 Java 业务开发常见错误(三)
Java 业务开发常见错误(三)
# Java 业务开发常见错误(三)
# 异常处理
# 捕获和处理异常容易犯的错
“统一异常处理”方式为第一个错:不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。
“统一异常处理”方式正是我要说的第一个错:不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。
- Controller 层负责信息收集、参数校验、转换服务层处理的数据适配前端,轻业务逻辑;
- Service 层负责核心业务逻辑,包括各种外部服务调用、访问数据库、缓存处理、消息处理等;
- Repository 层负责数据访问实现,一般没有业务逻辑。

每层架构的工作性质不同,且从业务性质上异常可能分为业务异常和系统异常两大类,这就决定了很难进行统一的异常处理。我们从底向上看一下三层架构:
- Repository 层出现异常或许可以忽略,或许可以降级,或许需要转化为一个友好的异常。如果一律捕获异常仅记录日志,很可能业务逻辑已经出错,而用户和程序本身完全感知不到。
- Service 层往往涉及数据库事务,出现异常同样不适合捕获,否则事务无法自动回滚。此外 Service 层涉及业务逻辑,有些业务逻辑执行中遇到业务异常,可能需要在异常后转入分支业务流程。如果业务异常都被框架捕获了,业务功能就会不正常。
- 如果下层异常上升到 Controller 层还是无法处理的话,Controller 层往往会给予用户友好提示,或是根据每一个 API 的异常表返回指定的异常类型,同样无法对所有异常一视同仁。
因此不建议在框架层面进行异常的自动、统一处理,尤其不要随意捕获异常。但,框架可以做兜底工作。如果异常上升到最上层逻辑还是无法处理的话,可以以统一的方式进行异常转换,比如通过 @RestControllerAdvice + @ExceptionHandler,来捕获这些“未处理”异常:
- 对于自定义的业务异常,以 Warn 级别的日志记录异常以及当前 URL、执行方法等信息后,提取异常中的错误码和消息等信息,转换为合适的 API 包装体返回给 API 调用方;
- 对于无法处理的系统异常,以 Error 级别的日志记录异常和上下文信息(比如 URL、参数、用户 ID)后,转换为普适的“服务器忙,请稍后再试”异常信息,同样以 API 包装体返回给调用方。
比如,下面这段代码的做法:
@RestControllerAdvice
@Slf4j
public class RestControllerExceptionHandler {
private static int GENERIC_SERVER_ERROR_CODE = 2000;
private static String GENERIC_SERVER_ERROR_MESSAGE = "服务器忙,请稍后再试";
@ExceptionHandler
public APIResponse handle(HttpServletRequest req, HandlerMethod method, Exception ex) {
if (ex instanceof BusinessException) {
BusinessException exception = (BusinessException) ex;
log.warn(String.format("访问 %s -> %s 出现业务异常!", req.getRequestURI(), method.toString()), ex);
return new APIResponse(false, null, exception.getCode(), exception.getMessage());
} else {
log.error(String.format("访问 %s -> %s 出现系统异常!", req.getRequestURI(), method.toString()), ex);
return new APIResponse(false, null, GENERIC_SERVER_ERROR_CODE, GENERIC_SERVER_ERROR_MESSAGE);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
出现运行时系统异常后,异常处理程序会直接把异常转换为 JSON 返回给调用方:

要做得更好,可以把相关出入参、用户信息在脱敏后记录到日志中,方便出现问题时根据上下文进一步排查。
第二个错,捕获了异常后直接生吞。在任何时候,我们捕获了异常都不应该生吞,也就是直接丢弃异常不记录、不抛出。这样的处理方式还不如不捕获异常,因为被生吞掉的异常一旦导致 Bug,就很难在程序中找到蛛丝马迹,使得 Bug 排查工作难上加难。
通常情况下,生吞异常的原因,可能是不希望自己的方法抛出受检异常,只是为了把异常“处理掉”而捕获并生吞异常,也可能是想当然地认为异常并不重要或不可能产生。但不管是什么原因,不管是你认为多么不重要的异常,都不应该生吞,哪怕是一个日志也好。
第三个错,丢弃异常的原始信息。我们来看两个不太合适的异常处理方式,虽然没有完全生吞异常,但也丢失了宝贵的异常信息。
比如有这么一个会抛出受检异常的方法 readFile:
private void readFile() throws IOException {
Files.readAllLines(Paths.get("a_file"));
}
2
3
像这样调用 readFile 方法,捕获异常后,完全不记录原始异常,直接抛出一个转换后异常,导致出了问题不知道 IOException 具体是哪里引起的:
@GetMapping("wrong1")
public void wrong1(){
try {
readFile();
} catch (IOException e) {
//原始异常信息丢失
throw new RuntimeException("系统忙请稍后再试");
}
}
2
3
4
5
6
7
8
9
或者是这样,只记录了异常消息,却丢失了异常的类型、栈等重要信息:
catch (IOException e) {
//只保留了异常消息,栈没有记录
log.error("文件读取错误, {}", e.getMessage());
throw new RuntimeException("系统忙请稍后再试");
}
2
3
4
5
留下的日志是这样的,看完一脸茫然,只知道文件读取错误的文件名,至于为什么读取错误、是不存在还是没权限,完全不知道。
[12:57:19.746] [http-nio-45678-exec-1] [ERROR] [.g.t.c.e.d.HandleExceptionController:35 ] - 文件读取错误, a_file
这两种处理方式都不太合理,可以改为如下方式:
catch (IOException e) {
log.error("文件读取错误", e);
throw new RuntimeException("系统忙请稍后再试");
}
2
3
4
或者,把原始异常作为转换后新异常的 cause,原始异常信息同样不会丢:
catch (IOException e) {
throw new RuntimeException("系统忙请稍后再试", e);
}
2
3
其实,JDK 内部也会犯类似的错。如一个使用 JDK10 的应用偶发启动失败的案例,日志中可以看到出现类似的错误信息:
Caused by: java.lang.SecurityException: Couldn't parse jurisdiction policy files in: unlimited
at java.base/javax.crypto.JceSecurity.setupJurisdictionPolicies(JceSecurity.java:355)
at java.base/javax.crypto.JceSecurity.access$000(JceSecurity.java:73)
at java.base/javax.crypto.JceSecurity$1.run(JceSecurity.java:109)
at java.base/javax.crypto.JceSecurity$1.run(JceSecurity.java:106)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/javax.crypto.JceSecurity.<clinit>(JceSecurity.java:105)
... 20 more
2
3
4
5
6
7
8
查看 JDK JceSecurity 类 setupJurisdictionPolicies 方法源码,发现异常 e 没有记录,也没有作为新抛出异常的 cause,当时读取文件具体出现什么异常(权限问题又或是 IO 问题)可能永远都无法知道了,对问题定位造成了很大困扰:
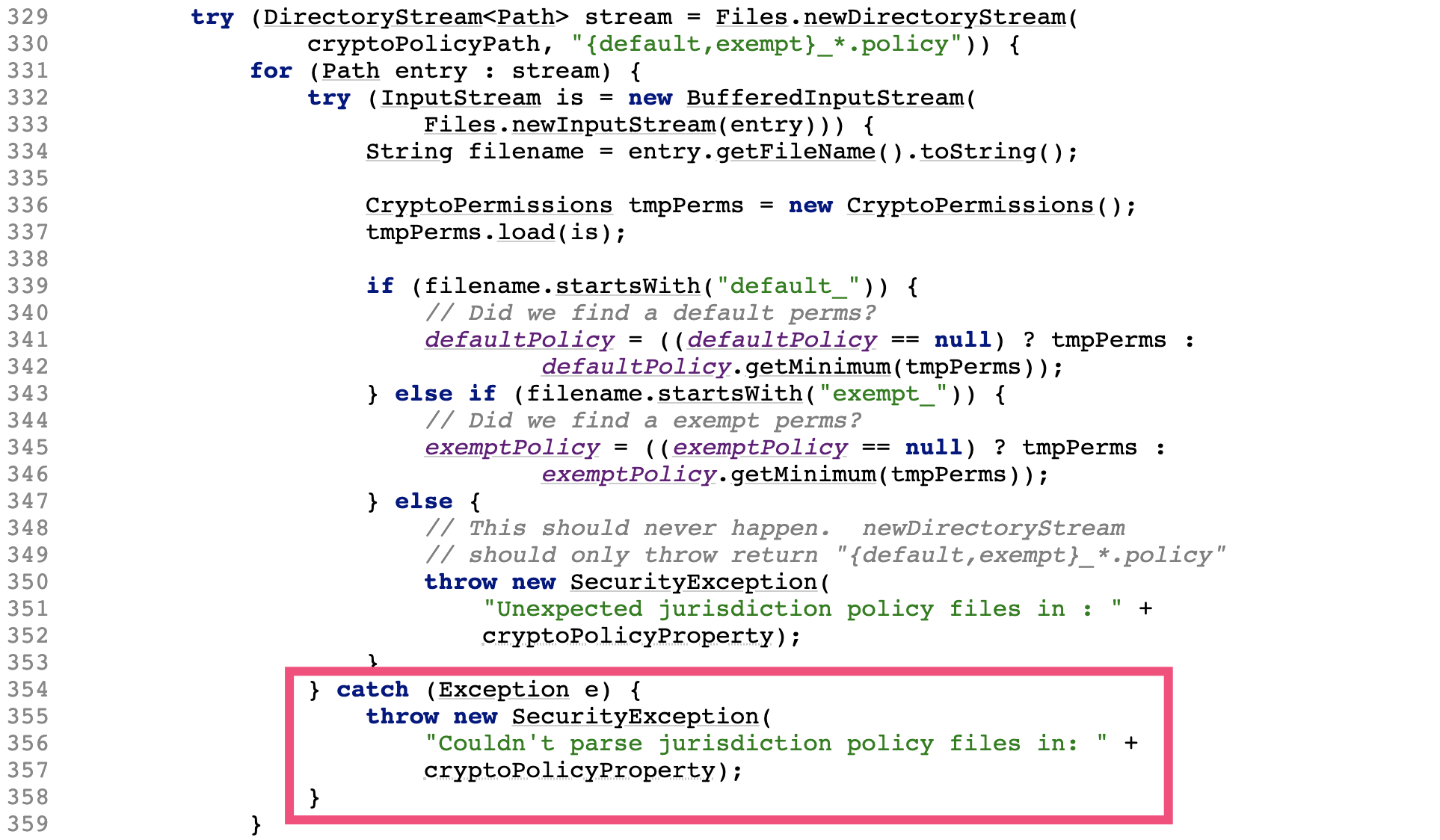
第四个错,抛出异常时不指定任何消息。我见过一些代码中的偷懒做法,直接抛出没有 message 的异常:
throw new RuntimeException();
这么写的同学可能觉得永远不会走到这个逻辑,永远不会出现这样的异常。但,这样的异常却出现了,被 ExceptionHandler 拦截到后输出了下面的日志信息:
[13:25:18.031] [http-nio-45678-exec-3] [ERROR] [c.e.d.RestControllerExceptionHandler:24 ] - 访问 /handleexception/wrong3 -> org.geekbang.time.commonmistakes.exception.demo1.HandleExceptionController#wrong3(String) 出现系统异常!
java.lang.RuntimeException: null
...
2
3
这里的 null 非常容易引起误解。按照空指针问题排查半天才发现,其实是异常的 message 为空。
总之,如果捕获了异常打算处理的话,除了通过日志正确记录异常原始信息外,通常还有三种处理模式:
- 转换,即转换新的异常抛出。对于新抛出的异常,最好具有特定的分类和明确的异常消息,而不是随便抛一个无关或没有任何信息的异常,并最好通过 cause 关联老异常。
- 重试,即重试之前的操作。比如远程调用服务端过载超时的情况,盲目重试会让问题更严重,需要考虑当前情况是否适合重试。
- 恢复,即尝试进行降级处理,或使用默认值来替代原始数据。
以上,就是通过 catch 捕获处理异常的一些最佳实践。
# 小心 finally 中的异常
有些时候,我们希望不管是否遇到异常,逻辑完成后都要释放资源,这时可以使用 finally 代码块而跳过使用 catch 代码块。
但要千万小心 finally 代码块中的异常,因为资源释放处理等收尾操作同样也可能出现异常。比如下面这段代码,我们在 finally 中抛出一个异常:
@GetMapping("wrong")
public void wrong() {
try {
log.info("try");
//异常丢失
throw new RuntimeException("try");
} finally {
log.info("finally");
throw new RuntimeException("finally");
}
}
2
3
4
5
6
7
8
9
10
11
最后在日志中只能看到 finally 中的异常,虽然 try 中的逻辑出现了异常,但却被 finally 中的异常覆盖了。这是非常危险的,特别是 finally 中出现的异常是偶发的,就会在部分时候覆盖 try 中的异常,让问题更不明显:
[13:34:42.247] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is java.lang.RuntimeException: finally] with root cause
java.lang.RuntimeException: finally
2
至于异常为什么被覆盖,原因也很简单,因为一个方法无法出现两个异常。修复方式是,finally 代码块自己负责异常捕获和处理:
@GetMapping("right")
public void right() {
try {
log.info("try");
throw new RuntimeException("try");
} finally {
log.info("finally");
try {
throw new RuntimeException("finally");
} catch (Exception ex) {
log.error("finally", ex);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
或者可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上:
@GetMapping("right2")
public void right2() throws Exception {
Exception e = null;
try {
log.info("try");
throw new RuntimeException("try");
} catch (Exception ex) {
e = ex;
} finally {
log.info("finally");
try {
throw new RuntimeException("finally");
} catch (Exception ex) {
if (e!= null) {
e.addSuppressed(ex);
} else {
e = ex;
}
}
}
throw e;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
运行方法可以得到如下异常信息,其中同时包含了主异常和被屏蔽的异常:
java.lang.RuntimeException: try
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:69)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
Suppressed: java.lang.RuntimeException: finally
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:75)
... 54 common frames omitted
2
3
4
5
6
7
其实这正是 try-with-resources 语句的做法,对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。比如如下我们定义一个测试资源,其 read 和 close 方法都会抛出异常:
public class TestResource implements AutoCloseable {
public void read() throws Exception{
throw new Exception("read error");
}
@Override
public void close() throws Exception {
throw new Exception("close error");
}
}
2
3
4
5
6
7
8
9
使用传统的 try-finally 语句,在 try 中调用 read 方法,在 finally 中调用 close 方法:
@GetMapping("useresourcewrong")
public void useresourcewrong() throws Exception {
TestResource testResource = new TestResource();
try {
testResource.read();
} finally {
testResource.close();
}
}
2
3
4
5
6
7
8
9
可以看到,同样出现了 finally 中的异常覆盖了 try 中异常的问题:
java.lang.Exception: close error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.close(TestResource.java:10)
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.useresourcewrong(FinallyIssueController.java:27)
2
3
而改为 try-with-resources 模式之后:
@GetMapping("useresourceright")
public void useresourceright() throws Exception {
try (TestResource testResource = new TestResource()){
testResource.read();
}
}
2
3
4
5
6
try 和 finally 中的异常信息都可以得到保留:
java.lang.Exception: read error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.read(TestResource.java:6)
...
Suppressed: java.lang.Exception: close error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.close(TestResource.java:10)
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.useresourceright(FinallyIssueController.java:35)
... 54 common frames omitted
2
3
4
5
6
7
# 千万别把异常定义为静态变量
既然我们通常会自定义一个业务异常类型,来包含更多的异常信息,比如异常错误码、友好的错误提示等,那就需要在业务逻辑各处,手动抛出各种业务异常来返回指定的错误码描述(比如对于下单操作,用户不存在返回 2001,商品缺货返回 2002 等)。
对于这些异常的错误代码和消息,我们期望能够统一管理,而不是散落在程序各处定义。这个想法很好,但稍有不慎就可能会出现把异常定义为静态变量的坑。
如某项目生产问题,诡异 bug:异常堆信息显示的方法调用路径,在当前入参的情况下根本不可能产生,项目的业务逻辑又很复杂,就始终没往异常信息是错的这方面想,总觉得是因为某个分支流程导致业务没有按照期望的流程进行。
经过艰难的排查,最终定位到原因是把异常定义为了静态变量,导致异常栈信息错乱,类似于定义一个 Exceptions 类来汇总所有的异常,把异常存放在静态字段中:
public class Exceptions {
public static BusinessException ORDEREXISTS = new BusinessException("订单已经存在", 3001);
...
}
2
3
4
把异常定义为静态变量会导致异常信息固化,这就和异常的栈一定是需要根据当前调用来动态获取相矛盾。
我们写段代码来模拟下这个问题:定义两个方法 createOrderWrong 和 cancelOrderWrong 方法,它们内部都会通过 Exceptions 类来获得一个订单不存在的异常;先后调用两个方法,然后抛出。
@GetMapping("wrong")
public void wrong() {
try {
createOrderWrong();
} catch (Exception ex) {
log.error("createOrder got error", ex);
}
try {
cancelOrderWrong();
} catch (Exception ex) {
log.error("cancelOrder got error", ex);
}
}
private void createOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}
private void cancelOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
运行程序后看到如下日志,cancelOrder got error 的提示对应了 createOrderWrong 方法。显然,cancelOrderWrong 方法在出错后抛出的异常,其实是 createOrderWrong 方法出错的异常:
[14:05:25.782] [http-nio-45678-exec-1] [ERROR] [.c.e.d.PredefinedExceptionController:25 ] - cancelOrder got error
org.geekbang.time.commonmistakes.exception.demo2.BusinessException: 订单已经存在
at org.geekbang.time.commonmistakes.exception.demo2.Exceptions.<clinit>(Exceptions.java:5)
at org.geekbang.time.commonmistakes.exception.demo2.PredefinedExceptionController.createOrderWrong(PredefinedExceptionController.java:50)
at org.geekbang.time.commonmistakes.exception.demo2.PredefinedExceptionController.wrong(PredefinedExceptionController.java:18)
2
3
4
5
修复方式很简单,改一下 Exceptions 类的实现,通过不同的方法把每一种异常都 new 出来抛出即可:
public class Exceptions {
public static BusinessException orderExists(){
return new BusinessException("订单已经存在", 3001);
}
}
2
3
4
5
# 提交线程池的任务出了异常会怎么样?
线程池常用作异步处理或并行处理。那么,把任务提交到线程池处理,任务本身出现异常时会怎样呢?
我们来看一个例子:提交 10 个任务到线程池异步处理,第 5 个任务抛出一个 RuntimeException,每个任务完成后都会输出一行日志:
@GetMapping("execute")
public void execute() throws InterruptedException {
String prefix = "test";
ExecutorService threadPool = Executors.newFixedThreadPool(1, new ThreadFactoryBuilder().setNameFormat(prefix+"%d").get());
//提交10个任务到线程池处理,第5个任务会抛出运行时异常
IntStream.rangeClosed(1, 10).forEach(i -> threadPool.execute(() -> {
if (i == 5) throw new RuntimeException("error");
log.info("I'm done : {}", i);
}));
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
观察日志可以发现两点:
...
[14:33:55.990] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:26 ] - I'm done : 4
Exception in thread "test0" java.lang.RuntimeException: error
at org.geekbang.time.commonmistakes.exception.demo3.ThreadPoolAndExceptionController.lambda$null$0(ThreadPoolAndExceptionController.java:25)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
[14:33:55.990] [test1] [INFO ] [e.d.ThreadPoolAndExceptionController:26 ] - I'm done : 6
...
2
3
4
5
6
7
8
9
- 任务 1 到 4 所在的线程是 test0,任务 6 开始运行在线程 test1。由于这里线程池通过线程工厂为线程使用统一的前缀 test 加上计数器进行命名,因此从线程名的改变可以知道因为异常的抛出老线程退出了,线程池只能重新创建一个线程。如果每个异步任务都以异常结束,那么线程池可能完全起不到线程重用的作用。
- 因为没有手动捕获异常进行处理,ThreadGroup 帮我们进行了未捕获异常的默认处理,向标准错误输出打印了出现异常的线程名称和异常信息。显然,这种没有以统一的错误日志格式记录错误信息打印出来的形式,对生产级代码是不合适的,ThreadGroup 的相关源码如下所示:
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {
parent.uncaughtException(t, e);
} else {
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
修复方式有 2 步:
- 以 execute 方法提交到线程池的异步任务,最好在任务内部做好异常处理;
- 设置自定义的异常处理程序作为保底,比如在声明线程池时自定义线程池的未捕获异常处理程序:
new ThreadFactoryBuilder()
.setNameFormat(prefix+"%d")
.setUncaughtExceptionHandler((thread, throwable)-> log.error("ThreadPool {} got exception", thread, throwable))
.get()
2
3
4
或者设置全局的默认未捕获异常处理程序:
static {
Thread.setDefaultUncaughtExceptionHandler((thread, throwable)-> log.error("Thread {} got exception", thread, throwable));
}
2
3
通过线程池 ExecutorService 的 execute 方法提交任务到线程池处理,如果出现异常会导致线程退出,控制台输出中可以看到异常信息。那么,把 execute 方法改为 submit,线程还会退出吗,异常还能被处理程序捕获到吗?
修改代码后重新执行程序可以看到如下日志,说明线程没退出,异常也没记录被生吞了:
[15:44:33.769] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 1
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 2
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 3
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 4
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 6
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 7
[15:44:33.770] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 8
[15:44:33.771] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 9
[15:44:33.771] [test0] [INFO ] [e.d.ThreadPoolAndExceptionController:47 ] - I'm done : 10
2
3
4
5
6
7
8
9
查看 FutureTask 源码可以发现,在执行任务出现异常之后,异常存到了一个 outcome 字段中,只有在调用 get 方法获取 FutureTask 结果的时候,才会以 ExecutionException 的形式重新抛出异常:
public void run() {
...
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
...
}
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
修改后的代码如下所示,我们把 submit 返回的 Future 放到了 List 中,随后遍历 List 来捕获所有任务的异常。这么做确实合乎情理。既然是以 submit 方式来提交任务,那么我们应该关心任务的执行结果,否则应该以 execute 来提交任务:
List<Future> tasks = IntStream.rangeClosed(1, 10).mapToObj(i -> threadPool.submit(() -> {
if (i == 5) throw new RuntimeException("error");
log.info("I'm done : {}", i);
})).collect(Collectors.toList());
tasks.forEach(task-> {
try {
task.get();
} catch (Exception e) {
log.error("Got exception", e);
}
});
2
3
4
5
6
7
8
9
10
11
12
执行这段程序可以看到如下的日志输出:
[15:44:13.543] [http-nio-45678-exec-1] [ERROR] [e.d.ThreadPoolAndExceptionController:69 ] - Got exception
java.util.concurrent.ExecutionException: java.lang.RuntimeException: error
2
# 日志
记录日志容易出错主要在于三个方面:
- 日志框架众多,不同的类库可能会使用不同的日志框架,如何兼容是一个问题。
- 配置复杂且容易出错。日志配置文件通常很复杂,因此有些开发同学会从其他项目或者网络上复制一份配置文件,但却不知道如何修改,甚至是胡乱修改,造成很多问题。比如,重复记录日志的问题、同步日志的性能问题、异步记录的错误配置问题。
- 日志记录本身就有些误区,比如没考虑到日志内容获取的代价、胡乱使用日志级别等。
Logback、Log4j、Log4j2、commons-logging、JDK 自带的 java.util.logging 等,都是 Java 体系的日志框架,确实非常多。而不同的类库,还可能选择使用不同的日志框架。这样一来,日志的统一管理就变得非常困难。为了解决这个问题,就有了 SLF4J(Simple Logging Facade For Java),如下图所示:
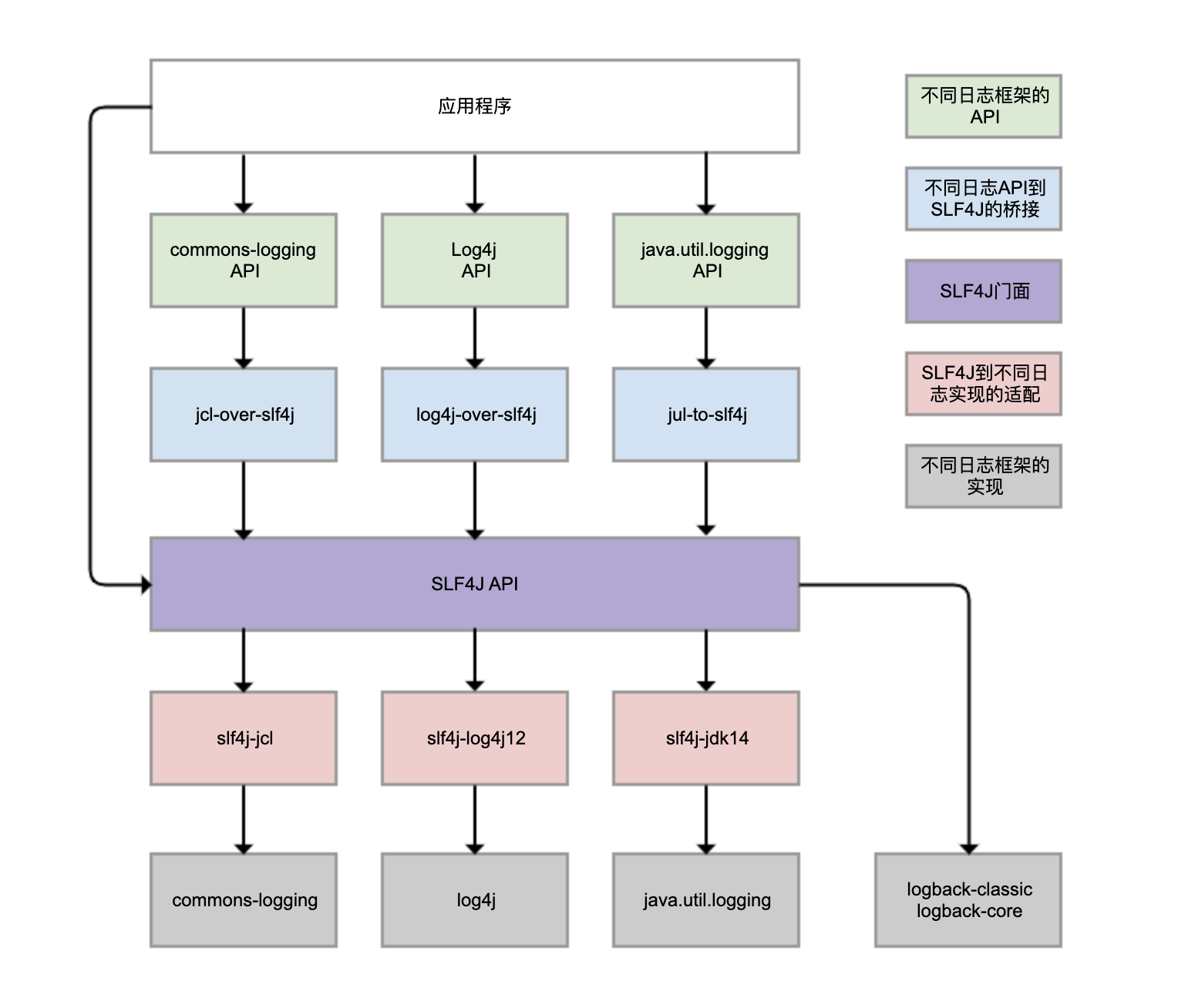
SLF4J 实现了三种功能:
- 一是提供了统一的日志门面 API,即图中紫色部分,实现了中立的日志记录 API。
- 二是桥接功能,即图中蓝色部分,用来把各种日志框架的 API(图中绿色部分)桥接到 SLF4J API。这样一来,即便你的程序中使用了各种日志 API 记录日志,最终都可以桥接到 SLF4J 门面 API。
- 三是适配功能,即图中红色部分,可以实现 SLF4J API 和实际日志框架(图中灰色部分)的绑定。SLF4J 只是日志标准,我们还是需要一个实际的日志框架。日志框架本身没有实现 SLF4J API,所以需要有一个前置转换。Logback 就是按照 SLF4J API 标准实现的,因此不需要绑定模块做转换。
需要理清楚的是,虽然我们可以使用 log4j-over-slf4j 来实现 Log4j 桥接到 SLF4J,也可以使用 slf4j-log4j12 实现 SLF4J 适配到 Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。jcl 和 jul 也是同样的道理。
虽然图中有 4 个灰色的日志实现框架,但业务系统使用最广泛的是 Logback 和 Log4j,它们是同一人开发的。Logback 可以认为是 Log4j 的改进版本,更推荐使用。所以,关于日志框架配置的案例,都会围绕 Logback 展开。
Spring Boot 是目前最流行的 Java 框架,它的日志框架也用的是 Logback。那为什么我们没有手动引入 Logback 的包,就可以直接使用 Logback 了呢?
查看 Spring Boot 的 Maven 依赖树,可以发现 spring-boot-starter 模块依赖了 spring-boot-starter-logging 模块,而 spring-boot-starter-logging 模块又帮我们自动引入了 logback-classic(包含了 SLF4J 和 Logback 日志框架)和 SLF4J 的一些适配器。其中,log4j-to-slf4j 用于实现 Log4j2 API 到 SLF4J 的桥接,jul-to-slf4j 则是实现 java.util.logging API 到 SLF4J 的桥接:

# 为什么日志会重复记录?
日志重复记录在业务上非常常见,不但给查看日志和统计工作带来不必要的麻烦,还会增加磁盘和日志收集系统的负担。
第一个案例是,logger 配置继承关系导致日志重复记录。首先,定义一个方法实现 debug、info、warn 和 error 四种日志的记录:
@Log4j2
@RequestMapping("logging")
@RestController
public class LoggingController {
@GetMapping("log")
public void log() {
log.debug("debug");
log.info("info");
log.warn("warn");
log.error("error");
}
}
2
3
4
5
6
7
8
9
10
11
12
然后,使用下面的 Logback 配置:
- 第 11 和 12 行设置了全局的日志级别为 INFO,日志输出使用 CONSOLE Appender。
- 第 3 到 7 行,首先将 CONSOLE Appender 定义为 ConsoleAppender,也就是把日志输出到控制台(System.out/System.err);然后通过 PatternLayout 定义了日志的输`出格式。关于格式化字符串的各种使用方式,你可以进一步查阅官方文档。
- 第 8 到 10 行实现了一个 Logger 配置,将应用包的日志级别设置为 DEBUG、日志输出同样使用 CONSOLE Appender。
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
</appender>
<logger name="org.geekbang.time.commonmistakes.logging" level="DEBUG">
<appender-ref ref="CONSOLE"/>
</logger>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
这段配置看起来没啥问题,但执行方法后出现了日志重复记录的问题:

从配置文件的第 9 和 12 行可以看到,CONSOLE 这个 Appender 同时挂载到了两个 Logger 上,一个是我们定义的 <logger>,一个是 <root>,由于我们定义的<logger> 继承自 <root>,所以同一条日志既会通过 logger 记录,也会发送到 root 记录,因此应用 package 下的日志出现了重复记录。
而如此配置的初衷是实现自定义的 logger 配置,让应用内的日志暂时开启 DEBUG 级别的日志记录。其实完全不需要重复挂载 Appender,去掉 <logger> 下挂载的 Appender 即可:
<logger name="org.geekbang.time.commonmistakes.logging" level="DEBUG"/>
如果自定义的 <logger> 需要把日志输出到不同的 Appender,比如将应用的日志输出到文件 app.log、把其他框架的日志输出到控制台,可以设置 <logger> 的 additivity 属性为 false,这样就不会继承 <root> 的 Appender 了:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>app.log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</encoder>
</appender>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
</appender>
<logger name="org.geekbang.time.commonmistakes.logging" level="DEBUG" additivity="false">
<appender-ref ref="FILE"/>
</logger>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
第二个案例是,错误配置 LevelFilter 造成日志重复记录。
一般互联网公司都会使用 ELK 三件套来统一收集日志,有一次我们发现 Kibana 上展示的日志有部分重复,一直怀疑是 Logstash 配置错误,但最后发现还是 Logback 的配置错误引起的。
这个项目的日志是这样配置的:在记录日志到控制台的同时,把日志记录按照不同的级别记录到两个文件中:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<property name="logDir" value="./logs" />
<property name="app.name" value="common-mistakes" />
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
</appender>
<appender name="INFO_FILE" class="ch.qos.logback.core.FileAppender">
<File>${logDir}/${app.name}_info.log</File>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
</filter>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<appender name="ERROR_FILE" class="ch.qos.logback.core.FileAppender
">
<File>${logDir}/${app.name}_error.log</File>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>WARN</level>
</filter>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="INFO_FILE"/>
<appender-ref ref="ERROR_FILE"/>
</root>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
这个配置文件比较长,一段一段地看:
- 第 31 到 35 行定义的 root 引用了三个 Appender。
- 第 5 到 9 行是第一个 ConsoleAppender,用于把所有日志输出到控制台。
- 第 10 到 19 行定义了一个 FileAppender,用于记录文件日志,并定义了文件名、记录日志的格式和编码等信息。最关键的是,第 12 到 14 行定义的 LevelFilter 过滤日志,将过滤级别设置为 INFO,目的是希望 _info.log 文件中可以记录 INFO 级别的日志。
- 第 20 到 30 行定义了一个类似的 FileAppender,并使用 ThresholdFilter 来过滤日志,过滤级别设置为 WARN,目的是把 WARN 以上级别的日志记录到另一个 _error.log 文件中。
运行一下测试程序:

可以看到,_info.log 中包含了 INFO、WARN 和 ERROR 三个级别的日志,不符合我们的预期;error.log 包含了 WARN 和 ERROR 两个级别的日志。因此,造成了日志的重复收集。
为了分析日志重复的原因,我们来复习一下 ThresholdFilter 和 LevelFilter 的配置方式。
分析 ThresholdFilter 的源码发现,当日志级别大于等于配置的级别时返回 NEUTRAL,继续调用过滤器链上的下一个过滤器;否则,返回 DENY 直接拒绝记录日志:
public class ThresholdFilter extends Filter<ILoggingEvent> {
public FilterReply decide(ILoggingEvent event) {
if (!isStarted()) {
return FilterReply.NEUTRAL;
}
if (event.getLevel().isGreaterOrEqual(level)) {
return FilterReply.NEUTRAL;
} else {
return FilterReply.DENY;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
在这个案例中,把 ThresholdFilter 设置为 WARN,可以记录 WARN 和 ERROR 级别的日志。
LevelFilter 用来比较日志级别,然后进行相应处理:如果匹配就调用 onMatch 定义的处理方式,默认是交给下一个过滤器处理(AbstractMatcherFilter 基类中定义的默认值);否则,调用 onMismatch 定义的处理方式,默认也是交给下一个过滤器处理。
public class LevelFilter extends AbstractMatcherFilter<ILoggingEvent> {
public FilterReply decide(ILoggingEvent event) {
if (!isStarted()) {
return FilterReply.NEUTRAL;
}
if (event.getLevel().equals(level)) {
return onMatch;
} else {
return onMismatch;
}
}
}
public abstract class AbstractMatcherFilter<E> extends Filter<E> {
protected FilterReply onMatch = FilterReply.NEUTRAL;
protected FilterReply onMismatch = FilterReply.NEUTRAL;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
和 ThresholdFilter 不同的是,LevelFilter 仅仅配置 level 是无法真正起作用的。由于没有配置 onMatch 和 onMismatch 属性,所以相当于这个过滤器是无用的,导致 INFO 以上级别的日志都记录了。
定位到问题后,修改方式就很明显了:配置 LevelFilter 的 onMatch 属性为 ACCEPT,表示接收 INFO 级别的日志;配置 onMismatch 属性为 DENY,表示除了 INFO 级别都不记录:
<appender name="INFO_FILE" class="ch.qos.logback.core.FileAppender">
<File>${logDir}/${app.name}_info.log</File>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>INFO</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
...
</appender>
2
3
4
5
6
7
8
9
这样修改后,_info.log 文件中只会有 INFO 级别的日志,不会出现日志重复的问题了。
# 使用异步日志改善性能的坑
掌握了把日志输出到文件中的方法后,我们接下来面临的问题是,如何避免日志记录成为应用的性能瓶颈。这可以帮助我们解决,磁盘(比如机械磁盘)IO 性能较差、日志量又很大的情况下,如何记录日志的问题。
我们先来测试一下,记录日志的性能问题,定义如下的日志配置,一共有两个 Appender:
- FILE 是一个 FileAppender,用于记录所有的日志;
- CONSOLE 是一个 ConsoleAppender,用于记录带有 time 标记的日志。
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>app.log</file>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</encoder>
</appender>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
<filter class="ch.qos.logback.core.filter.EvaluatorFilter">
<evaluator class="ch.qos.logback.classic.boolex.OnMarkerEvaluator">
<marker>time</marker>
</evaluator>
<onMismatch>DENY</onMismatch>
<onMatch>ACCEPT</onMatch>
</filter>
</appender>
<root level="INFO">
<appender-ref ref="FILE"/>
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
不知道你有没有注意到,这段代码中有个 EvaluatorFilter(求值过滤器),用于判断日志是否符合某个条件。
在后续的测试代码中,我们会把大量日志输出到文件中,日志文件会非常大,如果性能测试结果也混在其中的话,就很难找到那条日志。所以,这里我们使用 EvaluatorFilter 对日志按照标记进行过滤,并将过滤出的日志单独输出到控制台上。在这个案例中,我们给输出测试结果的那条日志上做了 time 标记。
配合使用标记和 EvaluatorFilter,实现日志的按标签过滤,是一个不错的小技巧。
如下测试代码中,实现了记录指定次数的大日志,每条日志包含 1MB 字节的模拟数据,最后记录一条以 time 为标记的方法执行耗时日志:
@GetMapping("performance")
public void performance(@RequestParam(name = "count", defaultValue = "1000") int count) {
long begin = System.currentTimeMillis();
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
IntStream.rangeClosed(1, count).forEach(i -> log.info("{} {}", i, payload));
Marker timeMarker = MarkerFactory.getMarker("time");
log.info(timeMarker, "took {} ms", System.currentTimeMillis() - begin);
}
2
3
4
5
6
7
8
9
10
执行程序后可以看到,记录 1000 次日志和 10000 次日志的调用耗时,分别是 6.3 秒和 44.5 秒:
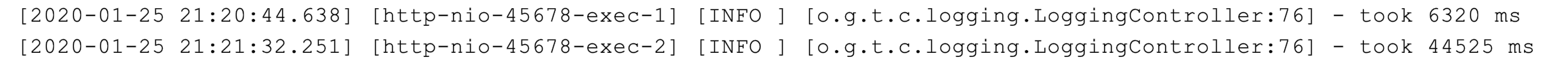
对于只记录文件日志的代码了来说,这个耗时挺长的。为了分析其中原因,我们需要分析下 FileAppender 的源码。
FileAppender 继承自 OutputStreamAppender,查看 OutputStreamAppender 源码的第 30 到 33 行发现,在追加日志的时候,是直接把日志写入 OutputStream 中,属于同步记录日志:
public class OutputStreamAppender<E> extends UnsynchronizedAppenderBase<E> {
private OutputStream outputStream;
boolean immediateFlush = true;
@Override
protected void append(E eventObject) {
if (!isStarted()) {
return;
}
subAppend(eventObject);
}
protected void subAppend(E event) {
if (!isStarted()) {
return;
}
try {
//编码LoggingEvent
byte[] byteArray = this.encoder.encode(event);
//写字节流
writeBytes(byteArray);
} catch (IOException ioe) {
...
}
}
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
lock.lock();
try {
//这个OutputStream其实是一个ResilientFileOutputStream,其内部使用的是带缓冲的BufferedOutputStream
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();//刷入OS
}
} finally {
lock.unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
分析到这里,我们就明白为什么日志大量写入时会耗时这么久了。那有没有办法实现大量日志写入时,不会过多影响业务逻辑执行耗时,影响吞吐量呢?
办法当然有了,使用 Logback 提供的 AsyncAppender 即可实现异步的日志记录。AsyncAppende 类似装饰模式,也就是在不改变类原有基本功能的情况下为其增添新功能。这样,我们就可以把 AsyncAppender 附加在其他的 Appender 上,将其变为异步的。
定义一个异步 Appender ASYNCFILE,包装之前的同步文件日志记录的 FileAppender,就可以实现异步记录日志到文件:
<appender name="ASYNCFILE" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="FILE"/>
</appender>
<root level="INFO">
<appender-ref ref="ASYNCFILE"/>
<appender-ref ref="CONSOLE"/>
</root>
2
3
4
5
6
7
测试一下可以发现,记录 1000 次日志和 10000 次日志的调用耗时,分别是 735 毫秒和 668 毫秒:

性能居然这么好,你觉得其中有什么问题吗?异步日志真的如此神奇和万能吗?当然不是,因为这样并没有记录下所有日志。之前就遇到过很多关于 AsyncAppender 异步日志的坑,这些坑可以归结为三类:
- 记录异步日志撑爆内存;
- 记录异步日志出现日志丢失;
- 记录异步日志出现阻塞。
为了解释这三种坑,来模拟一个慢日志记录场景:首先,自定义一个继承自 ConsoleAppender 的 MySlowAppender,作为记录到控制台的输出器,写入日志时休眠 1 秒。
public class MySlowAppender extends ConsoleAppender {
@Override
protected void subAppend(Object event) {
try {
// 模拟慢日志
TimeUnit.MILLISECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
super.subAppend(event);
}
}
2
3
4
5
6
7
8
9
10
11
12
然后,在配置文件中使用 AsyncAppender,将 MySlowAppender 包装为异步日志记录:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<appender name="CONSOLE" class="org.geekbang.time.commonmistakes.logging.async.MySlowAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
</appender>
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="CONSOLE" />
</appender>
<root level="INFO">
<appender-ref ref="ASYNC" />
</root>
</configuration>
2
3
4
5
6
7
8
9
10
11
12
13
14
定义一段测试代码,循环记录一定次数的日志,最后输出方法执行耗时:
@GetMapping("manylog")
public void manylog(@RequestParam(name = "count", defaultValue = "1000") int count) {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, count).forEach(i -> log.info("log-{}", i));
System.out.println("took " + (System.currentTimeMillis() - begin) + " ms");
}
2
3
4
5
6
执行方法后发现,耗时很短但出现了日志丢失:我们要记录 1000 条日志,最终控制台只能搜索到 215 条日志,而且日志的行号变为了一个问号。
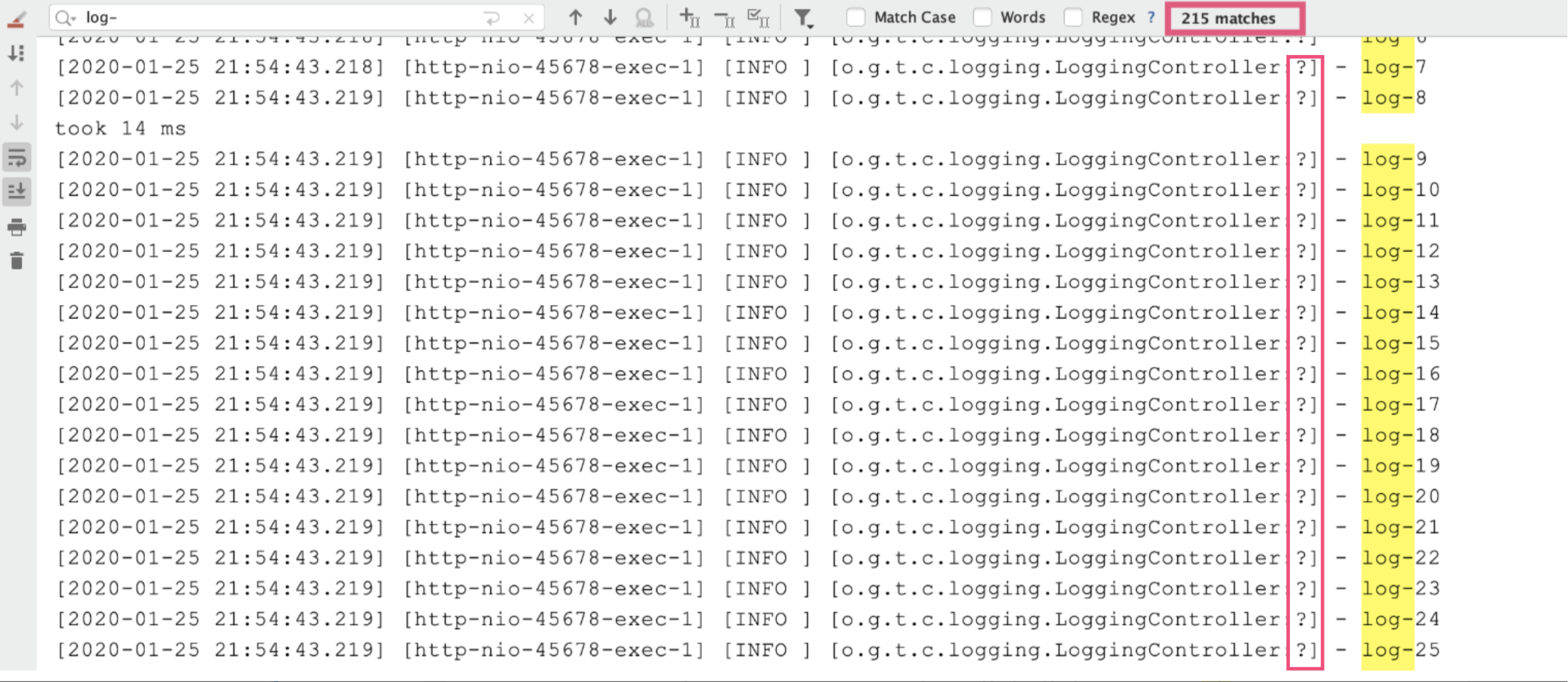
出现这个问题的原因在于,AsyncAppender 提供了一些配置参数,而我们没用对。我们结合相关源码分析一下:
- includeCallerData 用于控制是否收集调用方数据,默认是 false,此时方法行号、方法名等信息将不能显示(源码第 2 行以及 7 到 11 行)。
- queueSize 用于控制阻塞队列大小,使用的 ArrayBlockingQueue 阻塞队列(源码第 15 到 17 行),默认大小是 256,即内存中最多保存 256 条日志。
- discardingThreshold 是控制丢弃日志的阈值,主要是防止队列满后阻塞。默认情况下,队列剩余量低于队列长度的 20%,就会丢弃 TRACE、DEBUG 和 INFO 级别的日志。(参见源码第 3 到 6 行、18 到 19 行、26 到 27 行、33 到 34 行、40 到 42 行)
- neverBlock 用于控制队列满的时候,加入的数据是否直接丢弃,不会阻塞等待,默认是 false(源码第 44 到 68 行)。这里需要注意一下 offer 方法和 put 方法的区别,当队列满的时候 offer 方法不阻塞,而 put 方法会阻塞;neverBlock 为 true 时,使用 offer 方法。
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
boolean includeCallerData = false;//是否收集调用方数据
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
return level.toInt() <= Level.INFO_INT;//丢弃<=INFO级别的日志
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}
}
public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
BlockingQueue<E> blockingQueue;//异步日志的关键,阻塞队列
public static final int DEFAULT_QUEUE_SIZE = 256;//默认队列大小
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
boolean neverBlock = false;//控制队列满的时候加入数据时是否直接丢弃,不会阻塞等待
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
discardingThreshold = queueSize / 5;//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
看到默认队列大小为 256,达到 80% 容量后开始丢弃 <=INFO 级别的日志后,我们就可以理解日志中为什么只有 215 条 INFO 日志了。
我们可以继续分析下异步记录日志出现坑的原因。
- queueSize 设置得特别大,就可能会导致 OOM。
- queueSize 设置得比较小(默认值就非常小),且 discardingThreshold 设置为大于 0 的值(或者为默认值),队列剩余容量少于 discardingThreshold 的配置就会丢弃 <=INFO 的日志。这里的坑点有两个。一是,因为 discardingThreshold 的存在,设置 queueSize 时容易踩坑。比如,本例中最大日志并发是 1000,即便设置 queueSize 为 1000 同样会导致日志丢失。二是,discardingThreshold 参数容易有歧义,它不是百分比,而是日志条数。对于总容量 10000 的队列,如果希望队列剩余容量少于 1000 条的时候丢弃,需要配置为 1000。
- neverBlock 默认为 false,意味着总可能会出现阻塞。如果 discardingThreshold 为 0,那么队列满时再有日志写入就会阻塞;如果 discardingThreshold 不为 0,也只会丢弃 <=INFO 级别的日志,那么出现大量错误日志时,还是会阻塞程序。
可以看出 queueSize、discardingThreshold 和 neverBlock 这三个参数息息相关,务必按需进行设置和取舍,到底是性能为先,还是数据不丢为先:
- 如果考虑绝对性能为先,那就设置 neverBlock 为 true,永不阻塞。
- 如果考虑绝对不丢数据为先,那就设置 discardingThreshold 为 0,即使是 <=INFO 的级别日志也不会丢,但最好把 queueSize 设置大一点,毕竟默认的 queueSize 显然太小,太容易阻塞。
- 如果希望兼顾两者,可以丢弃不重要的日志,把 queueSize 设置大一点,再设置一个合理的 discardingThreshold。
# 使用日志占位符就不需要进行日志级别判断了?
SLF4J 的{}占位符语法,到真正记录日志时才会获取实际参数,因此解决了日志数据获取的性能问题。这种说法对吗?
为了验证这个问题,我们写一段测试代码:有一个 slowString 方法,返回结果耗时 1 秒:
private String slowString(String s) {
System.out.println("slowString called via " + s);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
return "OK";
}
2
3
4
5
6
7
8
如果我们记录 DEBUG 日志,并设置只记录 >=INFO 级别的日志,程序是否也会耗时 1 秒呢?我们使用三种方法来测试:
- 拼接字符串方式记录 slowString;
- 使用占位符方式记录 slowString;
- 先判断日志级别是否启用 DEBUG。
StopWatch stopWatch = new StopWatch();
stopWatch.start("debug1");
log.debug("debug1:" + slowString("debug1"));
stopWatch.stop();
stopWatch.start("debug2");
log.debug("debug2:{}", slowString("debug2"));
stopWatch.stop();
stopWatch.start("debug3");
if (log.isDebugEnabled())
log.debug("debug3:{}", slowString("debug3"));
stopWatch.stop();
2
3
4
5
6
7
8
9
10
11
可以看到,前两种方式都调用了 slowString 方法,所以耗时都是 1 秒:

使用占位符方式记录 slowString 的方式,同样需要耗时 1 秒,是因为这种方式虽然允许我们传入 Object,不用拼接字符串,但也只是延迟(如果日志不记录那么就是省去)了日志参数对象.toString() 和字符串拼接的耗时。
在这个案例中,除非事先判断日志级别,否则必然会调用 slowString 方法。回到之前提的问题,使用{}占位符语法不能通过延迟参数值获取,来解决日志数据获取的性能问题。
除了事先判断日志级别,我们还可以通过 lambda 表达式进行延迟参数内容获取。但 SLF4J 的 API 还不支持 lambda,因此需要使用 Log4j2 日志 API,把 Lombok 的 @Slf4j 注解替换为 @Log4j2 注解,这样就可以提供一个 lambda 表达式作为提供参数数据的方法:
@Log4j2
public class LoggingController {
...
log.debug("debug4:{}", ()->slowString("debug4"));
2
3
4
像这样调用 debug 方法,签名是 Supplier,参数会延迟到真正需要记录日志时再获取:
void debug(String message, Supplier<?>... paramSuppliers);
public void logIfEnabled(final String fqcn, final Level level, final Marker marker, final String message,
final Supplier<?>... paramSuppliers) {
if (isEnabled(level, marker, message)) {
logMessage(fqcn, level, marker, message, paramSuppliers);
}
}
protected void logMessage(final String fqcn, final Level level, final Marker marker, final String message,
final Supplier<?>... paramSuppliers) {
final Message msg = messageFactory.newMessage(message, LambdaUtil.getAll(paramSuppliers));
logMessageSafely(fqcn, level, marker, msg, msg.getThrowable());
}
2
3
4
5
6
7
8
9
10
11
12
13
修改后再次运行测试,可以看到这次 debug4 并不会调用 slowString 方法:

其实,我们只是换成了 Log4j2 API,真正的日志记录还是走的 Logback 框架。没错,这就是 SLF4J 适配的一个好处。
# 文件 IO
# 文件读写需要确保字符编码一致
有一个项目需要读取三方的对账文件定时对账,原先一直是单机处理的,没什么问题。后来为了提升性能,使用双节点同时处理对账,每一个节点处理部分对账数据,但新增的节点在处理文件中中文的时候总是读取到乱码。
程序代码都是一致的,为什么老节点就不会有问题呢?我们知道,这很可能是写代码时没有注意编码问题导致的。接下来,我们就分析下这个问题吧。
为模拟这个场景,我们使用 GBK 编码把“你好 hi”写入一个名为 hello.txt 的文本文件,然后直接以字节数组形式读取文件内容,转换为十六进制字符串输出到日志中:
Files.deleteIfExists(Paths.get("hello.txt"));
Files.write(Paths.get("hello.txt"), "你好hi".getBytes(Charset.forName("GBK")));
log.info("bytes:{}", Hex.encodeHexString(Files.readAllBytes(Paths.get("hello.txt"))).toUpperCase());
2
3
输出如下:
13:06:28.955 [main] INFO org.geekbang.time.commonmistakes.io.demo3.FileBadEncodingIssueApplication - bytes:C4E3BAC36869
虽然我们打开文本文件时看到的是“你好 hi”,但不管是什么文字,计算机中都是按照一定的规则将其以二进制保存的。这个规则就是字符集,字符集枚举了所有支持的字符映射成二进制的映射表。在处理文件读写的时候,如果是在字节层面进行操作,那么不会涉及字符编码问题;而如果需要在字符层面进行读写的话,就需要明确字符的编码方式也就是字符集了。
当时出现问题的文件读取代码是这样的:
char[] chars = new char[10];
String content = "";
try (FileReader fileReader = new FileReader("hello.txt")) {
int count;
while ((count = fileReader.read(chars)) != -1) {
content += new String(chars, 0, count);
}
}
log.info("result:{}", content);
2
3
4
5
6
7
8
9
可以看到,是使用了 FileReader 类以字符方式进行文件读取,日志中读取出来的“你好”变为了乱码:
13:06:28.961 [main] INFO org.geekbang.time.commonmistakes.io.demo3.FileBadEncodingIssueApplication - result:���hi
显然,这里并没有指定以什么字符集来读取文件中的字符。查看JDK 文档可以发现,FileReader 是以当前机器的默认字符集来读取文件的,如果希望指定字符集的话,需要直接使用 InputStreamReader 和 FileInputStream。
到这里我们就明白了,FileReader 虽然方便但因为使用了默认字符集对环境产生了依赖,这就是为什么老的机器上程序可以正常运作,在新节点上读取中文时却产生了乱码。
那怎么确定当前机器的默认字符集呢?写一段代码输出当前机器的默认字符集,以及 UTF-8 方式编码的“你好 hi”的十六进制字符串:
log.info("charset: {}", Charset.defaultCharset());
Files.write(Paths.get("hello2.txt"), "你好hi".getBytes(Charsets.UTF_8));
log.info("bytes:{}", Hex.encodeHexString(Files.readAllBytes(Paths.get("hello2.txt"))).toUpperCase());
2
3
输出结果如下:
13:06:28.961 [main] INFO org.geekbang.time.commonmistakes.io.demo3.FileBadEncodingIssueApplication - charset: UTF-8
13:06:28.962 [main] INFO org.geekbang.time.commonmistakes.io.demo3.FileBadEncodingIssueApplication - bytes:E4BDA0E5A5BD6869
2
可以看到,当前机器默认字符集是 UTF-8,当然无法读取 GBK 编码的汉字。UTF-8 编码的“你好”的十六进制是 E4BDA0E5A5BD,每一个汉字需要三个字节;而 GBK 编码的汉字,每一个汉字两个字节。字节长度都不一样,以 GBK 编码后保存的汉字,以 UTF8 进行解码读取,必然不会成功。
定位到问题后,修复就很简单了。按照文档所说,直接使用 FileInputStream 拿文件流,然后使用 InputStreamReader 读取字符流,并指定字符集为 GBK:
private static void right1() throws IOException {
char[] chars = new char[10];
String content = "";
try (FileInputStream fileInputStream = new FileInputStream("hello.txt");
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, Charset.forName("GBK"))) {
int count;
while ((count = inputStreamReader.read(chars)) != -1) {
content += new String(chars, 0, count);
}
}
log.info("result: {}", content);
}
2
3
4
5
6
7
8
9
10
11
12
从日志中看到,修复后的代码正确读取到了“你好 Hi”。
13:06:28.963 [main] INFO org.geekbang.time.commonmistakes.io.demo3.FileBadEncodingIssueApplication - result: 你好hi
如果你觉得这种方式比较麻烦的话,使用 JDK1.7 推出的 Files 类的 readAllLines 方法,可以很方便地用一行代码完成文件内容读取:
log.info("result: {}", Files.readAllLines(Paths.get("hello.txt"), Charset.forName("GBK")).stream().findFirst().orElse(""));
但这种方式有个问题是,读取超出内存大小的大文件时会出现 OOM。为什么呢?
打开 readAllLines 方法的源码可以看到,readAllLines 读取文件所有内容后,放到一个 List 中返回,如果内存无法容纳这个 List,就会 OOM:
public static List<String> readAllLines(Path path, Charset cs) throws IOException {
try (BufferedReader reader = newBufferedReader(path, cs)) {
List<String> result = new ArrayList<>();
for (;;) {
String line = reader.readLine();
if (line == null)
break;
result.add(line);
}
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
那么,有没有办法实现按需的流式读取呢?比如,需要消费某行数据时再读取,而不是把整个文件一次性读取到内存?
当然有,解决方案就是 File 类的 lines 方法。接下来说说使用 lines 方法时需要注意的一些问题。
# 使用 Files 类静态方法进行文件操作注意释放文件句柄
与 readAllLines 方法返回 List 不同,lines 方法返回的是 Stream。这使得我们在需要时可以不断读取、使用文件中的内容,而不是一次性地把所有内容都读取到内存中,因此避免了 OOM。
接下来通过一段代码测试一下。我们尝试读取一个 1 亿 1 万行的文件,文件占用磁盘空间超过 4GB。如果使用 -Xmx512m -Xms512m 启动 JVM 控制最大堆内存为 512M 的话,肯定无法一次性读取这样的大文件,但通过 Files.lines 方法就没问题。
在下面的代码中,首先输出这个文件的大小,然后计算读取 20 万行数据和 200 万行数据的耗时差异,最后逐行读取文件,统计文件的总行数:
//输出文件大小
log.info("file size:{}", Files.size(Paths.get("test.txt")));
StopWatch stopWatch = new StopWatch();
stopWatch.start("read 200000 lines");
//使用Files.lines方法读取20万行数据
log.info("lines {}", Files.lines(Paths.get("test.txt")).limit(200000).collect(Collectors.toList()).size());
stopWatch.stop();
stopWatch.start("read 2000000 lines");
//使用Files.lines方法读取200万行数据
log.info("lines {}", Files.lines(Paths.get("test.txt")).limit(2000000).collect(Collectors.toList()).size());
stopWatch.stop();
log.info(stopWatch.prettyPrint());
AtomicLong atomicLong = new AtomicLong();
//使用Files.lines方法统计文件总行数
Files.lines(Paths.get("test.txt")).forEach(line->atomicLong.incrementAndGet());
log.info("total lines {}", atomicLong.get());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
输出结果如下:

可以看到,实现了全文件的读取、统计了整个文件的行数,并没有出现 OOM;读取 200 万行数据耗时 760ms,读取 20 万行数据仅需 267ms。这些都可以说明,File.lines 方法并不是一次性读取整个文件的,而是按需读取。
到这里,你觉得这段代码有什么问题吗?
问题在于读取完文件后没有关闭。我们通常会认为静态方法的调用不涉及资源释放,因为方法调用结束自然代表资源使用完成,由 API 释放资源,但对于 Files 类的一些返回 Stream 的方法并不是这样。这是一个很容易被忽略的严重问题。
我就曾遇到过一个案例:程序在生产上运行一段时间后就会出现 too many files 的错误,我们想当然地认为是 OS 设置的最大文件句柄太小了,就让运维放开这个限制,但放开后还是会出现这样的问题。经排查发现,其实是文件句柄没有释放导致的,问题就出在 Files.lines 方法上。
我们来重现一下这个问题,随便写入 10 行数据到一个 demo.txt 文件中:
Files.write(Paths.get("demo.txt"),
IntStream.rangeClosed(1, 10).mapToObj(i -> UUID.randomUUID().toString()).collect(Collectors.toList())
, UTF_8, CREATE, TRUNCATE_EXISTING);
2
3
然后使用 Files.lines 方法读取这个文件 100 万次,每读取一行计数器 +1:
LongAdder longAdder = new LongAdder();
IntStream.rangeClosed(1, 1000000).forEach(i -> {
try {
Files.lines(Paths.get("demo.txt")).forEach(line -> longAdder.increment());
} catch (IOException e) {
e.printStackTrace();
}
});
log.info("total : {}", longAdder.longValue());
2
3
4
5
6
7
8
9
运行后马上可以在日志中看到如下错误:
java.nio.file.FileSystemException: demo.txt: Too many open files
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:91)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
2
3
4
使用 lsof 命令查看进程打开的文件,可以看到打开了 1 万多个 demo.txt:
lsof -p 63937
...
java 63902 zhuye *238r REG 1,4 370 12934160647 /Users/zhuye/Documents/common-mistakes/demo.txt
java 63902 zhuye *239r REG 1,4 370 12934160647 /Users/zhuye/Documents/common-mistakes/demo.txt
...
lsof -p 63937 | grep demo.txt | wc -l
10007
2
3
4
5
6
7
8
其实,在JDK 文档中有提到,注意使用 try-with-resources 方式来配合,确保流的 close 方法可以调用释放资源。
这也很容易理解,使用流式处理,如果不显式地告诉程序什么时候用完了流,程序又如何知道呢,它也不能帮我们做主何时关闭文件。
修复方式很简单,使用 try 来包裹 Stream 即可:
LongAdder longAdder = new LongAdder();
IntStream.rangeClosed(1, 1000000).forEach(i -> {
try (Stream<String> lines = Files.lines(Paths.get("demo.txt"))) {
lines.forEach(line -> longAdder.increment());
} catch (IOException e) {
e.printStackTrace();
}
});
log.info("total : {}", longAdder.longValue());
2
3
4
5
6
7
8
9
修改后的代码不再出现错误日志,因为读取了 100 万次包含 10 行数据的文件,所以最终正确输出了 1000 万:
14:19:29.410 [main] INFO org.geekbang.time.commonmistakes.io.demo2.FilesStreamOperationNeedCloseApplication - total : 10000000
查看 lines 方法源码可以发现,Stream 的 close 注册了一个回调,来关闭 BufferedReader 进行资源释放:
public static Stream<String> lines(Path path, Charset cs) throws IOException {
BufferedReader br = Files.newBufferedReader(path, cs);
try {
return br.lines().onClose(asUncheckedRunnable(br));
} catch (Error|RuntimeException e) {
try {
br.close();
} catch (IOException ex) {
try {
e.addSuppressed(ex);
} catch (Throwable ignore) {}
}
throw e;
}
}
private static Runnable asUncheckedRunnable(Closeable c) {
return () -> {
try {
c.close();
} catch (IOException e) {
throw new UncheckedIOException(e);
}
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
从命名上可以看出,使用 BufferedReader 进行字符流读取时,用到了缓冲。这里缓冲 Buffer 的意思是,使用一块内存区域作为直接操作的中转。
比如,读取文件操作就是一次性读取一大块数据(比如 8KB)到缓冲区,后续的读取可以直接从缓冲区返回数据,而不是每次都直接对应文件 IO。写操作也是类似。如果每次写几十字节到文件都对应一次 IO 操作,那么写一个几百兆的大文件可能就需要千万次的 IO 操作,耗时会非常久。
# 注意读写文件要考虑设置缓冲区
一个案例,一段先进行文件读入再简单处理后写入另一个文件的业务代码,由于开发人员使用了单字节的读取写入方式,导致执行得巨慢,业务量上来后需要数小时才能完成。
我们来模拟一下相关实现。创建一个文件随机写入 100 万行数据,文件大小在 35MB 左右:
Files.write(Paths.get("src.txt"),
IntStream.rangeClosed(1, 1000000).mapToObj(i -> UUID.randomUUID().toString()).collect(Collectors.toList())
, UTF_8, CREATE, TRUNCATE_EXISTING);
2
3
当时开发人员写的文件处理代码大概是这样的:使用 FileInputStream 获得一个文件输入流,然后调用其 read 方法每次读取一个字节,最后通过一个 FileOutputStream 文件输出流把处理后的结果写入另一个文件。
为了简化逻辑便于理解,这里我们不对数据进行处理,直接把原文件数据写入目标文件,相当于文件复制:
private static void perByteOperation() throws IOException {
try (FileInputStream fileInputStream = new FileInputStream("src.txt");
FileOutputStream fileOutputStream = new FileOutputStream("dest.txt")) {
int i;
while ((i = fileInputStream.read()) != -1) {
fileOutputStream.write(i);
}
}
}
2
3
4
5
6
7
8
9
这样的实现,复制一个 35MB 的文件居然耗时 190 秒。
显然,每读取一个字节、每写入一个字节都进行一次 IO 操作,代价太大了。解决方案就是,考虑使用缓冲区作为过渡,一次性从原文件读取一定数量的数据到缓冲区,一次性写入一定数量的数据到目标文件。
改良后,使用 100 字节作为缓冲区,使用 FileInputStream 的 byte[]的重载来一次性读取一定字节的数据,同时使用 FileOutputStream 的 byte[]的重载实现一次性从缓冲区写入一定字节的数据到文件:
private static void bufferOperationWith100Buffer() throws IOException {
try (FileInputStream fileInputStream = new FileInputStream("src.txt");
FileOutputStream fileOutputStream = new FileOutputStream("dest.txt")) {
byte[] buffer = new byte[100];
int len = 0;
while ((len = fileInputStream.read(buffer)) != -1) {
fileOutputStream.write(buffer, 0, len);
}
}
}
2
3
4
5
6
7
8
9
10
仅仅使用了 100 个字节的缓冲区作为过渡,完成 35M 文件的复制耗时缩短到了 26 秒,是无缓冲时性能的 7 倍;如果把缓冲区放大到 1000 字节,耗时可以进一步缩短到 342 毫秒。可以看到,在进行文件 IO 处理的时候,使用合适的缓冲区可以明显提高性能。
你可能会说,实现文件读写还要自己 new 一个缓冲区出来,太麻烦了,不是有一个 BufferedInputStream 和 BufferedOutputStream 可以实现输入输出流的缓冲处理吗?
是的,它们在内部实现了一个默认 8KB 大小的缓冲区。但是,在使用 BufferedInputStream 和 BufferedOutputStream 时,还是建议再使用一个缓冲进行读写,不要因为它们实现了内部缓冲就进行逐字节的操作。
接下来,写一段代码比较下使用下面三种方式读写一个字节的性能:
- 直接使用 BufferedInputStream 和 BufferedOutputStream;
- 额外使用一个 8KB 缓冲,使用 BufferedInputStream 和 BufferedOutputStream;
- 直接使用 FileInputStream 和 FileOutputStream,再使用一个 8KB 的缓冲。
//使用BufferedInputStream和BufferedOutputStream
private static void bufferedStreamByteOperation() throws IOException {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("src.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("dest.txt"))) {
int i;
while ((i = bufferedInputStream.read()) != -1) {
bufferedOutputStream.write(i);
}
}
}
//额外使用一个8KB缓冲,再使用BufferedInputStream和BufferedOutputStream
private static void bufferedStreamBufferOperation() throws IOException {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("src.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("dest.txt"))) {
byte[] buffer = new byte[8192];
int len = 0;
while ((len = bufferedInputStream.read(buffer)) != -1) {
bufferedOutputStream.write(buffer, 0, len);
}
}
}
//直接使用FileInputStream和FileOutputStream,再使用一个8KB的缓冲
private static void largerBufferOperation() throws IOException {
try (FileInputStream fileInputStream = new FileInputStream("src.txt");
FileOutputStream fileOutputStream = new FileOutputStream("dest.txt")) {
byte[] buffer = new byte[8192];
int len = 0;
while ((len = fileInputStream.read(buffer)) != -1) {
fileOutputStream.write(buffer, 0, len);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
结果如下:
---------------------------------------------
ns % Task name
---------------------------------------------
1424649223 086% bufferedStreamByteOperation
117807808 007% bufferedStreamBufferOperation
112153174 007% largerBufferOperation
2
3
4
5
6
可以看到,第一种方式虽然使用了缓冲流,但逐字节的操作因为方法调用次数实在太多还是慢,耗时 1.4 秒;后面两种方式的性能差不多,耗时 110 毫秒左右。虽然第三种方式没有使用缓冲流,但使用了 8KB 大小的缓冲区,和缓冲流默认的缓冲区大小相同。
看到这里,你可能会疑惑了,既然这样使用 BufferedInputStream 和 BufferedOutputStream 有什么意义呢?
其实,这里是为了演示所以示例三使用了固定大小的缓冲区,但在实际代码中每次需要读取的字节数很可能不是固定的,有的时候读取几个字节,有的时候读取几百字节,这个时候有一个固定大小较大的缓冲,也就是使用 BufferedInputStream 和 BufferedOutputStream 做为后备的稳定的二次缓冲,就非常有意义了。
最后我要补充说明的是,对于类似的文件复制操作,如果希望有更高性能,可以使用 FileChannel 的 transfreTo 方法进行流的复制。在一些操作系统(比如高版本的 Linux 和 UNIX)上可以实现 DMA(直接内存访问),也就是数据从磁盘经过总线直接发送到目标文件,无需经过内存和 CPU 进行数据中转:
private static void fileChannelOperation() throws IOException {
FileChannel in = FileChannel.open(Paths.get("src.txt"), StandardOpenOption.READ);
FileChannel out = FileChannel.open(Paths.get("dest.txt"), CREATE, WRITE);
in.transferTo(0, in.size(), out);
}
2
3
4
5
在测试 FileChannel 性能的同时,再运行一下上面的所有实现,比较一下读写 35MB 文件的耗时。
---------------------------------------------
ns % Task name
---------------------------------------------
183673362265 098% perByteOperation
2034504694 001% bufferOperationWith100Buffer
749967898 000% bufferedStreamByteOperation
110602155 000% bufferedStreamBufferOperation
114542834 000% largerBufferOperation
050068602 000% fileChannelOperation
2
3
4
5
6
7
8
9
可以看到,最慢的是单字节读写文件流的方式,耗时 183 秒,最快的是 FileChannel.transferTo 方式进行流转发的方式,耗时 50 毫秒。两者耗时相差达到 3600 倍!
# 序列化
序列化是把对象转换为字节流的过程,以方便传输或存储。反序列化,则是反过来把字节流转换为对象的过程。对象的序列化和反序列化,需要由序列化算法制定规则。
关于序列化算法,几年前常用的有 JDK(Java)序列化、XML 序列化等,但前者不能跨语言,后者性能较差(时间空间开销大);现在 RESTful 应用最常用的是 JSON 序列化,追求性能的 RPC 框架(比如 gRPC)使用 protobuf 序列化,这 2 种方法都是跨语言的,而且性能不错,应用广泛。
在架构设计阶段,我们可能会重点关注算法选型,在性能、易用性和跨平台性等中权衡,不过这里的坑比较少。通常情况下,序列化问题常见的坑会集中在业务场景中,比如 Redis、参数和响应序列化反序列化。
# 序列化和反序列化需要确保算法一致
业务代码中涉及序列化时,很重要的一点是要确保序列化和反序列化的算法一致性。
案例:开发同学使用 RedisTemplate 来操作 Redis 进行数据缓存。因为相比于 Jedis,使用 Spring 提供的 RedisTemplate 操作 Redis,除了无需考虑连接池、更方便外,还可以与 Spring Cache 等其他组件无缝整合。如果使用 Spring Boot 的话,无需任何配置就可以直接使用。
数据(包含 Key 和 Value)要保存到 Redis,需要经过序列化算法来序列化成字符串。虽然 Redis 支持多种数据结构,比如 Hash,但其每一个 field 的 Value 还是字符串。如果 Value 本身也是字符串的话,能否有便捷的方式来使用 RedisTemplate,而无需考虑序列化呢?
其实是有的,那就是 StringRedisTemplate。
那 StringRedisTemplate 和 RedisTemplate 的区别是什么呢?开头提到的乱码又是怎么回事呢?带着这些问题让我们来研究一下吧。
写一段测试代码,在应用初始化完成后向 Redis 设置两组数据,第一次使用 RedisTemplate 设置 Key 为 redisTemplate、Value 为 User 对象,第二次使用 StringRedisTemplate 设置 Key 为 stringRedisTemplate、Value 为 JSON 序列化后的 User 对象:
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private ObjectMapper objectMapper;
@PostConstruct
public void init() throws JsonProcessingException {
redisTemplate.opsForValue().set("redisTemplate", new User("zhuye", 36));
stringRedisTemplate.opsForValue().set("stringRedisTemplate", objectMapper.writeValueAsString(new User("zhuye", 36)));
}
2
3
4
5
6
7
8
9
10
11
12
如果你认为,StringRedisTemplate 和 RedisTemplate 的区别,无非是读取的 Value 是 String 和 Object,那就大错特错了,因为使用这两种方式存取的数据完全无法通用。
我们做个小实验,通过 RedisTemplate 读取 Key 为 stringRedisTemplate 的 Value,使用 StringRedisTemplate 读取 Key 为 redisTemplate 的 Value:
log.info("redisTemplate get {}", redisTemplate.opsForValue().get("stringRedisTemplate"));
log.info("stringRedisTemplate get {}", stringRedisTemplate.opsForValue().get("redisTemplate"));
2
结果是,两次都无法读取到 Value
[11:49:38.478] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:38 ] - redisTemplate get null
[11:49:38.481] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:39 ] - stringRedisTemplate get null
2
通过 redis-cli 客户端工具连接到 Redis,你会发现根本就没有叫作 redisTemplate 的 Key,所以 StringRedisTemplate 无法查到数据:

查看 RedisTemplate 的源码发现,默认情况下 RedisTemplate 针对 Key 和 Value 使用了 JDK 序列化:
public void afterPropertiesSet() {
...
if (defaultSerializer == null) {
defaultSerializer = new JdkSerializationRedisSerializer(
classLoader != null ? classLoader : this.getClass().getClassLoader());
}
if (enableDefaultSerializer) {
if (keySerializer == null) {
keySerializer = defaultSerializer;
defaultUsed = true;
}
if (valueSerializer == null) {
valueSerializer = defaultSerializer;
defaultUsed = true;
}
if (hashKeySerializer == null) {
hashKeySerializer = defaultSerializer;
defaultUsed = true;
}
if (hashValueSerializer == null) {
hashValueSerializer = defaultSerializer;
defaultUsed = true;
}
}
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
redis-cli 看到的类似一串乱码的"\xac\xed\x00\x05t\x00\rredisTemplate"字符串,其实就是字符串 redisTemplate 经过 JDK 序列化后的结果。这就回答了之前提到的乱码问题。而 RedisTemplate 尝试读取 Key 为 stringRedisTemplate 数据时,也会对这个字符串进行 JDK 序列化处理,所以同样无法读取到数据。
而 StringRedisTemplate 对于 Key 和 Value,使用的是 String 序列化方式,Key 和 Value 只能是 String:
public class StringRedisTemplate extends RedisTemplate<String, String> {
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());
setValueSerializer(RedisSerializer.string());
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
}
}
public class StringRedisSerializer implements RedisSerializer<String> {
@Override
public String deserialize(@Nullable byte[] bytes) {
return (bytes == null ? null : new String(bytes, charset));
}
@Override
public byte[] serialize(@Nullable String string) {
return (string == null ? null : string.getBytes(charset));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
看到这里,我们应该知道 RedisTemplate 和 StringRedisTemplate 保存的数据无法通用。修复方式就是,让它们读取自己存的数据:
- 使用 RedisTemplate 读出的数据,由于是 Object 类型的,使用时可以先强制转换为 User 类型;
- 使用 StringRedisTemplate 读取出的字符串,需要手动将 JSON 反序列化为 User 类型。
//使用RedisTemplate获取Value,无需反序列化就可以拿到实际对象,虽然方便,但是Redis中保存的Key和Value不易读
User userFromRedisTemplate = (User) redisTemplate.opsForValue().get("redisTemplate");
log.info("redisTemplate get {}", userFromRedisTemplate);
//使用StringRedisTemplate,虽然Key正常,但是Value存取需要手动序列化成字符串
User userFromStringRedisTemplate = objectMapper.readValue(stringRedisTemplate.opsForValue().get("stringRedisTemplate"), User.class);
log.info("stringRedisTemplate get {}", userFromStringRedisTemplate);
2
3
4
5
6
7
这样就可以得到正确输出:
[13:32:09.087] [http-nio-45678-exec-6] [INFO ] [.t.c.s.demo1.RedisTemplateController:45 ] - redisTemplate get User(name=zhuye, age=36)
[13:32:09.092] [http-nio-45678-exec-6] [INFO ] [.t.c.s.demo1.RedisTemplateController:47 ] - stringRedisTemplate get User(name=zhuye, age=36)
2
看到这里你可能会说,使用 RedisTemplate 获取 Value 虽然方便,但是 Key 和 Value 不易读;而使用 StringRedisTemplate 虽然 Key 是普通字符串,但是 Value 存取需要手动序列化成字符串,有没有两全其美的方式呢?
当然有,自己定义 RedisTemplate 的 Key 和 Value 的序列化方式即可:Key 的序列化使用 RedisSerializer.string()(也就是 StringRedisSerializer 方式)实现字符串序列化,而 Value 的序列化使用 Jackson2JsonRedisSerializer:
@Bean
public <T> RedisTemplate<String, T> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, T> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashKeySerializer(RedisSerializer.string());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
2
3
4
5
6
7
8
9
10
11
12
写代码测试一下存取,直接注入类型为 RedisTemplate 的 userRedisTemplate 字段,然后在 right2 方法中,使用注入的 userRedisTemplate 存入一个 User 对象,再分别使用 userRedisTemplate 和 StringRedisTemplate 取出这个对象:
@Autowired
private RedisTemplate<String, User> userRedisTemplate;
@GetMapping("right2")
public void right2() {
User user = new User("zhuye", 36);
userRedisTemplate.opsForValue().set(user.getName(), user);
Object userFromRedis = userRedisTemplate.opsForValue().get(user.getName());
log.info("userRedisTemplate get {} {}", userFromRedis, userFromRedis.getClass());
log.info("stringRedisTemplate get {}", stringRedisTemplate.opsForValue().get(user.getName()));
}
2
3
4
5
6
7
8
9
10
11
乍一看没啥问题,StringRedisTemplate 成功查出了我们存入的数据:
[14:07:41.315] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:55 ] - userRedisTemplate get {name=zhuye, age=36} class java.util.LinkedHashMap
[14:07:41.318] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:56 ] - stringRedisTemplate get {"name":"zhuye","age":36}
2
Redis 里也可以查到 Key 是纯字符串,Value 是 JSON 序列化后的 User 对象:

但值得注意的是,这里有一个坑。第一行的日志输出显示,userRedisTemplate 获取到的 Value,是 LinkedHashMap 类型的,完全不是泛型的 RedisTemplate 设置的 User 类型。
如果我们把代码里从 Redis 中获取到的 Value 变量类型由 Object 改为 User,编译不会出现问题,但会出现 ClassCastException:
java.lang.ClassCastException: java.util.LinkedHashMap cannot be cast to org.geekbang.time.commonmistakes.serialization.demo1.User
修复方式是,修改自定义 RestTemplate 的代码,把 new 出来的 Jackson2JsonRedisSerializer 设置一个自定义的 ObjectMapper,启用 activateDefaultTyping 方法把类型信息作为属性写入序列化后的数据中(当然了,你也可以调整 JsonTypeInfo.As 枚举以其他形式保存类型信息):
...
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
//把类型信息作为属性写入Value
objectMapper.activateDefaultTyping(objectMapper.getPolymorphicTypeValidator(), ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
...
2
3
4
5
6
7
或者,直接使用 RedisSerializer.json() 快捷方法,它内部使用的 GenericJackson2JsonRedisSerializer 直接设置了把类型作为属性保存到 Value 中:
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(RedisSerializer.json());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
redisTemplate.setHashValueSerializer(RedisSerializer.json());
2
3
4
重启程序调用 right2 方法进行测试,可以看到,从自定义的 RedisTemplate 中获取到的 Value 是 User 类型的(第一行日志),而且 Redis 中实际保存的 Value 包含了类型完全限定名(第二行日志):
[15:10:50.396] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:55 ] - userRedisTemplate get User(name=zhuye, age=36) class org.geekbang.time.commonmistakes.serialization.demo1.User
[15:10:50.399] [http-nio-45678-exec-1] [INFO ] [.t.c.s.demo1.RedisTemplateController:56 ] - stringRedisTemplate get ["org.geekbang.time.commonmistakes.serialization.demo1.User",{"name":"zhuye","age":36}]
2
因此,反序列化时可以直接得到 User 类型的 Value。
通过对 RedisTemplate 组件的分析,可以看到,当数据需要序列化后保存时,读写数据使用一致的序列化算法的必要性,否则就像对牛弹琴。
这里再总结下 Spring 提供的 4 种 RedisSerializer(Redis 序列化器):
- 默认情况下,RedisTemplate 使用 JdkSerializationRedisSerializer,也就是 JDK 序列化,容易产生 Redis 中保存了乱码的错觉。
- 通常考虑到易读性,可以设置 Key 的序列化器为 StringRedisSerializer。但直接使用 RedisSerializer.string(),相当于使用了 UTF_8 编码的 StringRedisSerializer,需要注意字符集问题。
- 如果希望 Value 也是使用 JSON 序列化的话,可以把 Value 序列化器设置为 Jackson2JsonRedisSerializer。默认情况下,不会把类型信息保存在 Value 中,即使我们定义 RedisTemplate 的 Value 泛型为实际类型,查询出的 Value 也只能是 LinkedHashMap 类型。如果希望直接获取真实的数据类型,你可以启用 Jackson ObjectMapper 的 activateDefaultTyping 方法,把类型信息一起序列化保存在 Value 中。
- 如果希望 Value 以 JSON 保存并带上类型信息,更简单的方式是,直接使用 RedisSerializer.json() 快捷方法来获取序列化器。
# 注意 Jackson JSON 反序列化对额外字段的处理
前面我提到,通过设置 JSON 序列化工具 Jackson 的 activateDefaultTyping 方法,可以在序列化数据时写入对象类型。其实,Jackson 还有很多参数可以控制序列化和反序列化,是一个功能强大而完善的序列化工具。因此,很多框架都将 Jackson 作为 JDK 序列化工具,比如 Spring Web。但也正是这个原因,我们使用时要小心各个参数的配置。
比如,在开发 Spring Web 应用程序时,如果自定义了 ObjectMapper,并把它注册成了 Bean,那很可能会导致 Spring Web 使用的 ObjectMapper 也被替换,导致 Bug。
我们来看一个案例。程序一开始是正常的,某一天开发同学希望修改一下 ObjectMapper 的行为,让枚举序列化为索引值而不是字符串值,比如默认情况下序列化一个 Color 枚举中的 Color.BLUE 会得到字符串 BLUE:
@Autowired
private ObjectMapper objectMapper;
@GetMapping("test")
public void test() throws JsonProcessingException {
log.info("color:{}", objectMapper.writeValueAsString(Color.BLUE));
}
enum Color {
RED, BLUE
}
2
3
4
5
6
7
8
9
10
11
于是,这位同学就重新定义了一个 ObjectMapper Bean,开启了 WRITE_ENUMS_USING_INDEX 功能特性:
@Bean
public ObjectMapper objectMapper(){
ObjectMapper objectMapper=new ObjectMapper();
objectMapper.configure(SerializationFeature.WRITE_ENUMS_USING_INDEX,true);
return objectMapper;
}
2
3
4
5
6
开启这个特性后,Color.BLUE 枚举序列化成索引值 1:
[16:11:37.382] [http-nio-45678-exec-1] [INFO ] [c.s.d.JsonIgnorePropertiesController:19 ] - color:1
修改后处理枚举序列化的逻辑是满足了要求,但线上爆出了大量 400 错误,日志中也出现了很多 UnrecognizedPropertyException:
JSON parse error: Unrecognized field \"ver\" (class org.geekbang.time.commonmistakes.serialization.demo4.UserWrong), not marked as ignorable; nested exception is com.fasterxml.jackson.databind.exc.UnrecognizedPropertyException: Unrecognized field \"version\" (class org.geekbang.time.commonmistakes.serialization.demo4.UserWrong), not marked as ignorable (one known property: \"name\"])\n at [Source: (PushbackInputStream); line: 1, column: 22] (through reference chain: org.geekbang.time.commonmistakes.serialization.demo4.UserWrong[\"ver\"])
从异常信息中可以看到,这是因为反序列化的时候,原始数据多了一个 version 属性。进一步分析发现,我们使用了 UserWrong 类型作为 Web 控制器 wrong 方法的入参,其中只有一个 name 属性:
@Data
public class UserWrong {
private String name;
}
@PostMapping("wrong")
public UserWrong wrong(@RequestBody UserWrong user) {
return user;
}
2
3
4
5
6
7
8
9
而客户端实际传过来的数据多了一个 version 属性。那,为什么之前没这个问题呢?
问题就出在,自定义 ObjectMapper 启用 WRITE_ENUMS_USING_INDEX 序列化功能特性时,覆盖了 Spring Boot 自动创建的 ObjectMapper;而这个自动创建的 ObjectMapper 设置过 FAIL_ON_UNKNOWN_PROPERTIES 反序列化特性为 false,以确保出现未知字段时不要抛出异常。源码如下:
public MappingJackson2HttpMessageConverter() {
this(Jackson2ObjectMapperBuilder.json().build());
}
public class Jackson2ObjectMapperBuilder {
...
private void customizeDefaultFeatures(ObjectMapper objectMapper) {
if (!this.features.containsKey(MapperFeature.DEFAULT_VIEW_INCLUSION)) {
configureFeature(objectMapper, MapperFeature.DEFAULT_VIEW_INCLUSION, false);
}
if (!this.features.containsKey(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES)) {
configureFeature(objectMapper, DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
要修复这个问题,有三种方式:
第一种,同样禁用自定义的 ObjectMapper 的 FAIL_ON_UNKNOWN_PROPERTIES:
@Bean public ObjectMapper objectMapper(){ ObjectMapper objectMapper=new ObjectMapper(); objectMapper.configure(SerializationFeature.WRITE_ENUMS_USING_INDEX,true); objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES,false); return objectMapper; }1
2
3
4
5
6
7第二种,设置自定义类型,加上 @JsonIgnoreProperties 注解,开启 ignoreUnknown 属性,以实现反序列化时忽略额外的数据:
@Data @JsonIgnoreProperties(ignoreUnknown = true) public class UserRight { private String name; }1
2
3
4
5第三种,不要自定义 ObjectMapper,而是直接在配置文件设置相关参数,来修改 Spring 默认的 ObjectMapper 的功能。比如,直接在配置文件启用把枚举序列化为索引号:
spring.jackson.serialization.write_enums_using_index=true1
或者可以直接定义 Jackson2ObjectMapperBuilderCustomizer Bean 来启用新特性:
@Bean
public Jackson2ObjectMapperBuilderCustomizer customizer(){
return builder -> builder.featuresToEnable(SerializationFeature.WRITE_ENUMS_USING_INDEX);
}
2
3
4
这个案例告诉我们两点:
- Jackson 针对序列化和反序列化有大量的细节功能特性,我们可以参考 Jackson 官方文档来了解这些特性,详见SerializationFeature、DeserializationFeature 和 MapperFeature。
- 忽略多余字段,是我们写业务代码时最容易遇到的一个配置项。Spring Boot 在自动配置时贴心地做了全局设置。如果需要设置更多的特性,可以直接修改配置文件 spring.jackson.** 或设置 Jackson2ObjectMapperBuilderCustomizer 回调接口,来启用更多设置,无需重新定义 ObjectMapper Bean。
# 反序列化时要小心类的构造方法
使用 Jackson 反序列化时,除了要注意忽略额外字段的问题外,还要小心类的构造方法。我们看一个实际的踩坑案例吧。
有一个 APIResult 类包装了 REST 接口的返回体(作为 Web 控制器的出参),其中 boolean 类型的 success 字段代表是否处理成功、int 类型的 code 字段代表处理状态码。
开始时,在返回 APIResult 的时候每次都根据 code 来设置 success。如果 code 是 2000,那么 success 是 true,否则是 false。后来为了减少重复代码,把这个逻辑放到了 APIResult 类的构造方法中处理:
@Data
public class APIResultWrong {
private boolean success;
private int code;
public APIResultWrong() {
}
public APIResultWrong(int code) {
this.code = code;
if (code == 2000) success = true;
else success = false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
经过改动后发现,即使 code 为 2000,返回 APIResult 的 success 也是 false。比如,我们反序列化两次 APIResult,一次使用 code==1234,一次使用 code==2000:
@Autowired
ObjectMapper objectMapper;
@GetMapping("wrong")
public void wrong() throws JsonProcessingException {
log.info("result :{}", objectMapper.readValue("{\"code\":1234}", APIResultWrong.class));
log.info("result :{}", objectMapper.readValue("{\"code\":2000}", APIResultWrong.class));
}
2
3
4
5
6
7
8
日志输出如下:
[17:36:14.591] [http-nio-45678-exec-1] [INFO ] [DeserializationConstructorController:20 ] - result :APIResultWrong(success=false, code=1234)
[17:36:14.591] [http-nio-45678-exec-1] [INFO ] [DeserializationConstructorController:21 ] - result :APIResultWrong(success=false, code=2000)
2
可以看到,两次的 APIResult 的 success 字段都是 false。
出现这个问题的原因是,默认情况下,在反序列化的时候,Jackson 框架只会调用无参构造方法创建对象。如果走自定义的构造方法创建对象,需要通过 @JsonCreator 来指定构造方法,并通过 @JsonProperty 设置构造方法中参数对应的 JSON 属性名:
@Data
public class APIResultRight {
...
@JsonCreator
public APIResultRight(@JsonProperty("code") int code) {
this.code = code;
if (code == 2000) success = true;
else success = false;
}
}
2
3
4
5
6
7
8
9
10
11
重新运行程序,可以得到正确输出:
[17:41:23.188] [http-nio-45678-exec-1] [INFO ] [DeserializationConstructorController:26 ] - result :APIResultRight(success=false, code=1234)
[17:41:23.188] [http-nio-45678-exec-1] [INFO ] [DeserializationConstructorController:27 ] - result :APIResultRight(success=true, code=2000)
2
可以看到,这次传入 code==2000 时,success 可以设置为 true。
# 枚举作为 API 接口参数或返回值的两个大坑
对于枚举建议尽量在程序内部使用,而不是作为 API 接口的参数或返回值,原因是枚举涉及序列化和反序列化时会有两个大坑。
第一个坑是,客户端和服务端的枚举定义不一致时,会出异常。比如,客户端版本的枚举定义了 4 个枚举值:
@Getter
enum StatusEnumClient {
CREATED(1, "已创建"),
PAID(2, "已支付"),
DELIVERED(3, "已送到"),
FINISHED(4, "已完成");
private final int status;
private final String desc;
StatusEnumClient(Integer status, String desc) {
this.status = status;
this.desc = desc;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
服务端定义了 5 个枚举值:
@Getter
enum StatusEnumServer {
...
CANCELED(5, "已取消");
private final int status;
private final String desc;
StatusEnumServer(Integer status, String desc) {
this.status = status;
this.desc = desc;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
写代码测试一下,使用 RestTemplate 来发起请求,让服务端返回客户端不存在的枚举值:
@GetMapping("getOrderStatusClient")
public void getOrderStatusClient() {
StatusEnumClient result = restTemplate.getForObject("http://localhost:45678/enumusedinapi/getOrderStatus", StatusEnumClient.class);
log.info("result {}", result);
}
@GetMapping("getOrderStatus")
public StatusEnumServer getOrderStatus() {
return StatusEnumServer.CANCELED;
}
2
3
4
5
6
7
8
9
10
访问接口会出现如下异常信息,提示在枚举 StatusEnumClient 中找不到 CANCELED:
JSON parse error: Cannot deserialize value of type `org.geekbang.time.commonmistakes.enums.enumusedinapi.StatusEnumClient` from String "CANCELED": not one of the values accepted for Enum class: [CREATED, FINISHED, DELIVERED, PAID];
要解决这个问题,可以开启 Jackson 的 read_unknown_enum_values_using_default_value 反序列化特性,也就是在枚举值未知的时候使用默认值:
spring.jackson.deserialization.read_unknown_enum_values_using_default_value=true
并为枚举添加一个默认值,使用 @JsonEnumDefaultValue 注解注释:
@JsonEnumDefaultValue
UNKNOWN(-1, "未知");
2
需要注意的是,这个枚举值一定是添加在客户端 StatusEnumClient 中的,因为反序列化使用的是客户端枚举。
这里还有一个小坑是,仅仅这样配置还不能让 RestTemplate 生效这个反序列化特性,还需要配置 RestTemplate,来使用 Spring Boot 的 MappingJackson2HttpMessageConverter 才行:
@Bean
public RestTemplate restTemplate(MappingJackson2HttpMessageConverter mappingJackson2HttpMessageConverter) {
return new RestTemplateBuilder()
.additionalMessageConverters(mappingJackson2HttpMessageConverter)
.build();
}
2
3
4
5
6
现在,请求接口可以返回默认值了:
[21:49:03.887] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:25 ] - result UNKNOWN
第二个坑,也是更大的坑,枚举序列化反序列化实现自定义的字段非常麻烦,会涉及 Jackson 的 Bug。比如,下面这个接口,传入枚举 List,为 List 增加一个 CENCELED 枚举值然后返回:
@PostMapping("queryOrdersByStatusList")
public List<StatusEnumServer> queryOrdersByStatus(@RequestBody List<StatusEnumServer> enumServers) {
enumServers.add(StatusEnumServer.CANCELED);
return enumServers;
}
2
3
4
5
如果我们希望根据枚举的 Desc 字段来序列化,传入“已送到”作为入参:
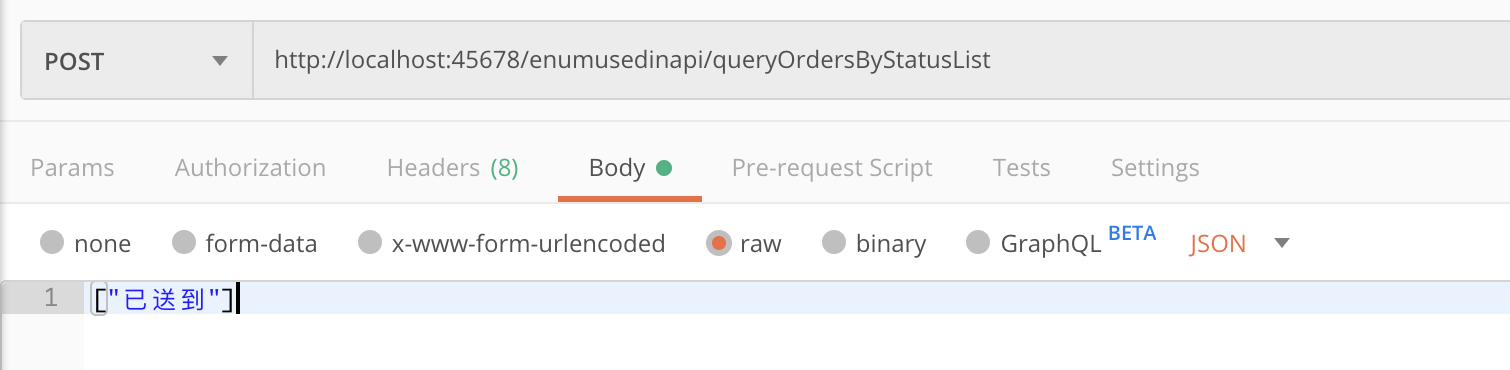
会得到异常,提示“已送到”不是正确的枚举值:
JSON parse error: Cannot deserialize value of type `org.geekbang.time.commonmistakes.enums.enumusedinapi.StatusEnumServer` from String "已送到": not one of the values accepted for Enum class: [CREATED, CANCELED, FINISHED, DELIVERED, PAID]
显然,这里反序列化使用的是枚举的 name,序列化也是一样:
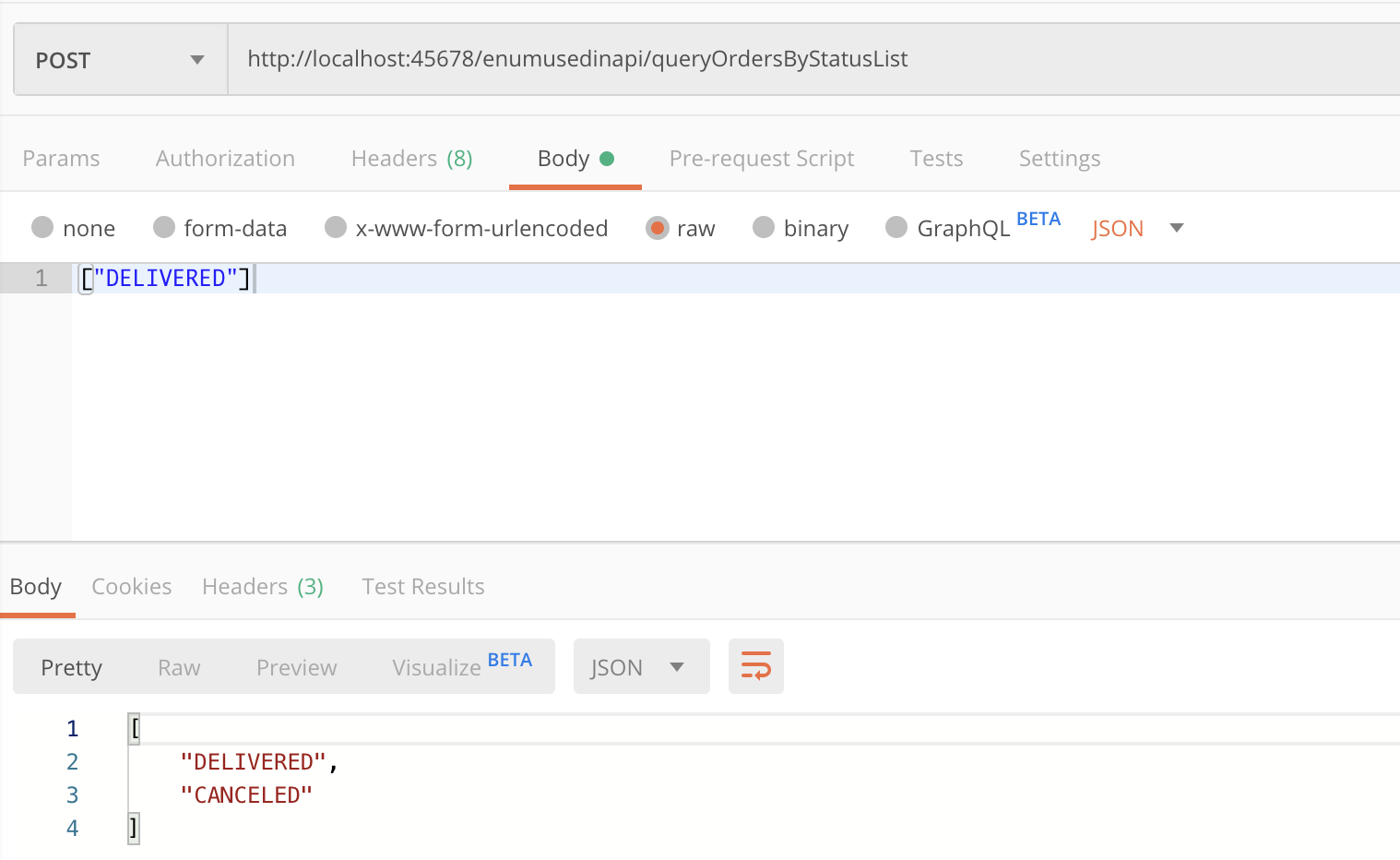
你可能也知道,要让枚举的序列化和反序列化走 desc 字段,可以在字段上加 @JsonValue 注解,修改 StatusEnumServer 和 StatusEnumClient:
@JsonValue
private final String desc;
2
然后再尝试下,果然可以用 desc 作为入参了,而且出参也使用了枚举的 desc:
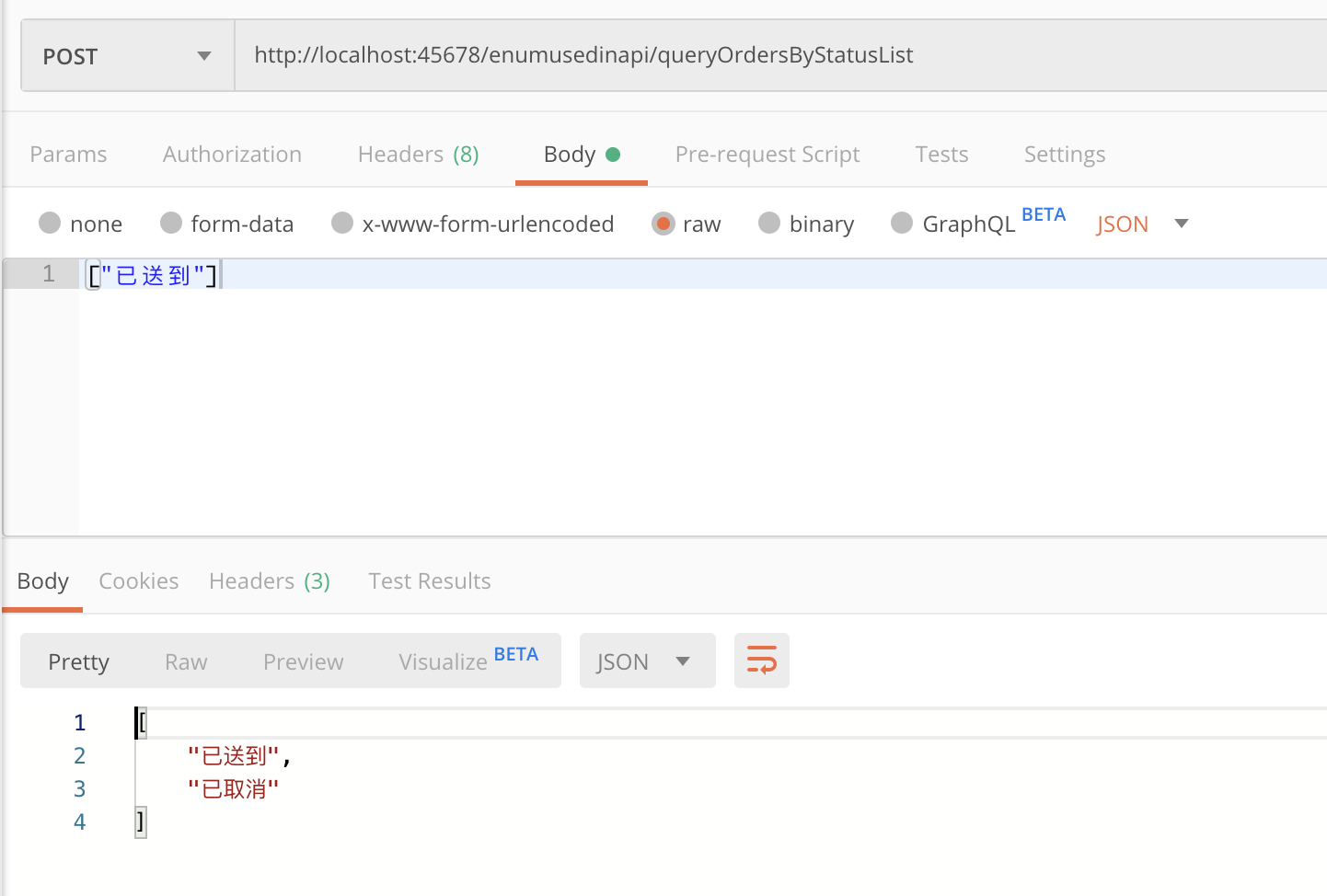
但是,如果你认为这样就完美解决问题了,那就大错特错了。你可以再尝试把 @JsonValue 注解加在 int 类型的 status 字段上,也就是希望序列化反序列化走 status 字段:
@JsonValue
private final int status;
2
写一个客户端测试一下,传入 CREATED 和 PAID 两个枚举值:
@GetMapping("queryOrdersByStatusListClient")
public void queryOrdersByStatusListClient() {
List<StatusEnumClient> request = Arrays.asList(StatusEnumClient.CREATED, StatusEnumClient.PAID);
HttpEntity<List<StatusEnumClient>> entity = new HttpEntity<>(request, new HttpHeaders());
List<StatusEnumClient> response = restTemplate.exchange("http://localhost:45678/enumusedinapi/queryOrdersByStatusList",
HttpMethod.POST, entity, new ParameterizedTypeReference<List<StatusEnumClient>>() {}).getBody();
log.info("result {}", response);
}
2
3
4
5
6
7
8
请求接口可以看到,传入的是 CREATED 和 PAID,返回的居然是 DELIVERED 和 FINISHED。果然如标题所说,一来一回你已不是原来的你:
[22:03:03.579] [http-nio-45678-exec-4] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:34 ] - result [DELIVERED, FINISHED, UNKNOWN]
出现这个问题的原因是,序列化走了 status 的值,而反序列化并没有根据 status 来,还是使用了枚举的 ordinal() 索引值。这是 Jackson(2.10)没有解决的 Bug。
如下图所示,我们调用服务端接口,传入一个不存在的 status 值 0,也能反序列化成功,最后服务端的返回是 1:
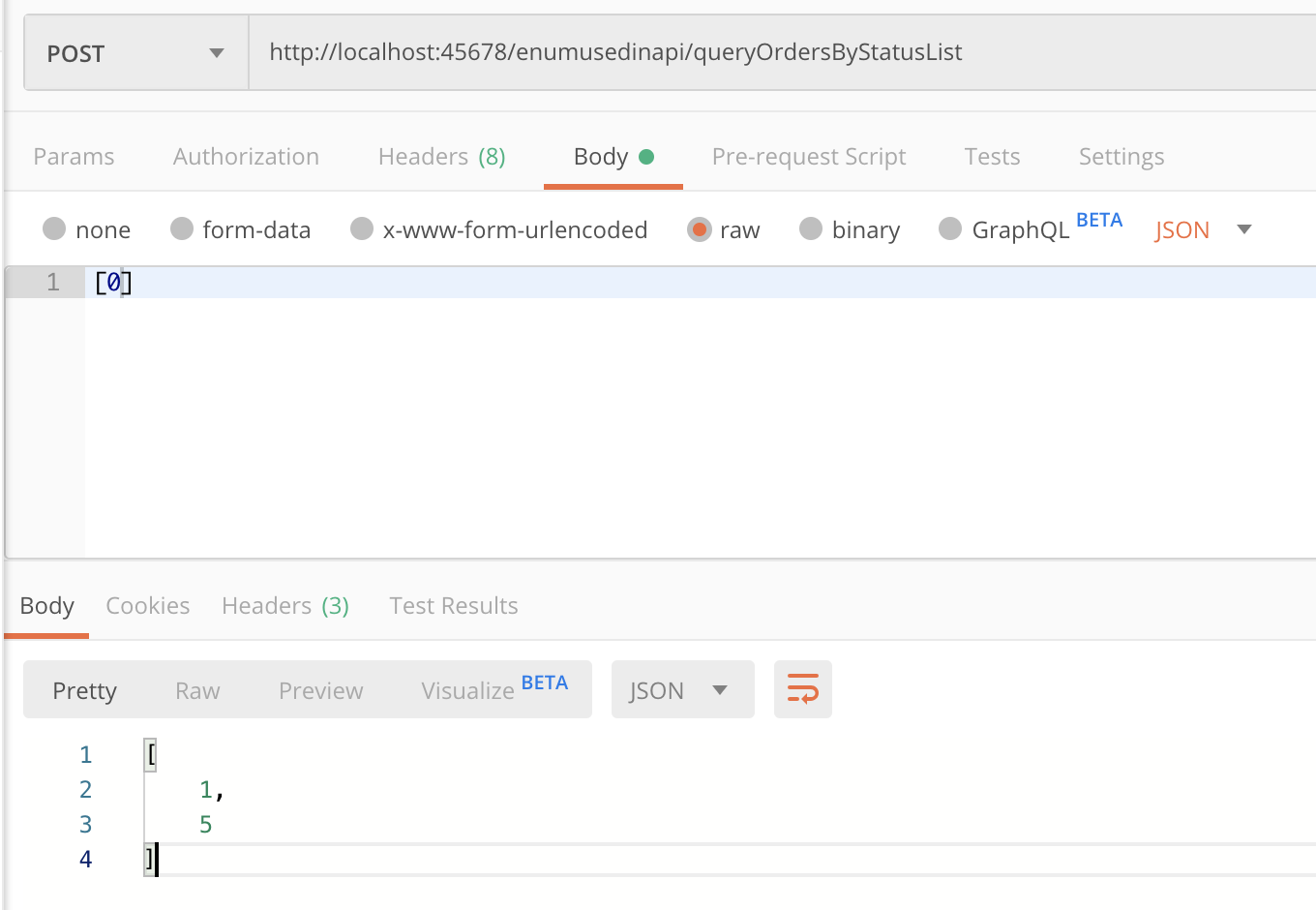
有一个解决办法是,设置 @JsonCreator 来强制反序列化时使用自定义的工厂方法,可以实现使用枚举的 status 字段来取值。我们把这段代码加在 StatusEnumServer 枚举类中:
@JsonCreator
public static StatusEnumServer parse(Object o) {
return Arrays.stream(StatusEnumServer.values()).filter(value->o.equals(value.status)).findFirst().orElse(null);
}
2
3
4
要特别注意的是,我们同样要为 StatusEnumClient 也添加相应的方法。因为除了服务端接口接收 StatusEnumServer 参数涉及一次反序列化外,从服务端返回值转换为 List 还会有一次反序列化:
@JsonCreator
public static StatusEnumClient parse(Object o) {
return Arrays.stream(StatusEnumClient.values()).filter(value->o.equals(value.status)).findFirst().orElse(null);
}
2
3
4
重新调用接口发现,虽然结果正确了,但是服务端不存在的枚举值 CANCELED 被设置为了 null,而不是 @JsonEnumDefaultValue 设置的 UNKNOWN。
这个问题,我们之前已经通过设置 @JsonEnumDefaultValue 注解解决了,但现在又出现了:
[22:20:13.727] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:34 ] - result [CREATED, PAID, null]
原因也很简单,我们自定义的 parse 方法实现的是找不到枚举值时返回 null。
为彻底解决这个问题,并避免通过 @JsonCreator 在枚举中自定义一个非常复杂的工厂方法,我们可以实现一个自定义的反序列化器。这段代码比较复杂,特意加了详细的注释:
class EnumDeserializer extends JsonDeserializer<Enum> implements
ContextualDeserializer {
private Class<Enum> targetClass;
public EnumDeserializer() {
}
public EnumDeserializer(Class<Enum> targetClass) {
this.targetClass = targetClass;
}
@Override
public Enum deserialize(JsonParser p, DeserializationContext ctxt) {
//找枚举中带有@JsonValue注解的字段,这是我们反序列化的基准字段
Optional<Field> valueFieldOpt = Arrays.asList(targetClass.getDeclaredFields()).stream()
.filter(m -> m.isAnnotationPresent(JsonValue.class))
.findFirst();
if (valueFieldOpt.isPresent()) {
Field valueField = valueFieldOpt.get();
if (!valueField.isAccessible()) {
valueField.setAccessible(true);
}
//遍历枚举项,查找字段的值等于反序列化的字符串的那个枚举项
return Arrays.stream(targetClass.getEnumConstants()).filter(e -> {
try {
return valueField.get(e).toString().equals(p.getValueAsString());
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}).findFirst().orElseGet(() -> Arrays.stream(targetClass.getEnumConstants()).filter(e -> {
//如果找不到,就需要寻找默认枚举值来替代,同样遍历所有枚举项,查找@JsonEnumDefaultValue注解标识的枚举项
try {
return targetClass.getField(e.name()).isAnnotationPresent(JsonEnumDefaultValue.class);
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}).findFirst().orElse(null));
}
return null;
}
@Override
public JsonDeserializer<?> createContextual(DeserializationContext ctxt,
BeanProperty property) throws JsonMappingException {
targetClass = (Class<Enum>) ctxt.getContextualType().getRawClass();
return new EnumDeserializer(targetClass);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
然后,把这个自定义反序列化器注册到 Jackson 中:
@Bean
public Module enumModule() {
SimpleModule module = new SimpleModule();
module.addDeserializer(Enum.class, new EnumDeserializer());
return module;
}
2
3
4
5
6
第二个大坑终于被完美地解决了:
[22:32:28.327] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.e.e.EnumUsedInAPIController:34 ] - result [CREATED, PAID, UNKNOWN]
这样做,虽然解决了序列化反序列化使用枚举中自定义字段的问题,也解决了找不到枚举值时使用默认值的问题,但解决方案很复杂。因此还是建议在 DTO 中直接使用 int 或 String 等简单的数据类型,而不是使用枚举再配合各种复杂的序列化配置,来实现枚举到枚举中字段的映射,会更加清晰明了。
# 时间日期类
在 Java 8 之前,我们处理日期时间需求时,使用 Date、Calender 和 SimpleDateFormat,来声明时间戳、使用日历处理日期和格式化解析日期时间。但是,这些类的 API 的缺点比较明显,比如可读性差、易用性差、使用起来冗余繁琐,还有线程安全问题。
因此,Java 8 推出了新的日期时间类。每一个类功能明确清晰、类之间协作简单、API 定义清晰不踩坑,API 功能强大无需借助外部工具类即可完成操作,并且线程安全。
但是,Java 8 刚推出的时候,诸如序列化、数据访问等类库都还不支持 Java 8 的日期时间类型,需要在新老类中来回转换。比如,在业务逻辑层使用 LocalDateTime,存入数据库或者返回前端的时候还要切换回 Date。因此,很多同学还是选择使用老的日期时间类。
现在几年时间过去了,几乎所有的类库都支持了新日期时间类型,使用起来也不会有来回切换等问题了。但很多代码中因为还是用的遗留的日期时间类,因此出现了很多时间错乱的错误实践。比如,试图通过随意修改时区,使读取到的数据匹配当前时钟;再比如,试图直接对读取到的数据做加、减几个小时的操作,来“修正数据”。
# 初始化日期时间
我们先从日期时间的初始化看起。如果要初始化一个 2019 年 12 月 31 日 11 点 12 分 13 秒这样的时间,可以使用下面的两行代码吗?
Date date = new Date(2019, 12, 31, 11, 12, 13);
System.out.println(date);
2
可以看到,输出的时间是 3029 年 1 月 31 日 11 点 12 分 13 秒:
Sat Jan 31 11:12:13 CST 3920
相信看到这里,你会说这是新手才会犯的低级错误:年应该是和 1900 的差值,月应该是从 0 到 11 而不是从 1 到 12。
你说的没错,但更重要的问题是,当有国际化需求时,需要使用 Calendar 类来初始化时间。
使用 Calendar 改造之后,初始化时年参数直接使用当前年即可,不过月需要注意是从 0 到 11。当然,你也可以直接使用 Calendar.DECEMBER 来初始化月份,更不容易犯错。为了说明时区的问题,分别使用当前时区和纽约时区初始化了两次相同的日期:
Calendar calendar = Calendar.getInstance();
calendar.set(2019, 11, 31, 11, 12, 13);
System.out.println(calendar.getTime());
Calendar calendar2 = Calendar.getInstance(TimeZone.getTimeZone("America/New_York"));
calendar2.set(2019, Calendar.DECEMBER, 31, 11, 12, 13);
System.out.println(calendar2.getTime());
2
3
4
5
6
输出显示了两个时间,说明时区产生了作用。但,我们更习惯年 / 月 / 日 时: 分: 秒这样的日期时间格式,对现在输出的日期格式还不满意:
Tue Dec 31 11:12:13 CST 2019
Wed Jan 01 00:12:13 CST 2020
2
那时区的问题是怎么回事,又怎么格式化需要输出的日期时间呢?
# “恼人”的时区问题
我们知道,全球有 24 个时区,同一个时刻不同时区(比如中国上海和美国纽约)的时间是不一样的。对于需要全球化的项目,如果初始化时间时没有提供时区,那就不是一个真正意义上的时间,只能认为是看到的当前时间的一个表示。
关于 Date 类,我们要有两点认识:
- 一是,Date 并无时区问题,世界上任何一台计算机使用 new Date() 初始化得到的时间都一样。因为,Date 中保存的是 UTC 时间,UTC 是以原子钟为基础的统一时间,不以太阳参照计时,并无时区划分。
- 二是,Date 中保存的是一个时间戳,代表的是从 1970 年 1 月 1 日 0 点(Epoch 时间)到现在的毫秒数。尝试输出 Date(0):
System.out.println(new Date(0));
System.out.println(TimeZone.getDefault().getID() + ":" + TimeZone.getDefault().getRawOffset()/3600000);
2
得到的是 1970 年 1 月 1 日 8 点。因为机器当前的时区是中国上海,相比 UTC 时差 +8 小时:
Thu Jan 01 08:00:00 CST 1970
Asia/Shanghai:8
2
对于国际化(世界各国的人都在使用)的项目,处理好时间和时区问题首先就是要正确保存日期时间。这里有两种保存方式:
- 方式一,以 UTC 保存,保存的时间没有时区属性,是不涉及时区时间差问题的世界统一时间。我们通常说的时间戳,或 Java 中的 Date 类就是用的这种方式,这也是推荐的方式。
- 方式二,以字面量保存,比如年 / 月 / 日 时: 分: 秒,一定要同时保存时区信息。只有有了时区信息,我们才能知道这个字面量时间真正的时间点,否则它只是一个给人看的时间表示,只在当前时区有意义。Calendar 是有时区概念的,所以我们通过不同的时区初始化 Calendar,得到了不同的时间。
正确保存日期时间之后,就是正确展示,即我们要使用正确的时区,把时间点展示为符合当前时区的时间表示。到这里,我们就能理解为什么会有所谓的“时间错乱”问题了。接下来,再通过实际案例分析一下,从字面量解析成时间和从时间格式化为字面量这两类问题。
第一类是,对于同一个时间表示,比如 2020-01-02 22:00:00,不同时区的人转换成 Date 会得到不同的时间(时间戳):
String stringDate = "2020-01-02 22:00:00";
SimpleDateFormat inputFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//默认时区解析时间表示
Date date1 = inputFormat.parse(stringDate);
System.out.println(date1 + ":" + date1.getTime());
//纽约时区解析时间表示
inputFormat.setTimeZone(TimeZone.getTimeZone("America/New_York"));
Date date2 = inputFormat.parse(stringDate);
System.out.println(date2 + ":" + date2.getTime());
2
3
4
5
6
7
8
9
可以看到,把 2020-01-02 22:00:00 这样的时间表示,对于当前的上海时区和纽约时区,转化为 UTC 时间戳是不同的时间:
Thu Jan 02 22:00:00 CST 2020:1577973600000
Fri Jan 03 11:00:00 CST 2020:1578020400000
2
这正是 UTC 的意义,并不是时间错乱。对于同一个本地时间的表示,不同时区的人解析得到的 UTC 时间一定是不同的,反过来不同的本地时间可能对应同一个 UTC。
第二类问题是,格式化后出现的错乱,即同一个 Date,在不同的时区下格式化得到不同的时间表示。比如,在我的当前时区和纽约时区格式化 2020-01-02 22:00:00:
String stringDate = "2020-01-02 22:00:00";
SimpleDateFormat inputFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//同一Date
Date date = inputFormat.parse(stringDate);
//默认时区格式化输出:
System.out.println(new SimpleDateFormat("[yyyy-MM-dd HH:mm:ss Z]").format(date));
//纽约时区格式化输出
TimeZone.setDefault(TimeZone.getTimeZone("America/New_York"));
System.out.println(new SimpleDateFormat("[yyyy-MM-dd HH:mm:ss Z]").format(date));
2
3
4
5
6
7
8
9
输出如下,我当前时区的 Offset(时差)是 +8 小时,对于 -5 小时的纽约,晚上 10 点对应早上 9 点:
[2020-01-02 22:00:00 +0800]
[2020-01-02 09:00:00 -0500]
2
因此,有些时候数据库中相同的时间,由于服务器的时区设置不同,读取到的时间表示不同。这不是时间错乱,正是时区发挥了作用,因为 UTC 时间需要根据当前时区解析为正确的本地时间。
所以,要正确处理时区,在于存进去和读出来两方面:存的时候,需要使用正确的当前时区来保存,这样 UTC 时间才会正确;读的时候,也只有正确设置本地时区,才能把 UTC 时间转换为正确的当地时间。
Java 8 推出了新的时间日期类 ZoneId、ZoneOffset、LocalDateTime、ZonedDateTime 和 DateTimeFormatter,处理时区问题更简单清晰。我们再用这些类配合一个完整的例子,来理解一下时间的解析和展示:
- 首先初始化上海、纽约和东京三个时区。我们可以使用 ZoneId.of 来初始化一个标准的时区,也可以使用 ZoneOffset.ofHours 通过一个 offset,来初始化一个具有指定时间差的自定义时区。
- 对于日期时间表示,LocalDateTime 不带有时区属性,所以命名为本地时区的日期时间;而 ZonedDateTime=LocalDateTime+ZoneId,具有时区属性。因此,LocalDateTime 只能认为是一个时间表示,ZonedDateTime 才是一个有效的时间。在这里我们把 2020-01-02 22:00:00 这个时间表示,使用东京时区来解析得到一个 ZonedDateTime。
- 使用 DateTimeFormatter 格式化时间的时候,可以直接通过 withZone 方法直接设置格式化使用的时区。最后,分别以上海、纽约和东京三个时区来格式化这个时间输出:
//一个时间表示
String stringDate = "2020-01-02 22:00:00";
//初始化三个时区
ZoneId timeZoneSH = ZoneId.of("Asia/Shanghai");
ZoneId timeZoneNY = ZoneId.of("America/New_York");
ZoneId timeZoneJST = ZoneOffset.ofHours(9);
//格式化器
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
ZonedDateTime date = ZonedDateTime.of(LocalDateTime.parse(stringDate, dateTimeFormatter), timeZoneJST);
//使用DateTimeFormatter格式化时间,可以通过withZone方法直接设置格式化使用的时区
DateTimeFormatter outputFormat = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss Z");
System.out.println(timeZoneSH.getId() + outputFormat.withZone(timeZoneSH).format(date));
System.out.println(timeZoneNY.getId() + outputFormat.withZone(timeZoneNY).format(date));
System.out.println(timeZoneJST.getId() + outputFormat.withZone(timeZoneJST).format(date));
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看到,相同的时区,经过解析存进去和读出来的时间表示是一样的(比如最后一行);而对于不同的时区,比如上海和纽约,最后输出的本地时间不同。+9 小时时区的晚上 10 点,对于上海是 +8 小时,所以上海本地时间是晚上 9 点;而对于纽约是 -5 小时,差 14 小时,所以是早上 8 点:
Asia/Shanghai2020-01-02 21:00:00 +0800
America/New_York2020-01-02 08:00:00 -0500
+09:002020-01-02 22:00:00 +0900
2
3
要正确处理国际化时间问题,推荐使用 Java 8 的日期时间类,即使用 ZonedDateTime 保存时间,然后使用设置了 ZoneId 的 DateTimeFormatter 配合 ZonedDateTime 进行时间格式化得到本地时间表示。这样的划分十分清晰、细化,也不容易出错。
# 日期时间格式化和解析
每到年底,就有很多开发同学踩时间格式化的坑,比如“这明明是一个 2019 年的日期,怎么使用 SimpleDateFormat 格式化后就提前跨年了。我们来重现一下这个问题。
初始化一个 Calendar,设置日期时间为 2019 年 12 月 29 日,使用大写的 YYYY 来初始化 SimpleDateFormat:
Locale.setDefault(Locale.SIMPLIFIED_CHINESE);
System.out.println("defaultLocale:" + Locale.getDefault());
Calendar calendar = Calendar.getInstance();
calendar.set(2019, Calendar.DECEMBER, 29,0,0,0);
SimpleDateFormat YYYY = new SimpleDateFormat("YYYY-MM-dd");
System.out.println("格式化: " + YYYY.format(calendar.getTime()));
System.out.println("weekYear:" + calendar.getWeekYear());
System.out.println("firstDayOfWeek:" + calendar.getFirstDayOfWeek());
System.out.println("minimalDaysInFirstWeek:" + calendar.getMinimalDaysInFirstWeek());
2
3
4
5
6
7
8
9
得到的输出却是 2020 年 12 月 29 日:
defaultLocale:zh_CN
格式化: 2020-12-29
weekYear:2020
firstDayOfWeek:1
minimalDaysInFirstWeek:1
2
3
4
5
出现这个问题的原因在于,这位同学混淆了 SimpleDateFormat 的各种格式化模式。JDK 的文档中有说明:小写 y 是年,而大写 Y 是 week year,也就是所在的周属于哪一年。
一年第一周的判断方式是,从 getFirstDayOfWeek() 开始,完整的 7 天,并且包含那一年至少 getMinimalDaysInFirstWeek() 天。这个计算方式和区域相关,对于当前 zh_CN 区域来说,2020 年第一周的条件是,从周日开始的完整 7 天,2020 年包含 1 天即可。显然,2019 年 12 月 29 日周日到 2020 年 1 月 4 日周六是 2020 年第一周,得出的 week year 就是 2020 年。
如果把区域改为法国:
Locale.setDefault(Locale.FRANCE);
那么 week yeay 就还是 2019 年,因为一周的第一天从周一开始算,2020 年的第一周是 2019 年 12 月 30 日周一开始,29 日还是属于去年:
defaultLocale:fr_FR
格式化: 2019-12-29
weekYear:2019
firstDayOfWeek:2
minimalDaysInFirstWeek:4
2
3
4
5
这个案例告诉我们,没有特殊需求,针对年份的日期格式化,应该一律使用 “y” 而非 “Y”。
除了格式化表达式容易踩坑外,SimpleDateFormat 还有两个著名的坑。
第一个坑是,定义的 static 的 SimpleDateFormat 可能会出现线程安全问题。比如像这样,使用一个 100 线程的线程池,循环 20 次把时间格式化任务提交到线程池处理,每个任务中又循环 10 次解析 2020-01-01 11:12:13 这样一个时间表示:
ExecutorService threadPool = Executors.newFixedThreadPool(100);
for (int i = 0; i < 20; i++) {
//提交20个并发解析时间的任务到线程池,模拟并发环境
threadPool.execute(() -> {
for (int j = 0; j < 10; j++) {
try {
System.out.println(simpleDateFormat.parse("2020-01-01 11:12:13"));
} catch (ParseException e) {
e.printStackTrace();
}
}
});
}
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
运行程序后大量报错,且没有报错的输出结果也不正常,比如 2020 年解析成了 1212 年:
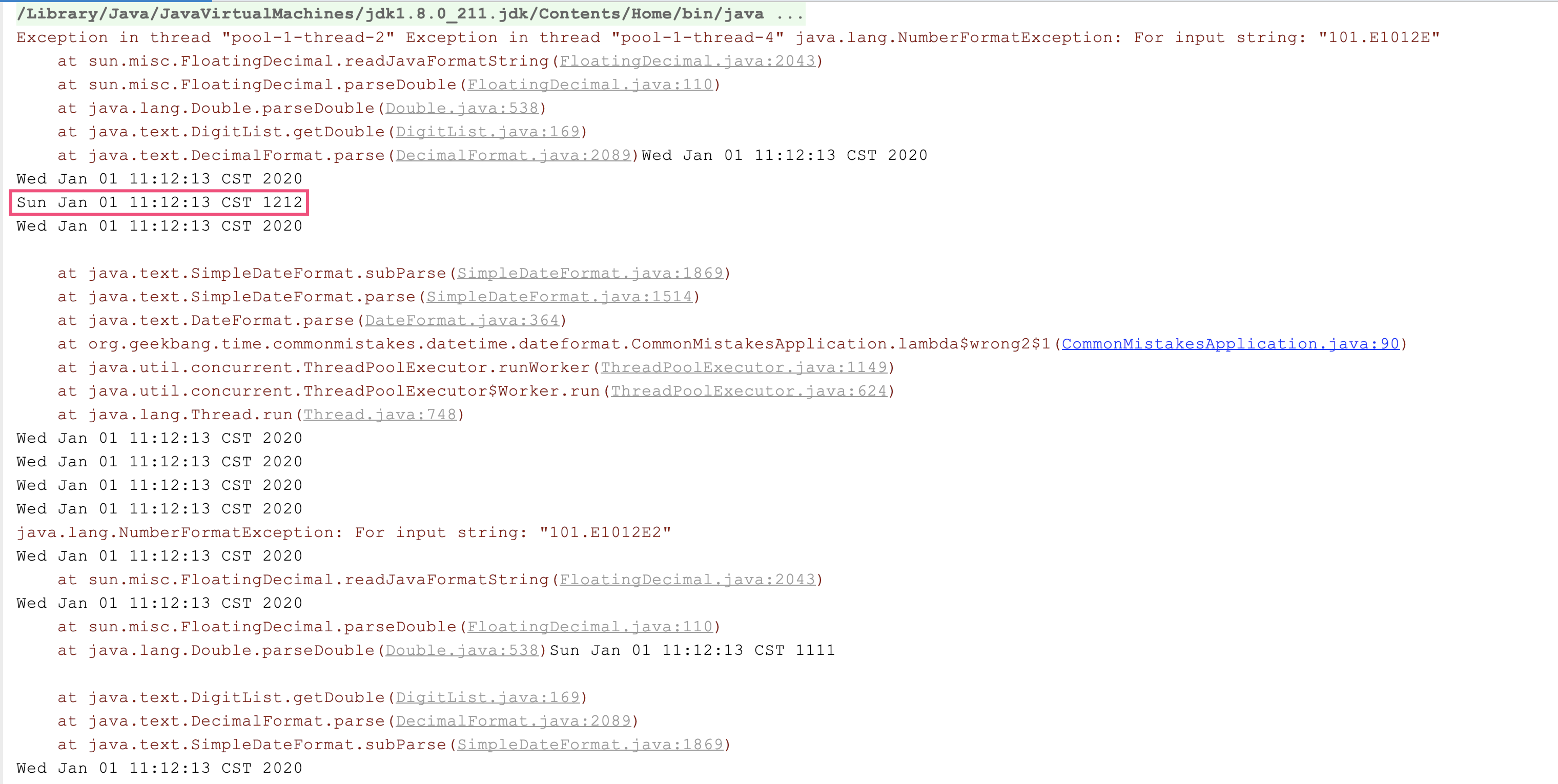
SimpleDateFormat 的作用是定义解析和格式化日期时间的模式。看起来这是一次性的工作,应该复用,但它的解析和格式化操作是非线程安全的。我们来分析一下相关源码:
- SimpleDateFormat 继承了 DateFormat,DateFormat 有一个字段 Calendar;
- SimpleDateFormat 的 parse 方法调用 CalendarBuilder 的 establish 方法,来构建 Calendar;
- establish 方法内部先清空 Calendar 再构建 Calendar,整个操作没有加锁。
显然,如果多线程池调用 parse 方法,也就意味着多线程在并发操作一个 Calendar,可能会产生一个线程还没来得及处理 Calendar 就被另一个线程清空了的情况:
public abstract class DateFormat extends Format {
protected Calendar calendar;
}
public class SimpleDateFormat extends DateFormat {
@Override
public Date parse(String text, ParsePosition pos)
{
CalendarBuilder calb = new CalendarBuilder();
parsedDate = calb.establish(calendar).getTime();
return parsedDate;
}
}
class CalendarBuilder {
Calendar establish(Calendar cal) {
...
cal.clear();//清空
for (int stamp = MINIMUM_USER_STAMP; stamp < nextStamp; stamp++) {
for (int index = 0; index <= maxFieldIndex; index++) {
if (field[index] == stamp) {
cal.set(index, field[MAX_FIELD + index]);//构建
break;
}
}
}
return cal;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
format 方法也类似,你可以自己分析。因此只能在同一个线程复用 SimpleDateFormat,比较好的解决方式是,通过 ThreadLocal 来存放 SimpleDateFormat:
private static ThreadLocal<SimpleDateFormat> threadSafeSimpleDateFormat = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
第二个坑是,当需要解析的字符串和格式不匹配的时候,SimpleDateFormat 表现得很宽容,还是能得到结果。比如,我们期望使用 yyyyMM 来解析 20160901 字符串:
String dateString = "20160901";
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyyMM");
System.out.println("result:" + dateFormat.parse(dateString));
2
3
居然输出了 2091 年 1 月 1 日,原因是把 0901 当成了月份,相当于 75 年:
result:Mon Jan 01 00:00:00 CST 2091
对于 SimpleDateFormat 的这三个坑,我们使用 Java 8 中的 DateTimeFormatter 就可以避过去。首先,使用 DateTimeFormatterBuilder 来定义格式化字符串,不用去记忆使用大写的 Y 还是小写的 Y,大写的 M 还是小写的 m:
private static DateTimeFormatter dateTimeFormatter = new DateTimeFormatterBuilder()
.appendValue(ChronoField.YEAR) //年
.appendLiteral("/")
.appendValue(ChronoField.MONTH_OF_YEAR) //月
.appendLiteral("/")
.appendValue(ChronoField.DAY_OF_MONTH) //日
.appendLiteral(" ")
.appendValue(ChronoField.HOUR_OF_DAY) //时
.appendLiteral(":")
.appendValue(ChronoField.MINUTE_OF_HOUR) //分
.appendLiteral(":")
.appendValue(ChronoField.SECOND_OF_MINUTE) //秒
.appendLiteral(".")
.appendValue(ChronoField.MILLI_OF_SECOND) //毫秒
.toFormatter();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
其次,DateTimeFormatter 是线程安全的,可以定义为 static 使用;最后,DateTimeFormatter 的解析比较严格,需要解析的字符串和格式不匹配时,会直接报错,而不会把 0901 解析为月份。我们测试一下:
//使用刚才定义的DateTimeFormatterBuilder构建的DateTimeFormatter来解析这个时间
LocalDateTime localDateTime = LocalDateTime.parse("2020/1/2 12:34:56.789", dateTimeFormatter);
//解析成功
System.out.println(localDateTime.format(dateTimeFormatter));
//使用yyyyMM格式解析20160901是否可以成功呢?
String dt = "20160901";
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyyMM");
System.out.println("result:" + dateTimeFormatter.parse(dt));
2
3
4
5
6
7
8
输出日志如下:
2020/1/2 12:34:56.789
Exception in thread "main" java.time.format.DateTimeParseException: Text '20160901' could not be parsed at index 0
at java.time.format.DateTimeFormatter.parseResolved0(DateTimeFormatter.java:1949)
at java.time.format.DateTimeFormatter.parse(DateTimeFormatter.java:1777)
at org.geekbang.time.commonmistakes.datetime.dateformat.CommonMistakesApplication.better(CommonMistakesApplication.java:80)
at org.geekbang.time.commonmistakes.datetime.dateformat.CommonMistakesApplication.main(CommonMistakesApplication.java:41)
2
3
4
5
6
使用 Java 8 中的 DateTimeFormatter 进行日期时间的格式化和解析,显然更让人放心。
# 日期时间的计算
关于日期时间的计算,有些同学喜欢直接使用时间戳进行时间计算,比如希望得到当前时间之后 30 天的时间,会这么写代码:直接把 new Date().getTime 方法得到的时间戳加 30 天对应的毫秒数,也就是 30 天 *1000 毫秒 *3600 秒 *24 小时:
Date today = new Date();
Date nextMonth = new Date(today.getTime() + 30 * 1000 * 60 * 60 * 24);
System.out.println(today);
System.out.println(nextMonth);
2
3
4
得到的日期居然比当前日期还要早,根本不是晚 30 天的时间:
Sat Feb 01 14:17:41 CST 2020
Sun Jan 12 21:14:54 CST 2020
2
出现这个问题,其实是因为 int 发生了溢出。修复方式就是把 30 改为 30L,让其成为一个 long:
Date today = new Date();
Date nextMonth = new Date(today.getTime() + 30L * 1000 * 60 * 60 * 24);
System.out.println(today);
System.out.println(nextMonth);
2
3
4
这样就可以得到正确结果了:
Sat Feb 01 14:17:41 CST 2020
Mon Mar 02 14:17:41 CST 2020
2
不难发现,手动在时间戳上进行计算操作的方式非常容易出错。对于 Java 8 之前的代码,更建议使用 Calendar:
Calendar c = Calendar.getInstance();
c.setTime(new Date());
c.add(Calendar.DAY_OF_MONTH, 30);
System.out.println(c.getTime());
2
3
4
使用 Java 8 的日期时间类型,可以直接进行各种计算,更加简洁和方便:
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println(localDateTime.plusDays(30));
2
并且,对日期时间做计算操作,Java 8 日期时间 API 会比 Calendar 功能强大很多。
第一,可以使用各种 minus 和 plus 方法直接对日期进行加减操作,比如如下代码实现了减一天和加一天,以及减一个月和加一个月:
System.out.println("//测试操作日期");
System.out.println(LocalDate.now()
.minus(Period.ofDays(1))
.plus(1, ChronoUnit.DAYS)
.minusMonths(1)
.plus(Period.ofMonths(1)));
2
3
4
5
6
可以得到:
//测试操作日期
2020-02-01
2
第二,还可以通过 with 方法进行快捷时间调节,比如:
- 使用 TemporalAdjusters.firstDayOfMonth 得到当前月的第一天;
- 使用 TemporalAdjusters.firstDayOfYear() 得到当前年的第一天;
- 使用 TemporalAdjusters.previous(DayOfWeek.SATURDAY) 得到上一个周六;
- 使用 TemporalAdjusters.lastInMonth(DayOfWeek.FRIDAY) 得到本月最后一个周五。
System.out.println("//本月的第一天");
System.out.println(LocalDate.now().with(TemporalAdjusters.firstDayOfMonth()));
System.out.println("//今年的程序员日");
System.out.println(LocalDate.now().with(TemporalAdjusters.firstDayOfYear()).plusDays(255));
System.out.println("//今天之前的一个周六");
System.out.println(LocalDate.now().with(TemporalAdjusters.previous(DayOfWeek.SATURDAY)));
System.out.println("//本月最后一个工作日");
System.out.println(LocalDate.now().with(TemporalAdjusters.lastInMonth(DayOfWeek.FRIDAY)));
2
3
4
5
6
7
8
9
10
11
输出如下:
//本月的第一天
2020-02-01
//今年的程序员日
2020-09-12
//今天之前的一个周六
2020-01-25
//本月最后一个工作日
2020-02-28
2
3
4
5
6
7
8
第三,可以直接使用 lambda 表达式进行自定义的时间调整。比如,为当前时间增加 100 天以内的随机天数:
System.out.println(LocalDate.now().with(temporal -> temporal.plus(ThreadLocalRandom.current().nextInt(100), ChronoUnit.DAYS)));
得到:
2020-03-15
除了计算外,还可以判断日期是否符合某个条件。比如,自定义函数,判断指定日期是否是家庭成员的生日:
public static Boolean isFamilyBirthday(TemporalAccessor date) {
int month = date.get(MONTH_OF_YEAR);
int day = date.get(DAY_OF_MONTH);
if (month == Month.FEBRUARY.getValue() && day == 17)
return Boolean.TRUE;
if (month == Month.SEPTEMBER.getValue() && day == 21)
return Boolean.TRUE;
if (month == Month.MAY.getValue() && day == 22)
return Boolean.TRUE;
return Boolean.FALSE;
}
2
3
4
5
6
7
8
9
10
11
然后,使用 query 方法查询是否匹配条件:
System.out.println("//查询是否是今天要举办生日");
System.out.println(LocalDate.now().query(CommonMistakesApplication::isFamilyBirthday));
2
使用 Java 8 操作和计算日期时间虽然方便,但计算两个日期差时可能会踩坑:Java 8 中有一个专门的类 Period 定义了日期间隔,通过 Period.between 得到了两个 LocalDate 的差,返回的是两个日期差几年零几月零几天。如果希望得知两个日期之间差几天,直接调用 Period 的 getDays() 方法得到的只是最后的“零几天”,而不是算总的间隔天数。
比如,计算 2019 年 12 月 12 日和 2019 年 10 月 1 日的日期间隔,很明显日期差是 2 个月零 11 天,但获取 getDays 方法得到的结果只是 11 天,而不是 72 天:
System.out.println("//计算日期差");
LocalDate today = LocalDate.of(2019, 12, 12);
LocalDate specifyDate = LocalDate.of(2019, 10, 1);
System.out.println(Period.between(specifyDate, today).getDays());
System.out.println(Period.between(specifyDate, today));
System.out.println(ChronoUnit.DAYS.between(specifyDate, today));
2
3
4
5
6
可以使用 ChronoUnit.DAYS.between 解决这个问题:
//计算日期差
11
P2M11D
72
2
3
4
# 问题解答
问题 1:关于在 finally 代码块中抛出异常的坑,如果在 finally 代码块中返回值,你觉得程序会以 try 或 catch 中的返回值为准,还是以 finally 中的返回值为准呢?
答:以 finally 中的返回值为准。
从语义上来说,finally 是做方法收尾资源释放处理的,我们不建议在 finally 中有 return,这样逻辑会很混乱。这是因为,实现上 finally 中的代码块会被复制多份,分别放到 try 和 catch 调用 return 和 throw 异常之前,所以 finally 中如果有返回值,会覆盖 try 中的返回值。
问题 2:对于手动抛出的异常,不建议直接使用 Exception 或 RuntimeException,通常建议复用 JDK 中的一些标准异常,比如IllegalArgumentException、IllegalStateException、UnsupportedOperationException。你能说说它们的适用场景,并列出更多常见的可重用标准异常吗?
答:我们先分别看看 IllegalArgumentException、IllegalStateException、UnsupportedOperationException 这三种异常的适用场景。
- IllegalArgumentException:参数不合法异常,适用于传入的参数不符合方法要求的场景。
- IllegalStateException:状态不合法异常,适用于状态机的状态的无效转换,当前逻辑的执行状态不适合进行相应操作等场景。
- UnsupportedOperationException:操作不支持异常,适用于某个操作在实现或环境下不支持的场景。
还可以重用的异常有 IndexOutOfBoundsException、NullPointerException、ConcurrentModificationException 等。
问题 3:如果要把 INFO 和 WARN 级别的日志存放到 _info.log 中,把 ERROR 日志存放到 _error.log 中,应该如何配置 Logback 呢?
答:要实现这个配置有两种方式,分别是:直接使用 EvaluatorFilter 和自定义一个 Filter。我们分别看一下。
第一种方式是,直接使用 logback 自带的 EvaluatorFilter:
<filter class="ch.qos.logback.core.filter.EvaluatorFilter"> <evaluator class="ch.qos.logback.classic.boolex.GEventEvaluator"> <expression> e.level.toInt() == WARN.toInt() || e.level.toInt() == INFO.toInt() </expression> </evaluator> <OnMismatch>DENY</OnMismatch> <OnMatch>NEUTRAL</OnMatch> </filter>1
2
3
4
5
6
7
8
9第二种方式是,自定义一个 Filter,实现解析配置中的“|”字符分割的多个 Level:
public class MultipleLevelsFilter extends Filter<ILoggingEvent> { @Getter @Setter private String levels; private List<Integer> levelList; @Override public FilterReply decide(ILoggingEvent event) { if (levelList == null && !StringUtils.isEmpty(levels)) { //把由|分割的多个Level转换为List<Integer> levelList = Arrays.asList(levels.split("\\|")).stream() .map(item -> Level.valueOf(item)) .map(level -> level.toInt()) .collect(Collectors.toList()); } //如果levelList包含当前日志的级别,则接收否则拒绝 if (levelList.contains(event.getLevel().toInt())) return FilterReply.ACCEPT; else return FilterReply.DENY; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23然后,在配置文件中使用这个 MultipleLevelsFilter 就可以了:
<filter class="org.geekbang.time.commonmistakes.logging.duplicate.MultipleLevelsFilter"> <levels>INFO|WARN</levels> </filter>1
2
3问题 4:生产级项目的文件日志肯定需要按时间和日期进行分割和归档处理,以避免单个文件太大,同时保留一定天数的历史日志,你知道如何配置吗?可以在官方文档找到答案。
答:参考配置如下,使用 SizeAndTimeBasedRollingPolicy 来实现按照文件大小和历史文件保留天数,进行文件分割和归档:
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"> <!--日志文件保留天数--> <MaxHistory>30</MaxHistory> <!--日志文件最大的大小--> <MaxFileSize>100MB</MaxFileSize> <!--日志整体最大 可选的totalSizeCap属性控制所有归档文件的总大小。当超过总大小上限时,将异步删除最旧的存档。 totalSizeCap属性也需要设置maxHistory属性。此外,“最大历史”限制总是首先应用,“总大小上限”限制其次应用。 --> <totalSizeCap>10GB</totalSizeCap> </rollingPolicy>1
2
3
4
5
6
7
8
9
10
11问题 5:Files.lines 方法进行流式处理,需要使用 try-with-resources 进行资源释放。那么,使用 Files 类中其他返回 Stream 包装对象的方法进行流式处理,比如 newDirectoryStream 方法返回 DirectoryStream,list、walk 和 find 方法返回 Stream,也同样有资源释放问题吗?
答:使用 Files 类中其他返回 Stream 包装对象的方法进行流式处理,也同样会有资源释放问题。
因为,这些接口都需要使用 try-with-resources 模式来释放。正如文中所说,如果不显式释放,那么可能因为底层资源没有及时关闭造成资源泄露。
问题 6:Java 的 File 类和 Files 类提供的文件复制、重命名、删除等操作,是原子性的吗?
答:Java 的 File 和 Files 类的文件复制、重命名、删除等操作,都不是原子性的。原因是,文件类操作基本都是调用操作系统本身的 API,一般来说这些文件 API 并不像数据库有事务机制(也很难办到),即使有也很可能有平台差异性。
问题 7:在讨论 Redis 序列化方式的时候,我们自定义了 RedisTemplate,让 Key 使用 String 序列化、让 Value 使用 JSON 序列化,从而使 Redis 获得的 Value 可以直接转换为需要的对象类型。那么,使用 RedisTemplate 能否存取 Value 是 Long 的数据呢?这其中有什么坑吗?
答:使用 RedisTemplate,不一定能存取 Value 是 Long 的数据。在 Integer 区间内返回的是 Integer,超过这个区间返回 Long。测试代码如下:
@GetMapping("wrong2") public void wrong2() { String key = "testCounter"; //测试一下设置在Integer范围内的值 countRedisTemplate.opsForValue().set(key, 1L); log.info("{} {}", countRedisTemplate.opsForValue().get(key), countRedisTemplate.opsForValue().get(key) instanceof Long); Long l1 = getLongFromRedis(key); //测试一下设置超过Integer范围的值 countRedisTemplate.opsForValue().set(key, Integer.MAX_VALUE + 1L); log.info("{} {}", countRedisTemplate.opsForValue().get(key), countRedisTemplate.opsForValue().get(key) instanceof Long); //使用getLongFromRedis转换后的值必定是Long Long l2 = getLongFromRedis(key); log.info("{} {}", l1, l2); } private Long getLongFromRedis(String key) { Object o = countRedisTemplate.opsForValue().get(key); if (o instanceof Integer) { return ((Integer) o).longValue(); } if (o instanceof Long) { return (Long) o; } return null; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25会得到如下输出:
1 false 2147483648 true 1 21474836481
2
3可以看到,值设置 1 的时候类型不是 Long,设置 2147483648 的时候是 Long。也就是使用 RedisTemplate<String, Long> 不一定就代表获取的到的 Value 是 Long。
所以,这边写了一个 getLongFromRedis 方法来做转换避免出错,判断当值是 Integer 的时候转换为 Long。
问题 8:你可以看一下 Jackson2ObjectMapperBuilder 类源码的实现(注意 configure 方法),分析一下其除了关闭 FAIL_ON_UNKNOWN_PROPERTIES 外,还做了什么吗?
答:除了关闭 FAIL_ON_UNKNOWN_PROPERTIES 外,Jackson2ObjectMapperBuilder 类源码还主要做了以下两方面的事儿。
第一,设置 Jackson 的一些默认值,比如:
- MapperFeature.DEFAULT_VIEW_INCLUSION 设置为禁用;
- DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES 设置为禁用。
第二,自动注册 classpath 中存在的一些 jackson 模块,比如:
- jackson-datatype-jdk8,支持 JDK8 的一些类型,比如 Optional;
- jackson-datatype-jsr310, 支持 JDK8 的日期时间一些类型。
- jackson-datatype-joda,支持 Joda-Time 类型。
- jackson-module-kotlin,支持 Kotlin。
问题 9:Date 是一个时间戳,是 UTC 时间、没有时区概念。那为什么调用其 toString 方法,会输出类似 CST 之类的时区字样呢?
答:关于这个问题,参考 toString 中的相关源码,你可以看到会获取当前时区(取不到则显示 GMT)进行格式化:
public String toString() { BaseCalendar.Date date = normalize(); ... TimeZone zi = date.getZone(); if (zi != null) { sb.append(zi.getDisplayName(date.isDaylightTime(), TimeZone.SHORT, Locale.US)); // zzz } else { sb.append("GMT"); } sb.append(' ').append(date.getYear()); // yyyy return sb.toString(); } private final BaseCalendar.Date normalize() { if (cdate == null) { BaseCalendar cal = getCalendarSystem(fastTime); cdate = (BaseCalendar.Date) cal.getCalendarDate(fastTime, TimeZone.getDefaultRef()); return cdate; } // Normalize cdate with the TimeZone in cdate first. This is // required for the compatible behavior. if (!cdate.isNormalized()) { cdate = normalize(cdate); } // If the default TimeZone has changed, then recalculate the // fields with the new TimeZone. TimeZone tz = TimeZone.getDefaultRef(); if (tz != cdate.getZone()) { cdate.setZone(tz); CalendarSystem cal = getCalendarSystem(cdate); cal.getCalendarDate(fastTime, cdate); } return cdate; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35其实说白了,这里显示的时区仅仅用于呈现,并不代表 Date 类内置了时区信息。
问题 10:日期时间数据始终要保存到数据库中,MySQL 中有两种数据类型 datetime 和 timestamp 可以用来保存日期时间。你能说说它们的区别吗,它们是否包含时区信息呢?
答:datetime 和 timestamp 的区别,主要体现在占用空间、表示的时间范围和时区三个方面。
- 占用空间:datetime 占用 8 字节;timestamp 占用 4 字节。
- 表示的时间范围:datetime 表示的范围是从“1000-01-01 00:00:00.000000”到“9999-12-31 23:59:59.999999”;timestamp 表示的范围是从“1970-01-01 00:00:01.000000”到“2038-01-19 03:14:07.999999”。
- 时区:timestamp 保存的时候根据当前时区转换为 UTC,查询的时候再根据当前时区从 UTC 转回来;而 datetime 就是一个死的字符串时间(仅仅对 MySQL 本身而言)表示。
需要注意的是,我们说 datetime 不包含时区是固定的时间表示,仅仅是指 MySQL 本身。使用 timestamp,需要考虑 Java 进程的时区和 MySQL 连接的时区。而使用 datetime 类型,则只需要考虑 Java 进程的时区(因为 MySQL datetime 没有时区信息了,JDBC 时间戳转换成 MySQL datetime,会根据 MySQL 的 serverTimezone 做一次转换)。
如果你的项目有国际化需求,推荐使用时间戳,并且要确保你的应用服务器和数据库服务器设置了正确的匹配当地时区的时区配置。
其实,即便你的项目没有国际化需求,至少是应用服务器和数据库服务器设置一致的时区,也是需要的。
# 参考
- 来源:极客时间《Java 业务开发常见错误 100例》