 Redis入门 - 概念和基础
Redis入门 - 概念和基础
# Redis入门 - 概念和基础
# 什么是Redis
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
# 官方资料
Redis官网: http://redis.io/
Redis官方文档: http://redis.io/documentation
Redis教程: http://www.w3cschool.cn/redis/redis-intro.html
Redis下载: http://redis.io/download
# 为什么要使用Redis
一个产品的使用场景肯定是需要根据产品的特性,先列举一下Redis的特点:
- 读写性能优异
- Redis能读的速度是110000次/s,写的速度是81000次/s (测试条件见下一节)。
- 数据类型丰富
- Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性
- Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性
- Redis支持 publish/subscribe, 通知, key 过期等特性。
- 持久化
- Redis支持RDB, AOF等持久化方式
- 发布订阅
- Redis支持发布/订阅模式
- 分布式
- Redis Cluster
(PS: 具体再结合下面的使用场景理解下)
下面是官方的bench-mark根据如下条件获得的性能测试(读的速度是110000次/s,写的速度是81000次/s)
- 测试完成了50个并发执行100000个请求。
- 设置和获取的值是一个256字节字符串。
- Linux box是运行Linux 2.6,这是X3320 Xeon 2.5 ghz。
- 文本执行使用loopback接口(127.0.0.1)。
# Redis为什么用单线程
Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。所以,严格来说,Redis 并不是单线程,但是我们一般把 Redis 称为单线程高性能,这样显得“酷”些。
如果采用多线程编程模式,需面临共享资源的并发访问控制问题。如Redis中的List数据类型,有两个线程A和B,线程 A 对一个 List 做 LPUSH 操作,并对队列长度加 1。同时,线程 B 对该 List 执行 LPOP 操作,并对队列长度减 1。为了保证队列长度的正确性,Redis 需要让线程 A 和 B 的 LPUSH 和 LPOP 串行执行,这样一来,Redis 可以无误地记录它们对 List 长度的修改。否则,我们可能就会得到错误的长度结果。
而且,采用多线程开发一般会引入同步原语来保护共享资源的并发访问,这也会降低系统代码的易调试性和可维护性。为了避免这些问题,Redis 直接采用了单线程模式。
# 单线程Redis为什么那么快
通常来说,单线程的处理能力要比多线程差很多,但是 Redis 却能使用单线程模型达到每秒数十万级别的处理能力。一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。
# 多路复用机制
基本 IO 模型与阻塞点
以 Get 请求为例,SimpleKV 为了处理一个 Get 请求,需要监听客户端请求(bind/listen),和客户端建立连接(accept),从 socket 中读取请求(recv),解析客户端发送请求(parse),根据请求类型读取键值数据(get),最后给客户端返回结果,即向 socket 中写回数据(send)。
下图显示了这一过程,其中,bind/listen、accept、recv、parse 和 send 属于网络 IO 处理,而 get 属于键值数据操作。既然 Redis 是单线程,那么,最基本的一种实现是在一个线程中依次执行上面说的这些操作。
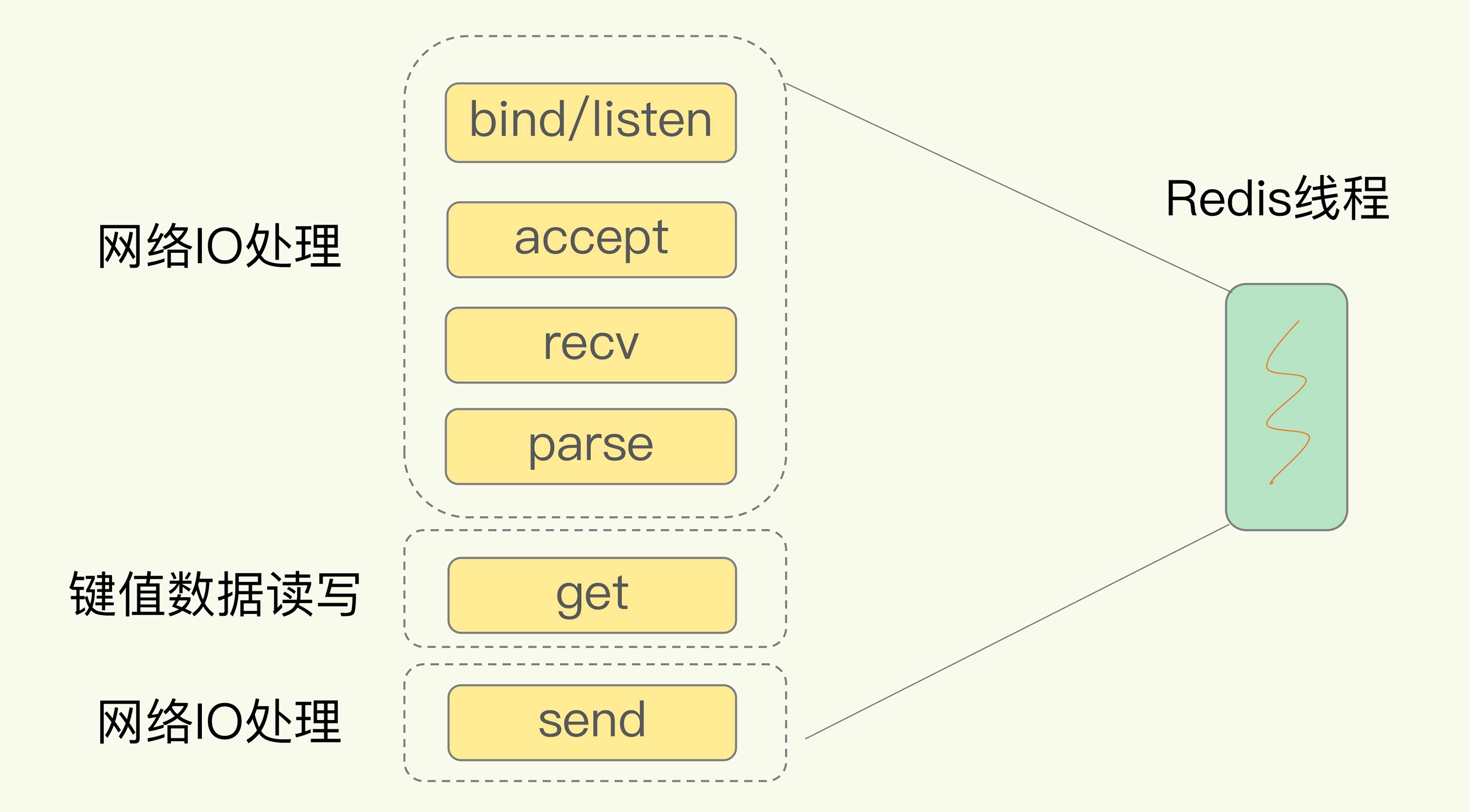
但是,在这里的网络 IO 操作中,有潜在的阻塞点,分别是 accept() 和 recv()。当 Redis 监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在 accept() 函数这里,导致其他客户端无法和 Redis 建立连接。类似的,当 Redis 通过 recv() 从一个客户端读取数据时,如果数据一直没有到达,Redis 也会一直阻塞在 recv()。
这就导致 Redis 整个线程阻塞,无法处理其他客户端请求,效率很低。不过,幸运的是,socket 网络模型本身支持非阻塞模式。
非阻塞模式
Socket 网络模型的非阻塞模式设置,主要体现在三个关键的函数调用上,如果想要使用 socket 非阻塞模式,就必须要了解这三个函数的调用返回类型和设置模式。
在 socket 模型中,不同操作调用后会返回不同的套接字类型。socket() 方法会返回主动套接字,然后调用 listen() 方法,将主动套接字转化为监听套接字,此时,可以监听来自客户端的连接请求。最后,调用 accept() 方法接收到达的客户端连接,并返回已连接套接字。

针对监听套接字,我们可以设置非阻塞模式:当 Redis 调用 accept() 但一直未有连接请求到达时,Redis 线程可以返回处理其他操作,而不用一直等待。但是,你要注意的是,调用 accept() 时,已经存在监听套接字了。
虽然 Redis 线程可以不用继续等待,但是总得有机制继续在监听套接字上等待后续连接请求,并在有请求时通知 Redis。
类似的,我们也可以针对已连接套接字设置非阻塞模式:Redis 调用 recv() 后,如果已连接套接字上一直没有数据到达,Redis 线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知 Redis。
这样才能保证 Redis 线程,既不会像基本 IO 模型中一直在阻塞点等待,也不会导致 Redis 无法处理实际到达的连接请求或数据。
基于多路复用的高性能 I/O 模型
Linux 中的 IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
下图就是基于多路复用的 Redis IO 模型。图中的多个 FD 就是刚才所说的多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。此时,Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。
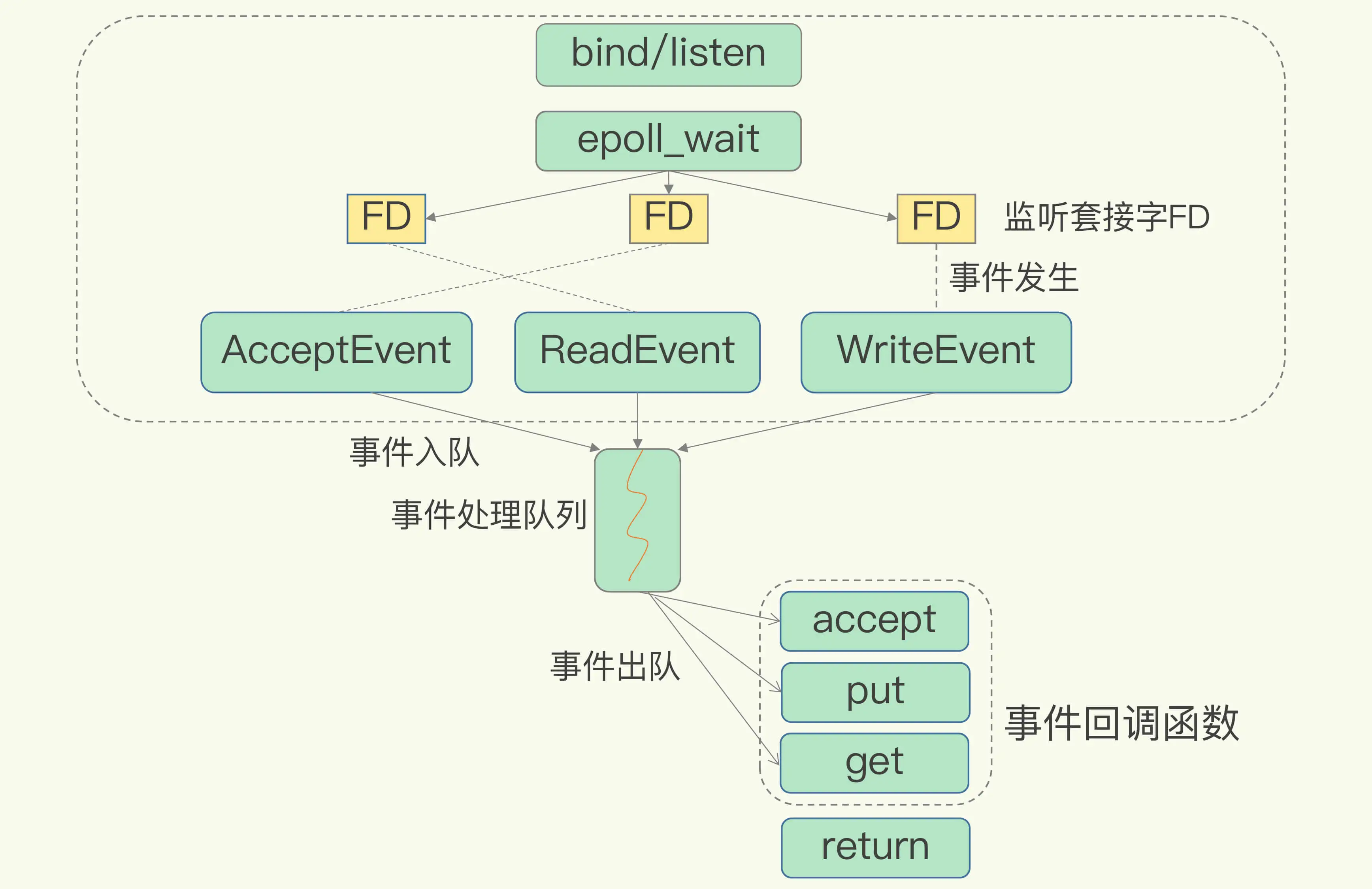
为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
回调机制是怎么工作的呢?其实,select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
以连接请求和读数据请求为例:这两个请求分别对应 Accept 事件和 Read 事件,Redis 分别对这两个事件注册 accept 和 get 回调函数。当 Linux 内核监听到有连接请求或读数据请求时,就会触发 Accept 事件和 Read 事件,此时,内核就会回调 Redis 相应的 accept 和 get 函数进行处理。
# Redis的使用场景
redis应用场景总结redis平时我们用到的地方蛮多的,下面就了解的应用场景做个总结:
# 热点数据的缓存
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且 Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
作为缓存使用时,一般有两种方式保存数据:
- 读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis。
- 插入数据时,同时写入Redis。
方案一:实施起来简单,但是有两个需要注意的地方:
- 避免缓存击穿。(数据库没有就需要命中的数据,导致Redis一直没有数据,而一直命中数据库。)
- 数据的实时性相对会差一点。
方案二:数据实时性强,但是开发时不便于统一处理。
当然,两种方式根据实际情况来适用。如:方案一适用于对于数据实时性要求不是特别高的场景。方案二适用于字典表、数据量不大的数据存储。
# 限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
# 计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
# 分布式锁
这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在很多后台中都有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先通过setnx设置一个lock, 如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
在分布式锁的场景中,主要用在比如秒杀系统等。
# 延时操作
比如在订单生产后我们占用了库存,10分钟后去检验用户是否真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。
当然我们也可以利用RabbitMQ、ActiveMQ等消息中间件的延迟队列服务实现该需求。
# 排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
比如点赞排行榜,做一个SortedSet, 然后以用户的openid作为上面的username, 以用户的点赞数作为上面的score, 然后针对每个用户做一个hash, 通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的。
# 点赞、好友等相互关系的存储
Redis 利用集合的一些命令,比如求交集、并集、差集等。
在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
# 简单队列
由于Redis有list push和list pop这样的命令,所以能够很方便的执行队列操作。
# 参考文章
- https://baike.baidu.com/item/Redis/6549233?fr=aladdin
- https://zhuanlan.zhihu.com/p/29665317
- https://www.jianshu.com/p/40dbc78711c8
- https://pdai.tech/md/db/nosql-redis/db-redis-introduce.html