 Java 业务开发常见错误(一)
Java 业务开发常见错误(一)
# Java 业务开发常见错误(一)
# 并发工具类
为了方便开发者进行多线程编程,现代编程语言会提供各种并发工具类。如果没有充分了解它们的使用场景、解决的问题,以及最佳实践的话,盲目使用就可能会导致一些坑,小则损失性能,大则无法确保多线程情况下业务逻辑的正确性。
# ThreadLocal
ThreadLocal 适用于变量在线程间隔离,而在方法或类间共享的场景。但不正确使用可能会出现用户信息错乱的 Bug。
案例:使用 Spring Boot 创建一个 Web 应用程序,使用 ThreadLocal 存放一个 Integer 的值,来暂且代表需要在线程中保存的用户信息,这个值初始是 null。在业务逻辑中,我先从 ThreadLocal 获取一次值,然后把外部传入的参数设置到 ThreadLocal 中,来模拟从当前上下文获取到用户信息的逻辑,随后再获取一次值,最后输出两次获得的值和线程名称。
private static final ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map wrong(@RequestParam("userId") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
//设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
按理说,在设置用户信息之前第一次获取的值始终应该是 null,但我们要意识到,程序运行在 Tomcat 中,执行程序的线程是 Tomcat 的工作线程,而 Tomcat 的工作线程是基于线程池的。
顾名思义,线程池会重用固定的几个线程,一旦线程重用,那么很可能首次从 ThreadLocal 获取的值是之前其他用户的请求遗留的值。这时,ThreadLocal 中的用户信息就是其他用户的信息。
为了更快地重现这个问题,在配置文件中设置一下 Tomcat 的参数,把工作线程池最大线程数设置为 1,这样始终是同一个线程在处理请求:
server.tomcat.max-threads=1
运行程序后先让用户 1 来请求接口,可以看到第一和第二次获取到用户 ID 分别是 null 和 1,符合预期:
{"before":"http-nio-8111-exec-1:null","after":"http-nio-8111-exec-1:1"}
随后用户 2 来请求接口,这次就出现了 Bug,第一和第二次获取到用户 ID 分别是 1 和 2,显然第一次获取到了用户 1 的信息,原因就是 Tomcat 的线程池重用了线程。从图中可以看到,两次请求的线程都是同一个线程:http-nio-8111-exec-1。
{"before":"http-nio-8111-exec-1:1","after":"http-nio-8111-exec-1:2"}
这个例子告诉我们,在写业务代码时,首先要理解代码会跑在什么线程上:
- 我们可能会抱怨学多线程没用,因为代码里没有开启使用多线程。但其实,可能只是我们没有意识到,在 Tomcat 这种 Web 服务器下跑的业务代码,本来就运行在一个多线程环境(否则接口也不可能支持这么高的并发),并不能认为没有显式开启多线程就不会有线程安全问题。
- 因为线程的创建比较昂贵,所以 Web 服务器往往会使用线程池来处理请求,这就意味着线程会被重用。这时,使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据。如果在代码中使用了自定义的线程池,也同样会遇到这个问题。
所以修正这段代码的方案是,在代码的 finally 代码块中,显式清除 ThreadLocal 中的数据。这样一来,新的请求过来即使使用了之前的线程也不会获取到错误的用户信息了。修正后的代码如下:
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
重新运行程序可以验证,再也不会出现第一次查询用户信息查询到之前用户请求的 Bug:
{"before":"http-nio-8111-exec-1:null","after":"http-nio-8111-exec-1:2"}
# ConcurrentHashMap
JDK 1.5 后推出的 ConcurrentHashMap,是一个高性能的线程安全的哈希表容器。“线程安全”这四个字特别容易让人误解,因为 ConcurrentHashMap 只能保证提供的原子性读写操作是线程安全的。
案例:有一个含 900 个元素的 Map,现在再补充 100 个元素进去,这个补充操作由 10 个线程并发进行。开发人员误以为使用了 ConcurrentHashMap 就不会有线程安全问题,于是不加思索地写出了下面的代码:在每一个线程的代码逻辑中先通过 size 方法拿到当前元素数量,计算 ConcurrentHashMap 目前还需要补充多少元素,并在日志中输出了这个值,然后通过 putAll 方法把缺少的元素添加进去。
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
//帮助方法,用来获得一个指定元素数量模拟数据的ConcurrentHashMap
private ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(Collectors.toConcurrentMap(i -> UUID.randomUUID().toString(), Function.identity(),
(o1, o2) -> o1, ConcurrentHashMap::new));
}
@GetMapping("wrong")
public String wrong() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}", gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
log.info("finish size:{}", concurrentHashMap.size());
return "OK";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
输出结果如下:
20:06:55 [http-nio-8888-exec-2] INFO DemoController - init size:900
20:06:55 [ForkJoinPool-2-worker-9] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-4] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-11] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-6] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-15] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-8] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-13] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-1] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-2] INFO DemoController - gap size:100
20:06:55 [ForkJoinPool-2-worker-10] INFO DemoController - gap size:100
20:06:55 [http-nio-8888-exec-2] INFO DemoController - finish size:1900
2
3
4
5
6
7
8
9
10
11
12
- 初始大小 900 符合预期,还需要填充 100 个元素。
- 最后 HashMap 的总项目数是 1900,显然不符合填充满 1000 的预期。
需要注意 ConcurrentHashMap 对外提供的方法或能力的限制:
- 使用了 ConcurrentHashMap,不代表对它的多个操作之间的状态是一致的,是没有其他线程在操作它的,如果需要确保需要手动加锁。
- 诸如 size、isEmpty 和 containsValue 等聚合方法,在并发情况下可能会反映 ConcurrentHashMap 的中间状态。因此在并发情况下,这些方法的返回值只能用作参考,而不能用于流程控制。显然,利用 size 方法计算差异值,是一个流程控制。
- 诸如 putAll 这样的聚合方法也不能确保原子性,在 putAll 的过程中去获取数据可能会获取到部分数据。
代码的修改方案很简单,整段逻辑加锁即可:
@GetMapping("right")
public String right() throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
log.info("init size:{}", concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//下面的这段复合逻辑需要锁一下这个ConcurrentHashMap
synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
log.info("gap size:{}", gap);
concurrentHashMap.putAll(getData(gap));
}
}));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
log.info("finish size:{}", concurrentHashMap.size());
return "OK";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
重新调用接口,程序的日志输出结果符合预期:
20:15:47 [http-nio-8888-exec-1] INFO DemoController - init size:900
20:15:47 [ForkJoinPool-1-worker-9] INFO DemoController - gap size:100
20:15:47 [ForkJoinPool-1-worker-10] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-2] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-8] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-15] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-11] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-1] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-4] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-6] INFO DemoController - gap size:0
20:15:47 [ForkJoinPool-1-worker-13] INFO DemoController - gap size:0
20:15:47 [http-nio-8888-exec-1] INFO DemoController - finish size:1000
2
3
4
5
6
7
8
9
10
11
12
可以看到,只有一个线程查询到了需要补 100 个元素,其他 9 个线程查询到不需要补元素,最后 Map 大小为 1000。
ConcurrentHashMap 全程加锁,是否还不如使用普通的 HashMap?其实不完全是这样。
ConcurrentHashMap 提供了一些原子性的简单复合逻辑方法,用好这些方法就可以发挥其威力。这就引申出代码中常见的另一个问题:在使用一些类库提供的高级工具类时,开发人员可能还是按照旧的方式去使用这些新类,因为没有使用其特性,所以无法发挥其威力。
案例:使用 Map 来统计 Key 出现次数的场景,这个逻辑在业务代码中非常常见。
- 使用 ConcurrentHashMap 来统计,Key 的范围是 10。
- 使用最多 10 个并发,循环操作 1000 万次,每次操作累加随机的 Key。
- 如果 Key 不存在的话,首次设置值为 1。
代码如下:
//循环次数
private static int LOOP_COUNT = 10000000;
//线程数量
private static int THREAD_COUNT = 10;
//元素数量
private static int ITEM_COUNT = 10;
private Map<String, Long> normaluse() throws InterruptedException {
ConcurrentHashMap<String, Long> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
//获得一个随机的Key
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
synchronized (freqs) {
if (freqs.containsKey(key)) {
//Key存在则+1
freqs.put(key, freqs.get(key) + 1);
} else {
//Key不存在则初始化为1
freqs.put(key, 1L);
}
}
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return freqs;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
吸取之前的教训,直接通过锁的方式锁住 Map,然后做判断、读取现在的累计值、加 1、保存累加后值的逻辑。这段代码在功能上没有问题,但无法充分发挥 ConcurrentHashMap 的威力,改进后的代码如下:
private Map<String, Long> gooduse() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
//利用computeIfAbsent()方法来实例化LongAdder,然后利用LongAdder来进行线程安全计数
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//因为我们的Value是LongAdder而不是Long,所以需要做一次转换才能返回
return freqs.entrySet().stream()
.collect(Collectors.toMap(
e -> e.getKey(),
e -> e.getValue().longValue())
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
在这段改进后的代码中,我们巧妙利用了下面两点:
- 使用 ConcurrentHashMap 的原子性方法 computeIfAbsent 来做复合逻辑操作,判断 Key 是否存在 Value,如果不存在则把 Lambda 表达式运行后的结果放入 Map 作为 Value,也就是新创建一个 LongAdder 对象,最后返回 Value。
- 由于 computeIfAbsent 方法返回的 Value 是 LongAdder,是一个线程安全的累加器,因此可以直接调用其 increment 方法进行累加。
这样在确保线程安全的情况下达到极致性能,把之前 7 行代码替换为了 1 行。通过一个简单的测试比较一下修改前后两段代码的性能:
@GetMapping("good")
public String good() throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("normaluse");
Map<String, Long> normaluse = normaluse();
stopWatch.stop();
//校验元素数量
Assert.isTrue(normaluse.size() == ITEM_COUNT, "normaluse size error");
//校验累计总数
Assert.isTrue(normaluse.entrySet().stream()
.mapToLong(item -> item.getValue()).reduce(0, Long::sum) == LOOP_COUNT
, "normaluse count error");
stopWatch.start("gooduse");
Map<String, Long> gooduse = gooduse();
stopWatch.stop();
Assert.isTrue(gooduse.size() == ITEM_COUNT, "gooduse size error");
Assert.isTrue(gooduse.entrySet().stream()
.mapToLong(item -> item.getValue())
.reduce(0, Long::sum) == LOOP_COUNT
, "gooduse count error");
log.info(stopWatch.prettyPrint());
return "OK";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这段测试代码并无特殊之处,使用 StopWatch 来测试两段代码的性能,最后跟了一个断言判断 Map 中元素的个数以及所有 Value 的和,是否符合预期来校验代码的正确性。测试结果如下:
---------------------------------------------
ns % Task name
---------------------------------------------
4312719272 082% normaluse
942867963 018% gooduse
2
3
4
5
可以看到,优化后的代码,相比使用锁来操作 ConcurrentHashMap 的方式,性能提升近 5 倍。
那么 computeIfAbsent 为什么如此高效呢?答案就在源码最核心的部分,也就是 Java 自带的 Unsafe 实现的 CAS。它在虚拟机层面确保了写入数据的原子性,比加锁的效率高得多:
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
2
3
4
像 ConcurrentHashMap 这样的高级并发工具的确提供了一些高级 API,只有充分了解其特性才能最大化其威力,而不能因为其足够高级、酷炫盲目使用。
# CopyOnWriteArrayList
案例:使用 CopyOnWriteArrayList 来缓存大量的数据,而数据变化又比较频繁。
CopyOnWrite 是一个时髦的技术,不管是 Linux 还是 Redis 都会用到。在 Java 中,CopyOnWriteArrayList 虽然是一个线程安全的 ArrayList,但因为其实现方式是,每次修改数据时都会复制一份数据出来,所以有明显的适用场景,即读多写少或者说希望无锁读的场景。
如果我们要使用 CopyOnWriteArrayList,那一定是因为场景需要而不是因为足够酷炫。如果读写比例均衡或者有大量写操作的话,使用 CopyOnWriteArrayList 的性能会非常糟糕。
写一段测试代码,来比较下使用 CopyOnWriteArrayList 和普通加锁方式 ArrayList 的读写性能吧。在这段代码中我们针对并发读和并发写分别写了一个测试方法,测试两者一定次数的写或读操作的耗时。
//测试并发写的性能
@GetMapping("write")
public Map testWrite() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount = 100000;
stopWatch.start("Write:copyOnWriteArrayList");
//循环100000次并发往CopyOnWriteArrayList写入随机元素
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
stopWatch.start("Write:synchronizedList");
//循环100000次并发往加锁的ArrayList写入随机元素
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
//帮助方法用来填充List
private void addAll(List<Integer> list) {
list.addAll(IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
}
//测试并发读的性能
@GetMapping("read")
public Map testRead() {
//创建两个测试对象
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
//填充数据
addAll(copyOnWriteArrayList);
addAll(synchronizedList);
StopWatch stopWatch = new StopWatch();
int loopCount = 1000000;
int count = copyOnWriteArrayList.size();
stopWatch.start("Read:copyOnWriteArrayList");
//循环1000000次并发从CopyOnWriteArrayList随机查询元素
IntStream.rangeClosed(1, loopCount).parallel().forEach(__ -> copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
stopWatch.start("Read:synchronizedList");
//循环1000000次并发从加锁的ArrayList随机查询元素
IntStream.range(0, loopCount).parallel().forEach(__ -> synchronizedList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
运行程序可以看到,大量写的场景(10 万次 add 操作),CopyOnWriteArray 几乎比同步的 ArrayList 慢一百倍:
---------------------------------------------
ns % Task name
---------------------------------------------
3818454779 099% Write:copyOnWriteArrayList
041842974 001% Write:synchronizedList
2
3
4
5
而在大量读的场景下(100 万次 get 操作),CopyOnWriteArray 又比同步的 ArrayList 快十倍以上:
---------------------------------------------
ns % Task name
---------------------------------------------
019907729 006% Read:copyOnWriteArrayList
317417458 094% Read:synchronizedList
2
3
4
5
为何在大量写的场景下,CopyOnWriteArrayList 会这么慢呢?答案就在源码中。以 add 方法为例,每次 add 时,都会用 Arrays.copyOf 创建一个新数组,频繁 add 时内存的申请释放消耗会很大:
public boolean add(E e) {
synchronized (lock) {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
}
}
2
3
4
5
6
7
8
9
10
# 代码加锁
# 加锁前要清楚要保护的是什么逻辑
案例:在一个类里有两个 int 类型的字段 a 和 b,有一个 add 方法循环 1 万次对 a 和 b 进行 ++ 操作,有另一个 compare 方法,同样循环 1 万次判断 a 是否小于 b,条件成立就打印 a 和 b 的值,并判断 a>b 是否成立。
@Slf4j
public class Interesting {
volatile int a = 1;
volatile int b = 1;
public void add() {
log.info("add start");
for (int i = 0; i < 10000; i++) {
a++;
b++;
}
log.info("add done");
}
public void compare() {
log.info("compare start");
for (int i = 0; i < 10000; i++) {
//a始终等于b吗?
if (a < b) {
log.info("a:{},b:{},{}", a, b, a > b);
//最后的a>b应该始终是false吗?
}
}
log.info("compare done");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
起了两个线程来分别执行 add 和 compare 方法:
Interesting interesting = new Interesting();
new Thread(() -> interesting.add()).start();
new Thread(() -> interesting.compare()).start();
2
3
按道理,a 和 b 同样进行累加操作,应该始终相等,compare 中的第一次判断应该始终不会成立,不会输出任何日志。但执行代码后发现不但输出了日志,而且更诡异的是,compare 方法在判断 a < b 成立的情况下还输出了 a>b 也成立:
14:41:34 [Thread-63] INFO Interesting - compare start
14:41:34 [Thread-62] INFO Interesting - add start
14:41:34 [Thread-63] INFO Interesting - a:74,b:94,false
14:41:34 [Thread-63] INFO Interesting - a:8600,b:8604,true
14:41:34 [Thread-62] INFO Interesting - add done
14:41:34 [Thread-63] INFO Interesting - compare done
2
3
4
5
6
之所以出现这种错乱,是因为两个线程是交错执行 add 和 compare 方法中的业务逻辑,而且这些业务逻辑不是原子性的:a++ 和 b++ 操作中可以穿插在 compare 方法的比较代码中;更需要注意的是,a<b 这种比较操作在字节码层面是加载 a、加载 b 和比较三步,代码虽然是一行但也不是原子性的。
所以,正确的做法应该是,为 add 和 compare 都加上方法锁,确保 add 方法执行时,compare 无法读取 a 和 b:
public synchronized void add()
public synchronized void compare()
2
# 加锁前要清楚锁和被保护的对象是不是一个层面的
还有一种比较常见的错误是,没有理清楚锁和要保护的对象是否是一个层面的。我们知道静态字段属于类,类级别的锁才能保护;而非静态字段属于类实例,实例级别的锁就可以保护。
案例:在类 Data 中定义了一个静态的 int 字段 counter 和一个非静态的 wrong 方法,实现 counter 字段的累加操作。
class Data {
@Getter
private static int counter = 0;
public static int reset() {
counter = 0;
return counter;
}
public synchronized void wrong() {
counter++;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
写一段代码测试下:
@GetMapping("wrong")
public int wrong(@RequestParam(value = "count", defaultValue = "1000000") int count) {
Data.reset();
//多线程循环一定次数调用Data类不同实例的wrong方法
IntStream.rangeClosed(1, count).parallel().forEach(i -> new Data().wrong());
return Data.getCounter();
}
2
3
4
5
6
7
因为默认运行 100 万次,所以执行后应该输出 100 万,但页面输出的是 250983:
{"code":200,"message":"SUCCESS","data":250983}%
原因:在非静态的 wrong 方法上加锁,只能确保多个线程无法执行同一个实例的 wrong 方法,却不能保证不会执行不同实例的 wrong 方法。而静态的 counter 在多个实例中共享,所以必然会出现线程安全问题。
理清思路后,修正方法就很清晰了:同样在类中定义一个 Object 类型的静态字段,在操作 counter 之前对这个字段加锁。
class Data {
@Getter
private static int counter = 0;
private static Object locker = new Object();
public void right() {
synchronized (locker) {
counter++;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
疑问:把 wrong 方法定义为静态不就可以了,这个时候锁是类级别的。可以是可以,但我们不可能为了解决线程安全问题改变代码结构,把实例方法改为静态方法。
# 加锁要考虑锁的粒度和场景问题
在方法上加 synchronized 关键字实现加锁确实简单,也因此我曾看到一些业务代码中几乎所有方法都加了 synchronized,但这种滥用 synchronized 的做法:
- 没必要。通常情况下 60% 的业务代码是三层架构,数据经过无状态的 Controller、Service、Repository 流转到数据库,没必要使用 synchronized 来保护什么数据。
- 可能会极大地降低性能。使用 Spring 框架时,默认情况下 Controller、Service、Repository 是单例的,加上 synchronized 会导致整个程序几乎就只能支持单线程,造成极大的性能问题。
即使我们确实有一些共享资源需要保护,也要尽可能降低锁的粒度,仅对必要的代码块甚至是需要保护的资源本身加锁。
案例:在业务代码中,有一个 ArrayList 因为会被多个线程操作而需要保护,又有一段比较耗时的操作(代码中的 slow 方法)不涉及线程安全问题,应该如何加锁呢?错误的做法是,给整段业务逻辑加锁,把 slow 方法和操作 ArrayList 的代码同时纳入 synchronized 代码块;更合适的做法是,把加锁的粒度降到最低,只在操作 ArrayList 的时候给这个 ArrayList 加锁。
private List<Integer> data = new ArrayList<>();
//不涉及共享资源的慢方法
private void slow() {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
}
}
//错误的加锁方法
@GetMapping("wrong")
public int wrong() {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {
//加锁粒度太粗了
synchronized (this) {
slow();
data.add(i);
}
});
log.info("took:{}", System.currentTimeMillis() - begin);
return data.size();
}
//正确的加锁方法
@GetMapping("right")
public int right() {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {
slow();
//只对List加锁
synchronized (data) {
data.add(i);
}
});
log.info("took:{}", System.currentTimeMillis() - begin);
return data.size();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
执行这段代码,同样是 1000 次业务操作,正确加锁的版本耗时 1.4 秒,而对整个业务逻辑加锁的话耗时 11 秒。
15:03:41 [http-nio-8888-exec-1] INFO DemoController - took:11300
15:04:08 [http-nio-8888-exec-2] INFO DemoController - took:1414
2
如果精细化考虑了锁应用范围后,性能还无法满足需求的话,我们就要考虑另一个维度的粒度问题了,即:区分读写场景以及资源的访问冲突,考虑使用悲观方式的锁还是乐观方式的锁。
一般业务代码中,很少需要进一步考虑这两种更细粒度的锁,所以只分享几个大概的结论,可以根据自己的需求来考虑是否有必要进一步优化:
- 对于读写比例差异明显的场景,考虑使用 ReentrantReadWriteLock 细化区分读写锁,来提高性能。
- 如果 JDK 版本高于 1.8、共享资源的冲突概率也没那么大的话,考虑使用 StampedLock 的乐观读的特性,进一步提高性能。
- JDK 里 ReentrantLock 和 ReentrantReadWriteLock 都提供了公平锁的版本,在没有明确需求的情况下不要轻易开启公平锁特性,在任务很轻的情况下开启公平锁可能会让性能下降上百倍。
# 多把锁要小心死锁问题
一个业务逻辑如果涉及多把锁,容易产生死锁问题。
案例:下单操作需要锁定订单中多个商品的库存,拿到所有商品的锁之后进行下单扣减库存操作,全部操作完成之后释放所有的锁。代码上线后发现,下单失败概率很高,失败后需要用户重新下单,极大影响了用户体验,还影响到了销量。经排查发现是死锁引起的问题,背后原因是扣减库存的顺序不同,导致并发的情况下多个线程可能相互持有部分商品的锁,又等待其他线程释放另一部分商品的锁,于是出现了死锁问题。
首先,定义一个商品类型,包含商品名、库存剩余和商品的库存锁三个属性,每一种商品默认库存 1000 个;然后,初始化 10 个这样的商品对象来模拟商品清单:
@Data
@RequiredArgsConstructor
static class Item {
final String name; //商品名
int remaining = 1000; //库存剩余
@ToString.Exclude //ToString不包含这个字段
ReentrantLock lock = new ReentrantLock();
}
2
3
4
5
6
7
8
随后,写一个方法模拟在购物车进行商品选购,每次从商品清单(items 字段)中随机选购三个商品(为了逻辑简单,不考虑每次选购多个同类商品的逻辑,购物车中不体现商品数量):
private List<Item> createCart() {
return IntStream.rangeClosed(1, 3)
.mapToObj(i -> "item" + ThreadLocalRandom.current().nextInt(items.size()))
.map(name -> items.get(name)).collect(Collectors.toList());
}
2
3
4
5
下单代码如下:先声明一个 List 来保存所有获得的锁,然后遍历购物车中的商品依次尝试获得商品的锁,最长等待 10 秒,获得全部锁之后再扣减库存;如果有无法获得锁的情况则解锁之前获得的所有锁,返回 false 下单失败。
private boolean createOrder(List<Item> order) {
//存放所有获得的锁
List<ReentrantLock> locks = new ArrayList<>();
for (Item item : order) {
try {
//获得锁10秒超时
if (item.lock.tryLock(10, TimeUnit.SECONDS)) {
locks.add(item.lock);
} else {
locks.forEach(ReentrantLock::unlock);
return false;
}
} catch (InterruptedException e) {
}
}
//锁全部拿到之后执行扣减库存业务逻辑
try {
order.forEach(item -> item.remaining--);
} finally {
locks.forEach(ReentrantLock::unlock);
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
我们写一段代码测试这个下单操作。模拟在多线程情况下进行 100 次创建购物车和下单操作,最后通过日志输出成功的下单次数、总剩余的商品个数、100 次下单耗时,以及下单完成后的商品库存明细:
@GetMapping("wrong")
public long wrong() {
long begin = System.currentTimeMillis();
//并发进行100次下单操作,统计成功次数
long success = IntStream.rangeClosed(1, 100).parallel()
.mapToObj(i -> {
List<Item> cart = createCart();
return createOrder(cart);
})
.filter(result -> result)
.count();
log.info("success:{} totalRemaining:{} took:{}ms items:{}",
success,
items.entrySet().stream().map(item -> item.getValue().remaining).reduce(0, Integer::sum),
System.currentTimeMillis() - begin, items);
return success;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
运行程序,输出如下日志:

可以看到,100 次下单操作成功了 65 次,10 种商品总计 10000 件,库存总计为 9805,消耗了 195 件符合预期(65 次下单成功,每次下单包含三件商品),总耗时 50 秒。
使用 JDK 自带的 VisualVM 工具来跟踪一下,重新执行方法后不久就可以看到,线程 Tab 中提示了死锁问题,根据提示点击右侧线程 Dump 按钮进行线程抓取操作:

查看抓取出的线程栈,在页面中部可以看到如下日志:
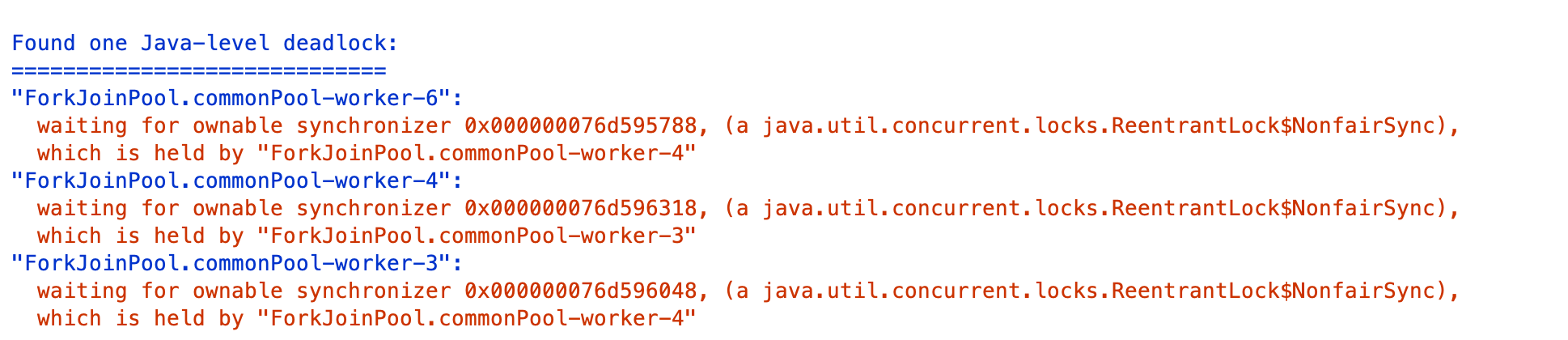
显然,是出现了死锁,线程 4 在等待的一个锁被线程 3 持有,线程 3 在等待的另一把锁被线程 4 持有。
回忆一下购物车添加商品的逻辑,随机添加了三种商品,假设一个购物车中的商品是 item1 和 item2,另一个购物车中的商品是 item2 和 item1,一个线程先获取到了 item1 的锁,同时另一个线程获取到了 item2 的锁,然后两个线程接下来要分别获取 item2 和 item1 的锁,这个时候锁已经被对方获取了,只能相互等待一直到 10 秒超时。
其实,避免死锁的方案很简单,为购物车中的商品排一下序,让所有的线程一定是先获取 item1 的锁然后获取 item2 的锁,就不会有问题了。所以只需要修改一行代码,对 createCart 获得的购物车按照商品名进行排序即可:
@GetMapping("right")
public long right() {
...
long success = IntStream.rangeClosed(1, 100).parallel()
.mapToObj(i -> {
List<Item> cart = createCart().stream()
.sorted(Comparator.comparing(Item::getName))
.collect(Collectors.toList());
return createOrder(cart);
})
.filter(result -> result)
.count();
...
return success;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
测试一下 right 方法,不管执行多少次都是 100 次成功下单,而且性能相当高,达到了 3000 以上的 TPS:
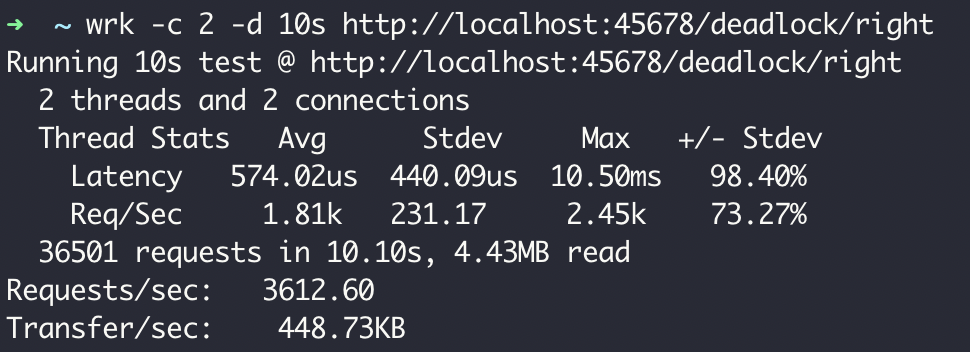
这个案例中,虽然产生了死锁问题,但因为尝试获取锁的操作并不是无限阻塞的,所以没有造成永久死锁,之后的改进就是避免循环等待,通过对购物车的商品进行排序来实现有顺序的加锁,避免循环等待。
# 线程池
在程序中会用各种池化技术来缓存创建昂贵的对象,比如线程池、连接池、内存池。一般是预先创建一些对象放入池中,使用的时候直接取出使用,用完归还以便复用,还会通过一定的策略调整池中缓存对象的数量,实现池的动态伸缩。
由于线程的创建比较昂贵,随意、没有控制地创建大量线程会造成性能问题,因此短平快的任务一般考虑使用线程池来处理,而不是直接创建线程。
# 建议手动创建线程池
Java 中的 Executors 类定义了一些快捷的工具方法,来帮助我们快速创建线程池。《阿里巴巴 Java 开发手册》中提到,禁止使用这些方法来创建线程池,而应该手动 new ThreadPoolExecutor 来创建线程池。这一条规则的背后,是大量血淋淋的生产事故,最典型的就是 newFixedThreadPool 和 newCachedThreadPool,可能因为资源耗尽导致 OOM 问题。
案例:写一段测试代码,来初始化一个单线程的 FixedThreadPool,循环 1 亿次向线程池提交任务,每个任务都会创建一个比较大的字符串然后休眠一小时:
@GetMapping("oom1")
public void oom1() throws InterruptedException {
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
//打印线程池的信息,稍后我会解释这段代码
printStats(threadPool);
for (int i = 0; i < 100000000; i++) {
threadPool.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
}
log.info(payload);
});
}
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
执行程序后不久,日志中就出现了如下 OOM:
Exception in thread "http-nio-45678-ClientPoller" java.lang.OutOfMemoryError: GC overhead limit exceeded
翻看 newFixedThreadPool 方法的源码不难发现,线程池的工作队列直接 new 了一个 LinkedBlockingQueue,而默认构造方法的 LinkedBlockingQueue 是一个 Integer.MAX_VALUE 长度的队列,可以认为是无界的:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
...
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
虽然使用 newFixedThreadPool 可以把工作线程控制在固定的数量上,但任务队列是无界的。如果任务较多并且执行较慢的话,队列可能会快速积压,撑爆内存导致 OOM。
再把刚才的例子稍微改一下,改为使用 newCachedThreadPool 方法来获得线程池。程序运行不久后,同样看到了如下 OOM 异常:
[11:30:30.487] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: unable to create new native thread] with root cause
java.lang.OutOfMemoryError: unable to create new native thread
2
从日志中可以看到,这次 OOM 的原因是无法创建线程,翻看 newCachedThreadPool 的源码可以看到,这种线程池的最大线程数是 Integer.MAX_VALUE,可以认为是没有上限的,而其工作队列 SynchronousQueue 是一个没有存储空间的阻塞队列。这意味着,只要有请求到来,就必须找到一条工作线程来处理,如果当前没有空闲的线程就再创建一条新的。
由于任务需要 1 小时才能执行完成,大量的任务进来后会创建大量的线程。而线程是需要分配一定的内存空间作为线程栈的,比如 1MB,因此无限制创建线程必然会导致 OOM:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
2
3
4
其实,大部分 Java 开发同学知道这两种线程池的特性,只是抱有侥幸心理,觉得只是使用线程池做一些轻量级的任务,不可能造成队列积压或开启大量线程。
但现实往往是残酷的。如用户注册后调用一个外部服务去发送短信,发送短信接口正常时可以在 100 毫秒内响应,TPS 100 的注册量,CachedThreadPool 能稳定在占用 10 个左右线程的情况下满足需求。在某个时间点,外部短信服务不可用了,我们调用这个服务的超时又特别长,比如 1 分钟,1 分钟可能就进来了 6000 用户,产生 6000 个发送短信的任务,需要 6000 个线程,没多久就因为无法创建线程导致了 OOM,整个应用程序崩溃。
因此不建议使用 Executors 提供的两种快捷的线程池,原因如下:
- 我们需要根据自己的场景、并发情况来评估线程池的几个核心参数,包括核心线程数、最大线程数、线程回收策略、工作队列的类型,以及拒绝策略,确保线程池的工作行为符合需求,一般都需要设置有界的工作队列和可控的线程数。
- 任何时候,都应该为自定义线程池指定有意义的名称,以方便排查问题。当出现线程数量暴增、线程死锁、线程占用大量 CPU、线程执行出现异常等问题时,我们往往会抓取线程栈。此时,有意义的线程名称,就可以方便我们定位问题。
除了建议手动声明线程池以外,还建议用一些监控手段来观察线程池的状态。线程池这个组件往往会表现得任劳任怨、默默无闻,除非是出现了拒绝策略,否则压力再大都不会抛出一个异常。如果我们能提前观察到线程池队列的积压,或者线程数量的快速膨胀,往往可以提早发现并解决问题。
# 线程池线程管理策略
可以用一个 printStats 方法实现了最简陋的监控,每秒输出一次线程池的基本内部信息,包括线程数、活跃线程数、完成了多少任务,以及队列中还有多少积压任务等信息:
private void printStats(ThreadPoolExecutor threadPool) {
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("=========================");
log.info("Pool Size: {}", threadPool.getPoolSize());
log.info("Active Threads: {}", threadPool.getActiveCount());
log.info("Number of Tasks Completed: {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}
2
3
4
5
6
7
8
9
10
11
线程池默认的工作行为:
- 不会初始化 corePoolSize 个线程,有任务来了才创建工作线程;
- 当核心线程满了之后不会立即扩容线程池,而是把任务堆积到工作队列中;
- 当工作队列满了后扩容线程池,一直到线程个数达到 maximumPoolSize 为止;
- 如果队列已满且达到了最大线程后还有任务进来,按照拒绝策略处理;
- 当线程数大于核心线程数时,线程等待 keepAliveTime 后还是没有任务需要处理的话,收缩线程到核心线程数。
可以通过一些手段来改变这些默认工作行为,比如:
- 声明线程池后立即调用 prestartAllCoreThreads 方法,来启动所有核心线程;
- 传入 true 给 allowCoreThreadTimeOut 方法,来让线程池在空闲的时候同样回收核心线程。
不知道你有没有想过:Java 线程池是先用工作队列来存放来不及处理的任务,满了之后再扩容线程池。当我们的工作队列设置得很大时,最大线程数这个参数显得没有意义,因为队列很难满,或者到满的时候再去扩容线程池已经于事无补了。那么有没有办法让线程池更激进一点,优先开启更多的线程,而把队列当成一个后备方案呢?
可以借鉴 Tomcat 线程池也实现了,大致思路:
- 由于线程池在工作队列满了无法入队的情况下会扩容线程池,那么我们是否可以重写队列的 offer 方法,造成这个队列已满的假象。
- 由于我们 Hack 了队列,在达到了最大线程后势必会触发拒绝策略,那么能否实现一个自定义的拒绝策略处理程序,这个时候再把任务真正插入队列。
# 确认线程池本身是不是复用的
案例:某项目生产环境时不时有报警提示线程数过多,超过 2000 个,收到报警后查看监控发现,瞬时线程数比较多但过一会儿又会降下来,线程数抖动很厉害,而应用的访问量变化不大。
为了定位问题,我们在线程数比较高的时候进行线程栈抓取,抓取后发现内存中有 1000 多个自定义线程池。一般而言,线程池肯定是复用的,有 5 个以内的线程池都可以认为正常,而 1000 多个线程池肯定不正常。
在项目代码里,我们没有搜到声明线程池的地方,搜索 execute 关键字后定位到,原来是业务代码调用了一个类库来获得线程池,类似如下的业务代码:调用 ThreadPoolHelper 的 getThreadPool 方法来获得线程池,然后提交数个任务到线程池处理,看不出什么异常。
@GetMapping("wrong")
public String wrong() throws InterruptedException {
ThreadPoolExecutor threadPool = ThreadPoolHelper.getThreadPool();
IntStream.rangeClosed(1, 10).forEach(i -> {
threadPool.execute(() -> {
...
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
});
});
return "OK";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
但是,来到 ThreadPoolHelper 的实现让人大跌眼镜,getThreadPool 方法居然是每次都使用 Executors.newCachedThreadPool 来创建一个线程池。
class ThreadPoolHelper {
public static ThreadPoolExecutor getThreadPool() {
//线程池没有复用
return (ThreadPoolExecutor) Executors.newCachedThreadPool();
}
}
2
3
4
5
6
可以想到 newCachedThreadPool 会在需要时创建必要多的线程,业务代码的一次业务操作会向线程池提交多个慢任务,这样执行一次业务操作就会开启多个线程。如果业务操作并发量较大的话,的确有可能一下子开启几千个线程。
那为什么我们能在监控中看到线程数量会下降,而不会撑爆内存呢?
回到 newCachedThreadPool 的定义就会发现,它的核心线程数是 0,而 keepAliveTime 是 60 秒,也就是在 60 秒之后所有的线程都是可以回收的。好吧,就因为这个特性业务程序死得没太难看。
要修复这个 Bug 也很简单,使用一个静态字段来存放线程池的引用,返回线程池的代码直接返回这个静态字段即可。这里一定要记得我们的最佳实践,手动创建线程池。修复后的 ThreadPoolHelper 类如下:
class ThreadPoolHelper {
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
10, 50,
2, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get());
public static ThreadPoolExecutor getRightThreadPool() {
return threadPoolExecutor;
}
}
2
3
4
5
6
7
8
9
10
# 考虑线程池的混用策略
线程池的意义在于复用,但并不意味着程序应该始终使用一个线程池。而是要根据任务的“轻重缓急”来指定线程池的核心参数,包括线程数、回收策略和任务队列:
- 对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。
- 而对于吞吐量较大的计算型任务,线程数量不宜过多,可以是 CPU 核数或核数 *2(理由是,线程一定调度到某个 CPU 进行执行,如果任务本身是 CPU 绑定的任务,那么过多的线程只会增加线程切换的开销,并不能提升吞吐量),但可能需要较长的队列来做缓冲。
案例:业务代码使用了线程池异步处理一些内存中的数据,但通过监控发现处理得非常慢,整个处理过程都是内存中的计算不涉及 IO 操作,也需要数秒的处理时间,应用程序 CPU 占用也不是特别高,有点不可思议。
经排查发现,业务代码使用的线程池,还被一个后台的文件批处理任务用到了。
或许是够用就好的原则,这个线程池只有 2 个核心线程,最大线程也是 2,使用了容量为 100 的 ArrayBlockingQueue 作为工作队列,使用了 CallerRunsPolicy 拒绝策略:
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
2, 2,
1, TimeUnit.HOURS,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("batchfileprocess-threadpool-%d").get(),
new ThreadPoolExecutor.CallerRunsPolicy());
2
3
4
5
6
这里模拟一下文件批处理的代码,在程序启动后通过一个线程开启死循环逻辑,不断向线程池提交任务,任务的逻辑是向一个文件中写入大量的数据:
@PostConstruct
public void init() {
printStats(threadPool);
new Thread(() -> {
//模拟需要写入的大量数据
String payload = IntStream.rangeClosed(1, 1_000_000)
.mapToObj(__ -> "a")
.collect(Collectors.joining(""));
while (true) {
threadPool.execute(() -> {
try {
//每次都是创建并写入相同的数据到相同的文件
Files.write(Paths.get("demo.txt"), Collections.singletonList(LocalTime.now().toString() + ":" + payload), UTF_8, CREATE, TRUNCATE_EXISTING);
} catch (IOException e) {
e.printStackTrace();
}
log.info("batch file processing done");
});
}
}).start();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这个线程池中的 2 个线程任务是相当重的。通过 printStats 方法打印出的日志,观察下线程池的负担:

可以看到,线程池的 2 个线程始终处于活跃状态,队列也基本处于打满状态。因为开启了 CallerRunsPolicy 拒绝处理策略,所以当线程满载队列也满的情况下,任务会再提交任务的线程,或者说调用 execute 方法的线程执行,也就是说不能认为提交到线程池的任务就一定是异步处理的。如果使用了 CallerRunsPolicy 策略,那么有可能异步任务变为同步执行。从日志的第四行也可以看到这点。这也是这个拒绝策略比较特别的原因。
不知道写代码的同学为什么设置这个策略,或许是测试时发现线程池因为任务处理不过来出现了异常,而又不希望线程池丢弃任务,所以最终选择了这样的拒绝策略。不管怎样,这些日志足以说明线程池是饱和状态。
可以想象到,业务代码复用这样的线程池来做内存计算,命运一定是悲惨的。我们写一段代码测试下,向线程池提交一个简单的任务,这个任务只是休眠 10 毫秒没有其他逻辑:
private Callable<Integer> calcTask() {
return () -> {
TimeUnit.MILLISECONDS.sleep(10);
return 1;
};
}
@GetMapping("wrong")
public int wrong() throws ExecutionException, InterruptedException {
return threadPool.submit(calcTask()).get();
}
2
3
4
5
6
7
8
9
10
11
我们使用 wrk 工具对这个接口进行一个简单的压测,可以看到 TPS 为 75,性能的确非常差。

细想一下,问题其实没有这么简单。因为原来执行 IO 任务的线程池使用的是 CallerRunsPolicy 策略,所以直接使用这个线程池进行异步计算的话,当线程池饱和的时候,计算任务会在执行 Web 请求的 Tomcat 线程执行,这时就会进一步影响到其他同步处理的线程,甚至造成整个应用程序崩溃。
解决方案很简单,使用独立的线程池来做这样的“计算任务”即可。计算任务打了双引号,是因为我们的模拟代码执行的是休眠操作,并不属于 CPU 绑定的操作,更类似 IO 绑定的操作,如果线程池线程数设置太小会限制吞吐能力:
private static ThreadPoolExecutor asyncCalcThreadPool = new ThreadPoolExecutor(
200, 200,
1, TimeUnit.HOURS,
new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("asynccalc-threadpool-%d").get());
@GetMapping("right")
public int right() throws ExecutionException, InterruptedException {
return asyncCalcThreadPool.submit(calcTask()).get();
}
2
3
4
5
6
7
8
9
10
11
使用单独的线程池改造代码后再来测试一下性能,TPS 提高到了 1727:

可以看到,盲目复用线程池混用线程的问题在于,别人定义的线程池属性不一定适合你的任务,而且混用会相互干扰。这就好比,我们往往会用虚拟化技术来实现资源的隔离,而不是让所有应用程序都直接使用物理机。
就线程池混用问题,再补充一个坑:Java 8 的 parallel stream 功能,可以让我们很方便地并行处理集合中的元素,其背后是共享同一个 ForkJoinPool,默认并行度是 CPU 核数 -1。对于 CPU 绑定的任务来说,使用这样的配置比较合适,但如果集合操作涉及同步 IO 操作的话(比如数据库操作、外部服务调用等),建议自定义一个 ForkJoinPool(或普通线程池)。
# 线程池原理
关于线程池相关原理,可以看这两篇文章:JUC - 线程池,JUC - Fork/Join框架
# 连接池
连接池一般对外提供获得连接、归还连接的接口给客户端使用,并暴露最小空闲连接数、最大连接数等可配置参数,在内部则实现连接建立、连接心跳保持、连接管理、空闲连接回收、连接可用性检测等功能。连接池的结构示意图,如下所示:

业务项目中经常会用到的连接池,主要是数据库连接池、Redis 连接池和 HTTP 连接池。以这三种连接池为例,说明使用和配置连接池容易出错的地方。
# 鉴别客户端 SDK 是否基于连接池
在使用三方客户端进行网络通信时,首先要确定客户端 SDK 是否是基于连接池技术实现的。我们知道,TCP 是面向连接的基于字节流的协议:
- 面向连接,意味着连接需要先创建再使用,创建连接的三次握手有一定开销;
- 基于字节流,意味着字节是发送数据的最小单元,TCP 协议本身无法区分哪几个字节是完整的消息体,也无法感知是否有多个客户端在使用同一个 TCP 连接,TCP 只是一个读写数据的管道。
如果客户端 SDK 没有使用连接池,而直接是 TCP 连接,那么就需要考虑每次建立 TCP 连接的开销,并且因为 TCP 基于字节流,在多线程的情况下对同一连接进行复用,可能会产生线程安全问题。
我们先看一下涉及 TCP 连接的客户端 SDK,对外提供 API 的三种方式。在面对各种三方客户端的时候,只有先识别出其属于哪一种,才能理清楚使用方式。
- 连接池和连接分离的 API:有一个 XXXPool 类负责连接池实现,先从其获得连接 XXXConnection,然后用获得的连接进行服务端请求,完成后使用者需要归还连接。通常,XXXPool 是线程安全的,可以并发获取和归还连接,而 XXXConnection 是非线程安全的。对应到连接池的结构示意图中,XXXPool 就是右边连接池那个框,左边的客户端是我们自己的代码。
- 内部带有连接池的 API:对外提供一个 XXXClient 类,通过这个类可以直接进行服务端请求;这个类内部维护了连接池,SDK 使用者无需考虑连接的获取和归还问题。一般而言,XXXClient 是线程安全的。对应到连接池的结构示意图中,整个 API 就是蓝色框包裹的部分。
- 非连接池的 API:一般命名为 XXXConnection,以区分其是基于连接池还是单连接的,而不建议命名为 XXXClient 或直接是 XXX。直接连接方式的 API 基于单一连接,每次使用都需要创建和断开连接,性能一般,且通常不是线程安全的。对应到连接池的结构示意图中,这种形式相当于没有右边连接池那个框,客户端直接连接服务端创建连接。
虽然上面提到了 SDK 一般的命名习惯,但不排除有一些客户端特立独行,因此在使用三方 SDK 时,一定要先查看官方文档了解其最佳实践,或是在类似 Stackoverflow 的网站搜索 XXX threadsafe/singleton 字样看看大家的回复,也可以一层一层往下看源码,直到定位到原始 Socket 来判断 Socket 和客户端 API 的对应关系。
明确了 SDK 连接池的实现方式后,我们就大概知道了使用 SDK 的最佳实践:
- 如果是分离方式,那么连接池本身一般是线程安全的,可以复用。每次使用需要从连接池获取连接,使用后归还,归还的工作由使用者负责。
- 如果是内置连接池,SDK 会负责连接的获取和归还,使用的时候直接复用客户端。
- 如果 SDK 没有实现连接池(大多数中间件、数据库的客户端 SDK 都会支持连接池),那通常不是线程安全的,而且短连接的方式性能不会很高,使用的时候需要考虑是否自己封装一个连接池。
接下来以 Java 中用于操作 Redis 最常见的库 Jedis 为例,从源码角度分析下 Jedis 类到底属于哪种类型的 API,直接在多线程环境下复用一个连接会产生什么问题,以及如何用最佳实践来修复这个问题。
首先,向 Redis 初始化 2 组数据,Key=a、Value=1,Key=b、Value=2:
@PostConstruct
public void init() {
try (Jedis jedis = new Jedis("127.0.0.1", 6379)) {
Assert.isTrue("OK".equals(jedis.set("a", "1")), "set a = 1 return OK");
Assert.isTrue("OK".equals(jedis.set("b", "2")), "set b = 2 return OK");
}
}
2
3
4
5
6
7
然后,启动两个线程,共享操作同一个 Jedis 实例,每一个线程循环 1000 次,分别读取 Key 为 a 和 b 的 Value,判断是否分别为 1 和 2:
Jedis jedis = new Jedis("127.0.0.1", 6379);
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("a");
if (!result.equals("1")) {
log.warn("Expect a to be 1 but found {}", result);
return;
}
}
}).start();
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("b");
if (!result.equals("2")) {
log.warn("Expect b to be 2 but found {}", result);
return;
}
}
}).start();
TimeUnit.SECONDS.sleep(5);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
执行程序多次,可以看到日志中出现了各种奇怪的异常信息,有的是读取 Key 为 b 的 Value 读取到了 1,有的是流非正常结束,还有的是连接关闭异常:
//错误1
[14:56:19.069] [Thread-28] [WARN ] [.t.c.c.redis.JedisMisreuseController:45 ] - Expect b to be 2 but found 1
//错误2
redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
at redis.clients.jedis.util.RedisInputStream.ensureFill(RedisInputStream.java:202)
at redis.clients.jedis.util.RedisInputStream.readLine(RedisInputStream.java:50)
at redis.clients.jedis.Protocol.processError(Protocol.java:114)
at redis.clients.jedis.Protocol.process(Protocol.java:166)
at redis.clients.jedis.Protocol.read(Protocol.java:220)
at redis.clients.jedis.Connection.readProtocolWithCheckingBroken(Connection.java:318)
at redis.clients.jedis.Connection.getBinaryBulkReply(Connection.java:255)
at redis.clients.jedis.Connection.getBulkReply(Connection.java:245)
at redis.clients.jedis.Jedis.get(Jedis.java:181)
at org.geekbang.time.commonmistakes.connectionpool.redis.JedisMisreuseController.lambda$wrong$1(JedisMisreuseController.java:43)
at java.lang.Thread.run(Thread.java:748)
//错误3
java.io.IOException: Socket Closed
at java.net.AbstractPlainSocketImpl.getOutputStream(AbstractPlainSocketImpl.java:440)
at java.net.Socket$3.run(Socket.java:954)
at java.net.Socket$3.run(Socket.java:952)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.Socket.getOutputStream(Socket.java:951)
at redis.clients.jedis.Connection.connect(Connection.java:200)
... 7 more
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
让我们分析一下 Jedis 类的源码,搞清楚其中缘由吧。
public class Jedis extends BinaryJedis implements JedisCommands, MultiKeyCommands,
AdvancedJedisCommands, ScriptingCommands, BasicCommands, ClusterCommands, SentinelCommands, ModuleCommands {
}
public class BinaryJedis implements BasicCommands, BinaryJedisCommands, MultiKeyBinaryCommands,
AdvancedBinaryJedisCommands, BinaryScriptingCommands, Closeable {
protected Client client = null;
...
}
public class Client extends BinaryClient implements Commands {
}
public class BinaryClient extends Connection {
}
public class Connection implements Closeable {
private Socket socket;
private RedisOutputStream outputStream;
private RedisInputStream inputStream;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
可以看到,Jedis 继承了 BinaryJedis,BinaryJedis 中保存了单个 Client 的实例,Client 最终继承了 Connection,Connection 中保存了单个 Socket 的实例,和 Socket 对应的两个读写流。因此,一个 Jedis 对应一个 Socket 连接。类图如下:
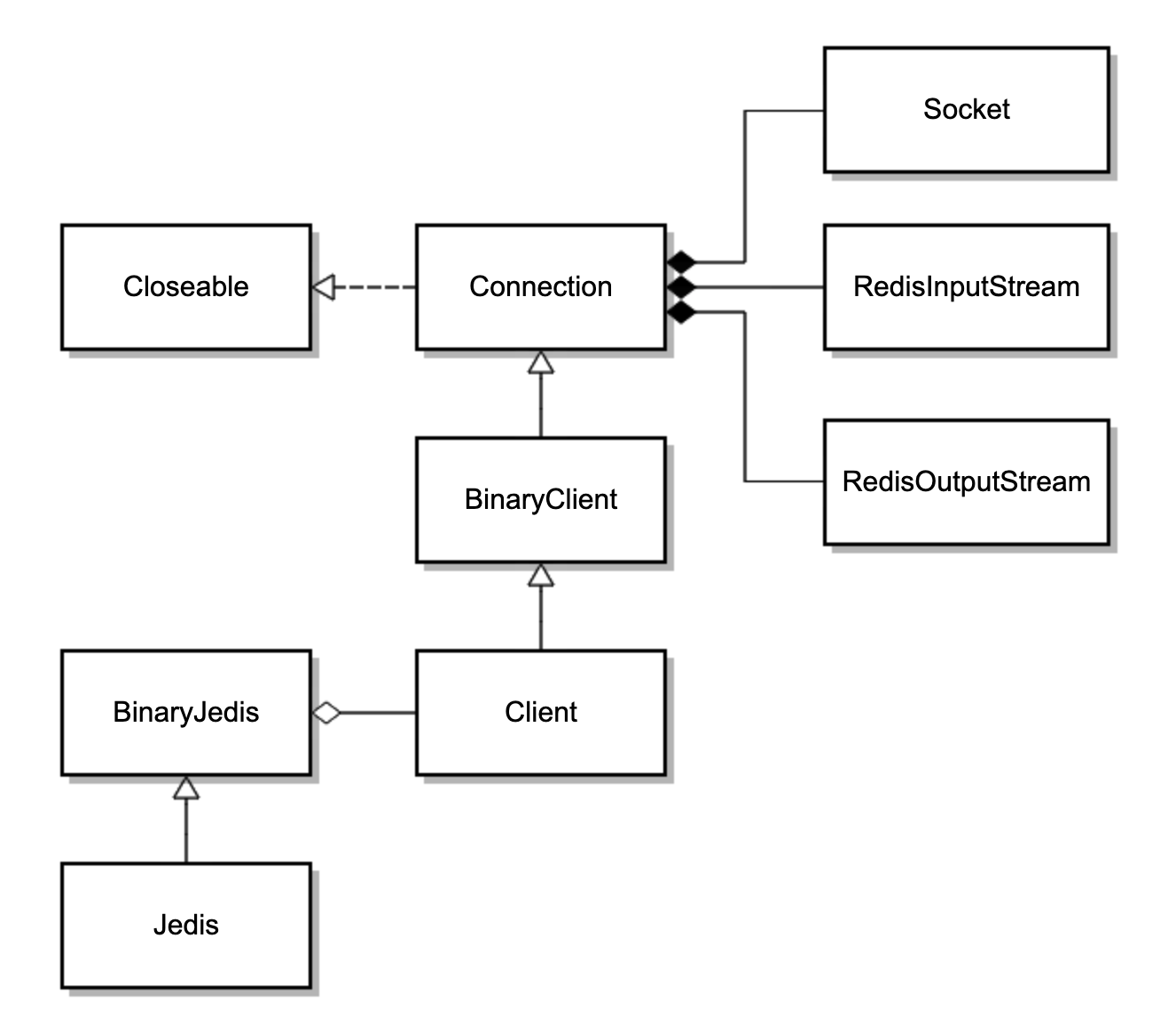
BinaryClient 封装了各种 Redis 命令,其最终会调用基类 Connection 的方法,使用 Protocol 类发送命令。看一下 Protocol 类的 sendCommand 方法的源码,可以发现其发送命令时是直接操作 RedisOutputStream 写入字节。
我们在多线程环境下复用 Jedis 对象,其实就是在复用 RedisOutputStream。如果多个线程在执行操作,那么既无法确保整条命令以一个原子操作写入 Socket,也无法确保写入后、读取前没有其他数据写到远端:
private static void sendCommand(final RedisOutputStream os, final byte[] command,
final byte[]... args) {
try {
os.write(ASTERISK_BYTE);
os.writeIntCrLf(args.length + 1);
os.write(DOLLAR_BYTE);
os.writeIntCrLf(command.length);
os.write(command);
os.writeCrLf();
for (final byte[] arg : args) {
os.write(DOLLAR_BYTE);
os.writeIntCrLf(arg.length);
os.write(arg);
os.writeCrLf();
}
} catch (IOException e) {
throw new JedisConnectionException(e);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
看到这里我们也可以理解了,为啥多线程情况下使用 Jedis 对象操作 Redis 会出现各种奇怪的问题。
比如,写操作互相干扰,多条命令相互穿插的话,必然不是合法的 Redis 命令,那么 Redis 会关闭客户端连接,导致连接断开;又比如,线程 1 和 2 先后写入了 get a 和 get b 操作的请求,Redis 也返回了值 1 和 2,但是线程 2 先读取了数据 1 就会出现数据错乱的问题。
修复方式是,使用 Jedis 提供的另一个线程安全的类 JedisPool 来获得 Jedis 的实例。JedisPool 可以声明为 static 在多个线程之间共享,扮演连接池的角色。使用时,按需使用 try-with-resources 模式从 JedisPool 获得和归还 Jedis 实例。
private static JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);
new Thread(() -> {
try (Jedis jedis = jedisPool.getResource()) {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("a");
if (!result.equals("1")) {
log.warn("Expect a to be 1 but found {}", result);
return;
}
}
}
}).start();
new Thread(() -> {
try (Jedis jedis = jedisPool.getResource()) {
for (int i = 0; i < 1000; i++) {
String result = jedis.get("b");
if (!result.equals("2")) {
log.warn("Expect b to be 2 but found {}", result);
return;
}
}
}
}).start();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这样修复后,代码不再有线程安全问题了。此外,我们最好通过 shutdownhook,在程序退出之前关闭 JedisPool:
@PostConstruct
public void init() {
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
jedisPool.close();
}));
}
2
3
4
5
6
看一下 Jedis 类 close 方法的实现可以发现,如果 Jedis 是从连接池获取的话,那么 close 方法会调用连接池的 return 方法归还连接:
public class Jedis extends BinaryJedis implements JedisCommands, MultiKeyCommands,
AdvancedJedisCommands, ScriptingCommands, BasicCommands, ClusterCommands, SentinelCommands, ModuleCommands {
protected JedisPoolAbstract dataSource = null;
@Override
public void close() {
if (dataSource != null) {
JedisPoolAbstract pool = this.dataSource;
this.dataSource = null;
if (client.isBroken()) {
pool.returnBrokenResource(this);
} else {
pool.returnResource(this);
}
} else {
super.close();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
如果不是,则直接关闭连接,其最终调用 Connection 类的 disconnect 方法来关闭 TCP 连接:
public void disconnect() {
if (isConnected()) {
try {
outputStream.flush();
socket.close();
} catch (IOException ex) {
broken = true;
throw new JedisConnectionException(ex);
} finally {
IOUtils.closeQuietly(socket);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
可以看到,Jedis 可以独立使用,也可以配合连接池使用,这个连接池就是 JedisPool。我们再看看 JedisPool 的实现。
public class JedisPool extends JedisPoolAbstract {
@Override
public Jedis getResource() {
Jedis jedis = super.getResource();
jedis.setDataSource(this);
return jedis;
}
@Override
protected void returnResource(final Jedis resource) {
if (resource != null) {
try {
resource.resetState();
returnResourceObject(resource);
} catch (Exception e) {
returnBrokenResource(resource);
throw new JedisException("Resource is returned to the pool as broken", e);
}
}
}
}
public class JedisPoolAbstract extends Pool<Jedis> {
}
public abstract class Pool<T> implements Closeable {
protected GenericObjectPool<T> internalPool;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
JedisPool 的 getResource 方法在拿到 Jedis 对象后,将自己设置为了连接池。连接池 JedisPool,继承了 JedisPoolAbstract,而后者继承了抽象类 Pool,Pool 内部维护了 Apache Common 的通用池 GenericObjectPool。JedisPool 的连接池就是基于 GenericObjectPool 的。
看到这里我们了解了,Jedis 的 API 实现是我们说的三种类型中的第一种,也就是连接池和连接分离的 API,JedisPool 是线程安全的连接池,Jedis 是非线程安全的单一连接。
# 使用连接池务必确保复用
池一定是用来复用的,否则其使用代价会比每次创建单一对象更大。对连接池来说更是如此,原因如下:
- 创建连接池的时候很可能一次性创建了多个连接,大多数连接池考虑到性能,会在初始化的时候维护一定数量的最小连接(毕竟初始化连接池的过程一般是一次性的),可以直接使用。如果每次使用连接池都按需创建连接池,那么很可能你只用到一个连接,但是创建了 N 个连接。
- 连接池一般会有一些管理模块,也就是连接池的结构示意图中的绿色部分。举个例子,大多数的连接池都有闲置超时的概念。连接池会检测连接的闲置时间,定期回收闲置的连接,把活跃连接数降到最低(闲置)连接的配置值,减轻服务端的压力。一般情况下,闲置连接由独立线程管理,启动了空闲检测的连接池相当于还会启动一个线程。此外,有些连接池还需要独立线程负责连接保活等功能。因此,启动一个连接池相当于启动了 N 个线程。
除了使用代价,连接池不释放,还可能会引起线程泄露。接下来以 Apache HttpClient 为例,和你说说连接池不复用的问题。
首先,创建一个 CloseableHttpClient,设置使用 PoolingHttpClientConnectionManager 连接池并启用空闲连接驱逐策略,最大空闲时间为 60 秒,然后使用这个连接来请求一个会返回 OK 字符串的服务端接口:
@GetMapping("wrong1")
public String wrong1() {
CloseableHttpClient client = HttpClients.custom()
.setConnectionManager(new PoolingHttpClientConnectionManager())
.evictIdleConnections(60, TimeUnit.SECONDS).build();
try (CloseableHttpResponse response = client.execute(new HttpGet("http://127.0.0.1:45678/httpclientnotreuse/test"))) {
return EntityUtils.toString(response.getEntity());
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
访问这个接口几次后查看应用线程情况,可以看到有大量叫作 Connection evictor 的线程,且这些线程不会销毁:
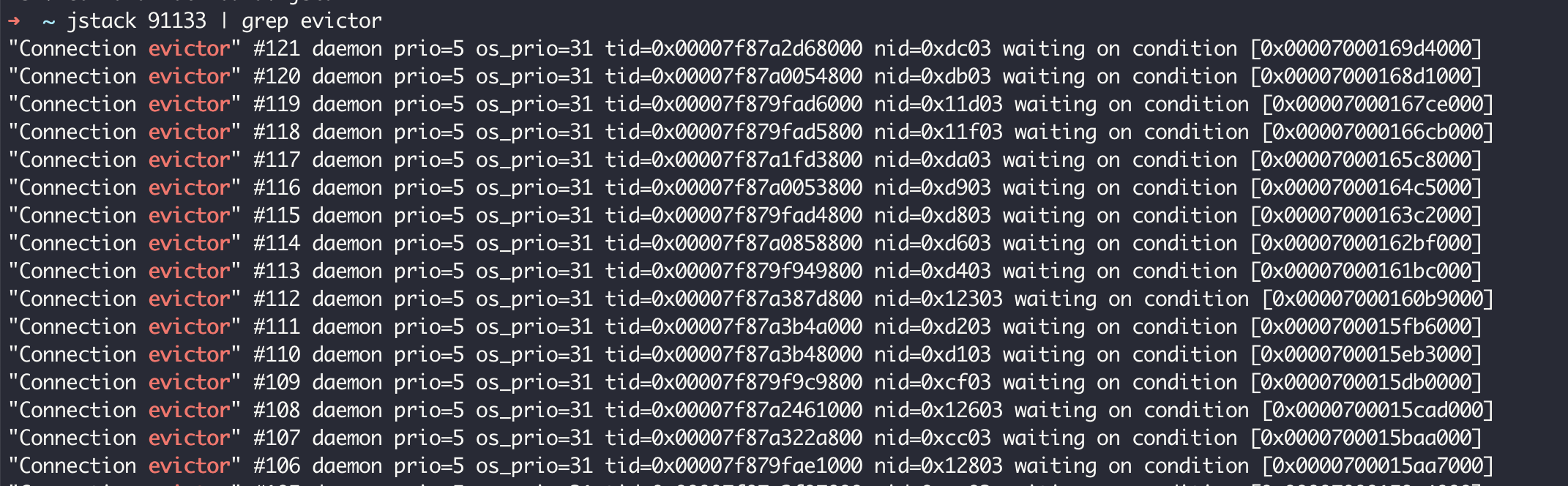
对这个接口进行几秒的压测(压测使用 wrk,1 个并发 1 个连接)可以看到,已经建立了三千多个 TCP 连接到 45678 端口(其中有 1 个是压测客户端到 Tomcat 的连接,大部分都是 HttpClient 到 Tomcat 的连接):
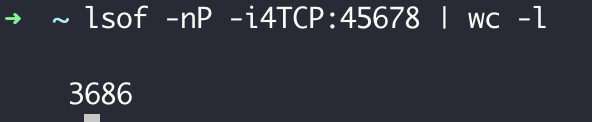
好在有了空闲连接回收的策略,60 秒之后连接处于 CLOSE_WAIT 状态,最终彻底关闭。

这 2 点证明,CloseableHttpClient 属于第二种模式,即内部带有连接池的 API,其背后是连接池,最佳实践一定是复用。
复用方式很简单,可以把 CloseableHttpClient 声明为 static,只创建一次,并且在 JVM 关闭之前通过 addShutdownHook 钩子关闭连接池,在使用的时候直接使用 CloseableHttpClient 即可,无需每次都创建。
首先,定义一个 right 接口来实现服务端接口调用:
private static CloseableHttpClient httpClient = null;
static {
//当然,也可以把CloseableHttpClient定义为Bean,然后在@PreDestroy标记的方法内close这个HttpClient
httpClient = HttpClients.custom().setMaxConnPerRoute(1).setMaxConnTotal(1).evictIdleConnections(60, TimeUnit.SECONDS).build();
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
try {
httpClient.close();
} catch (IOException ignored) {
}
}));
}
@GetMapping("right")
public String right() {
try (CloseableHttpResponse response = httpClient.execute(new HttpGet("http://127.0.0.1:45678/httpclientnotreuse/test"))) {
return EntityUtils.toString(response.getEntity());
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
然后,重新定义一个 wrong2 接口,修复之前按需创建 CloseableHttpClient 的代码,每次用完之后确保连接池可以关闭:
@GetMapping("wrong2")
public String wrong2() {
try (CloseableHttpClient client = HttpClients.custom()
.setConnectionManager(new PoolingHttpClientConnectionManager())
.evictIdleConnections(60, TimeUnit.SECONDS).build();
CloseableHttpResponse response = client.execute(new HttpGet("http://127.0.0.1:45678/httpclientnotreuse/test"))) {
return EntityUtils.toString(response.getEntity());
} catch (Exception ex) {
ex.printStackTrace();
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
使用 wrk 对 wrong2 和 right 两个接口分别压测 60 秒,可以看到两种使用方式性能上的差异,每次创建连接池的 QPS 是 337,而复用连接池的 QPS 是 2022:
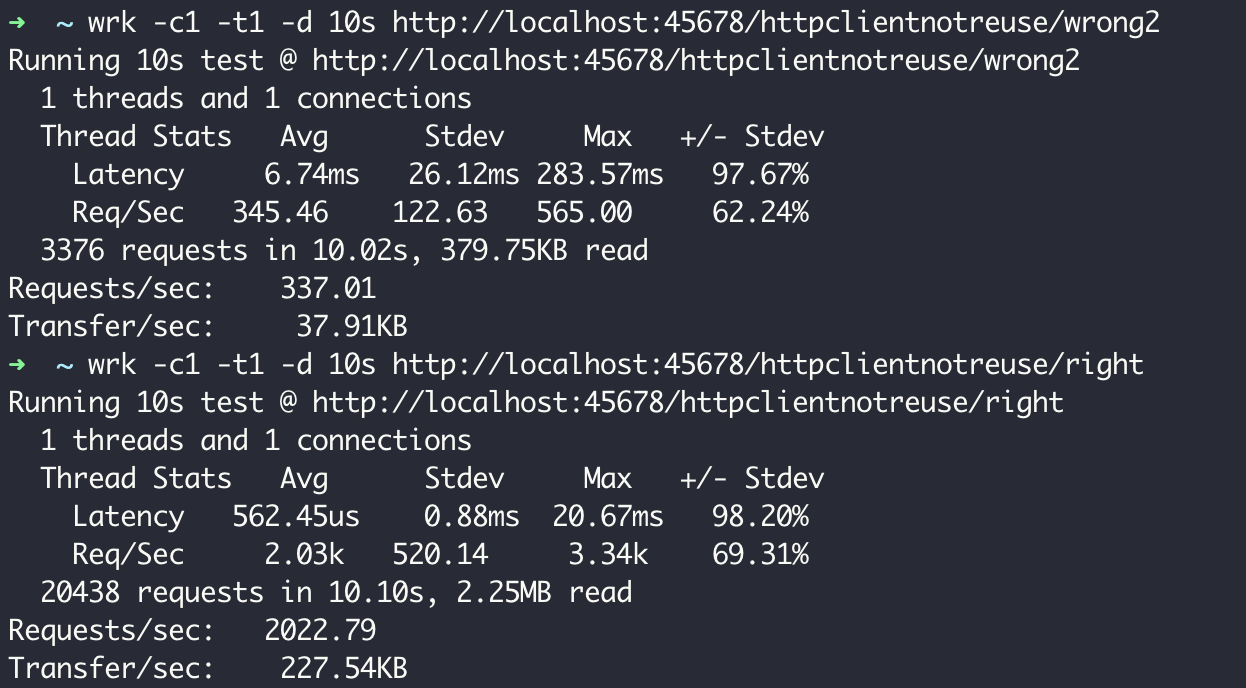
如此大的性能差异显然是因为 TCP 连接的复用。你可能注意到了,刚才定义连接池时将最大连接数设置为 1。所以,复用连接池方式复用的始终应该是同一个连接,而新建连接池方式应该是每次都会创建新的 TCP 连接。
# 合理配置连接池
为方便根据容量规划设置连接处的属性,连接池提供了许多参数,包括最小(闲置)连接、最大连接、闲置连接生存时间、连接生存时间等。其中,最重要的参数是最大连接数,它决定了连接池能使用的连接数量上限,达到上限后,新来的请求需要等待其他请求释放连接。
但最大连接数不是设置得越大越好。如果设置得太大,不仅仅是客户端需要耗费过多的资源维护连接,更重要的是由于服务端对应的是多个客户端,每一个客户端都保持大量的连接,会给服务端带来更大的压力。这个压力又不仅仅是内存压力,可以想一下如果服务端的网络模型是一个 TCP 连接一个线程,那么几千个连接意味着几千个线程,如此多的线程会造成大量的线程切换开销。
当然,连接池最大连接数设置得太小,很可能会因为获取连接的等待时间太长,导致吞吐量低下,甚至超时无法获取连接。
接下来就模拟下压力增大导致数据库连接池打满的情况,来实践下如何确认连接池的使用情况,以及有针对性地进行参数优化。
首先,定义一个用户注册方法,通过 @Transactional 注解为方法开启事务。其中包含了 500 毫秒的休眠,一个数据库事务对应一个 TCP 连接,所以 500 多毫秒的时间都会占用数据库连接:
@Transactional
public User register(){
User user=new User();
user.setName("new-user-"+System.currentTimeMillis());
userRepository.save(user);
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
return user;
}
2
3
4
5
6
7
8
9
10
11
12
随后,修改配置文件启用 register-mbeans,使 Hikari 连接池能通过 JMX MBean 注册连接池相关统计信息,方便观察连接池:
spring.datasource.hikari.register-mbeans=true
启动程序并通过 JConsole 连接进程后,可以看到默认情况下最大连接数为 10:
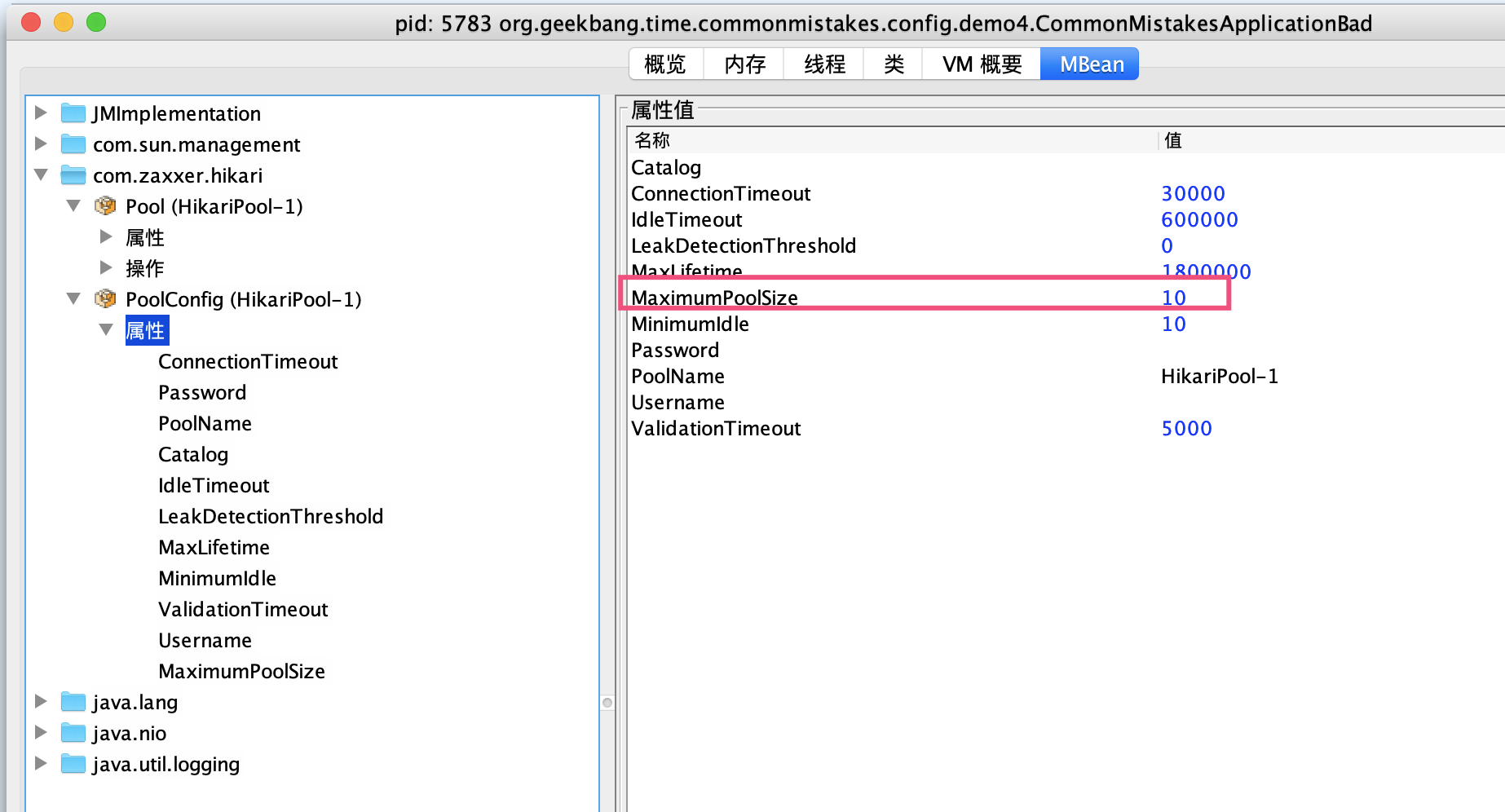
使用 wrk 对应用进行压测,可以看到连接数一下子从 0 到了 10,有 20 个线程在等待获取连接:
不久就出现了无法获取数据库连接的异常,如下所示:
[15:37:56.156] [http-nio-45678-exec-15] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.dao.DataAccessResourceFailureException: unable to obtain isolated JDBC connection; nested exception is org.hibernate.exception.JDBCConnectionException: unable to obtain isolated JDBC connection] with root cause
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 30000ms.
2
从异常信息中可以看到,数据库连接池是 HikariPool,解决方式很简单,修改一下配置文件,调整数据库连接池最大连接参数到 50 即可。
spring.datasource.hikari.maximum-pool-size=50
然后,再观察一下这个参数是否适合当前压力,满足需求的同时也不占用过多资源。从监控来看这个调整是合理的,有一半的富余资源,再也没有线程需要等待连接了:
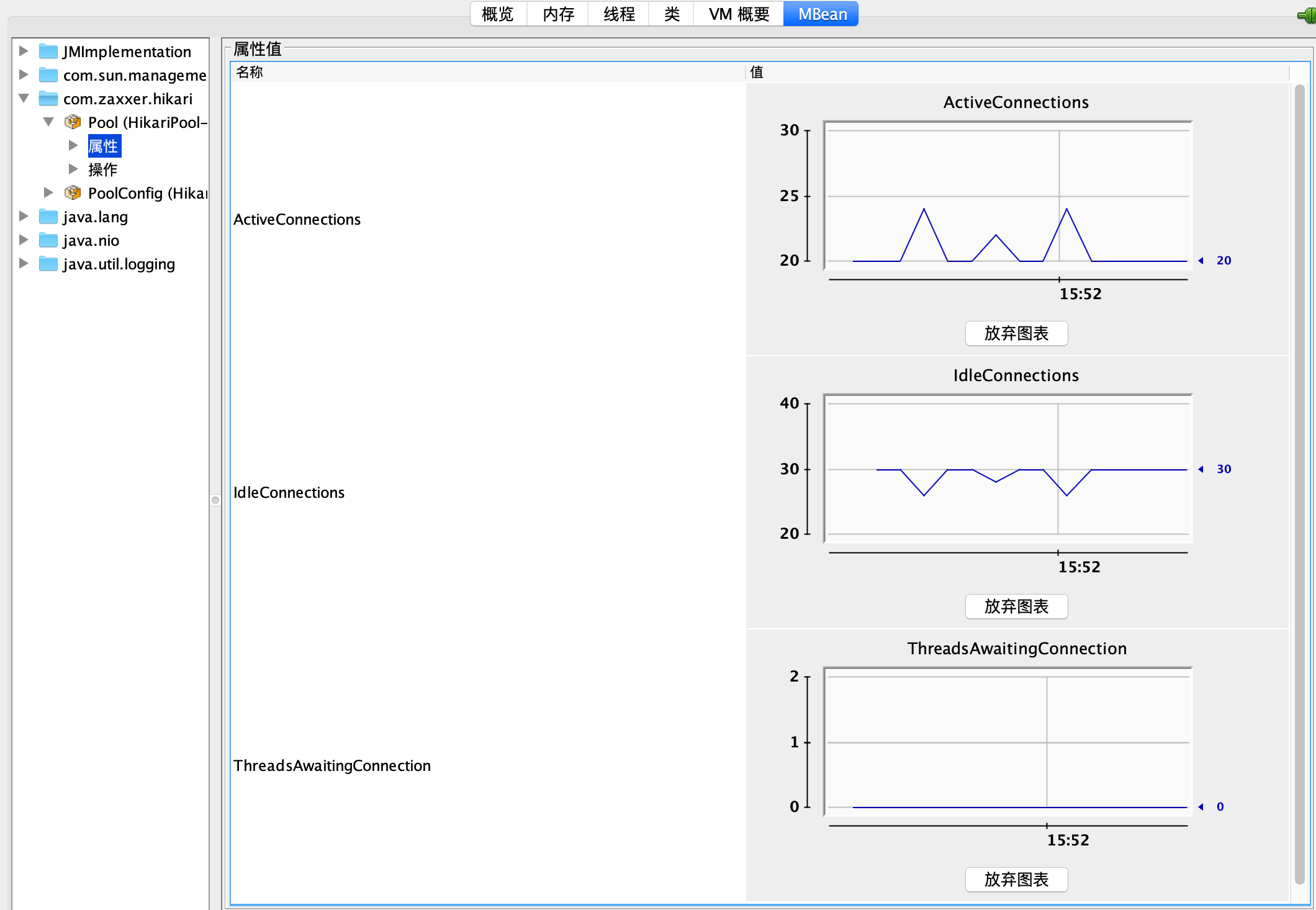
在这个 Demo 里,知道压测大概能对应使用 25 左右的并发连接,所以直接把连接池最大连接设置为了 50。在真实情况下,只要数据库可以承受,可以选择在遇到连接超限的时候先设置一个足够大的连接数,然后观察最终应用的并发,再按照实际并发数留出一半的余量来设置最终的最大连接。
其实,看到错误日志后再调整已经有点儿晚了。更合适的做法是,对类似数据库连接池的重要资源进行持续检测,并设置一半的使用量作为报警阈值,出现预警后及时扩容。
在这里是为了演示,才通过 JConsole 查看参数配置后的效果,生产上需要把相关数据对接到指标监控体系中持续监测。
这里要强调的是,修改配置参数务必验证是否生效,并且在监控系统中确认参数是否生效、是否合理。之所以要“强调”,是因为这里有坑。
比如这样一个事故。应用准备针对大促活动进行扩容,把数据库配置文件中 Druid 连接池最大连接数 maxActive 从 50 提高到了 100,修改后并没有通过监控验证,结果大促当天应用因为连接池连接数不够爆了。
经排查发现,当时修改的连接数并没有生效。原因是,应用虽然一开始使用的是 Druid 连接池,但后来框架升级了,把连接池替换为了 Hikari 实现,原来的那些配置其实都是无效的,修改后的参数配置当然也不会生效。
所以说,对连接池进行调参,一定要眼见为实。
# HTTP 调用
与执行本地方法不同,进行 HTTP 调用本质上是通过 HTTP 协议进行一次网络请求。网络请求必然有超时的可能性,因此我们必须考虑到这三点:
- 首先,框架设置的默认超时是否合理;
- 其次,考虑到网络的不稳定,超时后的请求重试是一个不错的选择,但需要考虑服务端接口的幂等性设计是否允许我们重试;
- 最后,需要考虑框架是否会像浏览器那样限制并发连接数,以免在服务并发很大的情况下,HTTP 调用的并发数限制成为瓶颈。
Spring Cloud 是 Java 微服务架构的代表性框架。如果使用 Spring Cloud 进行微服务开发,就会使用 Feign 进行声明式的服务调用。如果不使用 Spring Cloud,而直接使用 Spring Boot 进行微服务开发的话,可能会直接使用 Java 中最常用的 HTTP 客户端 Apache HttpClient 进行服务调用。
# 配置连接超时和读取超时参数
对于 HTTP 调用,虽然应用层走的是 HTTP 协议,但网络层面始终是 TCP/IP 协议。TCP/IP 是面向连接的协议,在传输数据之前需要建立连接。几乎所有的网络框架都会提供这么两个超时参数:
- 连接超时参数 ConnectTimeout,让用户配置建立连接阶段的最长等待时间;
- 读取超时参数 ReadTimeout,用来控制从 Socket 上读取数据的最长等待时间。
这两个参数看似是网络层偏底层的配置参数,不足以引起开发同学的重视。但正确理解和配置这两个参数,对业务应用特别重要,毕竟超时不是单方面的事情,需要客户端和服务端对超时有一致的估计,协同配合方能平衡吞吐量和错误率。
连接超时参数和连接超时的误区有这么两个:
- 连接超时配置得特别长,比如 60 秒。一般来说,TCP 三次握手建立连接需要的时间非常短,通常在毫秒级最多到秒级,不可能需要十几秒甚至几十秒。如果很久都无法建连,很可能是网络或防火墙配置的问题。这种情况下,如果几秒连接不上,那么可能永远也连接不上。因此,设置特别长的连接超时意义不大,将其配置得短一些(比如 1~5 秒)即可。如果是纯内网调用的话,这个参数可以设置得更短,在下游服务离线无法连接的时候,可以快速失败。
- 排查连接超时问题,却没理清连的是哪里。通常情况下,我们的服务会有多个节点,如果别的客户端通过客户端负载均衡技术来连接服务端,那么客户端和服务端会直接建立连接,此时出现连接超时大概率是服务端的问题;而如果服务端通过类似 Nginx 的反向代理来负载均衡,客户端连接的其实是 Nginx,而不是服务端,此时出现连接超时应该排查 Nginx。
读取超时参数和读取超时则会有更多的误区,将其归纳为如下三个。
第一个误区:认为出现了读取超时,服务端的执行就会中断。
我们来简单测试下。定义一个 client 接口,内部通过 HttpClient 调用服务端接口 server,客户端读取超时 2 秒,服务端接口执行耗时 5 秒。
@RestController @RequestMapping("clientreadtimeout") @Slf4j public class ClientReadTimeoutController { private String getResponse(String url, int connectTimeout, int readTimeout) throws IOException { return Request.Get("http://localhost:45678/clientreadtimeout" + url) .connectTimeout(connectTimeout) .socketTimeout(readTimeout) .execute() .returnContent() .asString(); } @GetMapping("client") public String client() throws IOException { log.info("client1 called"); //服务端5s超时,客户端读取超时2秒 return getResponse("/server?timeout=5000", 1000, 2000); } @GetMapping("server") public void server(@RequestParam("timeout") int timeout) throws InterruptedException { log.info("server called"); TimeUnit.MILLISECONDS.sleep(timeout); log.info("Done"); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27调用 client 接口后,从日志中可以看到,客户端 2 秒后出现了 SocketTimeoutException,原因是读取超时,服务端却丝毫没受影响在 3 秒后执行完成。
[11:35:11.943] [http-nio-45678-exec-1] [INFO ] [.t.c.c.d.ClientReadTimeoutController:29 ] - client1 called [11:35:12.032] [http-nio-45678-exec-2] [INFO ] [.t.c.c.d.ClientReadTimeoutController:36 ] - server called [11:35:14.042] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception java.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0(Native Method) ... [11:35:17.036] [http-nio-45678-exec-2] [INFO ] [.t.c.c.d.ClientReadTimeoutController:38 ] - Done1
2
3
4
5
6
7我们知道,类似 Tomcat 的 Web 服务器都是把服务端请求提交到线程池处理的,只要服务端收到了请求,网络层面的超时和断开便不会影响服务端的执行。因此,出现读取超时不能随意假设服务端的处理情况,需要根据业务状态考虑如何进行后续处理。
第二个误区:认为读取超时只是 Socket 网络层面的概念,是数据传输的最长耗时,故将其配置得非常短,比如 100 毫秒。
其实,发生了读取超时,网络层面无法区分是服务端没有把数据返回给客户端,还是数据在网络上耗时较久或丢包。
但,因为 TCP 是先建立连接后传输数据,对于网络情况不是特别糟糕的服务调用,通常可以认为出现连接超时是网络问题或服务不在线,而出现读取超时是服务处理超时。确切地说,读取超时指的是,向 Socket 写入数据后,我们等到 Socket 返回数据的超时时间,其中包含的时间或者说绝大部分的时间,是服务端处理业务逻辑的时间。
第三个误区:认为超时时间越长任务接口成功率就越高,将读取超时参数配置得太长。
进行 HTTP 请求一般是需要获得结果的,属于同步调用。如果超时时间很长,在等待服务端返回数据的同时,客户端线程(通常是 Tomcat 线程)也在等待,当下游服务出现大量超时的时候,程序可能也会受到拖累创建大量线程,最终崩溃。
对定时任务或异步任务来说,读取超时配置得长些问题不大。但面向用户响应的请求或是微服务短平快的同步接口调用,并发量一般较大,我们应该设置一个较短的读取超时时间,以防止被下游服务拖慢,通常不会设置超过 30 秒的读取超时。
你可能会说,如果把读取超时设置为 2 秒,服务端接口需要 3 秒,岂不是永远都拿不到执行结果了?的确是这样,因此设置读取超时一定要根据实际情况,过长可能会让下游抖动影响到自己,过短又可能影响成功率。甚至,有些时候我们还要根据下游服务的 SLA,为不同的服务端接口设置不同的客户端读取超时。
# Feign 和 Ribbon 配合使用,怎么配置超时
为 Feign 配置超时参数的复杂之处在于,Feign 自己有两个超时参数,它使用的负载均衡组件 Ribbon 本身还有相关配置。那么,这些配置的优先级是怎样的,又哪些什么坑呢?接下来,我们做一些实验吧。
为测试服务端的超时,假设有这么一个服务端接口,什么都不干只休眠 10 分钟:
@PostMapping("/server")
public void server() throws InterruptedException {
TimeUnit.MINUTES.sleep(10);
}
2
3
4
首先,定义一个 Feign 来调用这个接口:
@FeignClient(name = "clientsdk")
public interface Client {
@PostMapping("/feignandribbon/server")
void server();
}
2
3
4
5
然后,通过 Feign Client 进行接口调用:
@GetMapping("client")
public void timeout() {
long begin=System.currentTimeMillis();
try{
client.server();
}catch (Exception ex){
log.warn("执行耗时:{}ms 错误:{}", System.currentTimeMillis() - begin, ex.getMessage());
}
}
2
3
4
5
6
7
8
9
在配置文件仅指定服务端地址的情况下:
clientsdk.ribbon.listOfServers=localhost:45678
得到如下输出:
[15:40:16.094] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:1007ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
从这个输出中,我们可以得到结论一,默认情况下 Feign 的读取超时是 1 秒,如此短的读取超时算是坑点一。
我们来分析一下源码。打开 RibbonClientConfiguration 类后,会看到 DefaultClientConfigImpl 被创建出来之后,ReadTimeout 和 ConnectTimeout 被设置为 1s:
/**
* Ribbon client default connect timeout.
*/
public static final int DEFAULT_CONNECT_TIMEOUT = 1000;
/**
* Ribbon client default read timeout.
*/
public static final int DEFAULT_READ_TIMEOUT = 1000;
@Bean
@ConditionalOnMissingBean
public IClientConfig ribbonClientConfig() {
DefaultClientConfigImpl config = new DefaultClientConfigImpl();
config.loadProperties(this.name);
config.set(CommonClientConfigKey.ConnectTimeout, DEFAULT_CONNECT_TIMEOUT);
config.set(CommonClientConfigKey.ReadTimeout, DEFAULT_READ_TIMEOUT);
config.set(CommonClientConfigKey.GZipPayload, DEFAULT_GZIP_PAYLOAD);
return config;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
如果要修改 Feign 客户端默认的两个全局超时时间,你可以设置 feign.client.config.default.readTimeout 和 feign.client.config.default.connectTimeout 参数:
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
2
修改配置后重试,得到如下日志:
[15:43:39.955] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:3006ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
可见,3 秒读取超时生效了。注意:这里有一个大坑,如果你希望只修改读取超时,可能会只配置这么一行:
feign.client.config.default.readTimeout=3000
测试一下你就会发现,这样的配置是无法生效的!
结论二,也是坑点二,如果要配置 Feign 的读取超时,就必须同时配置连接超时,才能生效。
打开 FeignClientFactoryBean 可以看到,只有同时设置 ConnectTimeout 和 ReadTimeout,Request.Options 才会被覆盖:
if (config.getConnectTimeout() != null && config.getReadTimeout() != null) {
builder.options(new Request.Options(config.getConnectTimeout(),
config.getReadTimeout()));
}
2
3
4
更进一步,如果你希望针对单独的 Feign Client 设置超时时间,可以把 default 替换为 Client 的 name:
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
feign.client.config.clientsdk.readTimeout=2000
feign.client.config.clientsdk.connectTimeout=2000
2
3
4
以得出结论三,单独的超时可以覆盖全局超时,这符合预期,不算坑:
[15:45:51.708] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:2006ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
结论四,除了可以配置 Feign,也可以配置 Ribbon 组件的参数来修改两个超时时间。这里的坑点三是,参数首字母要大写,和 Feign 的配置不同。
ribbon.ReadTimeout=4000
ribbon.ConnectTimeout=4000
2
可以通过日志证明参数生效:
[15:55:18.019] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:4003ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
最后,我们来看看同时配置 Feign 和 Ribbon 的参数,最终谁会生效?如下代码的参数配置:
clientsdk.ribbon.listOfServers=localhost:45678
feign.client.config.default.readTimeout=3000
feign.client.config.default.connectTimeout=3000
ribbon.ReadTimeout=4000
ribbon.ConnectTimeout=4000
2
3
4
5
日志输出证明,最终生效的是 Feign 的超时:
[16:01:19.972] [http-nio-45678-exec-3] [WARN ] [o.g.t.c.h.f.FeignAndRibbonController :26 ] - 执行耗时:3006ms 错误:Read timed out executing POST http://clientsdk/feignandribbon/server
结论五,同时配置 Feign 和 Ribbon 的超时,以 Feign 为准。这有点反直觉,因为 Ribbon 更底层所以你会觉得后者的配置会生效,但其实不是这样的。
在 LoadBalancerFeignClient 源码中可以看到,如果 Request.Options 不是默认值,就会创建一个 FeignOptionsClientConfig 代替原来 Ribbon 的 DefaultClientConfigImpl,导致 Ribbon 的配置被 Feign 覆盖:
IClientConfig getClientConfig(Request.Options options, String clientName) {
IClientConfig requestConfig;
if (options == DEFAULT_OPTIONS) {
requestConfig = this.clientFactory.getClientConfig(clientName);
}
else {
requestConfig = new FeignOptionsClientConfig(options);
}
return requestConfig;
}
2
3
4
5
6
7
8
9
10
但如果这么配置最终生效的还是 Ribbon 的超时(4 秒),这容易让人产生 Ribbon 覆盖了 Feign 的错觉,其实这还是因为坑二所致,单独配置 Feign 的读取超时并不能生效:
clientsdk.ribbon.listOfServers=localhost:45678
feign.client.config.default.readTimeout=3000
feign.client.config.clientsdk.readTimeout=2000
ribbon.ReadTimeout=4000
2
3
4
# Ribbon 会自动重试请求
一些 HTTP 客户端往往会内置一些重试策略,其初衷是好的,毕竟因为网络问题导致丢包虽然频繁但持续时间短,往往重试下第二次就能成功,但一定要小心这种自作主张是否符合我们的预期。
之前遇到过一个短信重复发送的问题,但短信服务的调用方用户服务,反复确认代码里没有重试逻辑。那问题究竟出在哪里了?我们来重现一下这个案例。
首先,定义一个 Get 请求的发送短信接口,里面没有任何逻辑,休眠 2 秒模拟耗时:
@RestController
@RequestMapping("ribbonretryissueserver")
@Slf4j
public class RibbonRetryIssueServerController {
@GetMapping("sms")
public void sendSmsWrong(@RequestParam("mobile") String mobile, @RequestParam("message") String message, HttpServletRequest request) throws InterruptedException {
//输出调用参数后休眠2秒
log.info("{} is called, {}=>{}", request.getRequestURL().toString(), mobile, message);
TimeUnit.SECONDS.sleep(2);
}
}
2
3
4
5
6
7
8
9
10
11
配置一个 Feign 供客户端调用:
@FeignClient(name = "SmsClient")
public interface SmsClient {
@GetMapping("/ribbonretryissueserver/sms")
void sendSmsWrong(@RequestParam("mobile") String mobile, @RequestParam("message") String message);
}
2
3
4
5
Feign 内部有一个 Ribbon 组件负责客户端负载均衡,通过配置文件设置其调用的服务端为两个节点:
SmsClient.ribbon.listOfServers=localhost:45679,localhost:45678
写一个客户端接口,通过 Feign 调用服务端:
@RestController
@RequestMapping("ribbonretryissueclient")
@Slf4j
public class RibbonRetryIssueClientController {
@Autowired
private SmsClient smsClient;
@GetMapping("wrong")
public String wrong() {
log.info("client is called");
try{
//通过Feign调用发送短信接口
smsClient.sendSmsWrong("13600000000", UUID.randomUUID().toString());
} catch (Exception ex) {
//捕获可能出现的网络错误
log.error("send sms failed : {}", ex.getMessage());
}
return "done";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在 45678 和 45679 两个端口上分别启动服务端,然后访问 45678 的客户端接口进行测试。因为客户端和服务端控制器在一个应用中,所以 45678 同时扮演了客户端和服务端的角色。
在 45678 日志中可以看到,29 秒时客户端收到请求开始调用服务端接口发短信,同时服务端收到了请求,2 秒后(注意对比第一条日志和第三条日志)客户端输出了读取超时的错误信息:
[12:49:29.020] [http-nio-45678-exec-4] [INFO ] [c.d.RibbonRetryIssueClientController:23 ] - client is called
[12:49:29.026] [http-nio-45678-exec-5] [INFO ] [c.d.RibbonRetryIssueServerController:16 ] - http://localhost:45678/ribbonretryissueserver/sms is called, 13600000000=>a2aa1b32-a044-40e9-8950-7f0189582418
[12:49:31.029] [http-nio-45678-exec-4] [ERROR] [c.d.RibbonRetryIssueClientController:27 ] - send sms failed : Read timed out executing GET http://SmsClient/ribbonretryissueserver/sms?mobile=13600000000&message=a2aa1b32-a044-40e9-8950-7f0189582418
2
3
而在另一个服务端 45679 的日志中还可以看到一条请求,30 秒时收到请求,也就是客户端接口调用后的 1 秒:
[12:49:30.029] [http-nio-45679-exec-2] [INFO ] [c.d.RibbonRetryIssueServerController:16 ] - http://localhost:45679/ribbonretryissueserver/sms is called, 13600000000=>a2aa1b32-a044-40e9-8950-7f0189582418
客户端接口被调用的日志只输出了一次,而服务端的日志输出了两次。虽然 Feign 的默认读取超时时间是 1 秒,但客户端 2 秒后才出现超时错误。显然,这说明客户端自作主张进行了一次重试,导致短信重复发送。
翻看 Ribbon 的源码可以发现,MaxAutoRetriesNextServer 参数默认为 1,也就是 Get 请求在某个服务端节点出现问题(比如读取超时)时,Ribbon 会自动重试一次:
// DefaultClientConfigImpl
public static final int DEFAULT_MAX_AUTO_RETRIES_NEXT_SERVER = 1;
public static final int DEFAULT_MAX_AUTO_RETRIES = 0;
// RibbonLoadBalancedRetryPolicy
public boolean canRetry(LoadBalancedRetryContext context) {
HttpMethod method = context.getRequest().getMethod();
return HttpMethod.GET == method || lbContext.isOkToRetryOnAllOperations();
}
@Override
public boolean canRetrySameServer(LoadBalancedRetryContext context) {
return sameServerCount < lbContext.getRetryHandler().getMaxRetriesOnSameServer()
&& canRetry(context);
}
@Override
public boolean canRetryNextServer(LoadBalancedRetryContext context) {
// this will be called after a failure occurs and we increment the counter
// so we check that the count is less than or equals to too make sure
// we try the next server the right number of times
return nextServerCount <= lbContext.getRetryHandler().getMaxRetriesOnNextServer()
&& canRetry(context);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
解决办法有两个:
一是,把发短信接口从 Get 改为 Post。其实,这里还有一个 API 设计问题,有状态的 API 接口不应该定义为 Get。根据 HTTP 协议的规范,Get 请求用于数据查询,而 Post 才是把数据提交到服务端用于修改或新增。选择 Get 还是 Post 的依据,应该是 API 的行为,而不是参数大小。这里的一个误区是,Get 请求的参数包含在 Url QueryString 中,会受浏览器长度限制,所以一些同学会选择使用 JSON 以 Post 提交大参数,使用 Get 提交小参数。
二是,将 MaxAutoRetriesNextServer 参数配置为 0,禁用服务调用失败后在下一个服务端节点的自动重试。在配置文件中添加一行即可:
ribbon.MaxAutoRetriesNextServer=01
看到这里,你觉得问题出在用户服务还是短信服务呢?
在我看来,双方都有问题。就像之前说的,Get 请求应该是无状态或者幂等的,短信接口可以设计为支持幂等调用的;而用户服务的开发同学,如果对 Ribbon 的重试机制有所了解的话,或许就能在排查问题上少走些弯路。
# 并发限制了爬虫的抓取能力
除了超时和重试的坑,进行 HTTP 请求调用还有一个常见的问题是,并发数的限制导致程序的处理能力上不去。
案例:一个爬虫项目,整体爬取数据的效率很低,增加线程池数量也无济于事,只能堆更多的机器做分布式的爬虫。现在,我们就来模拟下这个场景,看看问题出在了哪里。
假设要爬取的服务端是这样的一个简单实现,休眠 1 秒返回数字 1:
@GetMapping("server")
public int server() throws InterruptedException {
TimeUnit.SECONDS.sleep(1);
return 1;
}
2
3
4
5
爬虫需要多次调用这个接口进行数据抓取,为了确保线程池不是并发的瓶颈,我们使用一个没有线程上限的 newCachedThreadPool 作为爬取任务的线程池(再次强调,除非你非常清楚自己的需求,否则一般不要使用没有线程数量上限的线程池),然后使用 HttpClient 实现 HTTP 请求,把请求任务循环提交到线程池处理,最后等待所有任务执行完成后输出执行耗时:
private int sendRequest(int count, Supplier<CloseableHttpClient> client) throws InterruptedException {
//用于计数发送的请求个数
AtomicInteger atomicInteger = new AtomicInteger();
//使用HttpClient从server接口查询数据的任务提交到线程池并行处理
ExecutorService threadPool = Executors.newCachedThreadPool();
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, count).forEach(i -> {
threadPool.execute(() -> {
try (CloseableHttpResponse response = client.get().execute(new HttpGet("http://127.0.0.1:45678/routelimit/server"))) {
atomicInteger.addAndGet(Integer.parseInt(EntityUtils.toString(response.getEntity())));
} catch (Exception ex) {
ex.printStackTrace();
}
});
});
//等到count个任务全部执行完毕
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
log.info("发送 {} 次请求,耗时 {} ms", atomicInteger.get(), System.currentTimeMillis() - begin);
return atomicInteger.get();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
首先,使用默认的 PoolingHttpClientConnectionManager 构造的 CloseableHttpClient,测试一下爬取 10 次的耗时:
static CloseableHttpClient httpClient1;
static {
httpClient1 = HttpClients.custom().setConnectionManager(new PoolingHttpClientConnectionManager()).build();
}
@GetMapping("wrong")
public int wrong(@RequestParam(value = "count", defaultValue = "10") int count) throws InterruptedException {
return sendRequest(count, () -> httpClient1);
}
2
3
4
5
6
7
8
9
10
虽然一个请求需要 1 秒执行完成,但我们的线程池是可以扩张使用任意数量线程的。按道理说,10 个请求并发处理的时间基本相当于 1 个请求的处理时间,也就是 1 秒,但日志中显示实际耗时 5 秒:
[12:48:48.122] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.h.r.RouteLimitController :54 ] - 发送 10 次请求,耗时 5265 ms
查看 PoolingHttpClientConnectionManager 源码,可以注意到有两个重要参数:
- defaultMaxPerRoute=2,也就是同一个主机 / 域名的最大并发请求数为 2。我们的爬虫需要 10 个并发,显然是默认值太小限制了爬虫的效率
- maxTotal=20,也就是所有主机整体最大并发为 20,这也是 HttpClient 整体的并发度。目前,我们请求数是 10 最大并发是 10,20 不会成为瓶颈。举一个例子,使用同一个 HttpClient 访问 10 个域名,defaultMaxPerRoute 设置为 10,为确保每一个域名都能达到 10 并发,需要把 maxTotal 设置为 100。
public PoolingHttpClientConnectionManager(
final HttpClientConnectionOperator httpClientConnectionOperator,
final HttpConnectionFactory<HttpRoute, ManagedHttpClientConnection> connFactory,
final long timeToLive, final TimeUnit timeUnit) {
...
this.pool = new CPool(new InternalConnectionFactory(
this.configData, connFactory), 2, 20, timeToLive, timeUnit);
...
}
public CPool(
final ConnFactory<HttpRoute, ManagedHttpClientConnection> connFactory,
final int defaultMaxPerRoute, final int maxTotal,
final long timeToLive, final TimeUnit timeUnit) {
...
}}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
HttpClient 是 Java 非常常用的 HTTP 客户端,这个问题经常出现。你可能会问,为什么默认值限制得这么小。
其实,这不能完全怪 HttpClient,很多早期的浏览器也限制了同一个域名两个并发请求。对于同一个域名并发连接的限制,其实是 HTTP 1.1 协议要求的,这里有这么一段话:
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. A proxy SHOULD use up to 2*N connections to another server or proxy, where N is the number of simultaneously active users. These guidelines are intended to improve HTTP response times and avoid congestion.
HTTP 1.1 协议是 20 年前制定的,现在 HTTP 服务器的能力强很多了,所以有些新的浏览器没有完全遵从 2 并发这个限制,放开并发数到了 8 甚至更大。如果需要通过 HTTP 客户端发起大量并发请求,不管使用什么客户端,请务必确认客户端的实现默认的并发度是否满足需求。
既然知道了问题所在,我们就尝试声明一个新的 HttpClient 放开相关限制,设置 maxPerRoute 为 50、maxTotal 为 100,然后修改一下刚才的 wrong 方法,使用新的客户端进行测试:
httpClient2 = HttpClients.custom().setMaxConnPerRoute(10).setMaxConnTotal(20).build();
输出如下,10 次请求在 1 秒左右执行完成。可以看到,因为放开了一个 Host 2 个并发的默认限制,爬虫效率得到了大幅提升:
[12:58:11.333] [http-nio-45678-exec-3] [INFO ] [o.g.t.c.h.r.RouteLimitController :54 ] - 发送 10 次请求,耗时 1023 ms
# 问题解答
问题 1:ThreadLocalRandom 是 Java 7 引入的一个生成随机数的类。你觉得可以把它的实例设置到静态变量中,在多线程情况下重用吗?
答案:不能
ThreadLocalRandom 文档里有这么一条:Usages of this class should typically be of the form: ThreadLocalRandom.current().nextX(…) (where X is Int, Long, etc). When all usages are of this form, it is never possible to accidently share a ThreadLocalRandom across multiple threads.
那为什么规定要 ThreadLocalRandom.current().nextX(…) 这样来使用呢?
current() 的时候初始化一个初始化种子到线程,每次 nextseed 再使用之前的种子生成新的种子:
UNSAFE.putLong(t = Thread.currentThread(), SEED, r = UNSAFE.getLong(t, SEED) + GAMMA);1如果通过主线程调用一次 current 生成一个 ThreadLocalRandom 的实例保存起来,那么其它线程来获取种子的时候必然取不到初始种子,必须是每一个线程自己用的时候初始化一个种子到线程。可以在 nextSeed 方法设置一个断点来测试:
UNSAFE.getLong(Thread.currentThread(),SEED);1问题 2:ConcurrentHashMap 还提供了 putIfAbsent 方法,能否通过查阅JDK 文档,说说 computeIfAbsent 和 putIfAbsent 方法的区别?
答:computeIfAbsent 和 putIfAbsent 这两个方法,都是判断值不存在的时候为 Map 进行赋值的原子方法,它们的区别具体包括以下三个方面:
- 当 Key 存在的时候,如果 Value 的获取比较昂贵的话,putIfAbsent 方法就会白白浪费时间在获取这个昂贵的 Value 上(这个点特别注意),而 computeIfAbsent 则会因为传入的是 Lambda 表达式而不是实际值不会有这个问题。
- Key 不存在的时候,putIfAbsent 会返回 null,这时候我们要小心空指针;而 computeIfAbsent 会返回计算后的值,不存在空指针的问题。
- 当 Key 不存在的时候,putIfAbsent 允许 put null 进去,而 computeIfAbsent 不能(当然了,此条针对 HashMap,ConcurrentHashMap 不允许 put null value 进去)。
问题 3:在代码加锁开头的例子里,为变量 a、b 都使用了 volatile 关键字进行修饰, volatile 关键字的作用是什么?有这样一个坑:开启了一个线程无限循环来跑一些任务,有一个 bool 类型的变量来控制循环的退出,默认为 true 代表执行,一段时间后主线程将这个变量设置为了 false。如果这个变量不是 volatile 修饰的,子线程可以退出吗?能否解释其中的原因呢?
答:不能退出。比如下面的代码,3 秒后另一个线程把 b 设置为 false,但是主线程无法退出:
private static boolean b = true; public static void main(String[] args) throws InterruptedException { new Thread(()->{ try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { } b =false; }).start(); while (b) { TimeUnit.MILLISECONDS.sleep(0); } System.out.println("done"); }1
2
3
4
5
6
7
8
9
10
11
12
13其实,这是可见性的问题。
虽然另一个线程把 b 设置为了 false,但是这个字段在 CPU 缓存中,另一个线程(主线程)还是读不到最新的值。使用 volatile 关键字,可以让数据刷新到主内存中去。准确来说,让数据刷新到主内存中去是两件事情:
- 将当前处理器缓存行的数据,写回到系统内存;
- 这个写回内存的操作会导致其他 CPU 里缓存了该内存地址的数据变为无效。
当然,使用 AtomicBoolean 等关键字来修改变量 b 也行。但相比 volatile 来说,AtomicBoolean 等关键字除了确保可见性,还提供了 CAS 方法,具有更多的功能,在本例的场景中用不到。
volatile 关键字原理可见这篇文章:Java 并发 - 关键字 volatile
问题 4:关于代码加锁还有两个坑,一是加锁和释放没有配对的问题,二是分布式锁自动释放导致的重复逻辑执行的问题。有什么方法来发现和解决这两个问题吗?
答:针对加解锁没有配对的问题,我们可以用一些代码质量工具或代码扫描工具(比如 Sonar)来帮助排查。这个问题在编码阶段就能发现。
针对分布式锁超时自动释放问题,可以参考 Redisson 的 RedissonLock 的锁续期机制。锁续期是每次续一段时间,比如 30 秒,然后 10 秒执行一次续期。虽然是无限次续期,但即使客户端崩溃了也没关系,不会无限期占用锁,因为崩溃后无法自动续期自然最终会超时。
问题 5:实现一个激进创建线程的弹性线程池,能给出相关的实现吗?实现后再测试一下,是否所有的任务都可以正常处理完成呢?
答:我们按照文中提到的两个思路来实现一下激进线程池:
- 由于线程池在工作队列满了无法入队的情况下会扩容线程池,那么我们可以重写队列的 offer 方法,造成这个队列已满的假象;
- 由于我们 Hack 了队列,在达到了最大线程后势必会触发拒绝策略,那么我们还需要实现一个自定义的拒绝策略处理程序,这个时候再把任务真正插入队列。
完整的实现代码以及相应的测试代码如下:
@GetMapping("better") public int better() throws InterruptedException { //这里开始是激进线程池的实现 BlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>(10) { @Override public boolean offer(Runnable e) { //先返回false,造成队列满的假象,让线程池优先扩容 return false; } }; ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 2, 5, 5, TimeUnit.SECONDS, queue, new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get(), (r, executor) -> { try { //等出现拒绝后再加入队列 //如果希望队列满了阻塞线程而不是抛出异常,那么可以注释掉下面三行代码,修改为executor.getQueue().put(r); if (!executor.getQueue().offer(r, 0, TimeUnit.SECONDS)) { throw new RejectedExecutionException("ThreadPool queue full, failed to offer " + r.toString()); } } catch (InterruptedException e) { Thread.currentThread().interrupt(); } }); //激进线程池实现结束 printStats(threadPool); //每秒提交一个任务,每个任务耗时10秒执行完成,一共提交20个任务 //任务编号计数器 AtomicInteger atomicInteger = new AtomicInteger(); IntStream.rangeClosed(1, 20).forEach(i -> { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } int id = atomicInteger.incrementAndGet(); try { threadPool.submit(() -> { log.info("{} started", id); try { TimeUnit.SECONDS.sleep(10); } catch (InterruptedException e) { } log.info("{} finished", id); }); } catch (Exception ex) { log.error("error submitting task {}", id, ex); atomicInteger.decrementAndGet(); } }); TimeUnit.SECONDS.sleep(60); return atomicInteger.intValue(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58使用这个激进的线程池可以处理完这 20 个任务,因为我们优先开启了更多线程来处理任务。
[10:57:16.092] [demo-threadpool-4] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:157 ] - 20 finished [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:22 ] - ========================= [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:23 ] - Pool Size: 5 [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:24 ] - Active Threads: 0 [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:25 ] - Number of Tasks Completed: 20 [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:26 ] - Number of Tasks in Queue: 0 [10:57:17.062] [pool-8-thread-1] [INFO ] [o.g.t.c.t.t.ThreadPoolOOMController:28 ] - =========================1
2
3
4
5
6
7问题 6:在讲务必确认清楚线程池本身是不是复用时,我们改进了 ThreadPoolHelper 使其能够返回复用的线程池。如果我们不小心每次都创建了这样一个自定义的线程池(10 核心线程,50 最大线程,2 秒回收的),反复执行测试接口线程,最终可以被回收吗?会出现 OOM 问题吗?
答:会因为创建过多线程导致 OOM,因为默认情况下核心线程不会回收,并且 ThreadPoolExecutor 也回收不了。
我们可以看看它的源码,工作线程 Worker 是内部类,只要它活着,换句话说就是线程在跑,就会阻止 ThreadPoolExecutor 回收:
public class ThreadPoolExecutor extends AbstractExecutorService { private final class Worker extends AbstractQueuedSynchronizer implements Runnable { } }1
2
3
4
5
6
7因此,我们不能认为 ThreadPoolExecutor 没有引用,就能回收。
问题 7:有了连接池之后,获取连接是从连接池获取,没有足够连接时连接池会创建连接。这时,获取连接操作往往有两个超时时间:一个是从连接池获取连接的最长等待时间,通常叫作请求连接超时 connectRequestTimeout,或连接等待超时 connectWaitTimeout;一个是连接池新建 TCP 连接三次握手的连接超时,通常叫作连接超时 connectTimeout。针对 JedisPool、Apache HttpClient 和 Hikari 数据库连接池,你知道如何设置这 2 个参数吗?
答:假设我们希望设置连接超时 5s、请求连接超时 10s,下面我来演示下,如何配置 Hikari、Jedis 和 HttpClient 的两个超时参数。
针对 Hikari,设置两个超时时间的方式,是修改数据库连接字符串中的 connectTimeout 属性和配置文件中的 hikari 配置的 connection-timeout:
spring.datasource.hikari.connection-timeout=10000 spring.datasource.url=jdbc:mysql://localhost:6657/common_mistakes?connectTimeout=5000&characterEncoding=UTF-8&useSSL=false&rewriteBatchedStatements=true1
2
3针对 Jedis,是设置 JedisPoolConfig 的 MaxWaitMillis 属性和设置创建 JedisPool 时的 timeout 属性:
JedisPoolConfig config = new JedisPoolConfig(); config.setMaxWaitMillis(10000); try (JedisPool jedisPool = new JedisPool(config, "127.0.0.1", 6379, 5000); Jedis jedis = jedisPool.getResource()) { return jedis.set("test", "test"); }1
2
3
4
5
6针对 HttpClient,是设置 RequestConfig 的 ConnectionRequestTimeout 和 ConnectTimeout 属性:
RequestConfig requestConfig = RequestConfig.custom() .setConnectTimeout(5000) .setConnectionRequestTimeout(10000) .build(); HttpGet httpGet = new HttpGet("http://127.0.0.1:45678/twotimeoutconfig/test"); httpGet.setConfig(requestConfig); try (CloseableHttpResponse response = httpClient.execute(httpGet)) { return EntityUtils.toString(response.getEntity()); } catch (Exception ex) { ex.printStackTrace(); } return null;1
2
3
4
5
6
7
8
9
10
11
12问题 8:对于带有连接池的 SDK 的使用姿势,最主要的是鉴别其内部是否实现了连接池,如果实现了连接池要尽量复用 Client。对于 NoSQL 中的 MongoDB 来说,使用 MongoDB Java 驱动时,MongoClient 类应该是每次都创建还是复用呢?你能否在官方文档中找到答案呢?
答:官方文档里有这么一段话:Typically you only create one MongoClient instance for a given MongoDB deployment (e.g. standalone, replica set, or a sharded cluster) and use it across your application. However, if you do create multiple instances:All resource usage limits (e.g. max connections, etc.) apply per MongoClient instance.To dispose of an instance, call MongoClient.close() to clean up resources.
MongoClient 类应该尽可能复用(一个 MongoDB 部署只使用一个 MongoClient),不过复用不等于在任何情况下就只用一个。正如文档里所说,每一个 MongoClient 示例有自己独立的资源限制。
问题 9:在“配置连接超时和读取超时参数的学问”这一节中,我们强调了要注意连接超时和读取超时参数的配置,大多数的 HTTP 客户端也都有这两个参数。有读就有写,但为什么我们很少看到“写入超时”的概念呢?
答:其实写入操作只是将数据写入 TCP 的发送缓冲区,已经发送到网络的数据依然需要暂存在发送缓冲区中,只有收到对方的 ack 后,操作系统内核才从缓冲区中清除这一部分数据,为后续发送数据腾出空间。
如果接收端从 socket 读取数据的速度太慢,可能会导致发送端发送缓冲区满,导致写入操作阻塞,产生写入超时。但是,因为有滑动窗口的控制,通常不太容易发生发送缓冲区满导致写入超时的情况。相反,读取超时包含了服务端处理数据执行业务逻辑的时间,所以读取超时是比较容易发生的。
这也就是为什么我们一般都会比较重视读取超时而不是写入超时的原因了。
问题 10:除了 Ribbon 的 AutoRetriesNextServer 重试机制,Nginx 也有类似的重试功能。你了解 Nginx 相关的配置吗?
答:关于 Nginx 的重试功能,你可以参考这里,了解下 Nginx 的 proxy_next_upstream 配置。
proxy_next_upstream,用于指定在什么情况下 Nginx 会将请求转移到其他服务器上。其默认值是 proxy_next_upstream error timeout,即发生网络错误以及超时,才会重试其他服务器。也就是说,默认情况下,服务返回 500 状态码是不会重试的。
如果我们想在请求返回 500 状态码时也进行重试,可以配置:
proxy_next_upstream error timeout http_500;1需要注意的是,proxy_next_upstream 配置中有一个选项 non_idempotent,一定要小心开启。通常情况下,如果请求使用非等幂方法(POST、PATCH),请求失败后不会再到其他服务器进行重试。但是,加上 non_idempotent 这个选项后,即使是非幂等请求类型(例如 POST 请求),发生错误后也会重试。
# 参考
- 来源:极客时间《Java 业务开发常见错误 100例》