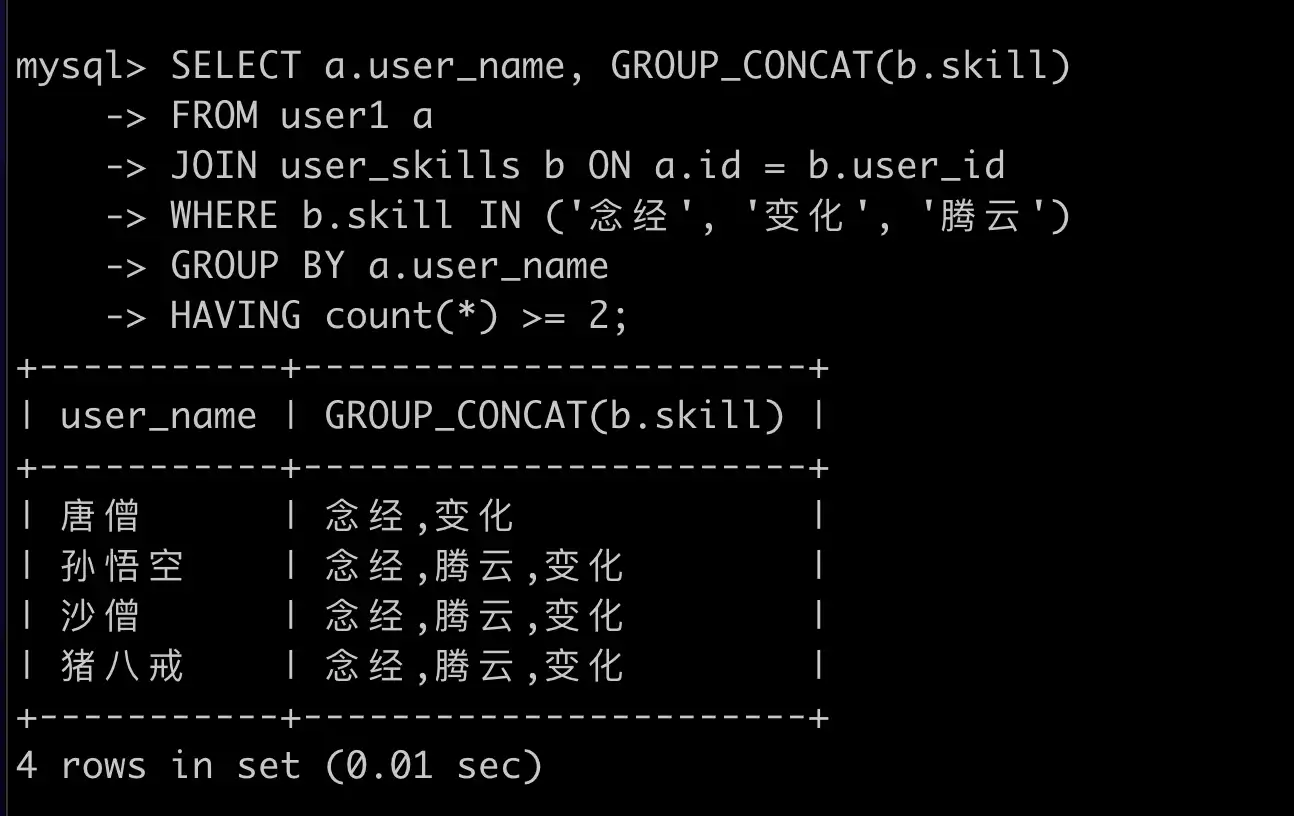
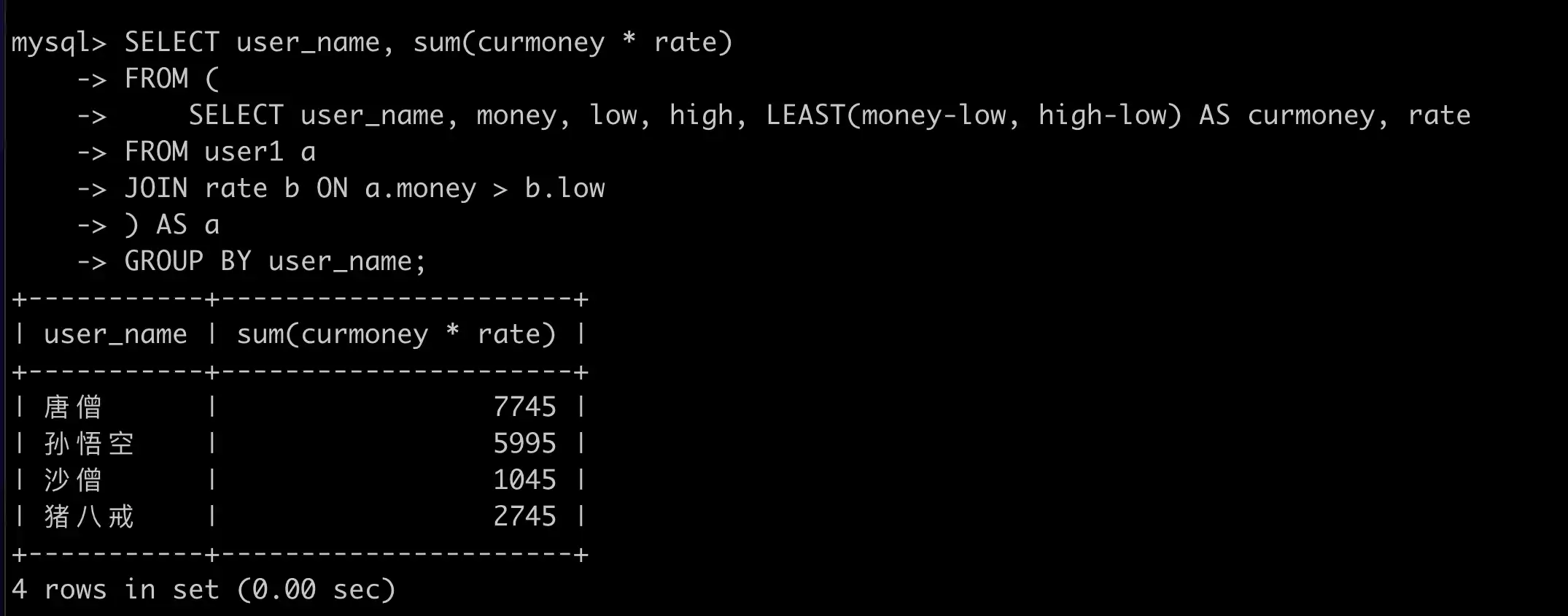
# 技巧十:计算累进税
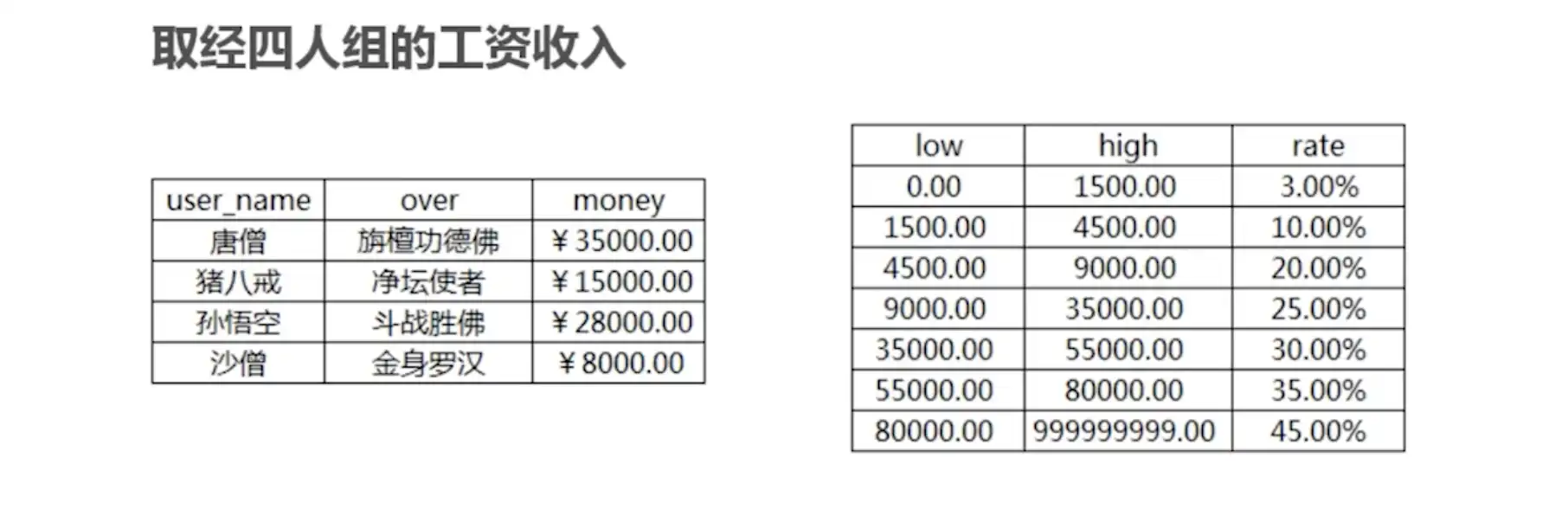
SELECT a.user_name, money, low, high, rate
FROM user1 a
JOIN rate b ON a.money > b.low
ORDER BY user_name;
2
3
4

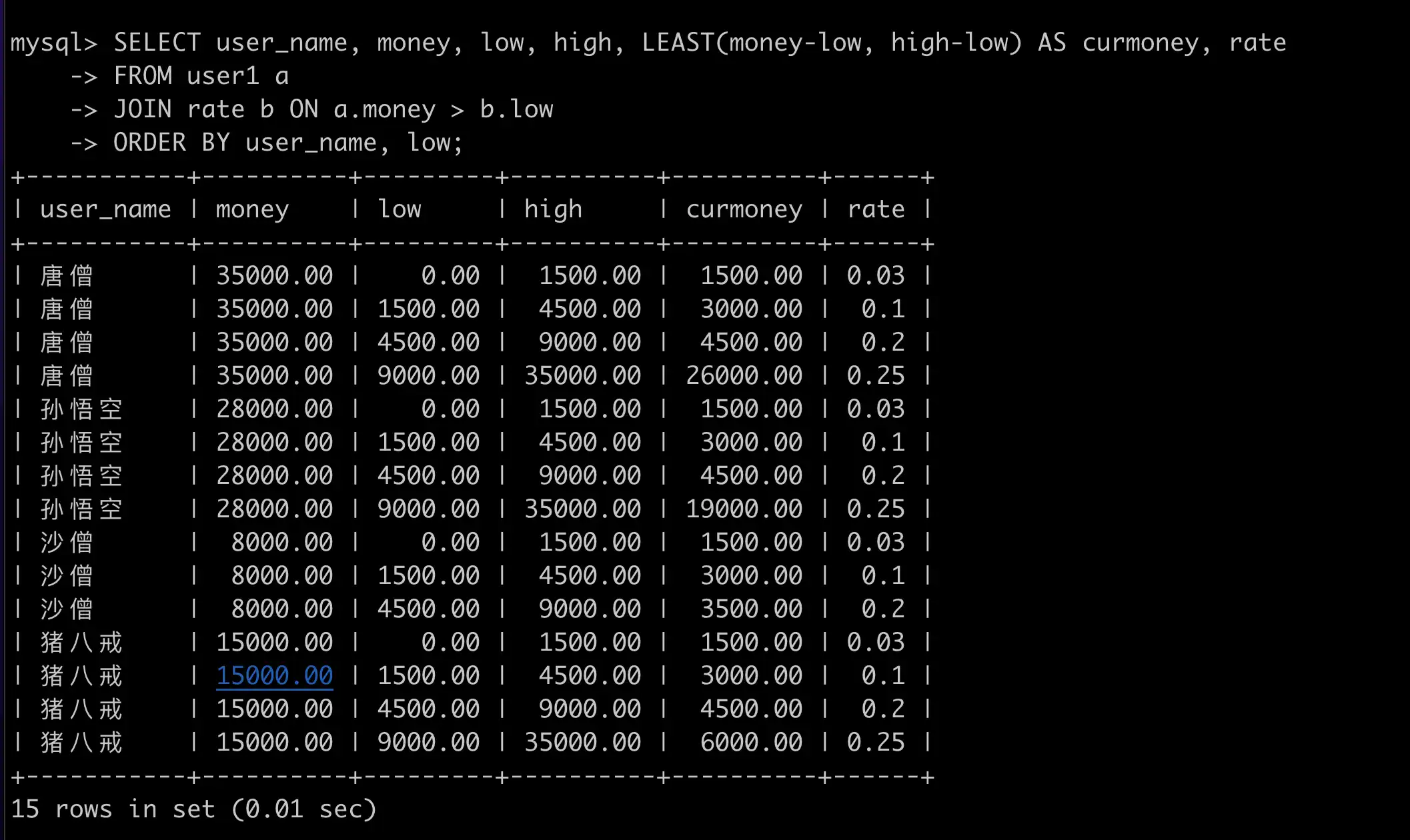
SELECT user_name, money, low, high, LEAST(money-low, high-low) AS curmoney, rate
FROM user1 a
JOIN rate b ON a.money > b.low
ORDER BY user_name, low;
2
3
4
SELECT user_name, sum(curmoney * rate)
FROM (
SELECT user_name, money, low, high, LEAST(money-low, high-low) AS curmoney, rate
FROM user1 a
JOIN rate b ON a.money > b.low
) AS a
GROUP BY user_name;
2
3
4
5
6
7