 Map - LinkedHashMap & LinkedHashSet 源码解析
Map - LinkedHashMap & LinkedHashSet 源码解析
# Map - LinkedHashMap & LinkedHashSet 源码解析
# LinkedHashMap
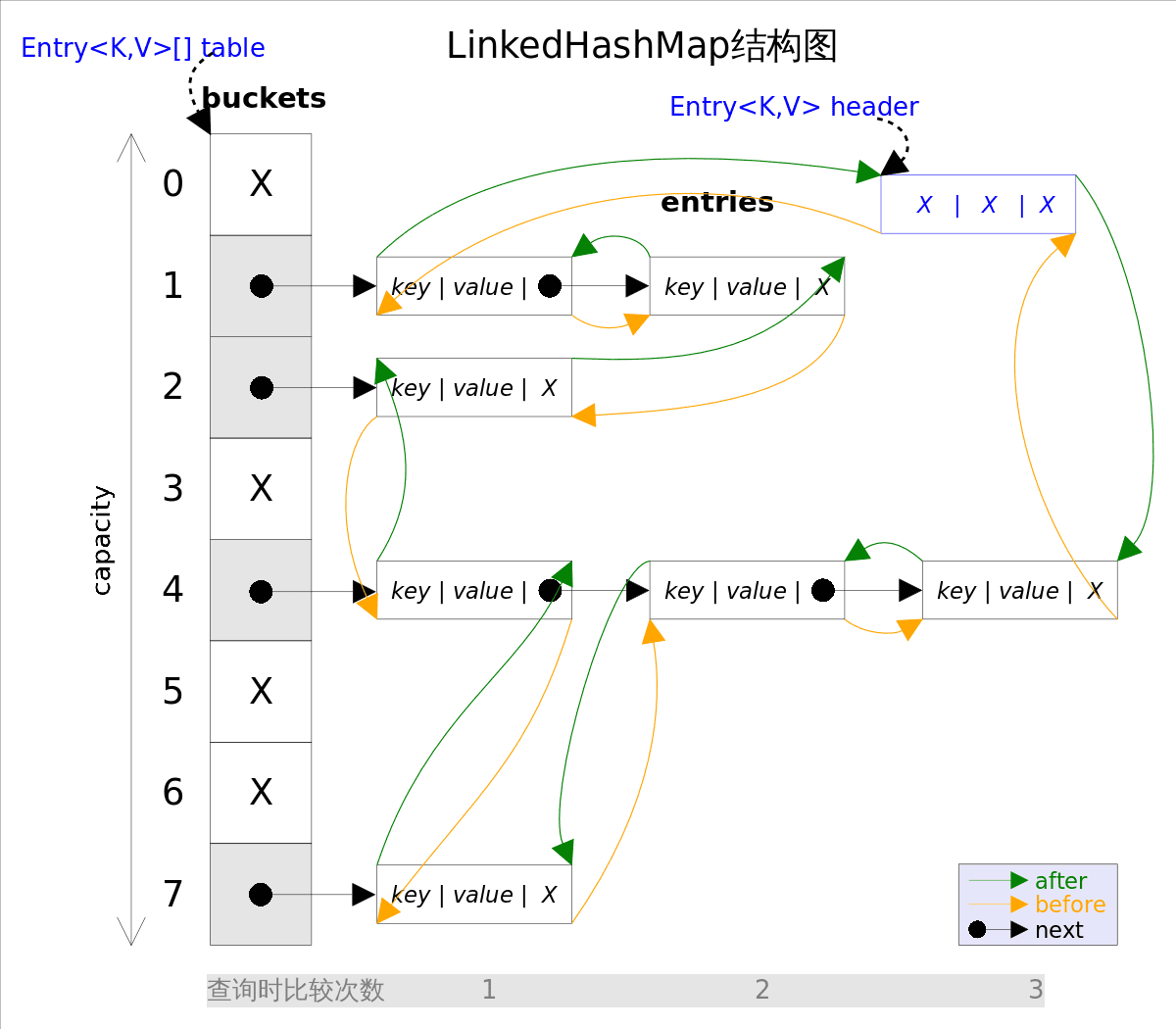
# 1. 介绍
# 1.1 HashMap 无法保证顺序
对于 HashMap 而言,将数据放入其中后,如果我们需要遍历 map 中的所有元素,可以这么做:
- 通过 map.entrySet() 来获取包含所有数据的set,对该 set 进行遍历;
- 通过 map.keySet() 获取所有的 key,然后遍历 key,调用 get 方法获取 value;
上面这两种方式都是可以进行 map 元素的遍历,但是同时也存在一个问题:数据的顺序无法保证,也就是说,在打印出所有元素前,元素的顺序是未知的。
# 1.2 如何保证 HashMap 的顺序
因为 HashMap 不能保证顺序,就需要借助其他的数据结构,比如可以额外使用一个List(比如 ArrayList ),每次加入 map 后,同时再加入 ArrayList,如果需要顺序遍历数据,则直接遍历 ArrayList 即可,就不用遍历 map 了。
但是这样的话,开销就会相对较高,首先需要创建 ArrayList,还需要每次增删元素后,都要对 ArrayList 进行操作(移动元素),时间复杂度 O(n),空间复杂度 O(n)。
# 1.3 使用 LinkedHashMap
上面使用 ArrayList 来保证数据的顺序性,当元素发生变化时,就需要移动 ArrayList 中的元素,时间复杂度 O(n),空间复杂度为 O(n),那么如果可以降低时间复杂度和空间复杂度就好了。
于是,就会联想到链表,不考虑查找元素的开销,增删元素的时间复杂度为 O(1);但是还是需要 O(n) 的空间复杂度,因为需要保存节点值,如果能把空间复杂度降下来就好了,此时就可以了解一下 LinkedHashMap。
LinkedHashMap,其实从名字上就可以看出他是功能,Linked+HashMap,说到 Linked,自然就会联系到 LinkedList,所以,LinkedhashMap 可以简单的理解为 LinkedList+HashMap。
需要注意的是,LinkedHashMap 并没有完全创建一个新的节点类型,而是在 HashMap 的 Node 内部类上进行扩充,增加前后指针,这样也是可以节省很多空间的。
# 1.4 LinkedHashMap 的顺序分类
LinkedHashMap 可以保证 HashMap 元素的顺序,这个顺序,有两种:
- 遍历元素的顺序与插入元素的顺序一致,也就是说,依次插入 A->B->C,那么遍历时的顺序就是 A->B->C;
- 初始时,遍历元素的顺序与插入的顺序一致,但是当元素被访问,也就是说,插入 A->B->C 后,遍历的顺序是 A->B->C;如果中间访问或者修改过 B,那么顺序就会变为A->C->B,
在 LinkedHashMap 中,有一个 accessOrder 属性来设定是否按照访问顺序来遍历,默认为f alse,也就是上面默认使用第一种方式。
# 1.5 LinkedHashMap使用示例
package cn.ganlixin.util;
import org.junit.Test;
import java.util.LinkedHashMap;
import java.util.Map;
public class TestLinkedHashMap {
/**
* 遍历顺序和插入顺序相同,期间访问或者修改元素,顺序不会发生改变
*/
@Test
public void testNormal() {
Map<String, String> map = new LinkedHashMap<>();
map.put("one", "1111");
map.put("two", "2222");
map.put("three", "3333");
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/** 输出如下:
one=>1111
two=>2222
three=>3333
*/
map.put("two", "2");
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/** 输出如下:
one=>1111
two=>2222
three=>3333
*/
}
/**
* 遍历顺序为访问(修改)顺序,元素被访问或者被修改后,会移到最后
*/
@Test
public void testAccessOrder() {
// public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
Map<String, String> map = new LinkedHashMap<>(16, 0.75f, true);
// 创建map时,设置遍历顺序按照访问顺序
map.put("one", "1111");
map.put("two", "2222");
map.put("three", "3333");
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/**
one=>1111
two=>2222
three=>3333
*/
map.get("one"); // 某个元素访问后,会将该元素移动到末尾
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/**
two=>2222
three=>3333
one=>1111
*/
map.put("two", "2"); // 修改元素后,也会将元素移动到最后
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/**
three=>3333
one=>1111
two=>2
*/
map.replace("three", "3"); // 修改元素后,也会将元素移动到最后
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + "=>" + entry.getValue());
}
/**
three=>3333
one=>1111
two=>2
*/
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
# 2. LinkedHashMap源码解析
# 2.1 LinkedHashMap原理概览
在阅读 LinkedHashMap 前,要先了解 HashMap 的原理,方便后面对LinkedHashMap源码的理解。
LinkedHashMap 继承自 HashMap,也就是说 HashMap 的功能,LinkedHashMap 都支持。
public class LinkedHashMap<K, V> extends HashMap<K, V> implements Map<K, V>
LinkedHashMap 对 HashMap 的部分 API 进行了重写,以此来保证 map 中元素遍历时的顺序。通过第一部分的一些介绍,其实我们大概才出 LinkedHashMap 是如何保证顺序的:
- 对于遍历顺序与插入顺序相同的情况,只需要在将元素 put 到双链表后,维护节点的指针,链入上一次 put 的节点后面(成为尾结点);
- 对于遍历顺序与访问顺序相同一致的情况,只需要在 get、put、replace..操作之后,将节点移动到末尾即可。
# 2.2 双链表的节点
LinkedHashMap 中双链表的节点类型,是直接在 HashMap 的节点类型上进行扩充的,增加了 before 和 after 指针;
/**
* 链表的节点类型Entry,继承自HashMap的Node内部类
*/
static class Entry<K, V> extends HashMap.Node<K, V> {
Entry<K, V> before, after;
Entry(int hash, K key, V value, Node<K, V> next) {
super(hash, key, value, next);
}
}
2
3
4
5
6
7
8
9
10
# 2.3 新增属性
LinkedHashMap 继承自 HashMap,也继承了 HashMap 中的所有属性,比如默认的初始容量、默认的负载因子、默认转换为红黑树和链表的阈值...
除此之前,LinkedHashMap 增加了 3 个额外的属性,其中两个属性用于实现双链表的头尾节点,另外一个属性用于控制顺序的类型:
/**
* 指向双链表的头结点(如果map为空=>双链表为空=>head为空)
*/
transient LinkedHashMap.Entry<K, V> head;
/**
* 指向双链表的尾结点(如果map为空=>双链表为空=>tail为空)
*/
transient LinkedHashMap.Entry<K, V> tail;
/**
* 设置LinkedHashMap的顺序类型
* false:表示遍历元素的顺序与插入顺序相同
* true:表示遍历元素的顺序按照访问的顺序排列,当一个数据被访问(修改)后,该数据就会移动到最后
*/
final boolean accessOrder;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 2.4 构造方法
LinkedHashMap 的构造方法,其实主要有两个点:1.设置 HashMap 的初始容量和负载因子;2.设置顺序类型(accessOrder)。
/**
* 创建LinkedHashMap,使用HashMap默认的初始容量16,默认的负载因子0.75
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* 创建LinkedHashMap,指定HashMap的初始容量,使用默认的负载因子0.75
*/
public LinkedHashMap(int initialCapacity) {
// 指定HashMap的初始容量
super(initialCapacity);
accessOrder = false;
}
/**
* 创建LinkedHashMap,指定HashMap的初始容量和负载因子
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 创建LinkedHashMap,指定HashMap初始容量和负载因子,以及是否顺序获取
*/
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* 创建LinkedHashMap,使用HashMap默认的初始容量(16)和负载因子(0.75)
* 并且将传入的map放入到LinkedHashMap中
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 2.5 LinkedHashMap 的 put
LinkedHashMap 并没有覆盖 HashMap 的 put 方法,而是直接沿用 HashMap 的 put 方法。那么 LinkedHashMap 是如何保证顺序的呢?是这样的,HashMap 在 put 的时候:
- 如果是新增节点,那么就会创建一个节点,然后放入到 map 中;
- 如果 put 操作时修改操作(也就是 put 的 key 已经存在),那么不需要创建节点,只需要修改已有节点的 value 即可;
对于第一种情况,创建节点,是 HashMap 和 LinkedHashMap 都有的,LinkedHashMap 重写了 HashMap 创建新节点的方法(newNode 和 newTreeNode 两个方法),在这个时候将新创建的节点加入链表的末尾:
/**
* HashMap的newNode,创建一个Node节点
*/
Node<K, V> newNode(int hash, K key, V value, Node<K, V> next) {
return new Node<>(hash, key, value, next);
}
/**
* HashMap中的newTreeNode,创建一个红黑树的节点
*/
TreeNode<K, V> newTreeNode(int hash, K key, V value, Node<K, V> next) {
return new TreeNode<>(hash, key, value, next);
}
/**
* LinkedHashMap重写HashMap的newNode方法,
* 创建一个双链表节点,同时将新节点作为双链表的尾结点
*/
@Override
Node<K, V> newNode(int hash, K key, V value, Node<K, V> e) {
// 创建双链表节点
LinkedHashMap.Entry<K, V> p = new LinkedHashMap.Entry<K, V>(hash, key, value, e);
// 将新创建的节点加入链表尾部
linkNodeLast(p);
return p;
}
/**
* LinkedHashMap重写HashMap的newTreeNode方法
* 创建一个红黑树的节点,并将节点加入到双链表的最后
*/
@Override
TreeNode<K, V> newTreeNode(int hash, K key, V value, Node<K, V> next) {
TreeNode<K, V> p = new TreeNode<K, V>(hash, key, value, next);
// 将新创建的节点加入链表尾部
linkNodeLast(p);
return p;
}
/**
* 将节点加入链表中(挂在最后位置)
*/
private void linkNodeLast(LinkedHashMap.Entry<K, V> p) {
// tail指向的尾结点
LinkedHashMap.Entry<K, V> last = tail;
tail = p;
if (last == null) {
// last==null,证明插入节点前链表为空,此时head也需要指向p
head = p;
} else {
// 插入节点前,链表不为空,维护指针关系,将p插入到最后
p.before = last;
last.after = p;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
对于put方法,进行了替换操作,就需要用到后面说的一些 post-actions(后置处理)来完成顺序的保证。
# 2.6 some post-actions
由于 LinkedHashMap 是继承自 HashMap,并且大部分的代码都没有做更改,也就是直接沿用 HashMap 的接口。那么 LinkedHashMap是如何保证顺序的呢?特别是前面说的保证插入的顺序,保证访问的顺序??
其实 HashMap 的一些 API 中,比如 put 方法,其中就包含了一些 callback,当插入元素或者查找到元素后,就调用某个方法;这些callback 方法在 HashMap 中没有进行任何操作(方法体为空),留给子类 LinkedHashMap 进行实现的,如下面所示:
// Callbacks to allow LinkedHashMap post-actions
/**
* 当节点被访问后调用,比如
*
* @param p 被访问的节点
*/
void afterNodeAccess(Node<K, V> p) {
}
/**
* 当元素添加到map后,执行的操作
* @param evict
*/
void afterNodeInsertion(boolean evict) {
}
/**
* 当元素被移除后,执行的操作
* @param p 被移除的节点
*/
void afterNodeRemoval(Node<K, V> p) {
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 2.6.1 afterNodeAccess
afterNodeAccess 方法,是在元素节点被访问之后被调用,主要是以下几种(一部分):
- get 操作
- put 操作,如果是替换,那么就会先查找是否存在已有节点,若发现已经存在该节点(则该节点被访问),就会回调afterNodeAccess 方法;
- 遍历操作
在 LinkedHashMap 中 afterNodeAccess,主要执行的就是将元素移动到链表的最后,前提是 accessOrder 为 true(在访问元素后,就将元素移动到链表移动到最后)。
/**
* accessOrder为true时,表示map中元素保持和访问的顺序相同
* 所以需要将访问的节点移动到双链表的末尾
*
* @param e 包含元素最新值的Node节点
*/
void afterNodeAccess(Node<K, V> e) { // move node to last
LinkedHashMap.Entry<K, V> last;
// accessOrder为true,表示map中数据的顺序按照访问顺序排序
// 如果e不是最后一个元素才进行操作(因为
if (accessOrder && (last = tail) != e) {
// p指向e,b指向e的前继节点,a指向e的后继节点
LinkedHashMap.Entry<K, V> p = (LinkedHashMap.Entry<K, V>) e, b = p.before, a = p.after;
// 将p的后继设为null(因为要将其设为尾结点,尾结点的after为null)
p.after = null;
if (b == null) {
// e的前继节点为null,证明e为头结点,则将e的后继节点设置为新头结点
head = a;
} else {
// e不是头结点,则将e的后继节点设置为前继节点的后继节点
b.after = a;
}
if (a != null) {
// e节点不是尾结点,那么就将e的前继节点设置为后继节点的前继节点
a.before = b;
} else {
// e的后继节点为null,证明e为尾结点,则将e的前继节点设置为尾结点
last = b;
}
if (last == null) {
// 如果修改指针关系(删除e后),last为null,也就是尾结点为null,证明链表为空了
// 此时将p节点(也就是e节点)作为头结点
head = p;
} else {
// 链表不为null,则将e节点挂到最后
p.before = last;
last.after = p;
}
// tail指针指向e节点
tail = p;
// 修改次数加1
++modCount;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 2.6.2 afterNodeInsertion
afterNodeInsertion 方法是在 HashMap 的 put 和 putAll 方法调用后执行的,主要做的就是删除链表的头结点。
在 LinkedHashMap 中,默认是不会每次删除头结点的,如果需要加入节点后进行删除头结点,则需要另外创建子类进行实现逻辑。
上面提到一个 eldestEntry,也就是最老的 Entry,其实也就是链表的头结点(accessOrder=false->最早插入,accessOrder=true->最久未访问)。
# 2.6.3 afterNodeRemoval
当调用 LinkedHashMap 的 remove 接口,其实也就是调用 HashMap 的 remove 接口(LinkedHashMap 没有重写该接口)。
在 HashMap 中移除元素后,会回调 afterNodeRemoval 方法,该方法在 HashMap 中并做任何操作,而是留给子类 LinkedHashMap 进行定义对应的操作,LinkedHashMap 做的就是维护链表指针,将删除的元素从链表中删除。
/**
* LinkedHashMap删除元素后,维护链表间的指针关系,将节点从双链表中删除
*/
@Override
void afterNodeRemoval(Node<K, V> e) { // unlink
LinkedHashMap.Entry<K, V> p = (LinkedHashMap.Entry<K, V>) e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null) {
// b为e的前继节点,如果前继节点为null,证明e为头结点,则将第二个节点(e的后继)作为新的头结点
head = a;
} else {
// e不是头结点,维护前继和后继的关系
b.after = a;
}
if (a == null) {
// 后继节点为空,表示e为尾结点,此时将e的前继节点b作为尾结点
tail = b;
} else {
// e不是尾结点,则前继和后继的关系
a.before = b;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 2.6.4 internalWriteEntries
当序列化 map 的时候(使用 ObjectOutputStream),会调用 HashMap 中的 writeObject 方法
/**
* 调用ObjectOutputStream来序列化map时,会调用writeObject方法
*/
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
int buckets = capacity();
// 将一些属性写入到流中
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
// 将数据写入
internalWriteEntries(s);
}
/**
* HashMap中的实现,将map中的数据顺序写入
*/
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
Node<K, V>[] tab;
// 如果map不为空,则遍历数组的每个位置进行操作
if (size > 0 && (tab = table) != null) {
for (int i = 0; i < tab.length; ++i) {
// 每个位置可能是链表或者红黑树结构,则进行遍历时写入
for (Node<K, V> e = tab[i]; e != null; e = e.next) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
internalWriteEntries 方法,就是在输出的时候决定数据的顺序,可以看到上面是 HashMap的internalWriteEntries 方法,是依次遍历数组的每个位置,然后遍历每个位置上的链表或者红黑树,这个时候顺序并没有什么规律。而 LinkedHashMap,只是重写了internalWriteEntries 方法,在其中对顺序进行调整:
/**
* LinkedHashMap中的实现
*/
void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
// 遍历双链表,从头到尾进行遍历,保证了顺序
for (LinkedHashMap.Entry<K, V> e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
}
2
3
4
5
6
7
8
9
10
# 2.7 LinkedHashMap.get 方法
/**
* 获取key对应的值
*/
public V get(Object key) {
Node<K, V> e;
// 调用HashMap中的getNode
if ((e = getNode(hash(key), key)) == null) {
return null;
}
// 如果设置的顺序是按照访问顺序,那么就需要在访问节点后,将节点移到末尾
if (accessOrder) {
afterNodeAccess(e);
}
return e.value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 3. 总结
其实对于 LinkedHashMap,没有太多的需要阐述的,更多的应该是看 HashMap,因为维护节点顺序的操作都是在 HashMap 中进行回调的。
简单理解 LinkedHashMap,也就是利用双链表数据结构,在 HashMap 的 Node 节点类型上增加前后指针,每次访问或者修改节点后,会回调相关的 callback,进行节点顺序的维护。节点的顺序可以分为插入顺序和访问顺序,通过 accessOrder 进行控制。
# 4. 常见的面试题
一般是问LinkedHashMap的原理,比如:
- 节点类型
- 底层是双链表还是单链表
- 节点的顺序(accessOrder)
- 几个扩展点(afterNodeAccess、afterNodeInsertion、afterNodeRemoval)
而关于节点的顺序,如果时间长了,可能会忘记,这里简单记一下:对于 accessOrder 为 false,也就是默认情况下,遍历时元素的顺序只与插入的顺序有关;如果某个 key 对应的数据已经存在,再次put、replace 该 key 后,元素的顺序不会发生改变。对于 accessOrder 为 true,将元素加入 map 后:1.在没有访问的情况下,遍历map元素,顺序与插入顺序一致;2.访问元素(access),包括get、put、replace操作,无论是替换还是新增,元素都将移动到最后!!
# 5. LinkedHashSet
LinkedHashSet 是对 LinkedHashMap 的简单包装,对 LinkedHashSet 的函数调用都会转换成合适的 LinkedHashMap 方法,因此 LinkedHashSet 的实现非常简单,这里不再赘述。
# 6. 参考
- https://www.cnblogs.com/-beyond/p/13412164.html
- https://pdai.tech/md/java/collection/java-map-LinkedHashMap&LinkedHashSet.html