 Java 业务开发常见错误(五)
Java 业务开发常见错误(五)
# Java 业务开发常见错误(五)
# 消除代码重复
业务同学抱怨业务开发没有技术含量,用不到设计模式、Java 高级特性、OOP,平时写代码都在堆 CRUD,个人成长无从谈起。每次面试官问到“请说说平时常用的设计模式”,都只能答单例模式,因为其他设计模式的确是听过但没用过;对于反射、注解之类的高级特性,也只是知道它们在写框架的时候非常常用,但自己又不写框架代码,没有用武之地。
其实,设计模式、OOP 是前辈们在大型项目中积累下来的经验,通过这些方法论来改善大型项目的可维护性。反射、注解、泛型等高级特性在框架中大量使用的原因是,框架往往需要以同一套算法来应对不同的数据结构,而这些特性可以帮助减少重复代码,提升项目可维护性。
可维护性是大型项目成熟度的一个重要指标,而提升可维护性非常重要的一个手段就是减少代码重复。那为什么这样说呢?
- 如果多处重复代码实现完全相同的功能,很容易修改一处忘记修改另一处,造成 Bug;
- 有一些代码并不是完全重复,而是相似度很高,修改这些类似的代码容易改(复制粘贴)错,把原本有区别的地方改为了一样。
# 利用工厂模式 + 模板方法模式,消除 if…else 和重复代码
假设要开发一个购物车下单的功能,针对不同用户进行不同处理:
- 普通用户需要收取运费,运费是商品价格的 10%,无商品折扣;
- VIP 用户同样需要收取商品价格 10% 的快递费,但购买两件以上相同商品时,第三件开始享受一定折扣;
- 内部用户可以免运费,无商品折扣。
我们的目标是实现三种类型的购物车业务逻辑,把入参 Map 对象(Key 是商品 ID,Value 是商品数量),转换为出参购物车类型 Cart。
先实现针对普通用户的购物车处理逻辑:
//购物车
@Data
public class Cart {
//商品清单
private List<Item> items = new ArrayList<>();
//总优惠
private BigDecimal totalDiscount;
//商品总价
private BigDecimal totalItemPrice;
//总运费
private BigDecimal totalDeliveryPrice;
//应付总价
private BigDecimal payPrice;
}
//购物车中的商品
@Data
public class Item {
//商品ID
private long id;
//商品数量
private int quantity;
//商品单价
private BigDecimal price;
//商品优惠
private BigDecimal couponPrice;
//商品运费
private BigDecimal deliveryPrice;
}
//普通用户购物车处理
public class NormalUserCart {
public Cart process(long userId, Map<Long, Integer> items) {
Cart cart = new Cart();
//把Map的购物车转换为Item列表
List<Item> itemList = new ArrayList<>();
items.entrySet().stream().forEach(entry -> {
Item item = new Item();
item.setId(entry.getKey());
item.setPrice(Db.getItemPrice(entry.getKey()));
item.setQuantity(entry.getValue());
itemList.add(item);
});
cart.setItems(itemList);
//处理运费和商品优惠
itemList.stream().forEach(item -> {
//运费为商品总价的10%
item.setDeliveryPrice(item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity())).multiply(new BigDecimal("0.1")));
//无优惠
item.setCouponPrice(BigDecimal.ZERO);
});
//计算商品总价
cart.setTotalItemPrice(cart.getItems().stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity()))).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算运费总价
cart.setTotalDeliveryPrice(cart.getItems().stream().map(Item::getDeliveryPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算总优惠
cart.setTotalDiscount(cart.getItems().stream().map(Item::getCouponPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//应付总价=商品总价+运费总价-总优惠
cart.setPayPrice(cart.getTotalItemPrice().add(cart.getTotalDeliveryPrice()).subtract(cart.getTotalDiscount()));
return cart;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
然后实现针对 VIP 用户的购物车逻辑。与普通用户购物车逻辑的不同在于,VIP 用户能享受同类商品多买的折扣。所以,这部分代码只需要额外处理多买折扣部分:
public class VipUserCart {
public Cart process(long userId, Map<Long, Integer> items) {
...
itemList.stream().forEach(item -> {
//运费为商品总价的10%
item.setDeliveryPrice(item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity())).multiply(new BigDecimal("0.1")));
//购买两件以上相同商品,第三件开始享受一定折扣
if (item.getQuantity() > 2) {
item.setCouponPrice(item.getPrice()
.multiply(BigDecimal.valueOf(100 - Db.getUserCouponPercent(userId)).divide(new BigDecimal("100")))
.multiply(BigDecimal.valueOf(item.getQuantity() - 2)));
} else {
item.setCouponPrice(BigDecimal.ZERO);
}
});
...
return cart;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
最后是免运费、无折扣的内部用户,同样只是处理商品折扣和运费时的逻辑差异:
public class InternalUserCart {
public Cart process(long userId, Map<Long, Integer> items) {
...
itemList.stream().forEach(item -> {
//免运费
item.setDeliveryPrice(BigDecimal.ZERO);
//无优惠
item.setCouponPrice(BigDecimal.ZERO);
});
...
return cart;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
对比一下代码量可以发现,三种购物车 70% 的代码是重复的。原因很简单,虽然不同类型用户计算运费和优惠的方式不同,但整个购物车的初始化、统计总价、总运费、总优惠和支付价格的逻辑都是一样的。
正如我们开始时提到的,代码重复本身不可怕,可怕的是漏改或改错。比如,写 VIP 用户购物车的同学发现商品总价计算有 Bug,不应该是把所有 Item 的 price 加在一起,而是应该把所有 Item 的 price*quantity 加在一起。这时,他可能会只修改 VIP 用户购物车的代码,而忽略了普通用户、内部用户的购物车中,重复的逻辑实现也有相同的 Bug。
有了三个购物车后,我们就需要根据不同的用户类型使用不同的购物车了。如下代码所示,使用三个 if 实现不同类型用户调用不同购物车的 process 方法:
@GetMapping("wrong")
public Cart wrong(@RequestParam("userId") int userId) {
//根据用户ID获得用户类型
String userCategory = Db.getUserCategory(userId);
//普通用户处理逻辑
if (userCategory.equals("Normal")) {
NormalUserCart normalUserCart = new NormalUserCart();
return normalUserCart.process(userId, items);
}
//VIP用户处理逻辑
if (userCategory.equals("Vip")) {
VipUserCart vipUserCart = new VipUserCart();
return vipUserCart.process(userId, items);
}
//内部用户处理逻辑
if (userCategory.equals("Internal")) {
InternalUserCart internalUserCart = new InternalUserCart();
return internalUserCart.process(userId, items);
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
电商的营销玩法是多样的,以后势必还会有更多用户类型,需要更多的购物车。我们就只能不断增加更多的购物车类,一遍一遍地写重复的购物车逻辑、写更多的 if 逻辑吗?
当然不是,相同的代码应该只在一处出现!
如果我们熟记抽象类和抽象方法的定义的话,这时或许就会想到,是否可以把重复的逻辑定义在抽象类中,三个购物车只要分别实现不同的那份逻辑呢?
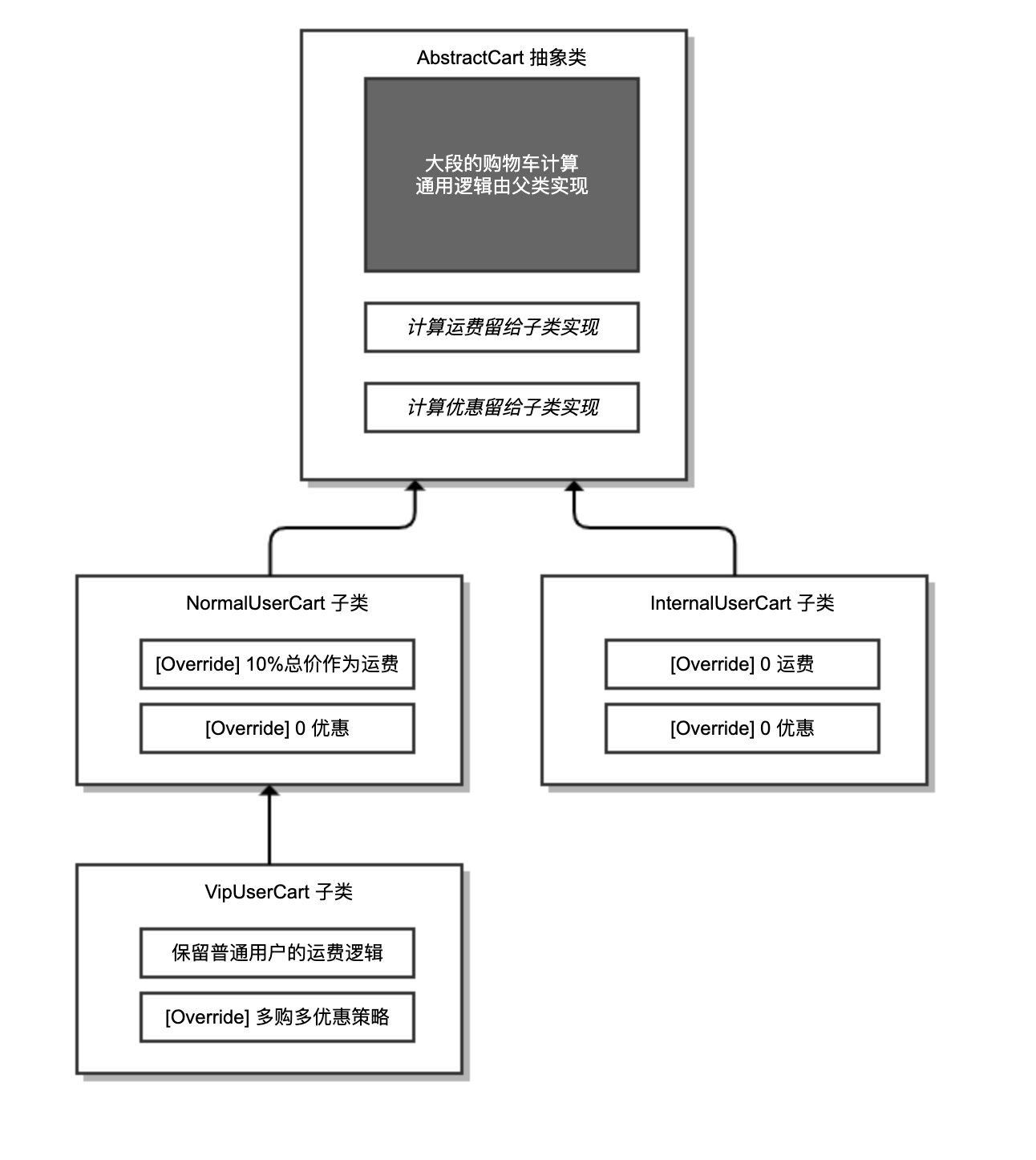
其实,这个模式就是模板方法模式。我们在父类中实现了购物车处理的流程模板,然后把需要特殊处理的地方留空白也就是留抽象方法定义,让子类去实现其中的逻辑。由于父类的逻辑不完整无法单独工作,因此需要定义为抽象类。
如下代码所示,AbstractCart 抽象类实现了购物车通用的逻辑,额外定义了两个抽象方法让子类去实现。其中,processCouponPrice 方法用于计算商品折扣,processDeliveryPrice 方法用于计算运费。
public abstract class AbstractCart {
//处理购物车的大量重复逻辑在父类实现
public Cart process(long userId, Map<Long, Integer> items) {
Cart cart = new Cart();
List<Item> itemList = new ArrayList<>();
items.entrySet().stream().forEach(entry -> {
Item item = new Item();
item.setId(entry.getKey());
item.setPrice(Db.getItemPrice(entry.getKey()));
item.setQuantity(entry.getValue());
itemList.add(item);
});
cart.setItems(itemList);
//让子类处理每一个商品的优惠
itemList.stream().forEach(item -> {
processCouponPrice(userId, item);
processDeliveryPrice(userId, item);
});
//计算商品总价
cart.setTotalItemPrice(cart.getItems().stream().map(item -> item.getPrice().multiply(BigDecimal.valueOf(item.getQuantity()))).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算总运费
cart.setTotalDeliveryPrice(cart.getItems().stream().map(Item::getDeliveryPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算总折扣
cart.setTotalDiscount(cart.getItems().stream().map(Item::getCouponPrice).reduce(BigDecimal.ZERO, BigDecimal::add));
//计算应付价格
cart.setPayPrice(cart.getTotalItemPrice().add(cart.getTotalDeliveryPrice()).subtract(cart.getTotalDiscount()));
return cart;
}
//处理商品优惠的逻辑留给子类实现
protected abstract void processCouponPrice(long userId, Item item);
//处理配送费的逻辑留给子类实现
protected abstract void processDeliveryPrice(long userId, Item item);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
有了这个抽象类,三个子类的实现就非常简单了。普通用户的购物车 NormalUserCart,实现的是 0 优惠和 10% 运费的逻辑:
@Service(value = "NormalUserCart")
public class NormalUserCart extends AbstractCart {
@Override
protected void processCouponPrice(long userId, Item item) {
item.setCouponPrice(BigDecimal.ZERO);
}
@Override
protected void processDeliveryPrice(long userId, Item item) {
item.setDeliveryPrice(item.getPrice()
.multiply(BigDecimal.valueOf(item.getQuantity()))
.multiply(new BigDecimal("0.1")));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
VIP 用户的购物车 VipUserCart,直接继承了 NormalUserCart,只需要修改多买优惠策略:
@Service(value = "VipUserCart")
public class VipUserCart extends NormalUserCart {
@Override
protected void processCouponPrice(long userId, Item item) {
if (item.getQuantity() > 2) {
item.setCouponPrice(item.getPrice()
.multiply(BigDecimal.valueOf(100 - Db.getUserCouponPercent(userId)).divide(new BigDecimal("100")))
.multiply(BigDecimal.valueOf(item.getQuantity() - 2)));
} else {
item.setCouponPrice(BigDecimal.ZERO);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
内部用户购物车 InternalUserCart 是最简单的,直接设置 0 运费和 0 折扣即可:
@Service(value = "InternalUserCart")
public class InternalUserCart extends AbstractCart {
@Override
protected void processCouponPrice(long userId, Item item) {
item.setCouponPrice(BigDecimal.ZERO);
}
@Override
protected void processDeliveryPrice(long userId, Item item) {
item.setDeliveryPrice(BigDecimal.ZERO);
}
}
2
3
4
5
6
7
8
9
10
11
12
抽象类和三个子类的实现关系图,如下所示:
是不是比三个独立的购物车程序简单了很多呢?接下来,我们再看看如何能避免三个 if 逻辑。
或许你已经注意到了,定义三个购物车子类时,我们在 @Service 注解中对 Bean 进行了命名。既然三个购物车都叫 XXXUserCart,那我们就可以把用户类型字符串拼接 UserCart 构成购物车 Bean 的名称,然后利用 Spring 的 IoC 容器,通过 Bean 的名称直接获取到 AbstractCart,调用其 process 方法即可实现通用。
其实,这就是工厂模式,只不过是借助 Spring 容器实现罢了:
@GetMapping("right")
public Cart right(@RequestParam("userId") int userId) {
String userCategory = Db.getUserCategory(userId);
AbstractCart cart = (AbstractCart) applicationContext.getBean(userCategory + "UserCart");
return cart.process(userId, items);
}
2
3
4
5
6
试想, 之后如果有了新的用户类型、新的用户逻辑,是不是完全不用对代码做任何修改,只要新增一个 XXXUserCart 类继承 AbstractCart,实现特殊的优惠和运费处理逻辑就可以了?
这样一来,我们就利用工厂模式 + 模板方法模式,不仅消除了重复代码,还避免了修改既有代码的风险。这就是设计模式中的开闭原则:对修改关闭,对扩展开放。
# 利用注解 + 反射消除重复代码
再看一个三方接口的调用案例,同样也是一个普通的业务逻辑。
假设银行提供了一些 API 接口,对参数的序列化有点特殊,不使用 JSON,而是需要我们把参数依次拼在一起构成一个大字符串。
- 按照银行提供的 API 文档的顺序,把所有参数构成定长的数据,然后拼接在一起作为整个字符串。
- 因为每一种参数都有固定长度,未达到长度时需要做填充处理:
- 字符串类型的参数不满长度部分需要以下划线右填充,也就是字符串内容靠左;
- 数字类型的参数不满长度部分以 0 左填充,也就是实际数字靠右;
- 货币类型的表示需要把金额向下舍入 2 位到分,以分为单位,作为数字类型同样进行左填充。
- 对所有参数做 MD5 操作作为签名(为了方便理解,Demo 中不涉及加盐处理)。
比如,创建用户方法和支付方法的定义是这样的:


代码很容易实现,直接根据接口定义实现填充操作、加签名、请求调用操作即可:
public class BankService {
//创建用户方法
public static String createUser(String name, String identity, String mobile, int age) throws IOException {
StringBuilder stringBuilder = new StringBuilder();
//字符串靠左,多余的地方填充_
stringBuilder.append(String.format("%-10s", name).replace(' ', '_'));
//字符串靠左,多余的地方填充_
stringBuilder.append(String.format("%-18s", identity).replace(' ', '_'));
//数字靠右,多余的地方用0填充
stringBuilder.append(String.format("%05d", age));
//字符串靠左,多余的地方用_填充
stringBuilder.append(String.format("%-11s", mobile).replace(' ', '_'));
//最后加上MD5作为签名
stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
return Request.Post("http://localhost:45678/reflection/bank/createUser")
.bodyString(stringBuilder.toString(), ContentType.APPLICATION_JSON)
.execute().returnContent().asString();
}
//支付方法
public static String pay(long userId, BigDecimal amount) throws IOException {
StringBuilder stringBuilder = new StringBuilder();
//数字靠右,多余的地方用0填充
stringBuilder.append(String.format("%020d", userId));
//金额向下舍入2位到分,以分为单位,作为数字靠右,多余的地方用0填充
stringBuilder.append(String.format("%010d", amount.setScale(2, RoundingMode.DOWN).multiply(new BigDecimal("100")).longValue()));
//最后加上MD5作为签名
stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
return Request.Post("http://localhost:45678/reflection/bank/pay")
.bodyString(stringBuilder.toString(), ContentType.APPLICATION_JSON)
.execute().returnContent().asString();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
可以看到,这段代码的重复粒度更细:
- 三种标准数据类型的处理逻辑有重复,稍有不慎就会出现 Bug;
- 处理流程中字符串拼接、加签和发请求的逻辑,在所有方法重复;
- 实际方法的入参的参数类型和顺序,不一定和接口要求一致,容易出错;
- 代码层面针对每一个参数硬编码,无法清晰地进行核对,如果参数达到几十个、上百个,出错的概率极大。
那应该如何改造这段代码呢?没错,就是要用注解和反射!
使用注解和反射这两个武器,就可以针对银行请求的所有逻辑均使用一套代码实现,不会出现任何重复。
要实现接口逻辑和逻辑实现的剥离,首先需要以 POJO 类(只有属性没有任何业务逻辑的数据类)的方式定义所有的接口参数。比如,下面这个创建用户 API 的参数:
@Data
public class CreateUserAPI {
private String name;
private String identity;
private String mobile;
private int age;
}
2
3
4
5
6
7
有了接口参数定义,我们就能通过自定义注解为接口和所有参数增加一些元数据。如下所示,我们定义一个接口 API 的注解 BankAPI,包含接口 URL 地址和接口说明:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Inherited
public @interface BankAPI {
String desc() default "";
String url() default "";
}
2
3
4
5
6
7
8
然后,我们再定义一个自定义注解 @BankAPIField,用于描述接口的每一个字段规范,包含参数的次序、类型和长度三个属性:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Documented
@Inherited
public @interface BankAPIField {
int order() default -1;
int length() default -1;
String type() default "";
}
2
3
4
5
6
7
8
9
接下来,注解就可以发挥威力了。
如下所示,我们定义了 CreateUserAPI 类描述创建用户接口的信息,通过为接口增加 @BankAPI 注解,来补充接口的 URL 和描述等元数据;通过为每一个字段增加 @BankAPIField 注解,来补充参数的顺序、类型和长度等元数据:
@BankAPI(url = "/bank/createUser", desc = "创建用户接口")
@Data
public class CreateUserAPI extends AbstractAPI {
@BankAPIField(order = 1, type = "S", length = 10)
private String name;
@BankAPIField(order = 2, type = "S", length = 18)
private String identity;
@BankAPIField(order = 4, type = "S", length = 11) //注意这里的order需要按照API表格中的顺序
private String mobile;
@BankAPIField(order = 3, type = "N", length = 5)
private int age;
}
2
3
4
5
6
7
8
9
10
11
12
另一个 PayAPI 类也是类似的实现:
@BankAPI(url = "/bank/pay", desc = "支付接口")
@Data
public class PayAPI extends AbstractAPI {
@BankAPIField(order = 1, type = "N", length = 20)
private long userId;
@BankAPIField(order = 2, type = "M", length = 10)
private BigDecimal amount;
}
2
3
4
5
6
7
8
这 2 个类继承的 AbstractAPI 类是一个空实现,因为这个案例中的接口并没有公共数据可以抽象放到基类。
通过这 2 个类,我们可以在几秒钟内完成和 API 清单表格的核对。理论上,如果我们的核心翻译过程(也就是把注解和接口 API 序列化为请求需要的字符串的过程)没问题,只要注解和表格一致,API 请求的翻译就不会有任何问题。
以上,我们通过注解实现了对 API 参数的描述。接下来,我们再看看反射如何配合注解实现动态的接口参数组装:
- 第 3 行代码中,我们从类上获得了 BankAPI 注解,然后拿到其 URL 属性,后续进行远程调用。
- 第 6~9 行代码,使用 stream 快速实现了获取类中所有带 BankAPIField 注解的字段,并把字段按 order 属性排序,然后设置私有字段反射可访问。
- 第 12~38 行代码,实现了反射获取注解的值,然后根据 BankAPIField 拿到的参数类型,按照三种标准进行格式化,将所有参数的格式化逻辑集中在了这一处。
- 第 41~48 行代码,实现了参数加签和请求调用。
private static String remoteCall(AbstractAPI api) throws IOException {
//从BankAPI注解获取请求地址
BankAPI bankAPI = api.getClass().getAnnotation(BankAPI.class);
bankAPI.url();
StringBuilder stringBuilder = new StringBuilder();
Arrays.stream(api.getClass().getDeclaredFields()) //获得所有字段
.filter(field -> field.isAnnotationPresent(BankAPIField.class)) //查找标记了注解的字段
.sorted(Comparator.comparingInt(a -> a.getAnnotation(BankAPIField.class).order())) //根据注解中的order对字段排序
.peek(field -> field.setAccessible(true)) //设置可以访问私有字段
.forEach(field -> {
//获得注解
BankAPIField bankAPIField = field.getAnnotation(BankAPIField.class);
Object value = "";
try {
//反射获取字段值
value = field.get(api);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
//根据字段类型以正确的填充方式格式化字符串
switch (bankAPIField.type()) {
case "S": {
stringBuilder.append(String.format("%-" + bankAPIField.length() + "s", value.toString()).replace(' ', '_'));
break;
}
case "N": {
stringBuilder.append(String.format("%" + bankAPIField.length() + "s", value.toString()).replace(' ', '0'));
break;
}
case "M": {
if (!(value instanceof BigDecimal))
throw new RuntimeException(String.format("{} 的 {} 必须是BigDecimal", api, field));
stringBuilder.append(String.format("%0" + bankAPIField.length() + "d", ((BigDecimal) value).setScale(2, RoundingMode.DOWN).multiply(new BigDecimal("100")).longValue()));
break;
}
default:
break;
}
});
//签名逻辑
stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
String param = stringBuilder.toString();
long begin = System.currentTimeMillis();
//发请求
String result = Request.Post("http://localhost:45678/reflection" + bankAPI.url())
.bodyString(param, ContentType.APPLICATION_JSON)
.execute().returnContent().asString();
log.info("调用银行API {} url:{} 参数:{} 耗时:{}ms", bankAPI.desc(), bankAPI.url(), param, System.currentTimeMillis() - begin);
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
可以看到,所有处理参数排序、填充、加签、请求调用的核心逻辑,都汇聚在了 remoteCall 方法中。有了这个核心方法,BankService 中每一个接口的实现就非常简单了,只是参数的组装,然后调用 remoteCall 即可。
//创建用户方法
public static String createUser(String name, String identity, String mobile, int age) throws IOException {
CreateUserAPI createUserAPI = new CreateUserAPI();
createUserAPI.setName(name);
createUserAPI.setIdentity(identity);
createUserAPI.setAge(age);
createUserAPI.setMobile(mobile);
return remoteCall(createUserAPI);
}
//支付方法
public static String pay(long userId, BigDecimal amount) throws IOException {
PayAPI payAPI = new PayAPI();
payAPI.setUserId(userId);
payAPI.setAmount(amount);
return remoteCall(payAPI);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
其实,许多涉及类结构性的通用处理,都可以按照这个模式来减少重复代码。反射给予了我们在不知晓类结构的时候,按照固定的逻辑处理类的成员;而注解给了我们为这些成员补充元数据的能力,使得我们利用反射实现通用逻辑的时候,可以从外部获得更多我们关心的数据。
# 利用属性拷贝工具消除重复代码
再来看一种业务代码中经常出现的代码逻辑,实体之间的转换复制。
对于三层架构的系统,考虑到层之间的解耦隔离以及每一层对数据的不同需求,通常每一层都会有自己的 POJO 作为数据实体。比如,数据访问层的实体一般叫作 DataObject 或 DO,业务逻辑层的实体一般叫作 Domain,表现层的实体一般叫作 Data Transfer Object 或 DTO。
这里我们需要注意的是,如果手动写这些实体之间的赋值代码,同样容易出错。
对于复杂的业务系统,实体有几十甚至几百个属性也很正常。就比如 ComplicatedOrderDTO 这个数据传输对象,描述的是一个订单中的几十个属性。如果我们要把这个 DTO 转换为一个类似的 DO,复制其中大部分的字段,然后把数据入库,势必需要进行很多属性映射赋值操作。就像这样,密密麻麻的代码是不是已经让你头晕了?
ComplicatedOrderDTO orderDTO = new ComplicatedOrderDTO();
ComplicatedOrderDO orderDO = new ComplicatedOrderDO();
orderDO.setAcceptDate(orderDTO.getAcceptDate());
orderDO.setAddress(orderDTO.getAddress());
orderDO.setAddressId(orderDTO.getAddressId());
orderDO.setCancelable(orderDTO.isCancelable());
orderDO.setCommentable(orderDTO.isComplainable()); //属性错误
orderDO.setComplainable(orderDTO.isCommentable()); //属性错误
orderDO.setCancelable(orderDTO.isCancelable());
orderDO.setCouponAmount(orderDTO.getCouponAmount());
orderDO.setCouponId(orderDTO.getCouponId());
orderDO.setCreateDate(orderDTO.getCreateDate());
orderDO.setDirectCancelable(orderDTO.isDirectCancelable());
orderDO.setDeliverDate(orderDTO.getDeliverDate());
orderDO.setDeliverGroup(orderDTO.getDeliverGroup());
orderDO.setDeliverGroupOrderStatus(orderDTO.getDeliverGroupOrderStatus());
orderDO.setDeliverMethod(orderDTO.getDeliverMethod());
orderDO.setDeliverPrice(orderDTO.getDeliverPrice());
orderDO.setDeliveryManId(orderDTO.getDeliveryManId());
orderDO.setDeliveryManMobile(orderDO.getDeliveryManMobile()); //对象错误
orderDO.setDeliveryManName(orderDTO.getDeliveryManName());
orderDO.setDistance(orderDTO.getDistance());
orderDO.setExpectDate(orderDTO.getExpectDate());
orderDO.setFirstDeal(orderDTO.isFirstDeal());
orderDO.setHasPaid(orderDTO.isHasPaid());
orderDO.setHeadPic(orderDTO.getHeadPic());
orderDO.setLongitude(orderDTO.getLongitude());
orderDO.setLatitude(orderDTO.getLongitude()); //属性赋值错误
orderDO.setMerchantAddress(orderDTO.getMerchantAddress());
orderDO.setMerchantHeadPic(orderDTO.getMerchantHeadPic());
orderDO.setMerchantId(orderDTO.getMerchantId());
orderDO.setMerchantAddress(orderDTO.getMerchantAddress());
orderDO.setMerchantName(orderDTO.getMerchantName());
orderDO.setMerchantPhone(orderDTO.getMerchantPhone());
orderDO.setOrderNo(orderDTO.getOrderNo());
orderDO.setOutDate(orderDTO.getOutDate());
orderDO.setPayable(orderDTO.isPayable());
orderDO.setPaymentAmount(orderDTO.getPaymentAmount());
orderDO.setPaymentDate(orderDTO.getPaymentDate());
orderDO.setPaymentMethod(orderDTO.getPaymentMethod());
orderDO.setPaymentTimeLimit(orderDTO.getPaymentTimeLimit());
orderDO.setPhone(orderDTO.getPhone());
orderDO.setRefundable(orderDTO.isRefundable());
orderDO.setRemark(orderDTO.getRemark());
orderDO.setStatus(orderDTO.getStatus());
orderDO.setTotalQuantity(orderDTO.getTotalQuantity());
orderDO.setUpdateTime(orderDTO.getUpdateTime());
orderDO.setName(orderDTO.getName());
orderDO.setUid(orderDTO.getUid());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
如果不是代码中有注释,你能看出其中的诸多问题吗?
- 如果原始的 DTO 有 100 个字段,我们需要复制 90 个字段到 DO 中,保留 10 个不赋值,最后应该如何校验正确性呢?数数吗?即使数出有 90 行代码,也不一定正确,因为属性可能重复赋值。
- 有的时候字段命名相近,比如 complainable 和 commentable,容易搞反(第 7 和第 8 行),或者对两个目标字段重复赋值相同的来源字段(比如第 28 行)
- 明明要把 DTO 的值赋值到 DO 中,却在 set 的时候从 DO 自己取值(比如第 20 行),导致赋值无效。
这段代码是一个真实案例。有位同学就像代码中那样把经纬度赋值反了,因为落库的字段实在太多了。这个 Bug 很久都没发现,直到真正用到数据库中的经纬度做计算时,才发现一直以来都存错了。
修改方法很简单,可以使用类似 BeanUtils 这种 Mapping 工具来做 Bean 的转换,copyProperties 方法还允许我们提供需要忽略的属性:
ComplicatedOrderDTO orderDTO = new ComplicatedOrderDTO();
ComplicatedOrderDO orderDO = new ComplicatedOrderDO();
BeanUtils.copyProperties(orderDTO, orderDO, "id");
return orderDO;
2
3
4
# 接口设计:一定要统一
在做接口设计时一定要确保系统之间对话的语言是统一的。
我们知道,开发一个服务的第一步就是设计接口。接口的设计需要考虑的点非常多,比如接口的命名、参数列表、包装结构体、接口粒度、版本策略、幂等性实现、同步异步处理方式等。
这其中,和接口设计相关比较重要的点有三个,分别是包装结构体、版本策略、同步异步处理方式。
# 接口的响应要明确表示处理结果
曾遇到过一个处理收单的收单中心项目,下单接口返回的响应体中,包含了 success、code、info、message 等属性,以及二级嵌套对象 data 结构体。在对项目进行重构的时候,我们发现真的是无从入手,接口缺少文档,代码一有改动就出错。
有时候,下单操作的响应结果是这样的:success 是 true、message 是 OK,貌似代表下单成功了;但 info 里却提示订单存在风险,code 是一个 5001 的错误码,data 中能看到订单状态是 Cancelled,订单 ID 是 -1,好像又说明没有下单成功。
{
"success": true,
"code": 5001,
"info": "Risk order detected",
"message": "OK",
"data": {
"orderStatus": "Cancelled",
"orderId": -1
}
}
2
3
4
5
6
7
8
9
10
有些时候,这个下单接口又会返回这样的结果:success 是 false,message 提示非法用户 ID,看上去下单失败;但 data 里的 orderStatus 是 Created、info 是空、code 是 0。那么,这次下单到底是成功还是失败呢?
这样的结果,让我们非常疑惑:
- 结构体的 code 和 HTTP 响应状态码,是什么关系?
- success 到底代表下单成功还是失败?
- info 和 message 的区别是什么?
- data 中永远都有数据吗?
- 什么时候应该去查询 data?
造成如此混乱的原因是:这个收单服务本身并不真正处理下单操作,只是做一些预校验和预处理;真正的下单操作,需要在收单服务内部调用另一个订单服务来处理;订单服务处理完成后,会返回订单状态和 ID。
在一切正常的情况下,下单后的订单状态就是已创建 Created,订单 ID 是一个大于 0 的数字。而结构体中的 message 和 success,其实是收单服务的处理异常信息和处理成功与否的结果,code、info 是调用订单服务的结果。
对于第一次调用,收单服务自己没问题,success 是 true,message 是 OK,但调用订单服务时却因为订单风险问题被拒绝,所以 code 是 5001,info 是 Risk order detected,data 中的信息是订单服务返回的,所以最终订单状态是 Cancelled。
对于第二次调用,因为用户 ID 非法,所以收单服务在校验了参数后直接就返回了 success 是 false,message 是 Illegal userId。因为请求没有到订单服务,所以 info、code、data 都是默认值,订单状态的默认值是 Created。因此,第二次下单肯定失败了,但订单状态却是已创建。
可以看到,如此混乱的接口定义和实现方式,是无法让调用者分清到底应该怎么处理的。为了将接口设计得更合理,我们需要考虑如下两个原则:
- 对外隐藏内部实现。虽然说收单服务调用订单服务进行真正的下单操作,但是直接接口其实是收单服务提供的,收单服务不应该“直接”暴露其背后订单服务的状态码、错误描述。
- 设计接口结构时,明确每个字段的含义,以及客户端的处理方式。
基于这两个原则,我们调整一下返回结构体,去掉外层的 info,即不再把订单服务的调用结果告知客户端:
@Data
public class APIResponse<T> {
private boolean success;
private T data;
private int code;
private String message;
}
2
3
4
5
6
7
并明确接口的设计逻辑:
- 如果出现非 200 的 HTTP 响应状态码,就代表请求没有到收单服务,可能是网络出问题、网络超时,或者网络配置的问题。这时,肯定无法拿到服务端的响应体,客户端可以给予友好提示,比如让用户重试,不需要继续解析响应结构体。
- 如果 HTTP 响应码是 200,解析响应体查看 success,为 false 代表下单请求处理失败,可能是因为收单服务参数验证错误,也可能是因为订单服务下单操作失败。这时,根据收单服务定义的错误码表和 code,做不同处理。比如友好提示,或是让用户重新填写相关信息,其中友好提示的文字内容可以从 message 中获取。
- success 为 true 的情况下,才需要继续解析响应体中的 data 结构体。data 结构体代表了业务数据,通常会有下面两种情况。
- 通常情况下,success 为 true 时订单状态是 Created,获取 orderId 属性可以拿到订单号。
- 特殊情况下,比如收单服务内部处理不当,或是订单服务出现了额外的状态,虽然 success 为 true,但订单实际状态不是 Created,这时可以给予友好的错误提示。
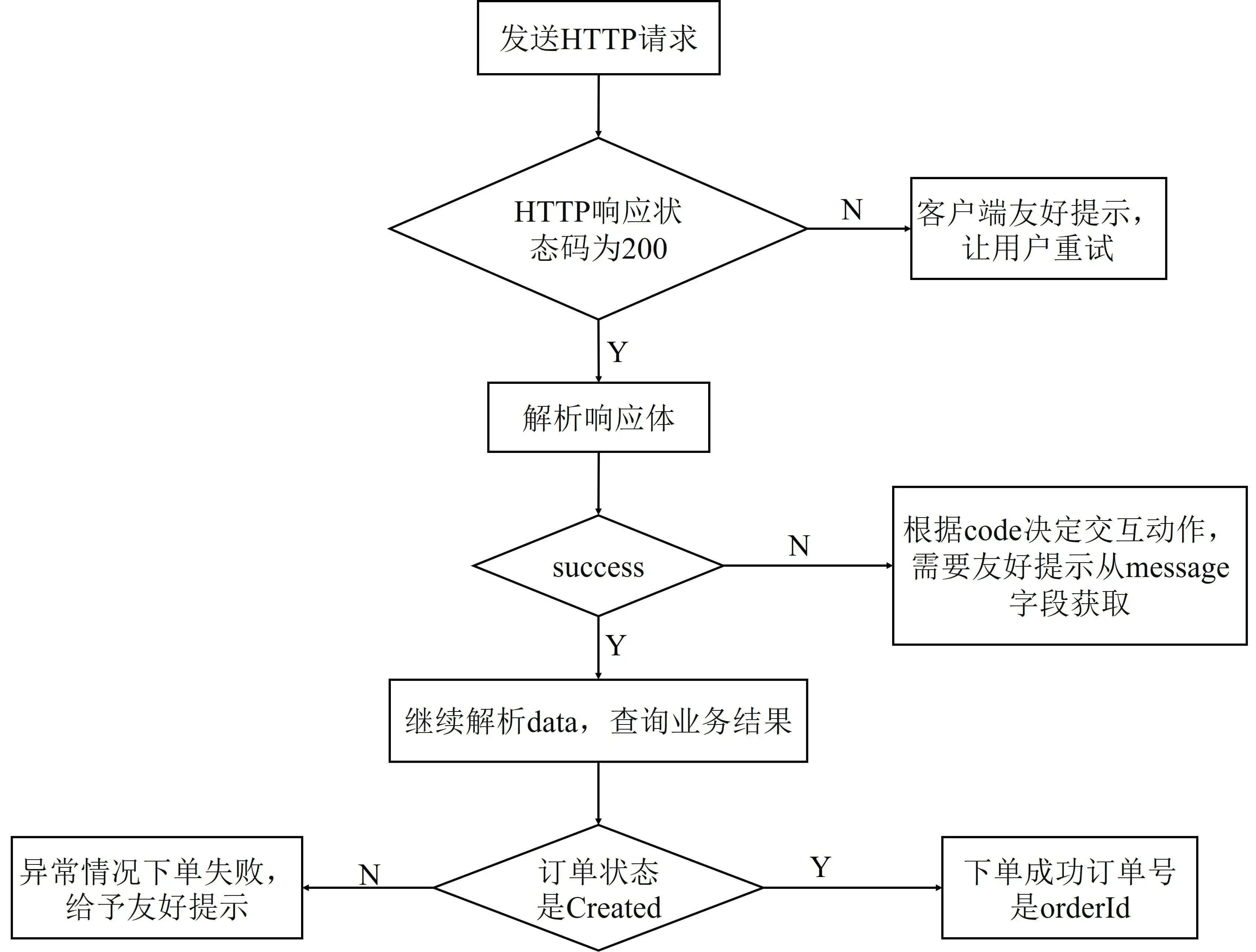
明确了接口的设计逻辑,我们就是可以实现收单服务的服务端和客户端来模拟这些情况了。
首先,实现服务端的逻辑:
@GetMapping("server")
public APIResponse<OrderInfo> server(@RequestParam("userId") Long userId) {
APIResponse<OrderInfo> response = new APIResponse<>();
if (userId == null) {
//对于userId为空的情况,收单服务直接处理失败,给予相应的错误码和错误提示
response.setSuccess(false);
response.setCode(3001);
response.setMessage("Illegal userId");
} else if (userId == 1) {
//对于userId=1的用户,模拟订单服务对于风险用户的情况
response.setSuccess(false);
//把订单服务返回的错误码转换为收单服务错误码
response.setCode(3002);
response.setMessage("Internal Error, order is cancelled");
//同时日志记录内部错误
log.warn("用户 {} 调用订单服务失败,原因是 Risk order detected", userId);
} else {
//其他用户,下单成功
response.setSuccess(true);
response.setCode(2000);
response.setMessage("OK");
response.setData(new OrderInfo("Created", 2L));
}
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
客户端代码,则可以按照流程图上的逻辑来实现,同样模拟三种出错情况和正常下单的情况:
error==1 的用例模拟一个不存在的 URL,请求无法到收单服务,会得到 404 的 HTTP 状态码,直接进行友好提示,这是第一层处理。

error==2 的用例模拟 userId 参数为空的情况,收单服务会因为缺少 userId 参数提示非法用户。这时,可以把响应体中的 message 展示给用户,这是第二层处理。

error==3 的用例模拟 userId 为 1 的情况,因为用户有风险,收单服务调用订单服务出错。处理方式和之前没有任何区别,因为收单服务会屏蔽订单服务的内部错误。

但在服务端可以看到如下错误信息:
[14:13:13.951] [http-nio-45678-exec-8] [WARN ] [.c.a.d.APIThreeLevelStatusController:36 ] - 用户 1 调用订单服务失败,原因是 Risk order detected1error==0 的用例模拟正常用户,下单成功。这时可以解析 data 结构体提取业务结果,作为兜底,需要判断订单状态,如果不是 Created 则给予友好提示,否则查询 orderId 获得下单的订单号,这是第三层处理。

客户端的实现代码如下:
@GetMapping("client")
public String client(@RequestParam(value = "error", defaultValue = "0") int error) {
String url = Arrays.asList("http://localhost:45678/apiresposne/server?userId=2",
"http://localhost:45678/apiresposne/server2",
"http://localhost:45678/apiresposne/server?userId=",
"http://localhost:45678/apiresposne/server?userId=1").get(error);
//第一层,先看状态码,如果状态码不是200,不处理响应体
String response = "";
try {
response = Request.Get(url).execute().returnContent().asString();
} catch (HttpResponseException e) {
log.warn("请求服务端出现返回非200", e);
return "服务器忙,请稍后再试!";
} catch (IOException e) {
e.printStackTrace();
}
//状态码为200的情况下处理响应体
if (!response.equals("")) {
try {
APIResponse<OrderInfo> apiResponse = objectMapper.readValue(response, new TypeReference<APIResponse<OrderInfo>>() {
});
//第二层,success是false直接提示用户
if (!apiResponse.isSuccess()) {
return String.format("创建订单失败,请稍后再试,错误代码: %s 错误原因:%s", apiResponse.getCode(), apiResponse.getMessage());
} else {
//第三层,往下解析OrderInfo
OrderInfo orderInfo = apiResponse.getData();
if ("Created".equals(orderInfo.getStatus()))
return String.format("创建订单成功,订单号是:%s,状态是:%s", orderInfo.getOrderId(), orderInfo.getStatus());
else
return String.format("创建订单失败,请联系客服处理");
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
return "";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
相比原来混乱的接口定义和处理逻辑,改造后的代码,明确了接口每一个字段的含义,以及对于各种情况服务端的输出和客户端的处理步骤,对齐了客户端和服务端的处理逻辑。那么现在,你能回答前面那 4 个让人疑惑的问题了吗?
最后分享一个小技巧。为了简化服务端代码,我们可以把包装 API 响应体 APIResponse 的工作交由框架自动完成,这样直接返回 DTO OrderInfo 即可。对于业务逻辑错误,可以抛出一个自定义异常:
@GetMapping("server")
public OrderInfo server(@RequestParam("userId") Long userId) {
if (userId == null) {
throw new APIException(3001, "Illegal userId");
}
if (userId == 1) {
...
//直接抛出异常
throw new APIException(3002, "Internal Error, order is cancelled");
}
//直接返回DTO
return new OrderInfo("Created", 2L);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 APIException 中包含错误码和错误消息:
public class APIException extends RuntimeException {
@Getter
private int errorCode;
@Getter
private String errorMessage;
public APIException(int errorCode, String errorMessage) {
super(errorMessage);
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
public APIException(Throwable cause, int errorCode, String errorMessage) {
super(errorMessage, cause);
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
然后,定义一个 @RestControllerAdvice 来完成自动包装响应体的工作:
- 通过实现 ResponseBodyAdvice 接口的 beforeBodyWrite 方法,来处理成功请求的响应体转换。
- 实现一个 @ExceptionHandler 来处理业务异常时,APIException 到 APIResponse 的转换。
//此段代码只是Demo,生产级应用还需要扩展很多细节
@RestControllerAdvice
@Slf4j
public class APIResponseAdvice implements ResponseBodyAdvice<Object> {
//自动处理APIException,包装为APIResponse
@ExceptionHandler(APIException.class)
public APIResponse handleApiException(HttpServletRequest request, APIException ex) {
log.error("process url {} failed", request.getRequestURL().toString(), ex);
APIResponse apiResponse = new APIResponse();
apiResponse.setSuccess(false);
apiResponse.setCode(ex.getErrorCode());
apiResponse.setMessage(ex.getErrorMessage());
return apiResponse;
}
//仅当方法或类没有标记@NoAPIResponse才自动包装
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return returnType.getParameterType() != APIResponse.class
&& AnnotationUtils.findAnnotation(returnType.getMethod(), NoAPIResponse.class) == null
&& AnnotationUtils.findAnnotation(returnType.getDeclaringClass(), NoAPIResponse.class) == null;
}
//自动包装外层APIResposne响应
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class<? extends HttpMessageConverter<?>> selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
APIResponse apiResponse = new APIResponse();
apiResponse.setSuccess(true);
apiResponse.setMessage("OK");
apiResponse.setCode(2000);
apiResponse.setData(body);
return apiResponse;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
在这里,我们实现了一个 @NoAPIResponse 自定义注解。如果某些 @RestController 的接口不希望实现自动包装的话,可以标记这个注解:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface NoAPIResponse {
}
2
3
4
在 ResponseBodyAdvice 的 support 方法中,我们排除了标记有这个注解的方法或类的自动响应体包装。比如,对于刚才我们实现的测试客户端 client 方法不需要包装为 APIResponse,就可以标记上这个注解:
@GetMapping("client")
@NoAPIResponse
public String client(@RequestParam(value = "error", defaultValue = "0") int error)
2
3
这样我们的业务逻辑中就不需要考虑响应体的包装,代码会更简洁。
延伸:
对于服务端出错的时候是否返回 200 响应码的问题,其实一直有争论。从 RESTful 设计原则来看,我们应该尽量利用 HTTP 状态码来表达错误,但也不是这么绝对。
如果我们认为 HTTP 状态码是协议层面的履约,那么当这个错误已经不涉及 HTTP 协议时(换句话说,服务端已经收到请求进入服务端业务处理后产生的错误),不一定需要硬套协议本身的错误码。但涉及非法 URL、非法参数、没有权限等无法处理请求的情况,还是应该使用正确的响应码来应对。
# 要考虑接口变迁的版本控制策略
接口不可能一成不变,需要根据业务需求不断增加内部逻辑。如果做大的功能调整或重构,涉及参数定义的变化或是参数废弃,导致接口无法向前兼容,这时接口就需要有版本的概念。在考虑接口版本策略设计时,我们需要注意的是,最好一开始就明确版本策略,并考虑在整个服务端统一版本策略。
第一,版本策略最好一开始就考虑。
既然接口总是要变迁的,那么最好一开始就确定版本策略。比如,确定是通过 URL Path 实现,是通过 QueryString 实现,还是通过 HTTP 头实现。这三种实现方式的代码如下:
//通过URL Path实现版本控制
@GetMapping("/v1/api/user")
public int right1(){
return 1;
}
//通过QueryString中的version参数实现版本控制
@GetMapping(value = "/api/user", params = "version=2")
public int right2(@RequestParam("version") int version) {
return 2;
}
//通过请求头中的X-API-VERSION参数实现版本控制
@GetMapping(value = "/api/user", headers = "X-API-VERSION=3")
public int right3(@RequestHeader("X-API-VERSION") int version) {
return 3;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这样,客户端就可以在配置中处理相关版本控制的参数,有可能实现版本的动态切换。
这三种方式中,URL Path 的方式最直观也最不容易出错;QueryString 不易携带,不太推荐作为公开 API 的版本策略;HTTP 头的方式比较没有侵入性,如果仅仅是部分接口需要进行版本控制,可以考虑这种方式。
第二,版本实现方式要统一。
案例:一个 O2O 项目,需要针对商品、商店和用户实现 REST 接口。虽然大家约定通过 URL Path 方式实现 API 版本控制,但实现方式不统一,有的是 /api/item/v1,有的是 /api/v1/shop,还有的是 /v1/api/merchant:
@GetMapping("/api/item/v1")
public void wrong1(){
}
@GetMapping("/api/v1/shop")
public void wrong2(){
}
@GetMapping("/v1/api/merchant")
public void wrong3(){
}
2
3
4
5
6
7
8
9
10
11
12
13
显然,商品、商店和商户的接口开发同学,没有按照一致的 URL 格式来实现接口的版本控制。更要命的是,我们可能开发出两个 URL 类似接口,比如一个是 /api/v1/user,另一个是 /api/user/v1,这到底是一个接口还是两个接口呢?
相比于在每一个接口的 URL Path 中设置版本号,更理想的方式是在框架层面实现统一。如果你使用 Spring 框架的话,可以按照下面的方式自定义 RequestMappingHandlerMapping 来实现。
首先,创建一个注解来定义接口的版本。@APIVersion 自定义注解可以应用于方法或 Controller 上:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface APIVersion {
String[] value();
}
2
3
4
5
然后,定义一个 APIVersionHandlerMapping 类继承 RequestMappingHandlerMapping。
RequestMappingHandlerMapping 的作用,是根据类或方法上的 @RequestMapping 来生成 RequestMappingInfo 的实例。我们覆盖 registerHandlerMethod 方法的实现,从 @APIVersion 自定义注解中读取版本信息,拼接上原有的、不带版本号的 URL Pattern,构成新的 RequestMappingInfo,来通过注解的方式为接口增加基于 URL 的版本号:
public class APIVersionHandlerMapping extends RequestMappingHandlerMapping {
@Override
protected boolean isHandler(Class<?> beanType) {
return AnnotatedElementUtils.hasAnnotation(beanType, Controller.class);
}
@Override
protected void registerHandlerMethod(Object handler, Method method, RequestMappingInfo mapping) {
Class<?> controllerClass = method.getDeclaringClass();
//类上的APIVersion注解
APIVersion apiVersion = AnnotationUtils.findAnnotation(controllerClass, APIVersion.class);
//方法上的APIVersion注解
APIVersion methodAnnotation = AnnotationUtils.findAnnotation(method, APIVersion.class);
//以方法上的注解优先
if (methodAnnotation != null) {
apiVersion = methodAnnotation;
}
String[] urlPatterns = apiVersion == null ? new String[0] : apiVersion.value();
PatternsRequestCondition apiPattern = new PatternsRequestCondition(urlPatterns);
PatternsRequestCondition oldPattern = mapping.getPatternsCondition();
PatternsRequestCondition updatedFinalPattern = apiPattern.combine(oldPattern);
//重新构建RequestMappingInfo
mapping = new RequestMappingInfo(mapping.getName(), updatedFinalPattern, mapping.getMethodsCondition(),
mapping.getParamsCondition(), mapping.getHeadersCondition(), mapping.getConsumesCondition(),
mapping.getProducesCondition(), mapping.getCustomCondition());
super.registerHandlerMethod(handler, method, mapping);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
最后,也是特别容易忽略的一点,要通过实现 WebMvcRegistrations 接口,来生效自定义的 APIVersionHandlerMapping:
@SpringBootApplication
public class CommonMistakesApplication implements WebMvcRegistrations {
...
@Override
public RequestMappingHandlerMapping getRequestMappingHandlerMapping() {
return new APIVersionHandlerMapping();
}
}
2
3
4
5
6
7
8
这样,就实现了在 Controller 上或接口方法上通过注解,来实现以统一的 Pattern 进行版本号控制:
@GetMapping(value = "/api/user")
@APIVersion("v4")
public int right4() {
return 4;
}
2
3
4
5
使用框架来明确 API 版本的指定策略,不仅实现了标准化,更实现了强制的 API 版本控制。对上面代码略做修改,我们就可以实现不设置 @APIVersion 接口就给予报错提示。
# 接口处理方式要明确同步或异步
案例:有一个文件上传服务 FileService,其中一个 upload 文件上传接口特别慢,原因是这个上传接口在内部需要进行两步操作,首先上传原图,然后压缩后上传缩略图。如果每一步都耗时 5 秒的话,那么这个接口返回至少需要 10 秒的时间。
于是,开发同学把接口改为了异步处理,每一步操作都限定了超时时间,也就是分别把上传原文件和上传缩略图的操作提交到线程池,然后等待一定的时间:
private ExecutorService threadPool = Executors.newFixedThreadPool(2);
//我没有贴出两个文件上传方法uploadFile和uploadThumbnailFile的实现,它们在内部只是随机进行休眠然后返回文件名,对于本例来说不是很重要
public UploadResponse upload(UploadRequest request) {
UploadResponse response = new UploadResponse();
//上传原始文件任务提交到线程池处理
Future<String> uploadFile = threadPool.submit(() -> uploadFile(request.getFile()));
//上传缩略图任务提交到线程池处理
Future<String> uploadThumbnailFile = threadPool.submit(() -> uploadThumbnailFile(request.getFile()));
//等待上传原始文件任务完成,最多等待1秒
try {
response.setDownloadUrl(uploadFile.get(1, TimeUnit.SECONDS));
} catch (Exception e) {
e.printStackTrace();
}
//等待上传缩略图任务完成,最多等待1秒
try {
response.setThumbnailDownloadUrl(uploadThumbnailFile.get(1, TimeUnit.SECONDS));
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
上传接口的请求和响应比较简单,传入二进制文件,传出原文件和缩略图下载地址:
@Data
public class UploadRequest {
private byte[] file;
}
@Data
public class UploadResponse {
private String downloadUrl;
private String thumbnailDownloadUrl;
}
2
3
4
5
6
7
8
9
10
到这里,你能看出这种实现方式的问题是什么吗?
从接口命名上看虽然是同步上传操作,但其内部通过线程池进行异步上传,并因为设置了较短超时所以接口整体响应挺快。但是,一旦遇到超时,接口就不能返回完整的数据,不是无法拿到原文件下载地址,就是无法拿到缩略图下载地址,接口的行为变得不可预测:
所以,这种优化接口响应速度的方式并不可取,更合理的方式是,让上传接口要么是彻底的同步处理,要么是彻底的异步处理:
- 所谓同步处理,接口一定是同步上传原文件和缩略图的,调用方可以自己选择调用超时,如果来得及可以一直等到上传完成,如果等不及可以结束等待,下一次再重试;
- 所谓异步处理,接口是两段式的,上传接口本身只是返回一个任务 ID,然后异步做上传操作,上传接口响应很快,客户端需要之后再拿着任务 ID 调用任务查询接口查询上传的文件 URL。
同步上传接口的实现代码如下,把超时的选择留给客户端:
public SyncUploadResponse syncUpload(SyncUploadRequest request) {
SyncUploadResponse response = new SyncUploadResponse();
response.setDownloadUrl(uploadFile(request.getFile()));
response.setThumbnailDownloadUrl(uploadThumbnailFile(request.getFile()));
return response;
}
2
3
4
5
6
这里的 SyncUploadRequest 和 SyncUploadResponse 类,与之前定义的 UploadRequest 和 UploadResponse 是一致的。对于接口的入参和出参 DTO 的命名,比较建议的方式是,使用接口名 +Request 和 Response 后缀。
接下来,我们看看异步的上传文件接口如何实现。异步上传接口在出参上有点区别,不再返回文件 URL,而是返回一个任务 ID:
@Data
public class AsyncUploadRequest {
private byte[] file;
}
@Data
public class AsyncUploadResponse {
private String taskId;
}
2
3
4
5
6
7
8
9
在接口实现上,我们同样把上传任务提交到线程池处理,但是并不会同步等待任务完成,而是完成后把结果写入一个 HashMap,任务查询接口通过查询这个 HashMap 来获得文件的 URL:
//计数器,作为上传任务的ID
private AtomicInteger atomicInteger = new AtomicInteger(0);
//暂存上传操作的结果,生产代码需要考虑数据持久化
private ConcurrentHashMap<String, SyncQueryUploadTaskResponse> downloadUrl = new ConcurrentHashMap<>();
//异步上传操作
public AsyncUploadResponse asyncUpload(AsyncUploadRequest request) {
AsyncUploadResponse response = new AsyncUploadResponse();
//生成唯一的上传任务ID
String taskId = "upload" + atomicInteger.incrementAndGet();
//异步上传操作只返回任务ID
response.setTaskId(taskId);
//提交上传原始文件操作到线程池异步处理
threadPool.execute(() -> {
String url = uploadFile(request.getFile());
//如果ConcurrentHashMap不包含Key,则初始化一个SyncQueryUploadTaskResponse,然后设置DownloadUrl
downloadUrl.computeIfAbsent(taskId, id -> new SyncQueryUploadTaskResponse(id)).setDownloadUrl(url);
});
//提交上传缩略图操作到线程池异步处理
threadPool.execute(() -> {
String url = uploadThumbnailFile(request.getFile());
downloadUrl.computeIfAbsent(taskId, id -> new SyncQueryUploadTaskResponse(id)).setThumbnailDownloadUrl(url);
});
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
文件上传查询接口则以任务 ID 作为入参,返回两个文件的下载地址,因为文件上传查询接口是同步的,所以直接命名为 syncQueryUploadTask:
//syncQueryUploadTask接口入参
@Data
@RequiredArgsConstructor
public class SyncQueryUploadTaskRequest {
private final String taskId;//使用上传文件任务ID查询上传结果
}
//syncQueryUploadTask接口出参
@Data
@RequiredArgsConstructor
public class SyncQueryUploadTaskResponse {
private final String taskId; //任务ID
private String downloadUrl; //原始文件下载URL
private String thumbnailDownloadUrl; //缩略图下载URL
}
public SyncQueryUploadTaskResponse syncQueryUploadTask(SyncQueryUploadTaskRequest request) {
SyncQueryUploadTaskResponse response = new SyncQueryUploadTaskResponse(request.getTaskId());
//从之前定义的downloadUrl ConcurrentHashMap查询结果
response.setDownloadUrl(downloadUrl.getOrDefault(request.getTaskId(), response).getDownloadUrl());
response.setThumbnailDownloadUrl(downloadUrl.getOrDefault(request.getTaskId(), response).getThumbnailDownloadUrl());
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
经过改造的 FileService 不再提供一个看起来是同步上传,内部却是异步上传的 upload 方法,改为提供很明确的:
- 同步上传接口 syncUpload;
- 异步上传接口 asyncUpload,搭配 syncQueryUploadTask 查询上传结果。
使用方可以根据业务性质选择合适的方法:如果是后端批处理使用,那么可以使用同步上传,多等待一些时间问题不大;如果是面向用户的接口,那么接口响应时间不宜过长,可以调用异步上传接口,然后定时轮询上传结果,拿到结果再显示。
# 缓存设计
通常我们会使用更快的介质(比如内存)作为缓存,来解决较慢介质(比如磁盘)读取数据慢的问题,缓存是用空间换时间,来解决性能问题的一种架构设计模式。更重要的是,磁盘上存储的往往是原始数据,而缓存中保存的可以是面向呈现的数据。这样一来,缓存不仅仅是加快了 IO,还可以减少原始数据的计算工作。
此外,缓存系统一般设计简单,功能相对单一,所以诸如 Redis 这种缓存系统的整体吞吐量,能达到关系型数据库的几倍甚至几十倍,因此缓存特别适用于互联网应用的高并发场景。
使用 Redis 做缓存虽然简单好用,但使用和设计缓存并不是 set 一下这么简单,需要注意缓存的同步、雪崩、并发、穿透等问题。
# 不要把 Redis 当作数据库
通常,我们会使用 Redis 等分布式缓存数据库来缓存数据,但是千万别把 Redis 当做数据库来使用。许多案例因为 Redis 中数据消失导致业务逻辑错误,并且因为没有保留原始数据,业务都无法恢复。
Redis 的确具有数据持久化功能,可以实现服务重启后数据不丢失。这一点,很容易让我们误认为 Redis 可以作为高性能的 KV 数据库。
其实,从本质上来看,Redis(免费版)是一个内存数据库,所有数据保存在内存中,并且直接从内存读写数据响应操作,只不过具有数据持久化能力。所以 Redis 的特点是,处理请求很快,但无法保存超过内存大小的数据。
备注:VM 模式虽然可以保存超过内存大小的数据,但是因为性能原因从 2.6 开始已经被废弃。此外 Redis 企业版提供了 Redis on Flash 可以实现 Key+ 字典 + 热数据保存在内存中,冷数据保存在 SSD 中。
因此把 Redis 用作缓存,我们需要注意两点。
第一,从客户端的角度来说,缓存数据的特点一定是有原始数据来源,且允许丢失,即使设置的缓存时间是 1 分钟,在 30 秒时缓存数据因为某种原因消失了,我们也要能接受。当数据丢失后,我们需要从原始数据重新加载数据,不能认为缓存系统是绝对可靠的,更不能认为缓存系统不会删除没有过期的数据。
第二,从 Redis 服务端的角度来说,缓存系统可以保存的数据量一定是小于原始数据的。首先,我们应该限制 Redis 对内存的使用量,也就是设置 maxmemory 参数;其次,我们应该根据数据特点,明确 Redis 应该以怎样的算法来驱逐数据。
从 Redis 的文档可以看到,常用的数据淘汰策略有:
- allkeys-lru,针对所有 Key,优先删除最近最少使用的 Key;
- volatile-lru,针对带有过期时间的 Key,优先删除最近最少使用的 Key;
- volatile-ttl,针对带有过期时间的 Key,优先删除即将过期的 Key(根据 TTL 的值);
- allkeys-lfu(Redis 4.0 以上),针对所有 Key,优先删除最少使用的 Key;
- volatile-lfu(Redis 4.0 以上),针对带有过期时间的 Key,优先删除最少使用的 Key。
其实,这些算法是 Key 范围 +Key 选择算法的搭配组合,其中范围有 allkeys 和 volatile 两种,算法有 LRU、TTL 和 LFU 三种。接下来 从 Key 范围和算法角度,和你说说如何选择合适的驱逐算法。
首先,从算法角度来说,Redis 4.0 以后推出的 LFU 比 LRU 更“实用”。试想一下,如果一个 Key 访问频率是 1 天一次,但正好在 1 秒前刚访问过,那么 LRU 可能不会选择优先淘汰这个 Key,反而可能会淘汰一个 5 秒访问一次但最近 2 秒没有访问过的 Key,而 LFU 算法不会有这个问题。而 TTL 会比较“头脑简单”一点,优先删除即将过期的 Key,但有可能这个 Key 正在被大量访问。
然后,从 Key 范围角度来说,allkeys 可以确保即使 Key 没有 TTL 也能回收,如果使用的时候客户端总是“忘记”设置缓存的过期时间,那么可以考虑使用这个系列的算法。而 volatile 会更稳妥一些,万一客户端把 Redis 当做了长效缓存使用,只是启动时候初始化一次缓存,那么一旦删除了此类没有 TTL 的数据,可能就会导致客户端出错。
所以,不管是使用者还是管理者都要考虑 Redis 的使用方式,使用者需要考虑应该以缓存的姿势来使用 Redis,管理者应该为 Redis 设置内存限制和合适的驱逐策略,避免出现 OOM。
# 注意缓存雪崩问题
由于缓存系统的 IOPS 比数据库高很多,因此要特别小心短时间内大量缓存失效的情况。这种情况一旦发生,可能就会在瞬间有大量的数据需要回源到数据库查询,对数据库造成极大的压力,极限情况下甚至导致后端数据库直接崩溃。这就是我们常说的缓存失效,也叫作缓存雪崩。
从广义上说,产生缓存雪崩的原因有两种:
- 第一种是,缓存系统本身不可用,导致大量请求直接回源到数据库;
- 第二种是,应用设计层面大量的 Key 在同一时间过期,导致大量的数据回源。
第一种原因,主要涉及缓存系统本身高可用的配置,不属于缓存设计层面的问题,所以主要和你说说如何确保大量 Key 不在同一时间被动过期。
程序初始化的时候放入 1000 条城市数据到 Redis 缓存中,过期时间是 30 秒;数据过期后从数据库获取数据然后写入缓存,每次从数据库获取数据后计数器 +1;在程序启动的同时,启动一个定时任务线程每隔一秒输出计数器的值,并把计数器归零。
压测一个随机查询某城市信息的接口,观察一下数据库的 QPS:
@Autowired
private StringRedisTemplate stringRedisTemplate;
private AtomicInteger atomicInteger = new AtomicInteger();
@PostConstruct
public void wrongInit() {
//初始化1000个城市数据到Redis,所有缓存数据有效期30秒
IntStream.rangeClosed(1, 1000).forEach(i -> stringRedisTemplate.opsForValue().set("city" + i, getCityFromDb(i), 30, TimeUnit.SECONDS));
log.info("Cache init finished");
//每秒一次,输出数据库访问的QPS
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("DB QPS : {}", atomicInteger.getAndSet(0));
}, 0, 1, TimeUnit.SECONDS);
}
@GetMapping("city")
public String city() {
//随机查询一个城市
int id = ThreadLocalRandom.current().nextInt(1000) + 1;
String key = "city" + id;
String data = stringRedisTemplate.opsForValue().get(key);
if (data == null) {
//回源到数据库查询
data = getCityFromDb(id);
if (!StringUtils.isEmpty(data))
//缓存30秒过期
stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);
}
return data;
}
private String getCityFromDb(int cityId) {
//模拟查询数据库,查一次增加计数器加一
atomicInteger.incrementAndGet();
return "citydata" + System.currentTimeMillis();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
使用 wrk 工具,设置 10 线程 10 连接压测 city 接口:
wrk -c10 -t10 -d 100s http://localhost:45678/cacheinvalid/city
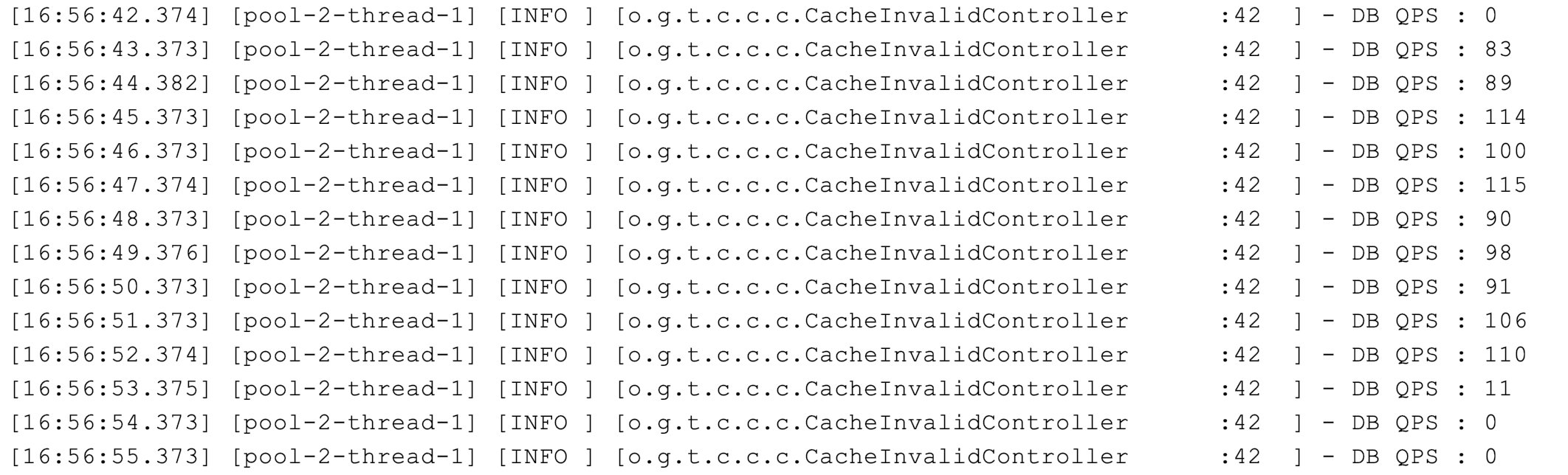
启动程序 30 秒后缓存过期,回源的数据库 QPS 最高达到了 700 多:

解决缓存 Key 同时大规模失效需要回源,导致数据库压力激增问题的方式有两种。
方案一,差异化缓存过期时间,不要让大量的 Key 在同一时间过期。比如,在初始化缓存的时候,设置缓存的过期时间是 30 秒 +10 秒以内的随机延迟(扰动值)。这样,这些 Key 不会集中在 30 秒这个时刻过期,而是会分散在 30~40 秒之间过期:
@PostConstruct
public void rightInit1() {
//这次缓存的过期时间是30秒+10秒内的随机延迟
IntStream.rangeClosed(1, 1000).forEach(i -> stringRedisTemplate.opsForValue().set("city" + i, getCityFromDb(i), 30 + ThreadLocalRandom.current().nextInt(10), TimeUnit.SECONDS));
log.info("Cache init finished");
//同样1秒一次输出数据库QPS:
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("DB QPS : {}", atomicInteger.getAndSet(0));
}, 0, 1, TimeUnit.SECONDS);
}
2
3
4
5
6
7
8
9
10
修改后,缓存过期时的回源不会集中在同一秒,数据库的 QPS 从 700 多降到了最高 100 左右:
方案二,让缓存不主动过期。初始化缓存数据的时候设置缓存永不过期,然后启动一个后台线程 30 秒一次定时把所有数据更新到缓存,而且通过适当的休眠,控制从数据库更新数据的频率,降低数据库压力:
@PostConstruct
public void rightInit2() throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
//每隔30秒全量更新一次缓存
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
IntStream.rangeClosed(1, 1000).forEach(i -> {
String data = getCityFromDb(i);
//模拟更新缓存需要一定的时间
try {
TimeUnit.MILLISECONDS.sleep(20);
} catch (InterruptedException e) { }
if (!StringUtils.isEmpty(data)) {
//缓存永不过期,被动更新
stringRedisTemplate.opsForValue().set("city" + i, data);
}
});
log.info("Cache update finished");
//启动程序的时候需要等待首次更新缓存完成
countDownLatch.countDown();
}, 0, 30, TimeUnit.SECONDS);
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("DB QPS : {}", atomicInteger.getAndSet(0));
}, 0, 1, TimeUnit.SECONDS);
countDownLatch.await();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这样修改后,虽然缓存整体更新的耗时在 21 秒左右,但数据库的压力会比较稳定:

关于这两种解决方案,我们需要特别注意以下三点:
- 方案一和方案二是截然不同的两种缓存方式,如果无法全量缓存所有数据,那么只能使用方案一;
- 即使使用了方案二,缓存永不过期,同样需要在查询的时候,确保有回源的逻辑。正如之前所说,我们无法确保缓存系统中的数据永不丢失。
- 不管是方案一还是方案二,在把数据从数据库加入缓存的时候,都需要判断来自数据库的数据是否合法,比如进行最基本的判空检查。
案例:有这样一个重大事故,某系统会在缓存中对基础数据进行长达半年的缓存,在某个时间点 DBA 把数据库中的原始数据进行了归档(可以认为是删除)操作。因为缓存中的数据一直在所以一开始没什么问题,但半年后的一天缓存中数据过期了,就从数据库中查询到了空数据加入缓存,爆发了大面积的事故。
这个案例说明,缓存会让我们更不容易发现原始数据的问题,所以在把数据加入缓存之前一定要校验数据,如果发现有明显异常要及时报警。
说到这里,我们再仔细看一下回源 QPS 超过 700 的截图,可以看到在并发情况下,总共 1000 条数据回源达到了 1002 次,说明有一些条目出现了并发回源。即缓存并发问题。
# 注意缓存击穿问题
在某些 Key 属于极端热点数据,且并发量很大的情况下,如果这个 Key 过期,可能会在某个瞬间出现大量的并发请求同时回源,相当于大量的并发请求直接打到了数据库。这种情况,就是我们常说的缓存击穿或缓存并发问题。
我们来重现下这个问题。在程序启动的时候,初始化一个热点数据到 Redis 中,过期时间设置为 5 秒,每隔 1 秒输出一下回源的 QPS:
@PostConstruct
public void init() {
//初始化一个热点数据到Redis中,过期时间设置为5秒
stringRedisTemplate.opsForValue().set("hotsopt", getExpensiveData(), 5, TimeUnit.SECONDS);
//每隔1秒输出一下回源的QPS
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("DB QPS : {}", atomicInteger.getAndSet(0));
}, 0, 1, TimeUnit.SECONDS);
}
@GetMapping("wrong")
public String wrong() {
String data = stringRedisTemplate.opsForValue().get("hotsopt");
if (StringUtils.isEmpty(data)) {
data = getExpensiveData();
//重新加入缓存,过期时间还是5秒
stringRedisTemplate.opsForValue().set("hotsopt", data, 5, TimeUnit.SECONDS);
}
return data;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
可以看到,每隔 5 秒数据库都有 20 左右的 QPS:
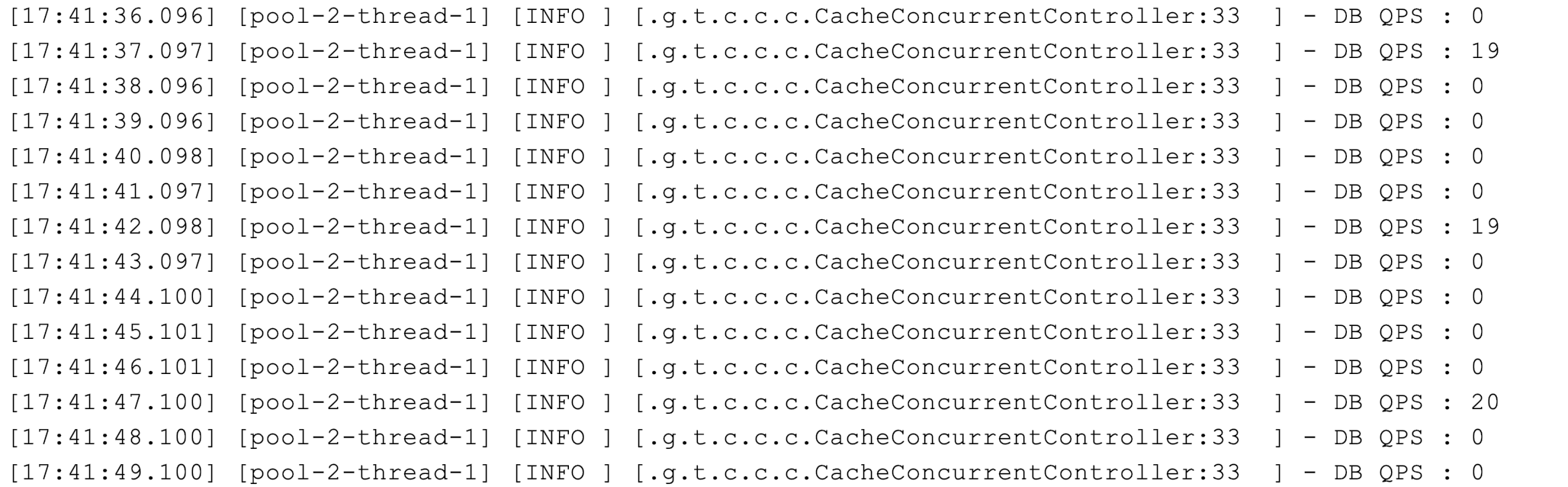
如果回源操作特别昂贵,那么这种并发就不能忽略不计。这时,我们可以考虑使用锁机制来限制回源的并发。比如如下代码示例,使用 Redisson 来获取一个基于 Redis 的分布式锁,在查询数据库之前先尝试获取锁:
@Autowired
private RedissonClient redissonClient;
@GetMapping("right")
public String right() {
String data = stringRedisTemplate.opsForValue().get("hotsopt");
if (StringUtils.isEmpty(data)) {
RLock locker = redissonClient.getLock("locker");
//获取分布式锁
if (locker.tryLock()) {
try {
data = stringRedisTemplate.opsForValue().get("hotsopt");
//双重检查,因为可能已经有一个B线程过了第一次判断,在等锁,然后A线程已经把数据写入了Redis中
if (StringUtils.isEmpty(data)) {
//回源到数据库查询
data = getExpensiveData();
stringRedisTemplate.opsForValue().set("hotsopt", data, 5, TimeUnit.SECONDS);
}
} finally {
//别忘记释放,另外注意写法,获取锁后整段代码try+finally,确保unlock万无一失
locker.unlock();
}
}
}
return data;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这样,可以把回源到数据库的并发限制在 1:
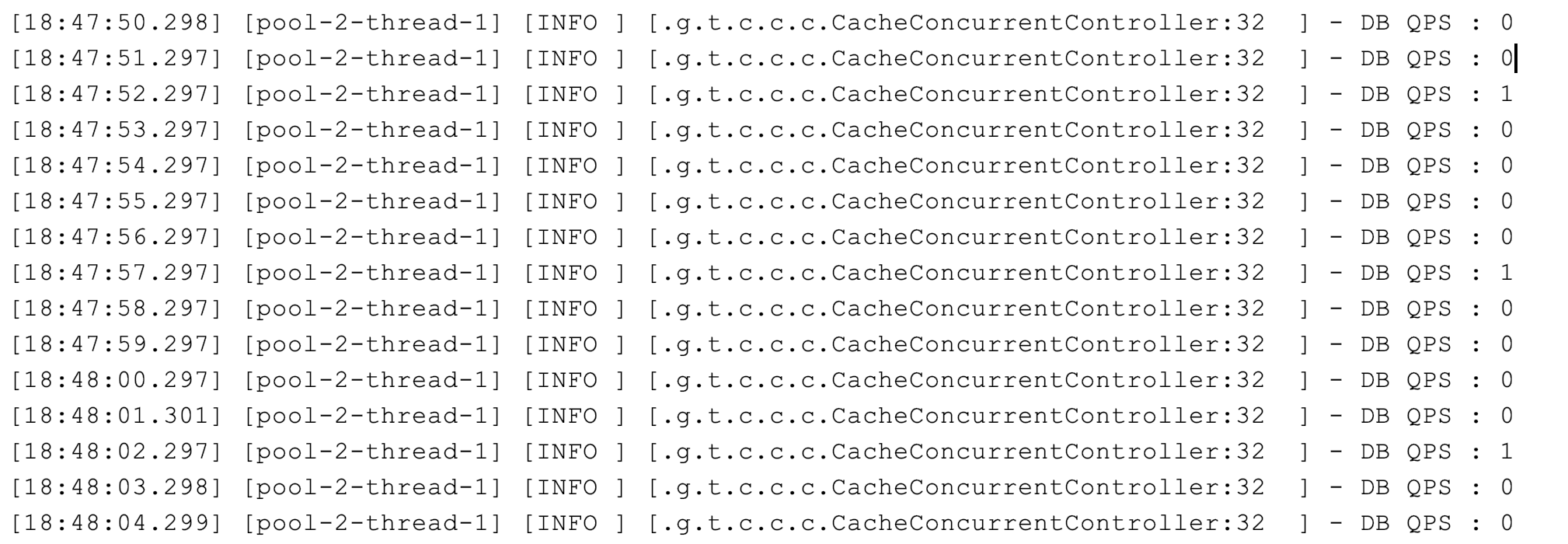
在真实的业务场景下,不一定要这么严格地使用双重检查分布式锁进行全局的并发限制,因为这样虽然可以把数据库回源并发降到最低,但也限制了缓存失效时的并发。可以考虑的方式是:
- 方案一,使用进程内的锁进行限制,这样每一个节点都可以以一个并发回源数据库;
- 方案二,不使用锁进行限制,而是使用类似 Semaphore 的工具限制并发数,比如限制为 10,这样既限制了回源并发数不至于太大,又能使得一定量的线程可以同时回源。
# 注意缓存穿透问题
在之前的例子中,缓存回源的逻辑都是当缓存中查不到需要的数据时,回源到数据库查询。这里容易出现的一个漏洞是,缓存中没有数据不一定代表数据没有缓存,还有一种可能是原始数据压根就不存在。
比如下面的例子。数据库中只保存有 ID 介于 0(不含)和 10000(包含)之间的用户,如果从数据库查询 ID 不在这个区间的用户,会得到空字符串,所以缓存中缓存的也是空字符串。如果使用 ID=0 去压接口的话,从缓存中查出了空字符串,认为是缓存中没有数据回源查询,其实相当于每次都回源:
@GetMapping("wrong")
public String wrong(@RequestParam("id") int id) {
String key = "user" + id;
String data = stringRedisTemplate.opsForValue().get(key);
//无法区分是无效用户还是缓存失效
if (StringUtils.isEmpty(data)) {
data = getCityFromDb(id);
stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);
}
return data;
}
private String getCityFromDb(int id) {
atomicInteger.incrementAndGet();
//注意,只有ID介于0(不含)和10000(包含)之间的用户才是有效用户,可以查询到用户信息
if (id > 0 && id <= 10000) return "userdata";
//否则返回空字符串
return "";
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
压测后数据库的 QPS 达到了几千:

如果这种漏洞被恶意利用的话,就会对数据库造成很大的性能压力。这就是缓存穿透。
这里需要注意,缓存穿透和缓存击穿的区别:
- 缓存穿透是指,缓存没有起到压力缓冲的作用;
- 而缓存击穿是指,缓存失效时瞬时的并发打到数据库。
解决缓存穿透有以下两种方案。
方案一,对于不存在的数据,同样设置一个特殊的 Value 到缓存中,比如当数据库中查出的用户信息为空的时候,设置 NODATA 这样具有特殊含义的字符串到缓存中。这样下次请求缓存的时候还是可以命中缓存,即直接从缓存返回结果,不查询数据库:
@GetMapping("right")
public String right(@RequestParam("id") int id) {
String key = "user" + id;
String data = stringRedisTemplate.opsForValue().get(key);
if (StringUtils.isEmpty(data)) {
data = getCityFromDb(id);
//校验从数据库返回的数据是否有效
if (!StringUtils.isEmpty(data)) {
stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);
}
else {
//如果无效,直接在缓存中设置一个NODATA,这样下次查询时即使是无效用户还是可以命中缓存
stringRedisTemplate.opsForValue().set(key, "NODATA", 30, TimeUnit.SECONDS);
}
}
return data;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
但这种方式可能会把大量无效的数据加入缓存中,如果担心大量无效数据占满缓存的话还可以考虑方案二,即使用布隆过滤器做前置过滤。
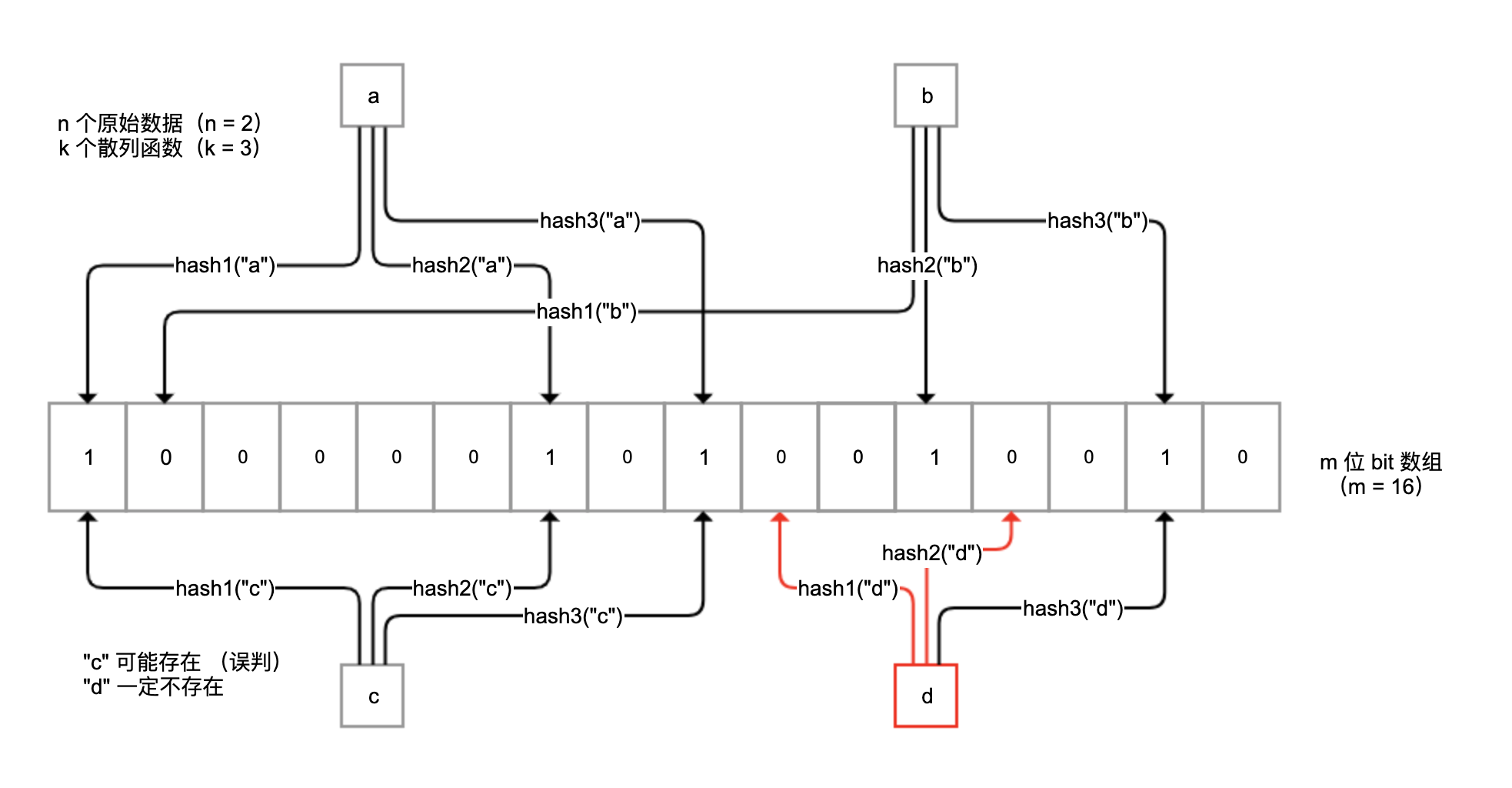
布隆过滤器是一种概率型数据库结构,由一个很长的二进制向量和一系列随机映射函数组成。它的原理是,当一个元素被加入集合时,通过 k 个散列函数将这个元素映射成一个 m 位 bit 数组中的 k 个点,并置为 1。
检索时,我们只要看看这些点是不是都是 1 就(大概)知道集合中有没有它了。如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。
原理如下图所示:
布隆过滤器不保存原始值,空间效率很高,平均每一个元素占用 2.4 字节就可以达到万分之一的误判率。这里的误判率是指,过滤器判断值存在而实际并不存在的概率。我们可以设置布隆过滤器使用更大的存储空间,来得到更小的误判率。
你可以把所有可能的值保存在布隆过滤器中,从缓存读取数据前先过滤一次:
- 如果布隆过滤器认为值不存在,那么值一定是不存在的,无需查询缓存也无需查询数据库;
- 对于极小概率的误判请求,才会最终让非法 Key 的请求走到缓存或数据库。
要用上布隆过滤器,我们可以使用 Google 的 Guava 工具包提供的 BloomFilter 类改造一下程序:启动时,初始化一个具有所有有效用户 ID 的、10000 个元素的 BloomFilter,在从缓存查询数据之前调用其 mightContain 方法,来检测用户 ID 是否可能存在;如果布隆过滤器说值不存在,那么一定是不存在的,直接返回:
private BloomFilter<Integer> bloomFilter;
@PostConstruct
public void init() {
//创建布隆过滤器,元素数量10000,期望误判率1%
bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 10000, 0.01);
//填充布隆过滤器
IntStream.rangeClosed(1, 10000).forEach(bloomFilter::put);
}
@GetMapping("right2")
public String right2(@RequestParam("id") int id) {
String data = "";
//通过布隆过滤器先判断
if (bloomFilter.mightContain(id)) {
String key = "user" + id;
//走缓存查询
data = stringRedisTemplate.opsForValue().get(key);
if (StringUtils.isEmpty(data)) {
//走数据库查询
data = getCityFromDb(id);
stringRedisTemplate.opsForValue().set(key, data, 30, TimeUnit.SECONDS);
}
}
return data;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
对于方案二,我们需要同步所有可能存在的值并加入布隆过滤器,这是比较麻烦的地方。如果业务规则明确的话,你也可以考虑直接根据业务规则判断值是否存在。
其实,方案二可以和方案一同时使用,即将布隆过滤器前置,对于误判的情况再保存特殊值到缓存,双重保险避免无效数据查询请求打到数据库。
# 注意缓存数据同步策略
前面提到的 3 个案例,其实都属于缓存数据过期后的被动删除。在实际情况下,修改了原始数据后,考虑到缓存数据更新的及时性,我们可能会采用主动更新缓存的策略。这些策略可能是:
- 先更新缓存,再更新数据库;
- 先更新数据库,再更新缓存;
- 先删除缓存,再更新数据库,访问的时候按需加载数据到缓存;
- 先更新数据库,再删除缓存,访问的时候按需加载数据到缓存。
那么,我们应该选择哪种更新策略呢?逐一分析下这 4 种策略:
“先更新缓存再更新数据库”策略不可行。数据库设计复杂,压力集中,数据库因为超时等原因更新操作失败的可能性较大,此外还会涉及事务,很可能因为数据库更新失败,导致缓存和数据库的数据不一致。
“先更新数据库再更新缓存”策略不可行。一是,如果线程 A 和 B 先后完成数据库更新,但更新缓存时却是 B 和 A 的顺序,那很可能会把旧数据更新到缓存中引起数据不一致;二是,我们不确定缓存中的数据是否会被访问,不一定要把所有数据都更新到缓存中去。
“先删除缓存再更新数据库,访问的时候按需加载数据到缓存”策略也不可行。在并发的情况下,很可能删除缓存后还没来得及更新数据库,就有另一个线程先读取了旧值到缓存中,如果并发量很大的话这个概率也会很大。
“先更新数据库再删除缓存,访问的时候按需加载数据到缓存”策略是最好的。虽然在极端情况下,这种策略也可能出现数据不一致的问题,但概率非常低,基本可以忽略。举一个“极端情况”的例子,比如更新数据的时间节点恰好是缓存失效的瞬间,这时 A 先读取到了旧值,随后在 B 操作数据库完成更新并且删除了缓存之后,A 再把旧值加入缓存。
需要注意的是,更新数据库后删除缓存的操作可能失败,如果失败则考虑把任务加入延迟队列进行延迟重试,确保数据可以删除,缓存可以及时更新。因为删除操作是幂等的,所以即使重复删问题也不是太大,这又是删除比更新好的一个原因。
因此,针对缓存更新更推荐的方式是,缓存中的数据不由数据更新操作主动触发,统一在需要使用的时候按需加载,数据更新后及时删除缓存中的数据即可。
# 业务代码写完,不意味生产就绪
所谓生产就绪(Production-ready),是指应用开发完成要投入生产环境,开发层面需要额外做的一些工作。如果应用只是开发完成了功能代码,然后就直接投产,那意味着应用其实在裸奔。在这种情况下,遇到问题因为缺乏有效的监控导致无法排查定位问题,同时很可能遇到问题我们自己都不知道,需要依靠用户反馈才知道应用出了问题。
那么生产就绪需要做哪些工作呢?有以下三方面的工作最重要。
- 提供健康检测接口。传统采用 ping 的方式对应用进行探活检测并不准确。有的时候,应用的关键内部或外部依赖已经离线,导致其根本无法正常工作,但其对外的 Web 端口或管理端口是可以 ping 通的。我们应该提供一个专有的监控检测接口,并尽可能触达一些内部组件。
- 暴露应用内部信息。应用内部诸如线程池、内存队列等组件,往往在应用内部扮演了重要的角色,如果应用或应用框架可以对外暴露这些重要信息,并加以监控,那么就有可能在诸如 OOM 等重大问题暴露之前发现蛛丝马迹,避免出现更大的问题。
- 建立应用指标 Metrics 监控。Metrics 可以翻译为度量或者指标,指的是对于一些关键信息以可聚合的、数值的形式做定期统计,并绘制出各种趋势图表。这里的指标监控,包括两个方面:一是,应用内部重要组件的指标监控,比如 JVM 的一些指标、接口的 QPS 等;二是,应用的业务数据的监控,比如电商订单量、游戏在线人数等。
# 配置 Spring Boot Actuator
Spring Boot 有一个 Actuator 模块,封装了诸如健康检测、应用内部信息、Metrics 指标等生产就绪的功能。后面的内容都是基于 Actuator 的,因此我们需要先完成 Actuator 的引入和配置。
我们可以像这样在 pom 中通过添加依赖的方式引入 Actuator:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
2
3
4
之后就可以直接使用 Actuator 了,但还要注意一些重要的配置:
- 如果不希望 Web 应用的 Actuator 管理端口和应用端口重合的话,可使用 management.server.port 设置独立的端口。
- Actuator 自带了很多开箱即用提供信息的端点(Endpoint),可以通过 JMX 或 Web 两种方式进行暴露。考虑到有些信息比较敏感,这些内置的端点默认不是完全开启的,你可以通过官网 (opens new window)查看这些默认值。在这里,为了方便后续 Demo,我们设置所有端点通过 Web 方式开启。
- 默认情况下,Actuator 的 Web 访问方式的根地址为 /actuator,可以通过 management.endpoints.web.base-path 参数进行修改。演示下如何将其修改为 /admin。
management.server.port=45679
management.endpoints.web.exposure.include=*
management.endpoints.web.base-path=/admin
2
3
现在,你就可以访问 http://localhost:45679/admin ,来查看 Actuator 的所有功能 URL 了:

其中,大部分端点提供的是只读信息,比如查询 Spring 的 Bean、ConfigurableEnvironment、定时任务、SpringBoot 自动配置、Spring MVC 映射等;少部分端点还提供了修改功能,比如优雅关闭程序、下载线程 Dump、下载堆 Dump、修改日志级别等。
你可以访问这里 (opens new window),查看所有这些端点的功能,详细了解它们提供的信息以及实现的操作。此外分享一个不错的 Spring Boot 管理工具Spring Boot Admin (opens new window),它把大部分 Actuator 端点提供的功能封装为了 Web UI。
# 健康检测需要触达关键组件
在这一讲开始我们提到,健康检测接口可以让监控系统或发布工具知晓应用的真实健康状态,比 ping 应用端口更可靠。不过,要达到这种效果最关键的是,我们能确保健康检测接口可以探查到关键组件的状态。
好在 Spring Boot Actuator 帮我们预先实现了诸如数据库、InfluxDB、Elasticsearch、Redis、RabbitMQ 等三方系统的健康检测指示器 HealthIndicator。
通过 Spring Boot 的自动配置,这些指示器会自动生效。当这些组件有问题的时候,HealthIndicator 会返回 DOWN 或 OUT_OF_SERVICE 状态,health 端点 HTTP 响应状态码也会变为 503,我们可以以此来配置程序健康状态监控报警。
为了演示,我们可以修改配置文件,把 management.endpoint.health.show-details 参数设置为 always,让所有用户都可以直接查看各个组件的健康情况(如果配置为 when-authorized,那么可以结合 management.endpoint.health.roles 配置授权的角色):
management.endpoint.health.show-details=always
访问 health 端点可以看到,数据库、磁盘、RabbitMQ、Redis 等组件健康状态是 UP,整个应用的状态也是 UP:

在了解了基本配置之后,我们考虑一下,如果程序依赖一个很重要的三方服务,我们希望这个服务无法访问的时候,应用本身的健康状态也是 DOWN。
比如三方服务有一个 user 接口,出现异常的概率是 50%:
@Slf4j
@RestController
@RequestMapping("user")
public class UserServiceController {
@GetMapping
public User getUser(@RequestParam("userId") long id) {
//一半概率返回正确响应,一半概率抛异常
if (ThreadLocalRandom.current().nextInt() % 2 == 0)
return new User(id, "name" + id);
else
throw new RuntimeException("error");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
要实现这个 user 接口是否正确响应和程序整体的健康状态挂钩的话,很简单,只需定义一个 UserServiceHealthIndicator 实现 HealthIndicator 接口即可。
在 health 方法中,我们通过 RestTemplate 来访问这个 user 接口,如果结果正确则返回 Health.up(),并把调用执行耗时和结果作为补充信息加入 Health 对象中。如果调用接口出现异常,则返回 Health.down(),并把异常信息作为补充信息加入 Health 对象中:
@Component
@Slf4j
public class UserServiceHealthIndicator implements HealthIndicator {
@Autowired
private RestTemplate restTemplate;
@Override
public Health health() {
long begin = System.currentTimeMillis();
long userId = 1L;
User user = null;
try {
//访问远程接口
user = restTemplate.getForObject("http://localhost:45678/user?userId=" + userId, User.class);
if (user != null && user.getUserId() == userId) {
//结果正确,返回UP状态,补充提供耗时和用户信息
return Health.up()
.withDetail("user", user)
.withDetail("took", System.currentTimeMillis() - begin)
.build();
} else {
//结果不正确,返回DOWN状态,补充提供耗时
return Health.down().withDetail("took", System.currentTimeMillis() - begin).build();
}
} catch (Exception ex) {
//出现异常,先记录异常,然后返回DOWN状态,补充提供异常信息和耗时
log.warn("health check failed!", ex);
return Health.down(ex).withDetail("took", System.currentTimeMillis() - begin).build();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
我们再来看一个聚合多个 HealthIndicator 的案例,也就是定义一个 CompositeHealthContributor 来聚合多个 HealthContributor,实现一组线程池的监控。
首先,在 ThreadPoolProvider 中定义两个线程池,其中 demoThreadPool 是包含一个工作线程的线程池,类型是 ArrayBlockingQueue,阻塞队列的长度为 10;还有一个 ioThreadPool 模拟 IO 操作线程池,核心线程数 10,最大线程数 50:
public class ThreadPoolProvider {
//一个工作线程的线程池,队列长度10
private static ThreadPoolExecutor demoThreadPool = new ThreadPoolExecutor(
1, 1,
2, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get());
//核心线程数10,最大线程数50的线程池,队列长度50
private static ThreadPoolExecutor ioThreadPool = new ThreadPoolExecutor(
10, 50,
2, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("io-threadpool-%d").get());
public static ThreadPoolExecutor getDemoThreadPool() {
return demoThreadPool;
}
public static ThreadPoolExecutor getIOThreadPool() {
return ioThreadPool;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
然后,我们定义一个接口,来把耗时很长的任务提交到这个 demoThreadPool 线程池,以模拟线程池队列满的情况:
@GetMapping("slowTask")
public void slowTask() {
ThreadPoolProvider.getDemoThreadPool().execute(() -> {
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
}
});
}
2
3
4
5
6
7
8
9
做了这些准备工作后,让我们来真正实现自定义的 HealthIndicator 类,用于单一线程池的健康状态。
我们可以传入一个 ThreadPoolExecutor,通过判断队列剩余容量来确定这个组件的健康状态,有剩余量则返回 UP,否则返回 DOWN,并把线程池队列的两个重要数据,也就是当前队列元素个数和剩余量,作为补充信息加入 Health:
public class ThreadPoolHealthIndicator implements HealthIndicator {
private ThreadPoolExecutor threadPool;
public ThreadPoolHealthIndicator(ThreadPoolExecutor threadPool) {
this.threadPool = threadPool;
}
@Override
public Health health() {
//补充信息
Map<String, Integer> detail = new HashMap<>();
//队列当前元素个数
detail.put("queue_size", threadPool.getQueue().size());
//队列剩余容量
detail.put("queue_remaining", threadPool.getQueue().remainingCapacity());
//如果还有剩余量则返回UP,否则返回DOWN
if (threadPool.getQueue().remainingCapacity() > 0) {
return Health.up().withDetails(detail).build();
} else {
return Health.down().withDetails(detail).build();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
再定义一个 CompositeHealthContributor,来聚合两个 ThreadPoolHealthIndicator 的实例,分别对应 ThreadPoolProvider 中定义的两个线程池:
@Component
public class ThreadPoolsHealthContributor implements CompositeHealthContributor {
//保存所有的子HealthContributor
private Map<String, HealthContributor> contributors = new HashMap<>();
ThreadPoolsHealthContributor() {
//对应ThreadPoolProvider中定义的两个线程池
this.contributors.put("demoThreadPool", new ThreadPoolHealthIndicator(ThreadPoolProvider.getDemoThreadPool()));
this.contributors.put("ioThreadPool", new ThreadPoolHealthIndicator(ThreadPoolProvider.getIOThreadPool()));
}
@Override
public HealthContributor getContributor(String name) {
//根据name找到某一个HealthContributor
return contributors.get(name);
}
@Override
public Iterator<NamedContributor<HealthContributor>> iterator() {
//返回NamedContributor的迭代器,NamedContributor也就是Contributor实例+一个命名
return contributors.entrySet().stream()
.map((entry) -> NamedContributor.of(entry.getKey(), entry.getValue())).iterator();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
程序启动后可以看到,health 接口展现了线程池和外部服务 userService 的健康状态,以及一些具体信息:

我们看到一个 demoThreadPool 为 DOWN 导致父 threadPools 为 DOWN,进一步导致整个程序的 status 为 DOWN:

以上,就是通过自定义 HealthContributor 和 CompositeHealthContributor,来实现监控检测触达程序内部诸如三方服务、线程池等关键组件,是不是很方便呢?
额外补充一下,Spring Boot 2.3.0 增强了健康检测的功能,细化了 Liveness 和 Readiness 两个端点,便于 Spring Boot 应用程序和 Kubernetes 整合。
# 对外暴露应用内部重要组件状态
除了可以把线程池的状态作为整个应用程序是否健康的依据外,我们还可以通过 Actuator 的 InfoContributor 功能,对外暴露程序内部重要组件的状态数据。这里用一个例子演示使用 info 的 HTTP 端点、JMX MBean 这两种方式,如何查看状态数据。
我们看一个具体案例,实现一个 ThreadPoolInfoContributor 来展现线程池的信息。
@Component
public class ThreadPoolInfoContributor implements InfoContributor {
private static Map threadPoolInfo(ThreadPoolExecutor threadPool) {
Map<String, Object> info = new HashMap<>();
info.put("poolSize", threadPool.getPoolSize());//当前池大小
info.put("corePoolSize", threadPool.getCorePoolSize());//设置的核心池大小
info.put("largestPoolSize", threadPool.getLargestPoolSize());//最大达到过的池大小
info.put("maximumPoolSize", threadPool.getMaximumPoolSize());//设置的最大池大小
info.put("completedTaskCount", threadPool.getCompletedTaskCount());//总完成任务数
return info;
}
@Override
public void contribute(Info.Builder builder) {
builder.withDetail("demoThreadPool", threadPoolInfo(ThreadPoolProvider.getDemoThreadPool()));
builder.withDetail("ioThreadPool", threadPoolInfo(ThreadPoolProvider.getIOThreadPool()));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
访问 /admin/info 接口,可以看到这些数据:
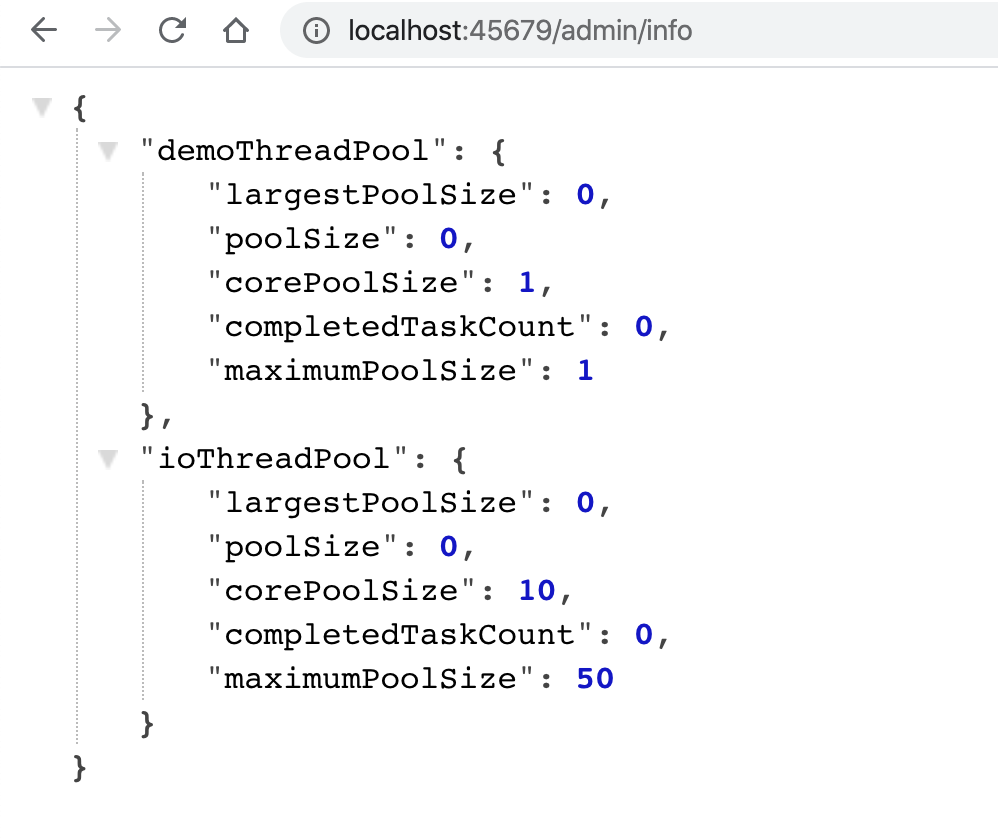
此外,如果设置开启 JMX 的话:
spring.jmx.enabled=true
可以通过 jconsole 工具,在 org.springframework.boot.Endpoint 中找到 Info 这个 MBean,然后执行 info 操作可以看到,我们刚才自定义的 InfoContributor 输出的有关两个线程池的信息:
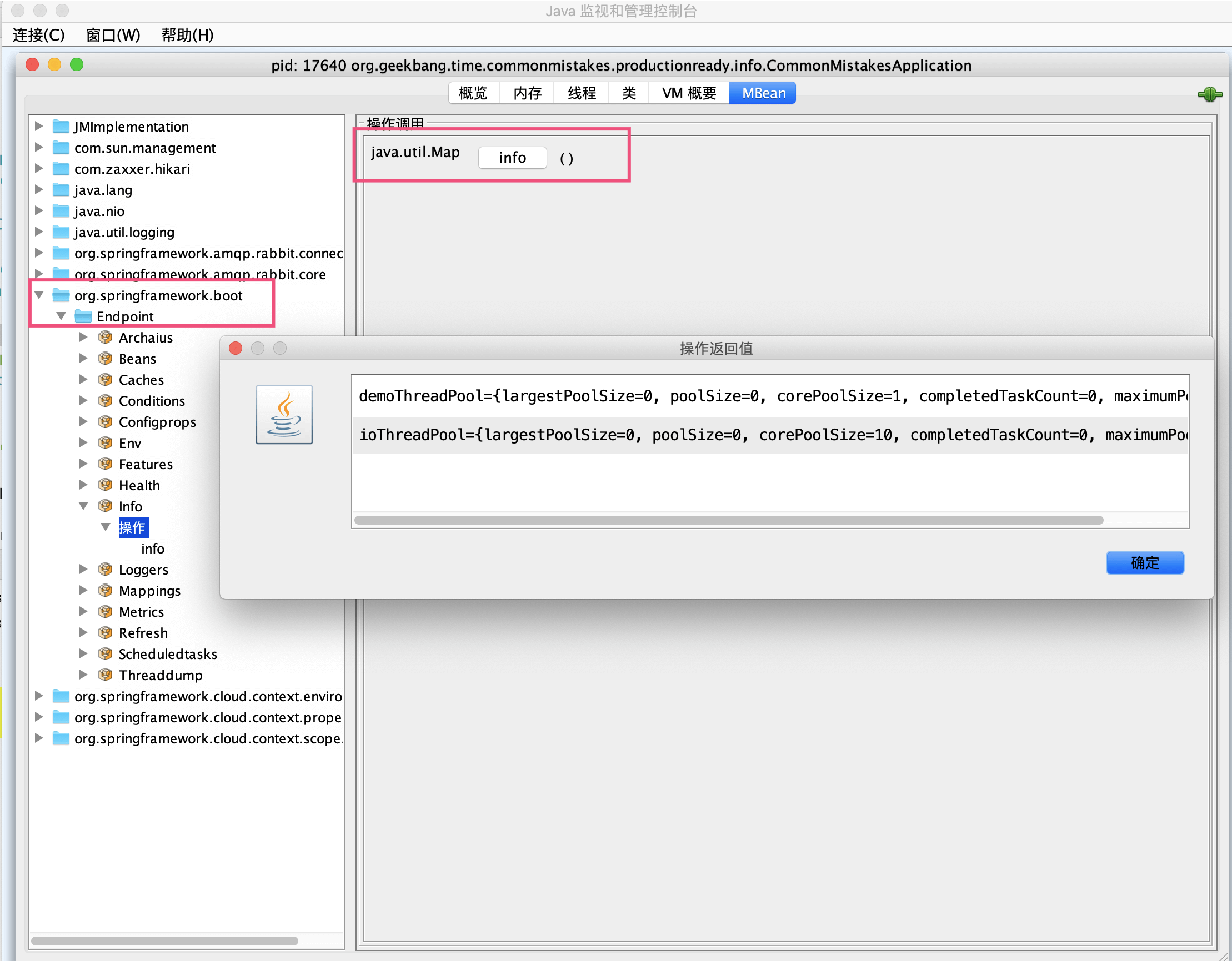
这里再额外补充一点。对于查看和操作 MBean,除了使用 jconsole 之外,你可以使用 jolokia 把 JMX 转换为 HTTP 协议,引入依赖:
<dependency>
<groupId>org.jolokia</groupId>
<artifactId>jolokia-core</artifactId>
</dependency>
2
3
4
然后,你就可以通过 jolokia,来执行 org.springframework.boot:type=Endpoint,name=Info 这个 MBean 的 info 操作:
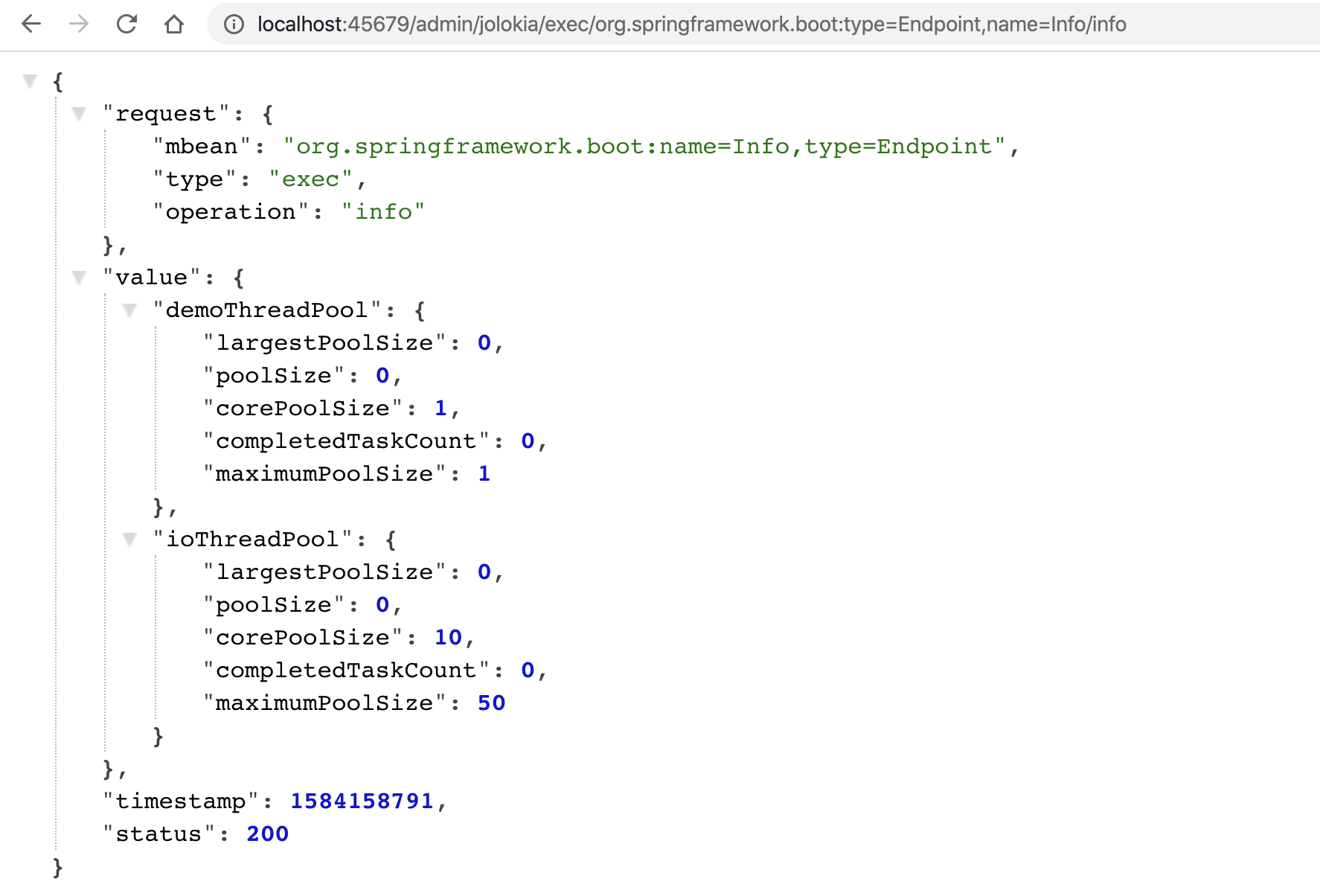
# 指标 Metrics 快速定位问题
指标是指一组和时间关联的、衡量某个维度能力的量化数值。通过收集指标并展现为曲线图、饼图等图表,可以帮助我们快速定位、分析问题。
我们通过一个实际的案例,来看看如何通过图表快速定位问题。
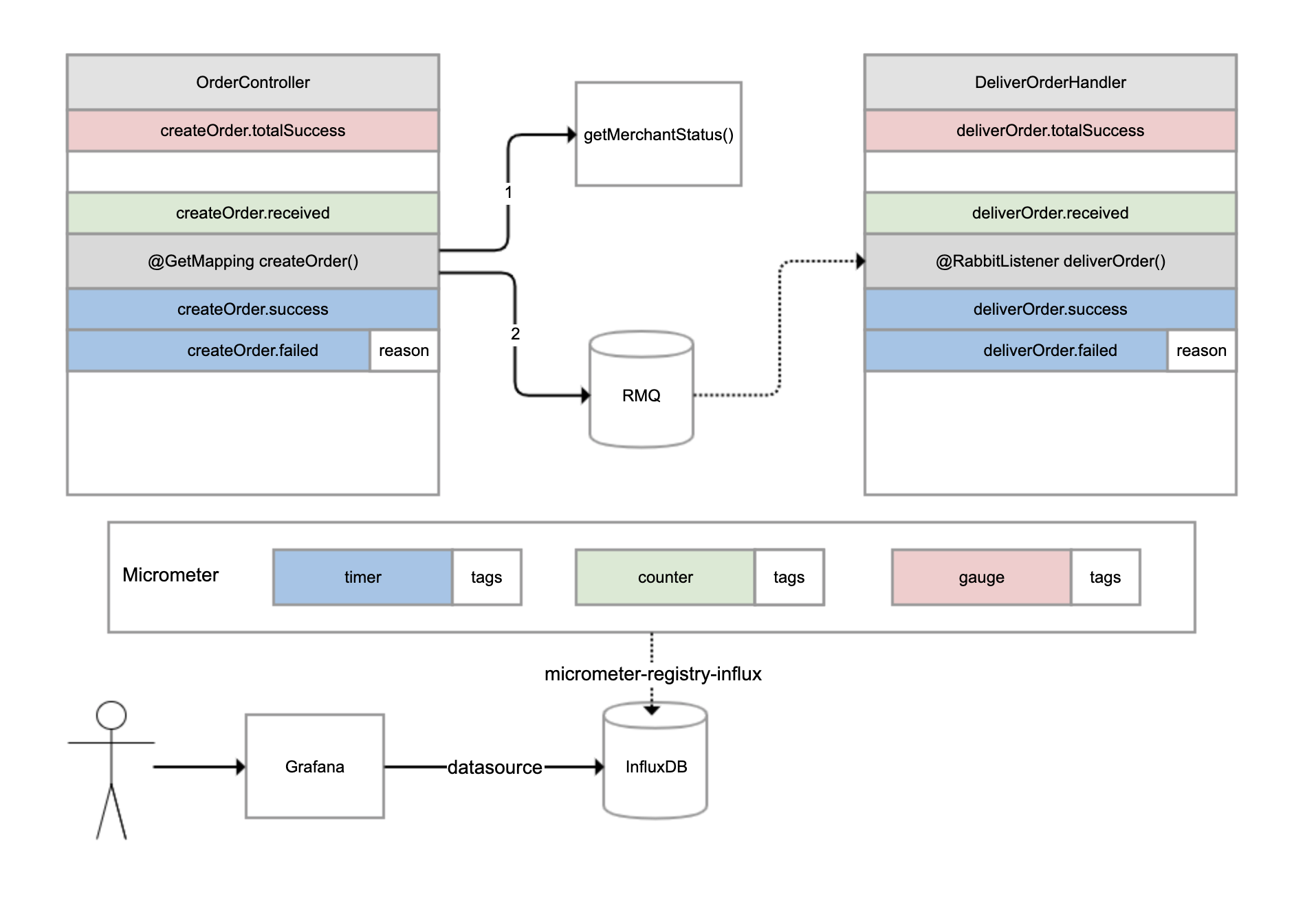
有一个外卖订单的下单和配送流程,如下图所示。OrderController 进行下单操作,下单操作前先判断参数,如果参数正确调用另一个服务查询商户状态,如果商户在营业的话继续下单,下单成功后发一条消息到 RabbitMQ 进行异步配送流程;然后另一个 DeliverOrderHandler 监听这条消息进行配送操作。
对于这样一个涉及同步调用和异步调用的业务流程,如果用户反馈下单失败,那我们如何才能快速知道是哪个环节出了问题呢?
这时,指标体系就可以发挥作用了。我们可以分别为下单和配送这两个重要操作,建立一些指标进行监控。
对于下单操作,可以建立 4 个指标:
- 下单总数量指标,监控整个系统当前累计的下单量;
- 下单请求指标,对于每次收到下单请求,在处理之前 +1;
- 下单成功指标,每次下单成功完成 +1;
- 下单失败指标,下单操作处理出现异常 +1,并且把异常原因附加到指标上。
对于配送操作,也是建立类似的 4 个指标。我们可以使用 Micrometer 框架实现指标的收集,它也是 Spring Boot Actuator 选用的指标框架。它实现了各种指标的抽象,常用的有三种:
- gauge(红色),它反映的是指标当前的值,是多少就是多少,不能累计,比如本例中的下单总数量指标,又比如游戏的在线人数、JVM 当前线程数都可以认为是 gauge。
- counter(绿色),每次调用一次方法值增加 1,是可以累计的,比如本例中的下单请求指标。举一个例子,如果 5 秒内我们调用了 10 次方法,Micrometer 也是每隔 5 秒把指标发送给后端存储系统一次,那么它可以只发送一次值,其值为 10。
- timer(蓝色),类似 counter,只不过除了记录次数,还记录耗时,比如本例中的下单成功和下单失败两个指标。
所有的指标还可以附加一些 tags 标签,作为补充数据。比如,当操作执行失败的时候,我们就会附加一个 reason 标签到指标上。
Micrometer 除了抽象了指标外,还抽象了存储。你可以把 Micrometer 理解为类似 SLF4J 这样的框架,只不过后者针对日志抽象,而 Micrometer 是针对指标进行抽象。Micrometer 通过引入各种 registry,可以实现无缝对接各种监控系统或时间序列数据库。
在这个案例中,我们引入了 micrometer-registry-influx 依赖,目的是引入 Micrometer 的核心依赖,以及通过 Micrometer 对于InfluxDB(InfluxDB 是一个时间序列数据库,其专长是存储指标数据)的绑定,以实现指标数据可以保存到 InfluxDB:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-influx</artifactId>
</dependency>
2
3
4
然后,修改配置文件,启用指标输出到 InfluxDB 的开关、配置 InfluxDB 的地址,以及设置指标每秒在客户端聚合一次,然后发送到 InfluxDB:
management.metrics.export.influx.enabled=true
management.metrics.export.influx.uri=http://localhost:8086
management.metrics.export.influx.step=1S
2
3
接下来,我们在业务逻辑中增加相关的代码来记录指标。
下面是 OrderController 的实现,代码中有详细注释,就不一一说明了。你需要注意观察如何通过 Micrometer 框架,来实现下单总数量、下单请求、下单成功和下单失败这四个指标,分别对应代码的第 17、25、43、47 行:
//下单操作,以及商户服务的接口
@Slf4j
@RestController
@RequestMapping("order")
public class OrderController {
//总订单创建数量
private AtomicLong createOrderCounter = new AtomicLong();
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private RestTemplate restTemplate;
@PostConstruct
public void init() {
//注册createOrder.received指标,gauge指标只需要像这样初始化一次,直接关联到AtomicLong引用即可
Metrics.gauge("createOrder.totalSuccess", createOrderCounter);
}
//下单接口,提供用户ID和商户ID作为入参
@GetMapping("createOrder")
public void createOrder(@RequestParam("userId") long userId, @RequestParam("merchantId") long merchantId) {
//记录一次createOrder.received指标,这是一个counter指标,表示收到下单请求
Metrics.counter("createOrder.received").increment();
Instant begin = Instant.now();
try {
TimeUnit.MILLISECONDS.sleep(200);
//模拟无效用户的情况,ID<10为无效用户
if (userId < 10)
throw new RuntimeException("invalid user");
//查询商户服务
Boolean merchantStatus = restTemplate.getForObject("http://localhost:45678/order/getMerchantStatus?merchantId=" + merchantId, Boolean.class);
if (merchantStatus == null || !merchantStatus)
throw new RuntimeException("closed merchant");
Order order = new Order();
order.setId(createOrderCounter.incrementAndGet()); //gauge指标可以得到自动更新
order.setUserId(userId);
order.setMerchantId(merchantId);
//发送MQ消息
rabbitTemplate.convertAndSend(Consts.EXCHANGE, Consts.ROUTING_KEY, order);
//记录一次createOrder.success指标,这是一个timer指标,表示下单成功,同时提供耗时
Metrics.timer("createOrder.success").record(Duration.between(begin, Instant.now()));
} catch (Exception ex) {
log.error("creareOrder userId {} failed", userId, ex);
//记录一次createOrder.failed指标,这是一个timer指标,表示下单失败,同时提供耗时,并且以tag记录失败原因
Metrics.timer("createOrder.failed", "reason", ex.getMessage()).record(Duration.between(begin, Instant.now()));
}
}
//商户查询接口
@GetMapping("getMerchantStatus")
public boolean getMerchantStatus(@RequestParam("merchantId") long merchantId) throws InterruptedException {
//只有商户ID为2的商户才是营业的
TimeUnit.MILLISECONDS.sleep(200);
return merchantId == 2;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
当用户 ID<10 的时候,我们模拟用户数据无效的情况,当商户 ID 不为 2 的时候我们模拟商户不营业的情况。
接下来是 DeliverOrderHandler 配送服务的实现。
其中,deliverOrder 方法监听 OrderController 发出的 MQ 消息模拟配送。如下代码所示,第 17、25、32 和 36 行代码,实现了配送相关四个指标的记录:
//配送服务消息处理程序
@RestController
@Slf4j
@RequestMapping("deliver")
public class DeliverOrderHandler {
//配送服务运行状态
private volatile boolean deliverStatus = true;
private AtomicLong deliverCounter = new AtomicLong();
//通过一个外部接口来改变配送状态模拟配送服务停工
@PostMapping("status")
public void status(@RequestParam("status") boolean status) {
deliverStatus = status;
}
@PostConstruct
public void init() {
//同样注册一个gauge指标deliverOrder.totalSuccess,代表总的配送单量,只需注册一次即可
Metrics.gauge("deliverOrder.totalSuccess", deliverCounter);
}
//监听MQ消息
@RabbitListener(queues = Consts.QUEUE_NAME)
public void deliverOrder(Order order) {
Instant begin = Instant.now();
//对deliverOrder.received进行递增,代表收到一次订单消息,counter类型
Metrics.counter("deliverOrder.received").increment();
try {
if (!deliverStatus)
throw new RuntimeException("deliver outofservice");
TimeUnit.MILLISECONDS.sleep(500);
deliverCounter.incrementAndGet();
//配送成功指标deliverOrder.success,timer类型
Metrics.timer("deliverOrder.success").record(Duration.between(begin, Instant.now()));
} catch (Exception ex) {
log.error("deliver Order {} failed", order, ex);
//配送失败指标deliverOrder.failed,同样附加了失败原因作为tags,timer类型
Metrics.timer("deliverOrder.failed", "reason", ex.getMessage()).record(Duration.between(begin, Instant.now()));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
同时,我们模拟了一个配送服务整体状态的开关,调用 status 接口可以修改其状态。至此,我们完成了场景准备,接下来开始配置指标监控。
首先,我们来安装 Grafana (opens new window)。然后进入 Grafana 配置一个 InfluxDB 数据源:

配置好数据源之后,就可以添加一个监控面板,然后在面板中添加各种监控图表。比如,我们在一个下单次数图表中添加了下单收到、成功和失败三个指标。
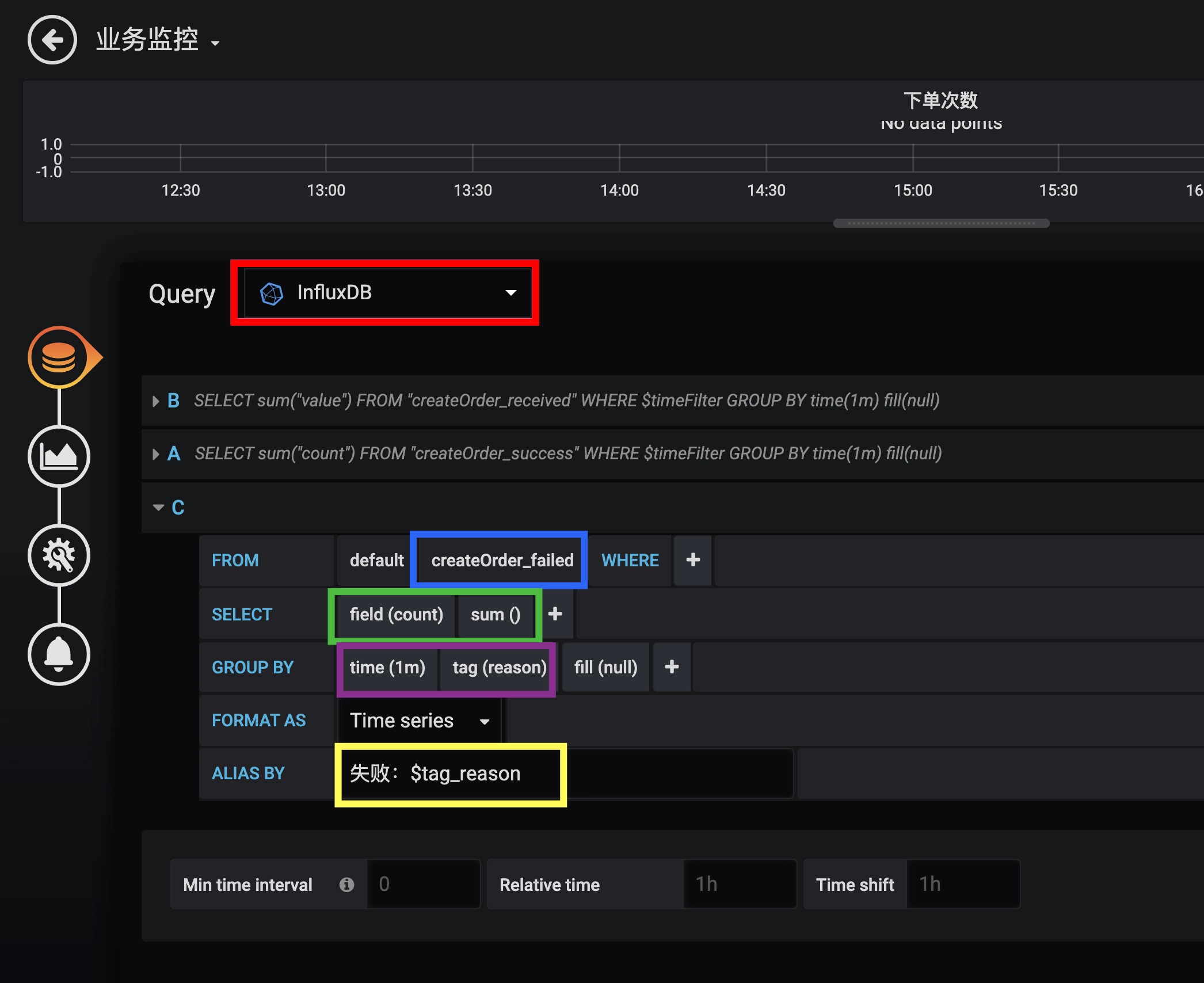
关于这张图中的配置:
- 红色框数据源配置,选择刚才配置的数据源。
- 蓝色框 FROM 配置,选择我们的指标名。
- 绿色框 SELECT 配置,选择我们要查询的指标字段,也可以应用一些聚合函数。在这里,我们取 count 字段的值,然后使用 sum 函数进行求和。
- 紫色框 GROUP BY 配置,我们配置了按 1 分钟时间粒度和 reason 字段进行分组,这样指标的 Y 轴代表 QPM(每分钟请求数),且每种失败的情况都会绘制单独的曲线。
- 黄色框 ALIAS BY 配置中设置了每一个指标的别名,在别名中引用了 reason 这个 tag。
使用 Grafana 配置 InfluxDB 指标的详细方式,你可以参考这里 (opens new window)。其中的 FROM、SELECT、GROUP BY 的含义和 SQL 类似,理解起来应该不困难。
类似地, 我们配置出一个完整的业务监控面板,包含之前实现的 8 个指标:
- 配置 2 个 Gauge 图表分别呈现总订单完成次数、总配送完成次数。
- 配置 4 个 Graph 图表分别呈现下单操作的次数和性能,以及配送操作的次数和性能。
下面我们进入实战,使用 wrk 针对四种情况进行压测,然后通过曲线来分析定位问题。
第一种情况是,使用合法的用户 ID 和营业的商户 ID 运行一段时间:
wrk -t 1 -c 1 -d 3600s http://localhost:45678/order/createOrder\?userId\=20\&merchantId\=2
从监控面板可以一目了然地看到整个系统的运作情况。可以看到,目前系统运行良好,不管是下单还是配送操作都是成功的,且下单操作平均处理时间 400ms、配送操作则是在 500ms 左右,符合预期(注意,下单次数曲线中的绿色和黄色两条曲线其实是重叠在一起的,表示所有下单都成功了):
第二种情况是,模拟无效用户 ID 运行一段时间:
wrk -t 1 -c 1 -d 3600s http://localhost:45678/order/createOrder\?userId\=2\&merchantId\=2
使用无效用户下单,显然会导致下单全部失败。接下来,我们就看看从监控图中是否能看到这个现象。
- 绿色框可以看到,下单现在出现了 invalid user 这条蓝色的曲线,并和绿色收到下单请求的曲线是吻合的,表示所有下单都失败了,原因是无效用户错误,说明源头并没有问题。
- 红色框可以看到,虽然下单都是失败的,但是下单操作时间从 400ms 减少为 200ms 了,说明下单失败之前也消耗了 200ms(和代码符合)。而因为下单失败操作的响应时间减半了,反而导致吞吐翻倍了。
- 观察两个配送监控可以发现,配送曲线出现掉 0 现象,是因为下单失败导致的,下单失败 MQ 消息压根就不会发出。再注意下蓝色那条线,可以看到配送曲线掉 0 延后于下单成功曲线的掉 0,原因是配送走的是异步流程,虽然从某个时刻开始下单全部失败了,但是 MQ 队列中还有一些之前未处理的消息。
第三种情况是,尝试一下因为商户不营业导致的下单失败:
wrk -t 1 -c 1 -d 3600s http://localhost:45678/order/createOrder\?userId\=20\&merchantId\=1
把变化的地方圈了出来,你可以自己尝试分析一下:
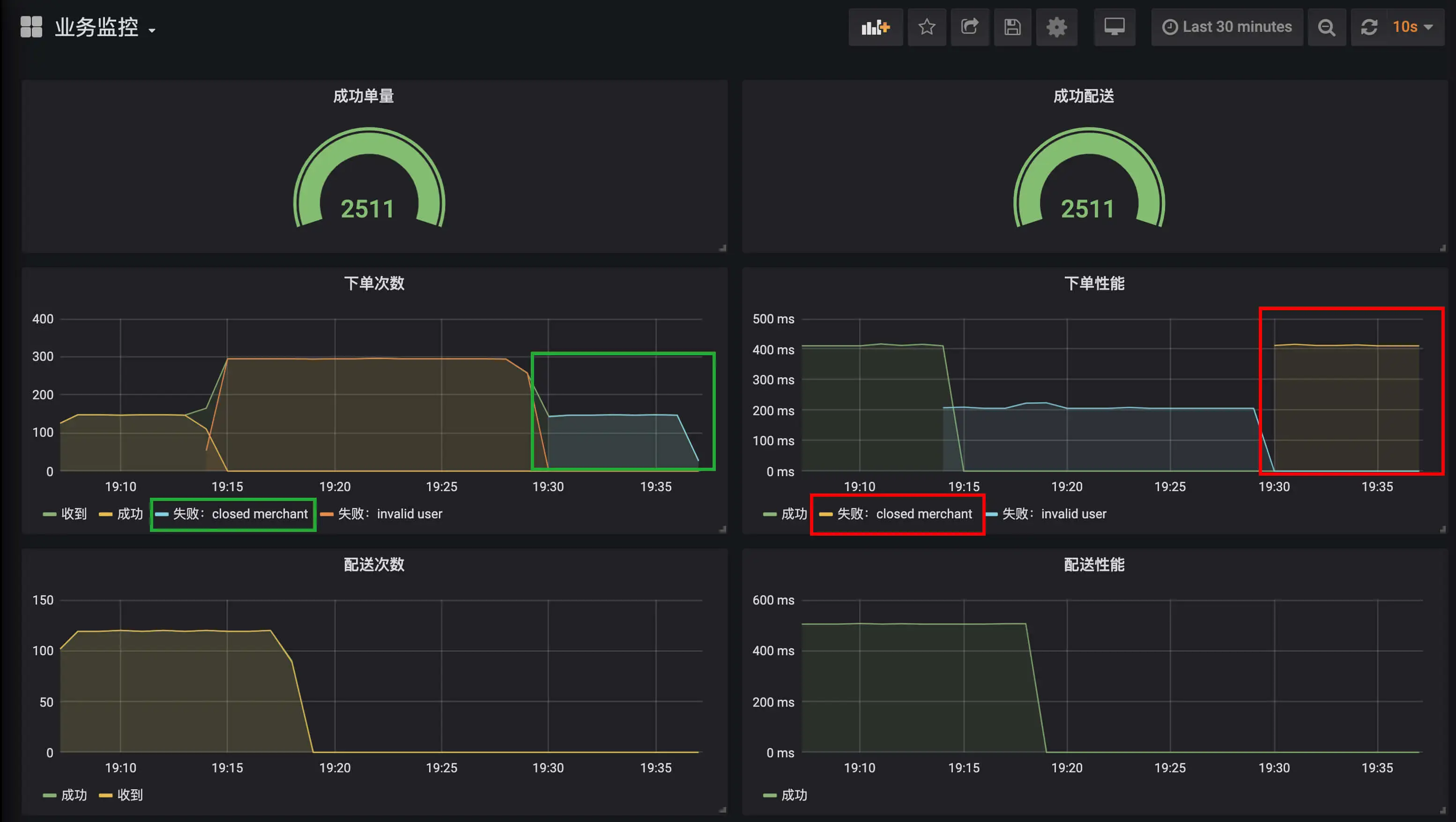
第四种情况是,配送停止。我们通过 curl 调用接口,来设置配送停止开关:
curl -X POST 'http://localhost:45678/deliver/status?status=false'
从监控可以看到,从开关关闭那刻开始,所有的配送消息全部处理失败了,原因是 deliver outofservice,配送操作性能从 500ms 左右到了 0ms,说明配送失败是一个本地快速失败,并不是因为服务超时等导致的失败。而且虽然配送失败,但下单操作都是正常的:
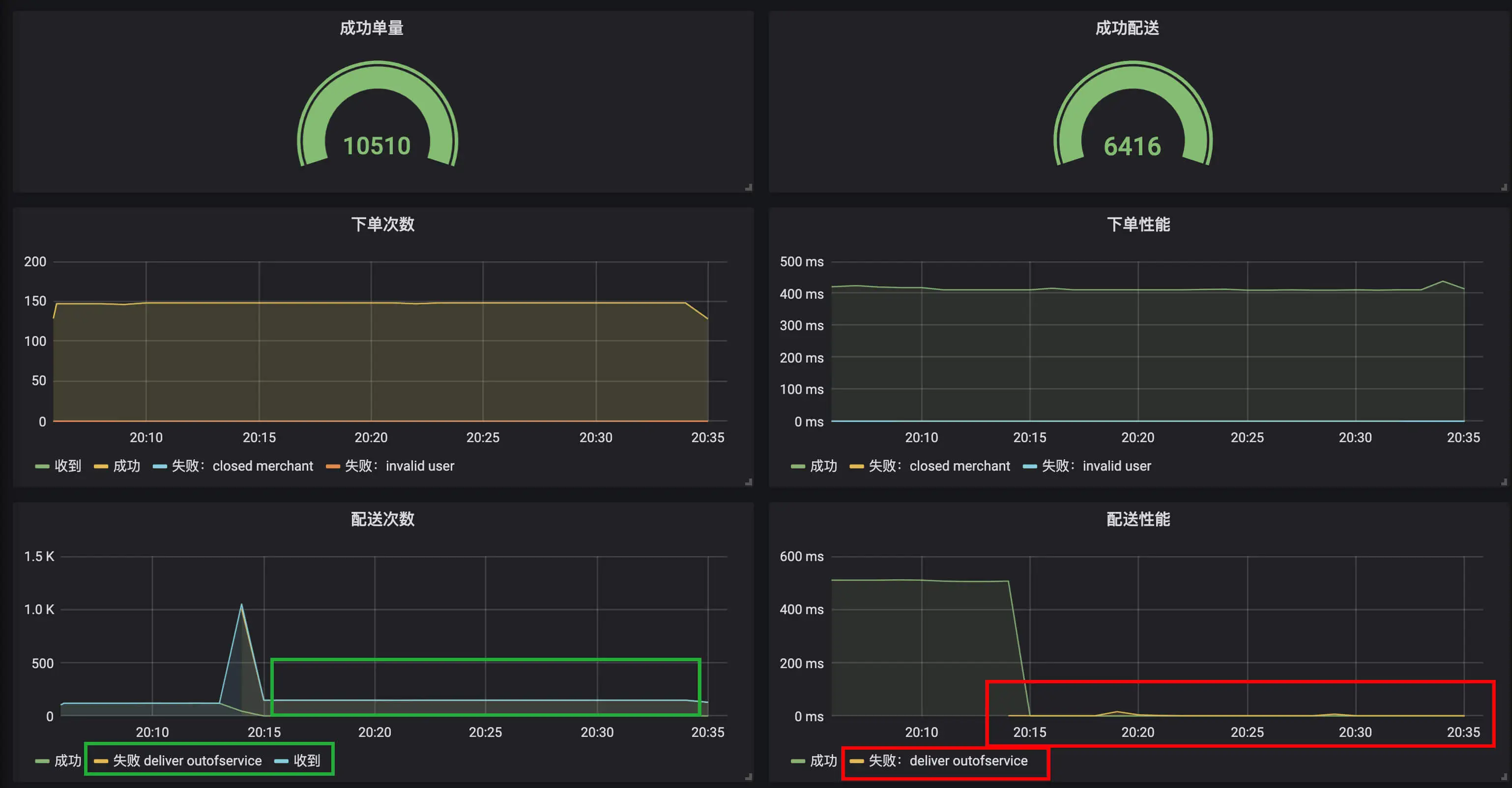
最后希望说的是,除了手动添加业务监控指标外,Micrometer 框架还帮我们自动做了很多有关 JVM 内部各种数据的指标。进入 InfluxDB 命令行客户端,你可以看到下面的这些表(指标),其中前 8 个是我们自己建的业务指标,后面都是框架帮我们建的 JVM、各种组件状态的指标:
> USE mydb
Using database mydb
> SHOW MEASUREMENTS
name: measurements
name
----
createOrder_failed
createOrder_received
createOrder_success
createOrder_totalSuccess
deliverOrder_failed
deliverOrder_received
deliverOrder_success
deliverOrder_totalSuccess
hikaricp_connections
hikaricp_connections_acquire
hikaricp_connections_active
hikaricp_connections_creation
hikaricp_connections_idle
hikaricp_connections_max
hikaricp_connections_min
hikaricp_connections_pending
hikaricp_connections_timeout
hikaricp_connections_usage
http_server_requests
jdbc_connections_max
jdbc_connections_min
jvm_buffer_count
jvm_buffer_memory_used
jvm_buffer_total_capacity
jvm_classes_loaded
jvm_classes_unloaded
jvm_gc_live_data_size
jvm_gc_max_data_size
jvm_gc_memory_allocated
jvm_gc_memory_promoted
jvm_gc_pause
jvm_memory_committed
jvm_memory_max
jvm_memory_used
jvm_threads_daemon
jvm_threads_live
jvm_threads_peak
jvm_threads_states
logback_events
process_cpu_usage
process_files_max
process_files_open
process_start_time
process_uptime
rabbitmq_acknowledged
rabbitmq_acknowledged_published
rabbitmq_channels
rabbitmq_connections
rabbitmq_consumed
rabbitmq_failed_to_publish
rabbitmq_not_acknowledged_published
rabbitmq_published
rabbitmq_rejected
rabbitmq_unrouted_published
spring_rabbitmq_listener
system_cpu_count
system_cpu_usage
system_load_average_1m
tomcat_sessions_active_current
tomcat_sessions_active_max
tomcat_sessions_alive_max
tomcat_sessions_created
tomcat_sessions_expired
tomcat_sessions_rejected
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
我们可以按照自己的需求,选取其中的一些指标,在 Grafana 中配置应用监控面板:
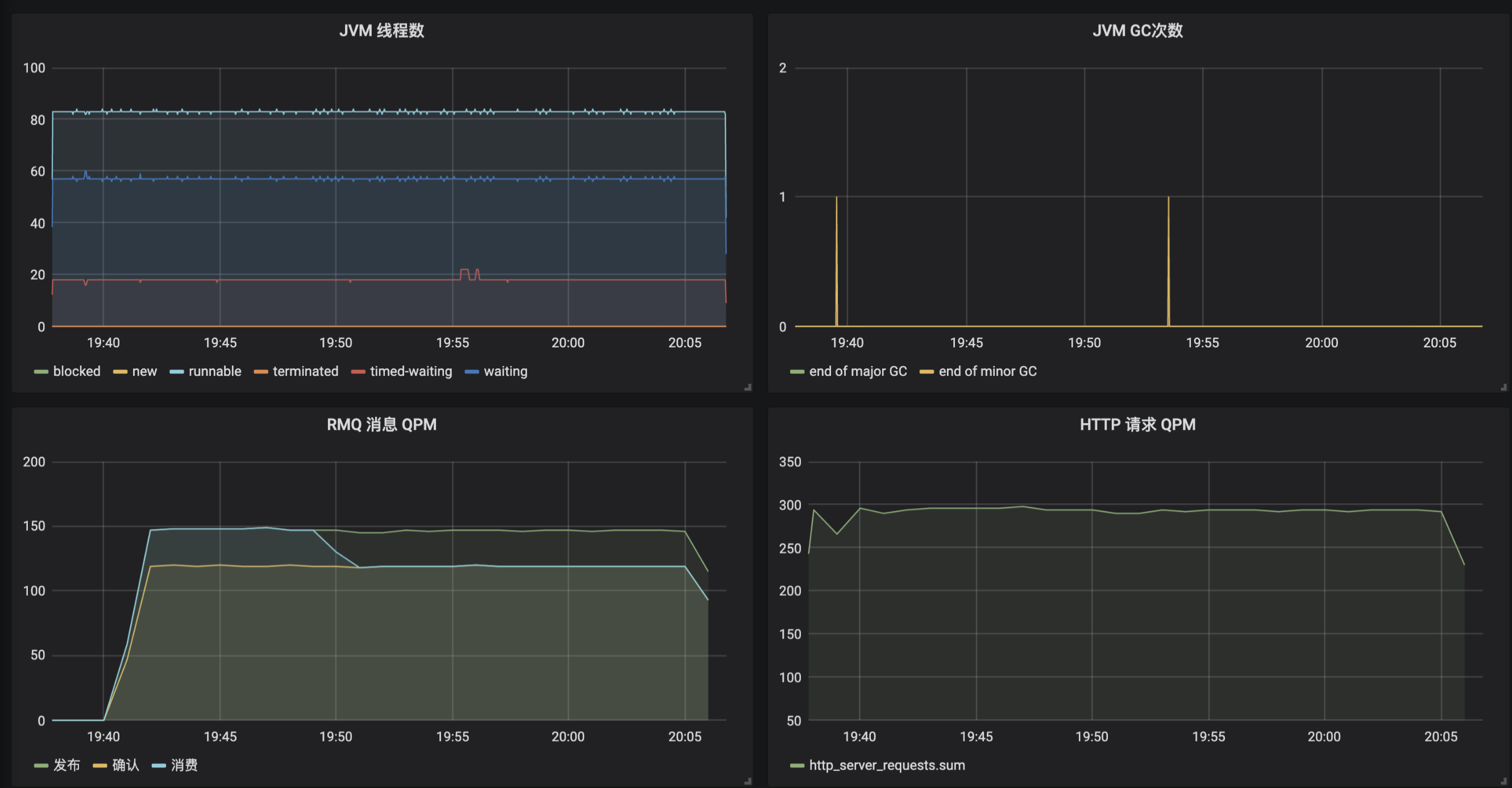
看到这里,通过监控图表来定位问题,是不是比日志方便了很多呢?
# 小结
上面介绍了如何使用 Spring Boot Actuaor 实现生产就绪的几个关键点,包括健康检测、暴露应用信息和指标监控。
所谓磨刀不误砍柴工,健康检测可以帮我们实现负载均衡的联动;应用信息以及 Actuaor 提供的各种端点,可以帮我们查看应用内部情况,甚至对应用的一些参数进行调整;而指标监控,则有助于我们整体观察应用运行情况,帮助我们快速发现和定位问题。
其实,完整的应用监控体系一般由三个方面构成,包括日志 Logging、指标 Metrics 和追踪 Tracing。其中,日志和指标相信你应该已经比较清楚了。追踪一般不涉及开发工作简单介绍一下。
追踪也叫做全链路追踪,比较有代表性的开源系统是 SkyWalking 和 Pinpoint。一般而言,接入此类系统无需额外开发,使用其提供的 javaagent 来启动 Java 程序,就可以通过动态修改字节码实现各种组件的改写,以加入追踪代码(类似 AOP)。
全链路追踪的原理是:
- 请求进入第一个组件时,先生成一个 TraceID,作为整个调用链(Trace)的唯一标识;
- 对于每次操作,都记录耗时和相关信息形成一个 Span 挂载到调用链上,Span 和 Span 之间同样可以形成树状关联,出现远程调用、跨系统调用的时候,把 TraceID 进行透传(比如,HTTP 调用通过请求透传,MQ 消息则通过消息透传);
- 把这些数据汇总提交到数据库中,通过一个 UI 界面查询整个树状调用链。
同时一般会把 TraceID 记录到日志中,方便实现日志和追踪的关联。用一张图对比了日志、指标和追踪的区别和特点:

完善的监控体系三者缺一不可,它们还可以相互配合,比如通过指标发现性能问题,通过追踪定位性能问题所在的应用和操作,最后通过日志定位出具体请求的明细参数。
# 异步处理好用,但容易用错
异步处理是互联网应用不可或缺的一种架构模式,大多数业务项目都是由同步处理、异步处理和定时任务处理三种模式相辅相成实现的。
区别于同步处理,异步处理无需同步等待流程处理完毕,因此适用场景主要包括:
- 服务于主流程的分支流程。比如,在注册流程中,把数据写入数据库的操作是主流程,但注册后给用户发优惠券或欢迎短信的操作是分支流程,时效性不那么强,可以进行异步处理。
- 用户不需要实时看到结果的流程。比如,下单后的配货、送货流程完全可以进行异步处理,每个阶段处理完成后,再给用户发推送或短信让用户知晓即可。
同时,异步处理因为可以有 MQ 中间件的介入用于任务的缓冲的分发,所以相比于同步处理,在应对流量洪峰、实现模块解耦和消息广播方面有功能优势。
不过,异步处理虽然好用,但在实现的时候却有三个最容易犯的错,分别是异步处理流程的可靠性问题、消息发送模式的区分问题,以及大量死信消息堵塞队列的问题。
下面都会使用 Spring AMQP 来操作 RabbitMQ,所以你需要先引入 amqp 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2
3
4
# 异步处理需要消息补偿闭环
使用类似 RabbitMQ、RocketMQ 等 MQ 系统来做消息队列实现异步处理,虽然说消息可以落地到磁盘保存,即使 MQ 出现问题消息数据也不会丢失,但是异步流程在消息发送、传输、处理等环节,都可能发生消息丢失。此外,任何 MQ 中间件都无法确保 100% 可用,需要考虑不可用时异步流程如何继续进行。
因此,对于异步处理流程,必须考虑补偿或者说建立主备双活流程。
我们来看一个用户注册后异步发送欢迎消息的场景。用户注册落数据库的流程为同步流程,会员服务收到消息后发送欢迎消息的流程为异步流程。
我们来分析一下:
- 蓝色的线,使用 MQ 进行的异步处理,我们称作主线,可能存在消息丢失的情况(虚线代表异步调用);
- 绿色的线,使用补偿 Job 定期进行消息补偿,我们称作备线,用来补偿主线丢失的消息;
- 考虑到极端的 MQ 中间件失效的情况,我们要求备线的处理吞吐能力达到主线的能力水平。
我们来看一下相关的实现代码。
首先,定义 UserController 用于注册 + 发送异步消息。对于注册方法,我们一次性注册 10 个用户,用户注册消息不能发送出去的概率为 50%。
@RestController
@Slf4j
@RequestMapping("user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("register")
public void register() {
//模拟10个用户注册
IntStream.rangeClosed(1, 10).forEach(i -> {
//落库
User user = userService.register();
//模拟50%的消息可能发送失败
if (ThreadLocalRandom.current().nextInt(10) % 2 == 0) {
//通过RabbitMQ发送消息
rabbitTemplate.convertAndSend(RabbitConfiguration.EXCHANGE, RabbitConfiguration.ROUTING_KEY, user);
log.info("sent mq user {}", user.getId());
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
然后,定义 MemberService 类用于模拟会员服务。会员服务监听用户注册成功的消息,并发送欢迎短信。我们使用 ConcurrentHashMap 来存放那些发过短信的用户 ID 实现幂等,避免相同的用户进行补偿时重复发送短信:
@Component
@Slf4j
public class MemberService {
//发送欢迎消息的状态
private Map<Long, Boolean> welcomeStatus = new ConcurrentHashMap<>();
//监听用户注册成功的消息,发送欢迎消息
@RabbitListener(queues = RabbitConfiguration.QUEUE)
public void listen(User user) {
log.info("receive mq user {}", user.getId());
welcome(user);
}
//发送欢迎消息
public void welcome(User user) {
//去重操作
if (welcomeStatus.putIfAbsent(user.getId(), true) == null) {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
}
log.info("memberService: welcome new user {}", user.getId());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
对于 MQ 消费程序,处理逻辑务必考虑去重(支持幂等),原因有几个:
- MQ 消息可能会因为中间件本身配置错误、稳定性等原因出现重复。
- 自动补偿重复,比如本例,同一条消息可能既走 MQ 也走补偿,肯定会出现重复,而且考虑到高内聚,补偿 Job 本身不会做去重处理。
- 人工补偿重复。出现消息堆积时,异步处理流程必然会延迟。如果我们提供了通过后台进行补偿的功能,那么在处理遇到延迟的时候,很可能会先进行人工补偿,过了一段时间后处理程序又收到消息了,重复处理。我之前就遇到过一次由 MQ 故障引发的事故,MQ 中堆积了几十万条发放资金的消息,导致业务无法及时处理,运营以为程序出错了就先通过后台进行了人工处理,结果 MQ 系统恢复后消息又被重复处理了一次,造成大量资金重复发放。
接下来,定义补偿 Job 也就是备线操作。
我们在 CompensationJob 中定义一个 @Scheduled 定时任务,5 秒做一次补偿操作,因为 Job 并不知道哪些用户注册的消息可能丢失,所以是全量补偿,补偿逻辑是:每 5 秒补偿一次,按顺序一次补偿 5 个用户,下一次补偿操作从上一次补偿的最后一个用户 ID 开始;对于补偿任务我们提交到线程池进行“异步”处理,提高处理能力。
@Component
@Slf4j
public class CompensationJob {
//补偿Job异步处理线程池
private static ThreadPoolExecutor compensationThreadPool = new ThreadPoolExecutor(
10, 10,
1, TimeUnit.HOURS,
new ArrayBlockingQueue<>(1000),
new ThreadFactoryBuilder().setNameFormat("compensation-threadpool-%d").get());
@Autowired
private UserService userService;
@Autowired
private MemberService memberService;
//目前补偿到哪个用户ID
private long offset = 0;
//10秒后开始补偿,5秒补偿一次
@Scheduled(initialDelay = 10_000, fixedRate = 5_000)
public void compensationJob() {
log.info("开始从用户ID {} 补偿", offset);
//获取从offset开始的用户
userService.getUsersAfterIdWithLimit(offset, 5).forEach(user -> {
compensationThreadPool.execute(() -> memberService.welcome(user));
offset = user.getId();
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
为了实现高内聚,主线和备线处理消息,最好使用同一个方法。比如,本例中 MemberService 监听到 MQ 消息和 CompensationJob 补偿,调用的都是 welcome 方法。
此外值得一说的是,Demo 中的补偿逻辑比较简单,生产级的代码应该在以下几个方面进行加强:
- 考虑配置补偿的频次、每次处理数量,以及补偿线程池大小等参数为合适的值,以满足补偿的吞吐量。
- 考虑备线补偿数据进行适当延迟。比如,对注册时间在 30 秒之前的用户再进行补偿,以方便和主线 MQ 实时流程错开,避免冲突。
- 诸如当前补偿到哪个用户的 offset 数据,需要落地数据库。
- 补偿 Job 本身需要高可用,可以使用类似 XXLJob 或 ElasticJob 等任务系统。
运行程序,执行注册方法注册 10 个用户,输出如下:
[17:01:16.570] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.a.compensation.UserController:28 ] - sent mq user 1
[17:01:16.571] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.a.compensation.UserController:28 ] - sent mq user 5
[17:01:16.572] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.a.compensation.UserController:28 ] - sent mq user 7
[17:01:16.573] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.a.compensation.UserController:28 ] - sent mq user 8
[17:01:16.594] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:18 ] - receive mq user 1
[17:01:18.597] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 1
[17:01:18.601] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:18 ] - receive mq user 5
[17:01:20.603] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 5
[17:01:20.604] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:18 ] - receive mq user 7
[17:01:22.605] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 7
[17:01:22.606] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:18 ] - receive mq user 8
[17:01:24.611] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 8
[17:01:25.498] [scheduling-1] [INFO ] [o.g.t.c.a.compensation.CompensationJob:29 ] - 开始从用户ID 0 补偿
[17:01:27.510] [compensation-threadpool-1] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 2
[17:01:27.510] [compensation-threadpool-3] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 4
[17:01:27.511] [compensation-threadpool-2] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 3
[17:01:30.496] [scheduling-1] [INFO ] [o.g.t.c.a.compensation.CompensationJob:29 ] - 开始从用户ID 5 补偿
[17:01:32.500] [compensation-threadpool-6] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 6
[17:01:32.500] [compensation-threadpool-9] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 9
[17:01:35.496] [scheduling-1] [INFO ] [o.g.t.c.a.compensation.CompensationJob:29 ] - 开始从用户ID 9 补偿
[17:01:37.501] [compensation-threadpool-0] [INFO ] [o.g.t.c.a.compensation.MemberService:28 ] - memberService: welcome new user 10
[17:01:40.495] [scheduling-1] [INFO ] [o.g.t.c.a.compensation.CompensationJob:29 ] - 开始从用户ID 10 补偿
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
可以看到:
总共 10 个用户,MQ 发送成功的用户有四个,分别是用户 1、5、7、8。
补偿任务第一次运行,补偿了用户 2、3、4,第二次运行补偿了用户 6、9,第三次运行补充了用户 10。
最后提一下,针对消息的补偿闭环处理的最高标准是,能够达到补偿全量数据的吞吐量。也就是说,如果补偿备线足够完善,即使直接把 MQ 停机,虽然会略微影响处理的及时性,但至少确保流程都能正常执行。
# 注意消息模式是广播还是队列
异步处理的一个重要优势,是实现消息广播。消息广播,和我们平时说的“广播”意思差不多,就是希望同一条消息,不同消费者都能分别消费;而队列模式,就是不同消费者共享消费同一个队列的数据,相同消息只能被某一个消费者消费一次。
比如,同一个用户的注册消息,会员服务需要监听以发送欢迎短信,营销服务同样需要监听以发送新用户小礼物。但是,会员服务、营销服务都可能有多个实例,我们期望的是同一个用户的消息,可以同时广播给不同的服务(广播模式),但对于同一个服务的不同实例(比如会员服务 1 和会员服务 2),不管哪个实例来处理,处理一次即可(工作队列模式):
在实现代码的时候,我们务必确认 MQ 系统的机制,确保消息的路由按照我们的期望。
对于类似 RocketMQ 这样的 MQ 来说,实现类似功能比较简单直白:如果消费者属于一个组,那么消息只会由同一个组的一个消费者来消费;如果消费者属于不同组,那么每个组都能消费一遍消息。
而对于 RabbitMQ 来说,消息路由的模式采用的是队列 + 交换器,队列是消息的载体,交换器决定了消息路由到队列的方式,配置比较复杂,容易出错。所以,接下来重点讲讲 RabbitMQ 的相关代码实现。
我们还是以上面的架构图为例,来演示使用 RabbitMQ 实现广播模式和工作队列模式的坑。
第一步,实现会员服务监听用户服务发出的新用户注册消息的那部分逻辑。
如果我们启动两个会员服务,那么同一个用户的注册消息应该只能被其中一个实例消费。
我们分别实现 RabbitMQ 队列、交换器、绑定三件套。其中,队列用的是匿名队列,交换器用的是直接交换器 DirectExchange,交换器绑定到匿名队列的路由 Key 是空字符串。在收到消息之后,我们会打印所在实例使用的端口:
//为了代码简洁直观,我们把消息发布者、消费者、以及MQ的配置代码都放在了一起
@Slf4j
@Configuration
@RestController
@RequestMapping("workqueuewrong")
public class WorkQueueWrong {
private static final String EXCHANGE = "newuserExchange";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//使用匿名队列作为消息队列
@Bean
public Queue queue() {
return new AnonymousQueue();
}
//声明DirectExchange交换器,绑定队列到交换器
@Bean
public Declarables declarables() {
DirectExchange exchange = new DirectExchange(EXCHANGE);
return new Declarables(queue(), exchange,
BindingBuilder.bind(queue()).to(exchange).with(""));
}
//监听队列,队列名称直接通过SpEL表达式引用Bean
@RabbitListener(queues = "#{queue.name}")
public void memberService(String userName) {
log.info("memberService: welcome message sent to new user {} from {}", userName, System.getProperty("server.port"));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
使用 12345 和 45678 两个端口启动两个程序实例后,调用 sendMessage 接口发送一条消息,输出的日志,显示同一个会员服务两个实例都收到了消息:


出现这个问题的原因是,我们没有理清楚 RabbitMQ 直接交换器和队列的绑定关系。
如下图所示,RabbitMQ 的直接交换器根据 routingKey 对消息进行路由。由于我们的程序每次启动都会创建匿名(随机命名)的队列,所以相当于每一个会员服务实例都对应独立的队列,以空 routingKey 绑定到直接交换器。用户服务发出消息的时候也设置了 routingKey 为空,所以直接交换器收到消息之后,发现有两条队列匹配,于是都转发了消息:
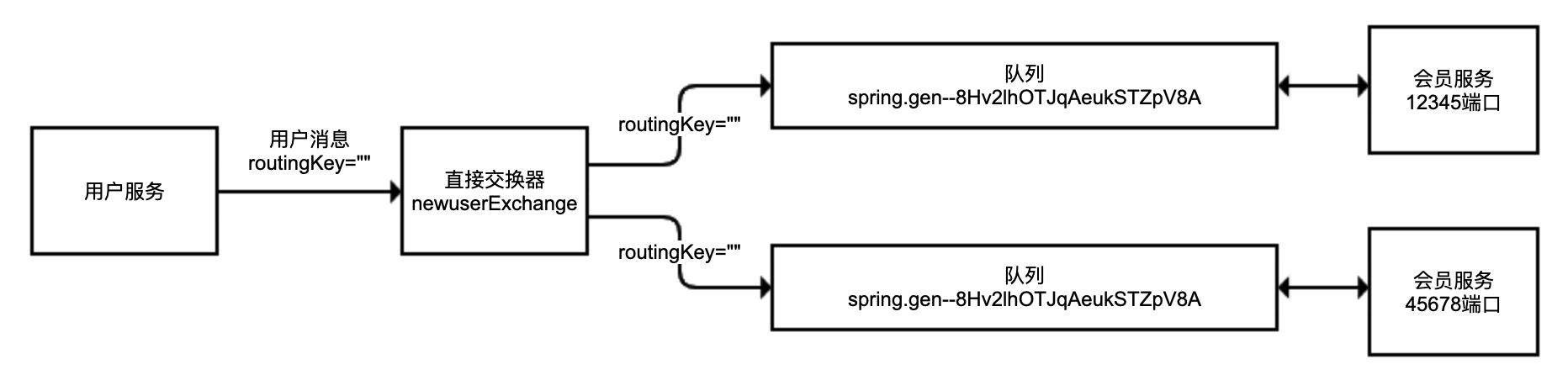
要修复这个问题其实很简单,对于会员服务不要使用匿名队列,而是使用同一个队列即可。把上面代码中的匿名队列替换为一个普通队列:
private static final String QUEUE = "newuserQueue";
@Bean
public Queue queue() {
return new Queue(QUEUE);
}
2
3
4
5
测试发现,对于同一条消息来说,两个实例中只有一个实例可以收到,不同的消息按照轮询分发给不同的实例。现在,交换器和队列的关系是这样的:
第二步,进一步完整实现用户服务需要广播消息给会员服务和营销服务的逻辑。
我们希望会员服务和营销服务都可以收到广播消息,但会员服务或营销服务中的每个实例只需要收到一次消息。
代码如下,我们声明了一个队列和一个广播交换器 FanoutExchange,然后模拟两个用户服务和两个营销服务:
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutwrong")
public class FanoutQueueWrong {
private static final String QUEUE = "newuser";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
//声明FanoutExchange,然后绑定到队列,FanoutExchange绑定队列的时候不需要routingKey
@Bean
public Declarables declarables() {
Queue queue = new Queue(QUEUE);
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
return new Declarables(queue, exchange,
BindingBuilder.bind(queue).to(exchange));
}
//会员服务实例1
@RabbitListener(queues = QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
//会员服务实例2
@RabbitListener(queues = QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
//营销服务实例1
@RabbitListener(queues = QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
//营销服务实例2
@RabbitListener(queues = QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
我们请求四次 sendMessage 接口,注册四个用户。通过日志可以发现,一条用户注册的消息,要么被会员服务收到,要么被营销服务收到,显然这不是广播。那我们使用的 FanoutExchange,看名字就应该是实现广播的交换器,为什么根本没有起作用呢?

其实,广播交换器非常简单,它会忽略 routingKey,广播消息到所有绑定的队列。在这个案例中,两个会员服务和两个营销服务都绑定了同一个队列,所以这四个服务只能收到一次消息:
修改方式很简单,我们把队列进行拆分,会员和营销两组服务分别使用一条独立队列绑定到广播交换器即可:
@Slf4j
@Configuration
@RestController
@RequestMapping("fanoutright")
public class FanoutQueueRight {
private static final String MEMBER_QUEUE = "newusermember";
private static final String PROMOTION_QUEUE = "newuserpromotion";
private static final String EXCHANGE = "newuser";
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping
public void sendMessage() {
rabbitTemplate.convertAndSend(EXCHANGE, "", UUID.randomUUID().toString());
}
@Bean
public Declarables declarables() {
//会员服务队列
Queue memberQueue = new Queue(MEMBER_QUEUE);
//营销服务队列
Queue promotionQueue = new Queue(PROMOTION_QUEUE);
//广播交换器
FanoutExchange exchange = new FanoutExchange(EXCHANGE);
//两个队列绑定到同一个交换器
return new Declarables(memberQueue, promotionQueue, exchange,
BindingBuilder.bind(memberQueue).to(exchange),
BindingBuilder.bind(promotionQueue).to(exchange));
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService1(String userName) {
log.info("memberService1: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = MEMBER_QUEUE)
public void memberService2(String userName) {
log.info("memberService2: welcome message sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService1(String userName) {
log.info("promotionService1: gift sent to new user {}", userName);
}
@RabbitListener(queues = PROMOTION_QUEUE)
public void promotionService2(String userName) {
log.info("promotionService2: gift sent to new user {}", userName);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
现在,交换器和队列的结构是这样的:
从日志输出可以验证,对于每一条 MQ 消息,会员服务和营销服务分别都会收到一次,一条消息广播到两个服务的同时,在每一个服务的两个实例中通过轮询接收:

所以说,理解了 RabbitMQ 直接交换器、广播交换器的工作方式之后,我们对消息的路由方式了解得很清晰了,实现代码就不会出错。
对于异步流程来说,消息路由模式一旦配置出错,轻则可能导致消息的重复处理,重则可能导致重要的服务无法接收到消息,最终造成业务逻辑错误。
每个 MQ 中间件对消息的路由处理的配置各不相同,我们一定要先了解原理再着手编码。
# 别让死信堵塞了消息队列
如果线程池的任务队列没有上限,那么最终可能会导致 OOM。使用消息队列处理异步流程的时候,我们也同样要注意消息队列的任务堆积问题。对于突发流量引起的消息队列堆积,问题并不大,适当调整消费者的消费能力应该就可以解决。但在很多时候,消息队列的堆积堵塞,是因为有大量始终无法处理的消息。
比如,用户服务在用户注册后发出一条消息,会员服务监听到消息后给用户派发优惠券,但因为用户并没有保存成功,会员服务处理消息始终失败,消息重新进入队列,然后还是处理失败。这种在 MQ 中像幽灵一样回荡的同一条消息,就是死信。
随着 MQ 被越来越多的死信填满,消费者需要花费大量时间反复处理死信,导致正常消息的消费受阻,最终 MQ 可能因为数据量过大而崩溃。
我们来测试一下这个场景。首先定义一个队列、一个直接交换器,然后把队列绑定到交换器:
@Bean
public Declarables declarables() {
//队列
Queue queue = new Queue(Consts.QUEUE);
//交换器
DirectExchange directExchange = new DirectExchange(Consts.EXCHANGE);
//快速声明一组对象,包含队列、交换器,以及队列到交换器的绑定
return new Declarables(queue, directExchange,
BindingBuilder.bind(queue).to(directExchange).with(Consts.ROUTING_KEY));
}
2
3
4
5
6
7
8
9
10
然后,实现一个 sendMessage 方法来发送消息到 MQ,访问一次提交一条消息,使用自增标识作为消息内容:
//自增消息标识
AtomicLong atomicLong = new AtomicLong();
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("sendMessage")
public void sendMessage() {
String msg = "msg" + atomicLong.incrementAndGet();
log.info("send message {}", msg);
//发送消息
rabbitTemplate.convertAndSend(Consts.EXCHANGE, msg);
}
2
3
4
5
6
7
8
9
10
11
12
收到消息后,直接抛出空指针异常,模拟处理出错的情况:
@RabbitListener(queues = Consts.QUEUE)
public void handler(String data) {
log.info("got message {}", data);
throw new NullPointerException("error");
}
2
3
4
5
调用 sendMessage 接口发送两条消息,然后来到 RabbitMQ 管理台,可以看到这两条消息始终在队列中,不断被重新投递,导致重新投递 QPS 达到了 1063。
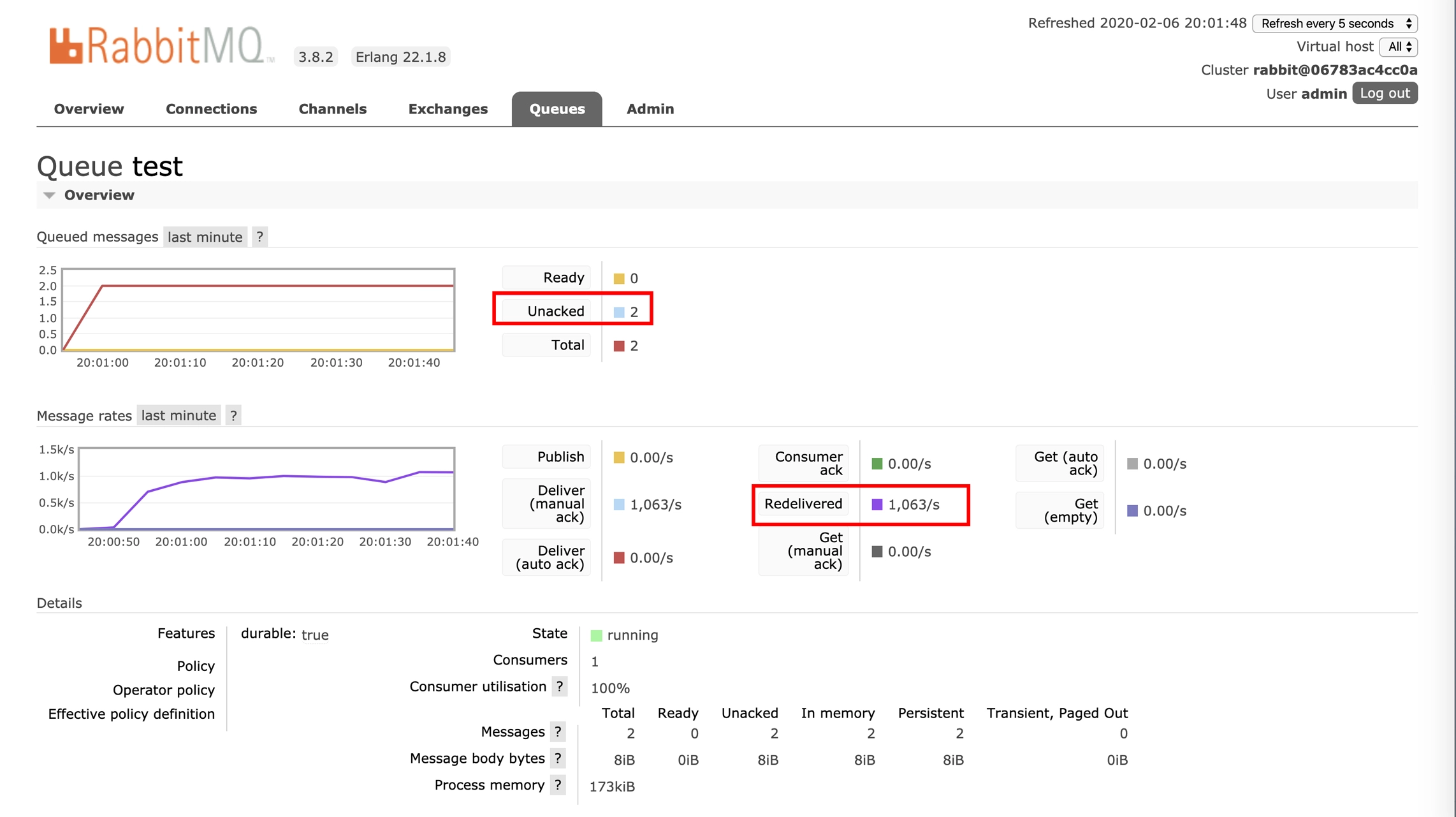
同时,在日志中可以看到大量异常信息:
[20:02:31.533] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [WARN ] [o.s.a.r.l.ConditionalRejectingErrorHandler:129 ] - Execution of Rabbit message listener failed.
org.springframework.amqp.rabbit.support.ListenerExecutionFailedException: Listener method 'public void org.geekbang.time.commonmistakes.asyncprocess.deadletter.MQListener.handler(java.lang.String)' threw exception
at org.springframework.amqp.rabbit.listener.adapter.MessagingMessageListenerAdapter.invokeHandler(MessagingMessageListenerAdapter.java:219)
at org.springframework.amqp.rabbit.listener.adapter.MessagingMessageListenerAdapter.invokeHandlerAndProcessResult(MessagingMessageListenerAdapter.java:143)
at org.springframework.amqp.rabbit.listener.adapter.MessagingMessageListenerAdapter.onMessage(MessagingMessageListenerAdapter.java:132)
at org.springframework.amqp.rabbit.listener.AbstractMessageListenerContainer.doInvokeListener(AbstractMessageListenerContainer.java:1569)
at org.springframework.amqp.rabbit.listener.AbstractMessageListenerContainer.actualInvokeListener(AbstractMessageListenerContainer.java:1488)
at org.springframework.amqp.rabbit.listener.AbstractMessageListenerContainer.invokeListener(AbstractMessageListenerContainer.java:1476)
at org.springframework.amqp.rabbit.listener.AbstractMessageListenerContainer.doExecuteListener(AbstractMessageListenerContainer.java:1467)
at org.springframework.amqp.rabbit.listener.AbstractMessageListenerContainer.executeListener(AbstractMessageListenerContainer.java:1411)
at org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer.doReceiveAndExecute(SimpleMessageListenerContainer.java:958)
at org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer.receiveAndExecute(SimpleMessageListenerContainer.java:908)
at org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer.access$1600(SimpleMessageListenerContainer.java:81)
at org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer$AsyncMessageProcessingConsumer.mainLoop(SimpleMessageListenerContainer.java:1279)
at org.springframework.amqp.rabbit.listener.SimpleMessageListenerContainer$AsyncMessageProcessingConsumer.run(SimpleMessageListenerContainer.java:1185)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NullPointerException: error
at org.geekbang.time.commonmistakes.asyncprocess.deadletter.MQListener.handler(MQListener.java:14)
at sun.reflect.GeneratedMethodAccessor46.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.messaging.handler.invocation.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:171)
at org.springframework.messaging.handler.invocation.InvocableHandlerMethod.invoke(InvocableHandlerMethod.java:120)
at org.springframework.amqp.rabbit.listener.adapter.HandlerAdapter.invoke(HandlerAdapter.java:50)
at org.springframework.amqp.rabbit.listener.adapter.MessagingMessageListenerAdapter.invokeHandler(MessagingMessageListenerAdapter.java:211)
... 13 common frames omitted
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
解决死信无限重复进入队列最简单的方式是,在程序处理出错的时候,直接抛出 AmqpRejectAndDontRequeueException 异常,避免消息重新进入队列:
throw new AmqpRejectAndDontRequeueException("error");
但我们更希望的逻辑是,对于同一条消息,能够先进行几次重试,解决因为网络问题导致的偶发消息处理失败,如果还是不行的话,再把消息投递到专门的一个死信队列。对于来自死信队列的数据,我们可能只是记录日志发送报警,即使出现异常也不会再重复投递。整个逻辑如下图所示:
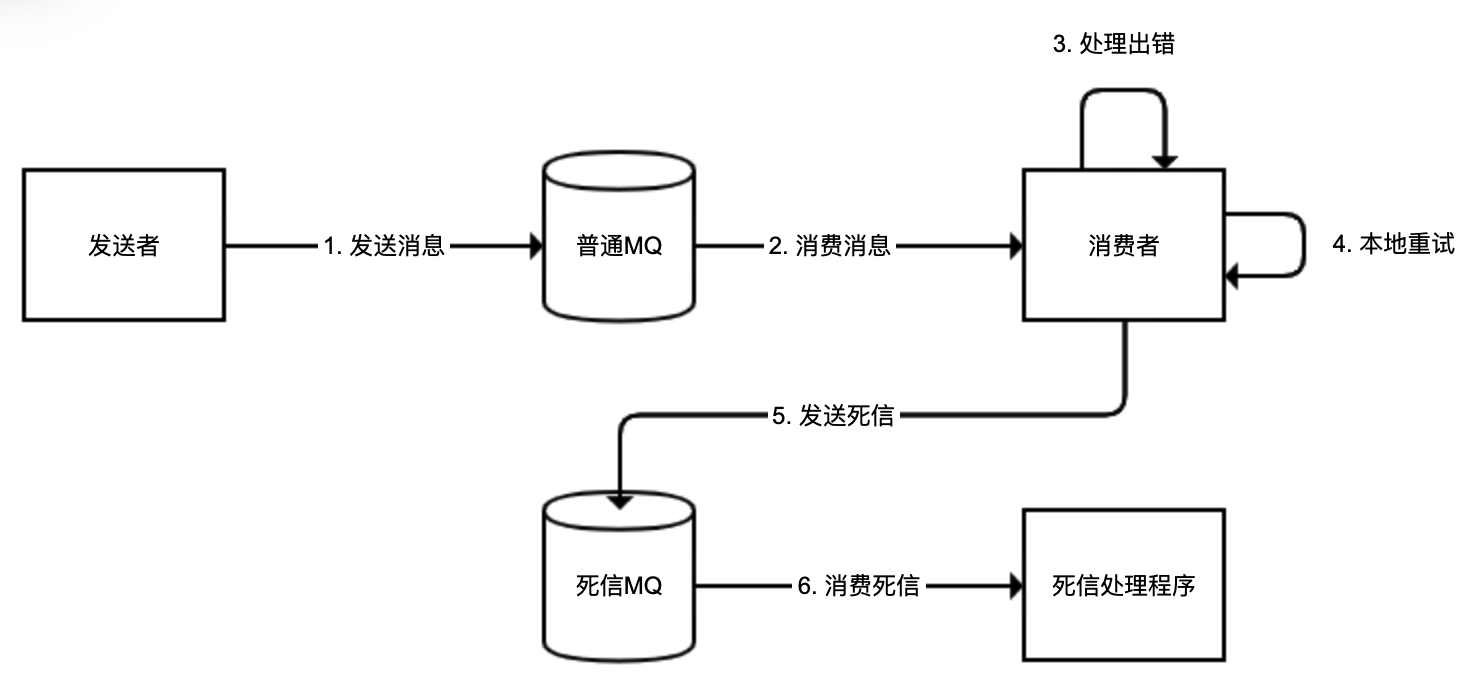
针对这个问题,Spring AMQP 提供了非常方便的解决方案:
- 首先,定义死信交换器和死信队列。其实,这些都是普通的交换器和队列,只不过被我们专门用于处理死信消息。
- 然后,通过 RetryInterceptorBuilder 构建一个 RetryOperationsInterceptor,用于处理失败时候的重试。这里的策略是,最多尝试 5 次(重试 4 次);并且采取指数退避重试,首次重试延迟 1 秒,第二次 2 秒,以此类推,最大延迟是 10 秒;如果第 4 次重试还是失败,则使用 RepublishMessageRecoverer 把消息重新投入一个“死信交换器”中。
- 最后,定义死信队列的处理程序。这个案例中,我们只是简单记录日志。
对应的实现代码如下:
//定义死信交换器和队列,并且进行绑定
@Bean
public Declarables declarablesForDead() {
Queue queue = new Queue(Consts.DEAD_QUEUE);
DirectExchange directExchange = new DirectExchange(Consts.DEAD_EXCHANGE);
return new Declarables(queue, directExchange,
BindingBuilder.bind(queue).to(directExchange).with(Consts.DEAD_ROUTING_KEY));
}
//定义重试操作拦截器
@Bean
public RetryOperationsInterceptor interceptor() {
return RetryInterceptorBuilder.stateless()
.maxAttempts(5) //最多尝试(不是重试)5次
.backOffOptions(1000, 2.0, 10000) //指数退避重试
.recoverer(new RepublishMessageRecoverer(rabbitTemplate, Consts.DEAD_EXCHANGE, Consts.DEAD_ROUTING_KEY)) //重新投递重试达到上限的消息
.build();
}
//通过定义SimpleRabbitListenerContainerFactory,设置其adviceChain属性为之前定义的RetryOperationsInterceptor来启用重试拦截器
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setAdviceChain(interceptor());
return factory;
}
//死信队列处理程序
@RabbitListener(queues = Consts.DEAD_QUEUE)
public void deadHandler(String data) {
log.error("got dead message {}", data);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
执行程序,发送两条消息,日志如下:
[11:22:02.193] [http-nio-45688-exec-1] [INFO ] [o.g.t.c.a.d.DeadLetterController:24 ] - send message msg1
[11:22:02.219] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg1
[11:22:02.614] [http-nio-45688-exec-2] [INFO ] [o.g.t.c.a.d.DeadLetterController:24 ] - send message msg2
[11:22:03.220] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg1
[11:22:05.221] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg1
[11:22:09.223] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg1
[11:22:17.224] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg1
[11:22:17.226] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [WARN ] [o.s.a.r.retry.RepublishMessageRecoverer:172 ] - Republishing failed message to exchange 'deadtest' with routing key deadtest
[11:22:17.227] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg2
[11:22:17.229] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#1-1] [ERROR] [o.g.t.c.a.deadletter.MQListener:20 ] - got dead message msg1
[11:22:18.232] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg2
[11:22:20.237] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg2
[11:22:24.241] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg2
[11:22:32.245] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.deadletter.MQListener:13 ] - got message msg2
[11:22:32.246] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [WARN ] [o.s.a.r.retry.RepublishMessageRecoverer:172 ] - Republishing failed message to exchange 'deadtest' with routing key deadtest
[11:22:32.250] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#1-1] [ERROR] [o.g.t.c.a.deadletter.MQListener:20 ] - got dead message msg2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
可以看到:
- msg1 的 4 次重试间隔分别是 1 秒、2 秒、4 秒、8 秒,再加上首次的失败,所以最大尝试次数是 5。
- 4 次重试后,RepublishMessageRecoverer 把消息发往了死信交换器。
- 死信处理程序输出了 got dead message 日志。
这里需要尤其注意的一点是,虽然我们几乎同时发送了两条消息,但是 msg2 是在 msg1 的四次重试全部结束后才开始处理。原因是,默认情况下 SimpleMessageListenerContainer 只有一个消费线程。可以通过增加消费线程来避免性能问题,如下我们直接设置 concurrentConsumers 参数为 10,来增加到 10 个工作线程:
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setAdviceChain(interceptor());
factory.setConcurrentConsumers(10);
return factory;
}
2
3
4
5
6
7
8
当然,我们也可以设置 maxConcurrentConsumers 参数,来让 SimpleMessageListenerContainer 自己动态地调整消费者线程数。不过,我们需要特别注意它的动态开启新线程的策略。你可以通过官方文档 (opens new window),来了解这个策略。
# 数据存储 NoSQL与RDBMS相辅相成
近几年,各种非关系型数据库,也就是 NoSQL 发展迅猛,在项目中也非常常见。其中不乏一些使用上的极端情况,比如直接把关系型数据库(RDBMS)全部替换为 NoSQL,或是在不合适的场景下错误地使用 NoSQL。
其实,每种 NoSQL 的特点不同,都有其要着重解决的某一方面的问题。因此,我们在使用 NoSQL 的时候,要尽量让它去处理擅长的场景,否则不但发挥不出它的功能和优势,还可能会导致性能问题。
NoSQL 一般可以分为缓存数据库、时间序列数据库、全文搜索数据库、文档数据库、图数据库等。以缓存数据库 Redis、时间序列数据库 InfluxDB、全文搜索数据库 ElasticSearch 为例,通过一些测试案例,聊聊这些常见 NoSQL 的特点,以及它们擅长和不擅长的地方。最后还会说说 NoSQL 如何与 RDBMS 相辅相成,来构成一套可以应对高并发的复合数据库体系。
# Redis vs MySQL
Redis 是一款设计简洁的缓存数据库,数据都保存在内存中,所以读写单一 Key 的性能非常高。
我们来做一个简单测试,分别填充 10 万条数据到 Redis 和 MySQL 中。MySQL 中的 name 字段做了索引,相当于 Redis 的 Key,data 字段为 100 字节的数据,相当于 Redis 的 Value:
@SpringBootApplication
@Slf4j
public class CommonMistakesApplication {
//模拟10万条数据存到Redis和MySQL
public static final int ROWS = 100000;
public static final String PAYLOAD = IntStream.rangeClosed(1, 100).mapToObj(__ -> "a").collect(Collectors.joining(""));
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StandardEnvironment standardEnvironment;
public static void main(String[] args) {
SpringApplication.run(CommonMistakesApplication.class, args);
}
@PostConstruct
public void init() {
//使用-Dspring.profiles.active=init启动程序进行初始化
if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase("init"))) {
initRedis();
initMySQL();
}
}
//填充数据到MySQL
private void initMySQL() {
//删除表
jdbcTemplate.execute("DROP TABLE IF EXISTS `r`;");
//新建表,name字段做了索引
jdbcTemplate.execute("CREATE TABLE `r` (\n" +
" `id` bigint(20) NOT NULL AUTO_INCREMENT,\n" +
" `data` varchar(2000) NOT NULL,\n" +
" `name` varchar(20) NOT NULL,\n" +
" PRIMARY KEY (`id`),\n" +
" KEY `name` (`name`) USING BTREE\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;");
//批量插入数据
String sql = "INSERT INTO `r` (`data`,`name`) VALUES (?,?)";
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
preparedStatement.setString(1, PAYLOAD);
preparedStatement.setString(2, "item" + i);
}
@Override
public int getBatchSize() {
return ROWS;
}
});
log.info("init mysql finished with count {}", jdbcTemplate.queryForObject("SELECT COUNT(*) FROM `r`", Long.class));
}
//填充数据到Redis
private void initRedis() {
IntStream.rangeClosed(1, ROWS).forEach(i -> stringRedisTemplate.opsForValue().set("item" + i, PAYLOAD));
log.info("init redis finished with count {}", stringRedisTemplate.keys("item*"));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
启动程序后,输出了如下日志,数据全部填充完毕:
[14:22:47.195] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:80 ] - init redis finished with count 100000
[14:22:50.030] [main] [INFO ] [o.g.t.c.n.r.CommonMistakesApplication:74 ] - init mysql finished with count 100000
2
然后,比较一下从 MySQL 和 Redis 随机读取单条数据的性能。“公平”起见,像 Redis 那样,我们使用 MySQL 时也根据 Key 来查 Value,也就是根据 name 字段来查 data 字段,并且我们给 name 字段做了索引:
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@GetMapping("redis")
public void redis() {
//使用随机的Key来查询Value,结果应该等于PAYLOAD
Assert.assertTrue(stringRedisTemplate.opsForValue().get("item" + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1)).equals(CommonMistakesApplication.PAYLOAD));
}
@GetMapping("mysql")
public void mysql() {
//根据随机name来查data,name字段有索引,结果应该等于PAYLOAD
Assert.assertTrue(jdbcTemplate.queryForObject("SELECT data FROM `r` WHERE name=?", new Object[]{("item" + (ThreadLocalRandom.current().nextInt(CommonMistakesApplication.ROWS) + 1))}, String.class)
.equals(CommonMistakesApplication.PAYLOAD));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
使用 wrk 加 10 个线程 50 个并发连接做压测。可以看到,MySQL 90% 的请求需要 61ms,QPS 为 1460;而 Redis 90% 的请求在 5ms 左右,QPS 达到了 14008,几乎是 MySQL 的十倍:

但 Redis 薄弱的地方是,不擅长做 Key 的搜索。对 MySQL 我们可以使用 LIKE 操作前匹配走 B+ 树索引实现快速搜索;但对 Redis,我们使用 Keys 命令对 Key 的搜索,其实相当于在 MySQL 里做全表扫描。
写一段代码来对比一下性能:
@GetMapping("redis2")
public void redis2() {
Assert.assertTrue(stringRedisTemplate.keys("item71*").size() == 1111);
}
@GetMapping("mysql2")
public void mysql2() {
Assert.assertTrue(jdbcTemplate.queryForList("SELECT name FROM `r` WHERE name LIKE 'item71%'", String.class).size() == 1111);
}
2
3
4
5
6
7
8
可以看到,在 QPS 方面,MySQL 的 QPS 达到了 Redis 的 157 倍;在延迟方面,MySQL 的延迟只有 Redis 的十分之一。

Redis 慢的原因有两个:
- Redis 的 Keys 命令是 O(n) 时间复杂度。如果数据库中 Key 的数量很多,就会非常慢。
- Redis 是单线程的,对于慢的命令如果有并发,串行执行就会非常耗时。
一般而言,我们使用 Redis 都是针对某一个 Key 来使用,而不能在业务代码中使用 Keys 命令从 Redis 中“搜索数据”,因为这不是 Redis 的擅长。对于 Key 的搜索,我们可以先通过关系型数据库进行,然后再从 Redis 存取数据(如果实在需要搜索 Key 可以使用 SCAN 命令)。在生产环境中,我们一般也会配置 Redis 禁用类似 Keys 这种比较危险的命令,你可以参考这里 (opens new window)。
总结一下,对于业务开发来说,大多数业务场景下 Redis 是作为关系型数据库的辅助用于缓存的,我们一般不会把它当作数据库独立使用。
此外值得一提的是,Redis 提供了丰富的数据结构(Set、SortedSet、Hash、List),并围绕这些数据结构提供了丰富的 API。如果我们好好利用这个特点的话,可以直接在 Redis 中完成一部分服务端计算,避免“读取缓存 -> 计算数据 -> 保存缓存”三部曲中的读取和保存缓存的开销,进一步提高性能。
# 取InfluxDB vs MySQL
InfluxDB 是一款优秀的时序数据库。之前讲的使用指标 Metrics 快速定位问题就是使用 InfluxDB 来做的 Metrics 打点。时序数据库的优势,在于处理指标数据的聚合,并且读写效率非常高。
同样的,我们使用一些测试来对比下 InfluxDB 和 MySQL 的性能。
在如下代码中,我们分别填充了 1000 万条数据到 MySQL 和 InfluxDB 中。其中,每条数据只有 ID、时间戳、10000 以内的随机值这 3 列信息,对于 MySQL 我们把时间戳列做了索引:
@SpringBootApplication
@Slf4j
public class CommonMistakesApplication {
public static void main(String[] args) {
SpringApplication.run(CommonMistakesApplication.class, args);
}
//测试数据量
public static final int ROWS = 10000000;
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private StandardEnvironment standardEnvironment;
@PostConstruct
public void init() {
//使用-Dspring.profiles.active=init启动程序进行初始化
if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase("init"))) {
initInfluxDB();
initMySQL();
}
}
//初始化MySQL
private void initMySQL() {
long begin = System.currentTimeMillis();
jdbcTemplate.execute("DROP TABLE IF EXISTS `m`;");
//只有ID、值和时间戳三列
jdbcTemplate.execute("CREATE TABLE `m` (\n" +
" `id` bigint(20) NOT NULL AUTO_INCREMENT,\n" +
" `value` bigint NOT NULL,\n" +
" `time` timestamp NOT NULL,\n" +
" PRIMARY KEY (`id`),\n" +
" KEY `time` (`time`) USING BTREE\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;");
String sql = "INSERT INTO `m` (`value`,`time`) VALUES (?,?)";
//批量插入数据
jdbcTemplate.batchUpdate(sql, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement preparedStatement, int i) throws SQLException {
preparedStatement.setLong(1, ThreadLocalRandom.current().nextInt(10000));
preparedStatement.setTimestamp(2, Timestamp.valueOf(LocalDateTime.now().minusSeconds(5 * i)));
}
@Override
public int getBatchSize() {
return ROWS;
}
});
log.info("init mysql finished with count {} took {}ms", jdbcTemplate.queryForObject("SELECT COUNT(*) FROM `m`", Long.class), System.currentTimeMillis()-begin);
}
//初始化InfluxDB
private void initInfluxDB() {
long begin = System.currentTimeMillis();
OkHttpClient.Builder okHttpClientBuilder = new OkHttpClient().newBuilder()
.connectTimeout(1, TimeUnit.SECONDS)
.readTimeout(10, TimeUnit.SECONDS)
.writeTimeout(10, TimeUnit.SECONDS);
try (InfluxDB influxDB = InfluxDBFactory.connect("http://127.0.0.1:8086", "root", "root", okHttpClientBuilder)) {
String db = "performance";
influxDB.query(new Query("DROP DATABASE " + db));
influxDB.query(new Query("CREATE DATABASE " + db));
//设置数据库
influxDB.setDatabase(db);
//批量插入,10000条数据刷一次,或1秒刷一次
influxDB.enableBatch(BatchOptions.DEFAULTS.actions(10000).flushDuration(1000));
IntStream.rangeClosed(1, ROWS).mapToObj(i -> Point
.measurement("m")
.addField("value", ThreadLocalRandom.current().nextInt(10000))
.time(LocalDateTime.now().minusSeconds(5 * i).toInstant(ZoneOffset.UTC).toEpochMilli(), TimeUnit.MILLISECONDS).build())
.forEach(influxDB::write);
influxDB.flush();
log.info("init influxdb finished with count {} took {}ms", influxDB.query(new Query("SELECT COUNT(*) FROM m")).getResults().get(0).getSeries().get(0).getValues().get(0).get(1), System.currentTimeMillis()-begin);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
启动后,程序输出了如下日志:
[16:08:25.062] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:104 ] - init influxdb finished with count 1.0E7 took 54280ms
[16:11:50.462] [main] [INFO ] [o.g.t.c.n.i.CommonMistakesApplication:80 ] - init mysql finished with count 10000000 took 205394ms
2
InfluxDB 批量插入 1000 万条数据仅用了 54 秒,相当于每秒插入 18 万条数据,速度相当快;MySQL 的批量插入,速度也挺快达到了每秒 4.8 万。
接下来,我们测试一下。
对这 1000 万数据进行一个统计,查询最近 60 天的数据,按照 1 小时的时间粒度聚合,统计 value 列的最大值、最小值和平均值,并将统计结果绘制成曲线图:
@Autowired
private JdbcTemplate jdbcTemplate;
@GetMapping("mysql")
public void mysql() {
long begin = System.currentTimeMillis();
//使用SQL从MySQL查询,按照小时分组
Object result = jdbcTemplate.queryForList("SELECT date_format(time,'%Y%m%d%H'),max(value),min(value),avg(value) FROM m WHERE time>now()- INTERVAL 60 DAY GROUP BY date_format(time,'%Y%m%d%H')");
log.info("took {} ms result {}", System.currentTimeMillis() - begin, result);
}
@GetMapping("influxdb")
public void influxdb() {
long begin = System.currentTimeMillis();
try (InfluxDB influxDB = InfluxDBFactory.connect("http://127.0.0.1:8086", "root", "root")) {
//切换数据库
influxDB.setDatabase("performance");
//InfluxDB的查询语法InfluxQL类似SQL
Object result = influxDB.query(new Query("SELECT MEAN(value),MIN(value),MAX(value) FROM m WHERE time > now() - 60d GROUP BY TIME(1h)"));
log.info("took {} ms result {}", System.currentTimeMillis() - begin, result);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
因为数据量非常大,单次查询就已经很慢了,所以这次我们不进行压测。分别调用两个接口,可以看到 MySQL 查询一次耗时 29 秒左右,而 InfluxDB 耗时 980ms:
[16:19:26.562] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.n.i.PerformanceController:31 ] - took 28919 ms result [{date_format(time,'%Y%m%d%H')=2019121308, max(value)=9993, min(value)=4, avg(value)=5129.5639}, {date_format(time,'%Y%m%d%H')=2019121309, max(value)=9990, min(value)=12, avg(value)=4856.0556}, {date_format(time,'%Y%m%d%H')=2019121310, max(value)=9998, min(value)=8, avg(value)=4948.9347}, {date_format(time,'%Y%m%d%H')...
[16:20:08.170] [http-nio-45678-exec-6] [INFO ] [o.g.t.c.n.i.PerformanceController:40 ] - took 981 ms result QueryResult [results=[Result [series=[Series [name=m, tags=null, columns=[time, mean, min, max], values=[[2019-12-13T08:00:00Z, 5249.2468619246865, 21.0, 9992.0],...
2
在按照时间区间聚合的案例上,我们看到了 InfluxDB 的性能优势。但我们肯定不能把 InfluxDB 当作普通数据库,原因是:
- InfluxDB 不支持数据更新操作,毕竟时间数据只能随着时间产生新数据,肯定无法对过去的数据做修改;
- 从数据结构上说,时间序列数据数据没有单一的主键标识,必须包含时间戳,数据只能和时间戳进行关联,不适合普通业务数据。
此外需要注意,即便只是使用 InfluxDB 保存和时间相关的指标数据,我们也要注意不能滥用 tag。
InfluxDB 提供的 tag 功能,可以为每一个指标设置多个标签,并且 tag 有索引,可以对 tag 进行条件搜索或分组。但是,tag 只能保存有限的、可枚举的标签,不能保存 URL 等信息,否则可能会出现 high series cardinality (opens new window) 问题,导致占用大量内存,甚至是 OOM。可以点击这里 (opens new window),查看 series 和内存占用的关系。对于 InfluxDB,我们无法把 URL 这种原始数据保存到数据库中,只能把数据进行归类,形成有限的 tag 进行保存。
总结一下,对于 MySQL 而言,针对大量的数据使用全表扫描的方式来聚合统计指标数据,性能非常差,一般只能作为临时方案来使用。此时,引入 InfluxDB 之类的时间序列数据库,就很有必要了。时间序列数据库可以作为特定场景(比如监控、统计)的主存储,也可以和关系型数据库搭配使用,作为一个辅助数据源,保存业务系统的指标数据。
# Elasticsearch vs MySQL
Elasticsearch(以下简称 ES),是目前非常流行的分布式搜索和分析数据库,独特的倒排索引结构尤其适合进行全文搜索。
简单来讲,倒排索引可以认为是一个 Map,其 Key 是分词之后的关键字,Value 是文档 ID/ 片段 ID 的列表。我们只要输入需要搜索的单词,就可以直接在这个 Map 中得到所有包含这个单词的文档 ID/ 片段 ID 列表,然后再根据其中的文档 ID/ 片段 ID 查询出实际的文档内容。
我们来测试一下,对比下使用 ES 进行关键字全文搜索、在 MySQL 中使用 LIKE 进行搜索的效率差距。
首先,定义一个实体 News,包含新闻分类、标题、内容等字段。这个实体同时会用作 Spring Data JPA 和 Spring Data Elasticsearch 的实体:
@Entity
@Document(indexName = "news", replicas = 0) //@Document注解定义了这是一个ES的索引,索引名称news,数据不需要冗余
@Table(name = "news", indexes = {@Index(columnList = "cateid")}) //@Table注解定义了这是一个MySQL表,表名news,对cateid列做索引
@Data
@AllArgsConstructor
@NoArgsConstructor
@DynamicUpdate
public class News {
@Id
private long id;
@Field(type = FieldType.Keyword)
private String category;//新闻分类名称
private int cateid;//新闻分类ID
@Column(columnDefinition = "varchar(500)")//@Column注解定义了在MySQL中字段,比如这里定义title列的类型是varchar(500)
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")//@Field注解定义了ES字段的格式,使用ik分词器进行分词
private String title;//新闻标题
@Column(columnDefinition = "text")
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String content;//新闻内容
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
接下来,我们实现主程序。在启动时,我们会从一个 csv 文件中加载 4000 条新闻数据,然后复制 100 份,拼成 40 万条数据,分别写入 MySQL 和 ES:
@SpringBootApplication
@Slf4j
@EnableElasticsearchRepositories(includeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, value = NewsESRepository.class)) //明确设置哪个是ES的Repository
@EnableJpaRepositories(excludeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, value = NewsESRepository.class)) //其他的是MySQL的Repository
public class CommonMistakesApplication {
public static void main(String[] args) {
Utils.loadPropertySource(CommonMistakesApplication.class, "es.properties");
SpringApplication.run(CommonMistakesApplication.class, args);
}
@Autowired
private StandardEnvironment standardEnvironment;
@Autowired
private NewsESRepository newsESRepository;
@Autowired
private NewsMySQLRepository newsMySQLRepository;
@PostConstruct
public void init() {
//使用-Dspring.profiles.active=init启动程序进行初始化
if (Arrays.stream(standardEnvironment.getActiveProfiles()).anyMatch(s -> s.equalsIgnoreCase("init"))) {
//csv中的原始数据只有4000条
List<News> news = loadData();
AtomicLong atomicLong = new AtomicLong();
news.forEach(item -> item.setTitle("%%" + item.getTitle()));
//我们模拟100倍的数据量,也就是40万条
IntStream.rangeClosed(1, 100).forEach(repeat -> {
news.forEach(item -> {
//重新设置主键ID
item.setId(atomicLong.incrementAndGet());
//每次复制数据稍微改一下title字段,在前面加上一个数字,代表这是第几次复制
item.setTitle(item.getTitle().replaceFirst("%%", String.valueOf(repeat)));
});
initMySQL(news, repeat == 1);
log.info("init MySQL finished for {}", repeat);
initES(news, repeat == 1);
log.info("init ES finished for {}", repeat);
});
}
}
//从news.csv中解析得到原始数据
private List<News> loadData() {
//使用jackson-dataformat-csv实现csv到POJO的转换
CsvMapper csvMapper = new CsvMapper();
CsvSchema schema = CsvSchema.emptySchema().withHeader();
ObjectReader objectReader = csvMapper.readerFor(News.class).with(schema);
ClassLoader classLoader = getClass().getClassLoader();
File file = new File(classLoader.getResource("news.csv").getFile());
try (Reader reader = new FileReader(file)) {
return objectReader.<News>readValues(reader).readAll();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
//把数据保存到ES中
private void initES(List<News> news, boolean clear) {
if (clear) {
//首次调用的时候先删除历史数据
newsESRepository.deleteAll();
}
newsESRepository.saveAll(news);
}
//把数据保存到MySQL中
private void initMySQL(List<News> news, boolean clear) {
if (clear) {
//首次调用的时候先删除历史数据
newsMySQLRepository.deleteAll();
}
newsMySQLRepository.saveAll(news);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
由于我们使用了 Spring Data,直接定义两个 Repository,然后直接定义查询方法,无需实现任何逻辑即可实现查询,Spring Data 会根据方法名生成相应的 SQL 语句和 ES 查询 DSL,其中 ES 的翻译逻辑详见这里 (opens new window)。
在这里,我们定义一个 countByCateidAndContentContainingAndContentContaining 方法,代表查询条件是:搜索分类等于 cateid 参数,且内容同时包含关键字 keyword1 和 keyword2,计算符合条件的新闻总数量:
@Repository
public interface NewsMySQLRepository extends JpaRepository<News, Long> {
//JPA:搜索分类等于cateid参数,且内容同时包含关键字keyword1和keyword2,计算符合条件的新闻总数量
long countByCateidAndContentContainingAndContentContaining(int cateid, String keyword1, String keyword2);
}
@Repository
public interface NewsESRepository extends ElasticsearchRepository<News, Long> {
//ES:搜索分类等于cateid参数,且内容同时包含关键字keyword1和keyword2,计算符合条件的新闻总数量
long countByCateidAndContentContainingAndContentContaining(int cateid, String keyword1, String keyword2);
}
2
3
4
5
6
7
8
9
10
11
对于 ES 和 MySQL,我们使用相同的条件进行搜索,搜素分类是 1,关键字是社会和苹果,然后输出搜索结果和耗时:
//测试MySQL搜索,最后输出耗时和结果
@GetMapping("mysql")
public void mysql(@RequestParam(value = "cateid", defaultValue = "1") int cateid,
@RequestParam(value = "keyword1", defaultValue = "社会") String keyword1,
@RequestParam(value = "keyword2", defaultValue = "苹果") String keyword2) {
long begin = System.currentTimeMillis();
Object result = newsMySQLRepository.countByCateidAndContentContainingAndContentContaining(cateid, keyword1, keyword2);
log.info("took {} ms result {}", System.currentTimeMillis() - begin, result);
}
//测试ES搜索,最后输出耗时和结果
@GetMapping("es")
public void es(@RequestParam(value = "cateid", defaultValue = "1") int cateid,
@RequestParam(value = "keyword1", defaultValue = "社会") String keyword1,
@RequestParam(value = "keyword2", defaultValue = "苹果") String keyword2) {
long begin = System.currentTimeMillis();
Object result = newsESRepository.countByCateidAndContentContainingAndContentContaining(cateid, keyword1, keyword2);
log.info("took {} ms result {}", System.currentTimeMillis() - begin, result);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
分别调用接口可以看到,ES 耗时仅仅 48ms,MySQL 耗时 6 秒多是 ES 的 100 倍。很遗憾,虽然新闻分类 ID 已经建了索引,但是这个索引只能起到加速过滤分类 ID 这一单一条件的作用,对于文本内容的全文搜索,B+ 树索引无能为力。
[22:04:00.951] [http-nio-45678-exec-6] [INFO ] [o.g.t.c.n.esvsmyql.PerformanceController:48 ] - took 48 ms result 2100
Hibernate: select count(news0_.id) as col_0_0_ from news news0_ where news0_.cateid=? and (news0_.content like ? escape ?) and (news0_.content like ? escape ?)
[22:04:11.946] [http-nio-45678-exec-7] [INFO ] [o.g.t.c.n.esvsmyql.PerformanceController:39 ] - took 6637 ms result 2100
2
3
但 ES 这种以索引为核心的数据库,也不是万能的,频繁更新就是一个大问题。
MySQL 可以做到仅更新某行数据的某个字段,但 ES 里每次数据字段更新都相当于整个文档索引重建。即便 ES 提供了文档部分更新的功能,但本质上只是节省了提交文档的网络流量,以及减少了更新冲突,其内部实现还是文档删除后重新构建索引。因此,如果要在 ES 中保存一个类似计数器的值,要实现不断更新,其执行效率会非常低。
我们来验证下,分别使用 JdbcTemplate+SQL 语句、ElasticsearchTemplate+ 自定义 UpdateQuery,实现部分更新 MySQL 表和 ES 索引的一个字段,每个方法都是循环更新 1000 次:
@GetMapping("mysql2")
public void mysql2(@RequestParam(value = "id", defaultValue = "400000") long id) {
long begin = System.currentTimeMillis();
//对于MySQL,使用JdbcTemplate+SQL语句,实现直接更新某个category字段,更新1000次
IntStream.rangeClosed(1, 1000).forEach(i -> {
jdbcTemplate.update("UPDATE `news` SET category=? WHERE id=?", new Object[]{"test" + i, id});
});
log.info("mysql took {} ms result {}", System.currentTimeMillis() - begin, newsMySQLRepository.findById(id));
}
@GetMapping("es2")
public void es(@RequestParam(value = "id", defaultValue = "400000") long id) {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, 1000).forEach(i -> {
//对于ES,通过ElasticsearchTemplate+自定义UpdateQuery,实现文档的部分更新
UpdateQuery updateQuery = null;
try {
updateQuery = new UpdateQueryBuilder()
.withIndexName("news")
.withId(String.valueOf(id))
.withType("_doc")
.withUpdateRequest(new UpdateRequest().doc(
jsonBuilder()
.startObject()
.field("category", "test" + i)
.endObject()))
.build();
} catch (IOException e) {
e.printStackTrace();
}
elasticsearchTemplate.update(updateQuery);
});
log.info("es took {} ms result {}", System.currentTimeMillis() - begin, newsESRepository.findById(id).get());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
可以看到,MySQL 耗时仅仅 1.5 秒,而 ES 耗时 6.8 秒:

ES 是一个分布式的全文搜索数据库,所以与 MySQL 相比的优势在于文本搜索,而且因为其分布式的特性,可以使用一个大 ES 集群处理大规模数据的内容搜索。但由于 ES 的索引是文档维度的,所以不适用于频繁更新的 OLTP 业务。
一般而言,我们会把 ES 和 MySQL 结合使用,MySQL 直接承担业务系统的增删改操作,而 ES 作为辅助数据库,直接扁平化保存一份业务数据,用于复杂查询、全文搜索和统计。
# 结合 NoSQL 和 MySQL 应对高并发的复合数据库架构
现在,我们通过一些案例看到了 Redis、InfluxDB、ES 这些 NoSQL 数据库,都有擅长和不擅长的场景。每一个存储系统都有其独特的数据结构,数据结构的设计就决定了其擅长和不擅长的场景。
比如 MySQL InnoDB 引擎的 B+ 树对排序和范围查询友好,频繁数据更新的代价不是太大,因此适合 OLTP(On-Line Transaction Processing)。
又比如 ES 的 Lucene 采用了 FST(Finite State Transducer)索引 + 倒排索引,空间效率高,适合对变动不频繁的数据做索引,实现全文搜索。存储系统本身不可能对一份数据使用多种数据结构保存,因此不可能适用于所有场景。
虽然在大多数业务场景下,MySQL 的性能都不算太差,但对于数据量大、访问量大、业务复杂的互联网应用来说,MySQL 因为实现了 ACID(原子性、一致性、隔离性、持久性)会比较重,而且横向扩展能力较差、功能单一,无法扛下所有数据量和流量,无法应对所有功能需求。因此,我们需要通过架构手段,来组合使用多种存储系统,取长补短,实现 1+1>2 的效果。
举个例子,我们设计了一个包含多个数据库系统的、能应对各种高并发场景的一套数据服务的系统架构,其中包含了同步写服务、异步写服务和查询服务三部分,分别实现主数据库写入、辅助数据库写入和查询路由。
我们按照服务来依次分析下这个架构。
首先要明确的是,重要的业务主数据只能保存在 MySQL 这样的关系型数据库中,原因有三点:
- RDBMS 经过了几十年的验证,已经非常成熟;
- RDBMS 的用户数量众多,Bug 修复快、版本稳定、可靠性很高;
- RDBMS 强调 ACID,能确保数据完整。
有两种类型的查询任务可以交给 MySQL 来做,性能会比较好,这也是 MySQL 擅长的地方:
- 按照主键 ID 的查询。直接查询聚簇索引,其性能会很高。但是单表数据量超过亿级后,性能也会衰退,而且单个数据库无法承受超大的查询并发,因此我们可以把数据表进行 Sharding 操作,均匀拆分到多个数据库实例中保存。我们把这套数据库集群称作 Sharding 集群。
- 按照各种条件进行范围查询,查出主键 ID。对二级索引进行查询得到主键,只需要查询一棵 B+ 树,效率同样很高。但索引的值不宜过大,比如对 varchar(1000) 进行索引不太合适,而索引外键(一般是 int 或 bigint 类型)性能就会比较好。因此,我们可以在 MySQL 中建立一张“索引表”,除了保存主键外,主要是保存各种关联表的外键,以及尽可能少的 varchar 类型的字段。这张索引表的大部分列都可以建上二级索引,用于进行简单搜索,搜索的结果是主键的列表,而不是完整的数据。由于索引表字段轻量并且数量不多(一般控制在 10 个以内),所以即便索引表没有进行 Sharding 拆分,问题也不会很大。
如图上蓝色线所示,写入两种 MySQL 数据表和发送 MQ 消息的这三步,我们用一个同步写服务完成了。主数据由两种 MySQL 数据表构成,其中索引表承担简单条件的搜索来得到主键,Sharding 表承担大并发的主键查询。主数据由同步写服务写入,写入后发出 MQ 消息。在“异步处理”中提到,所有异步流程都需要补偿,这里的异步流程同样需要。只不过为了简洁,在这里省略了补偿流程。
然后,如图中绿色线所示,有一个异步写服务,监听 MQ 的消息,继续完成辅助数据的更新操作。这里我们选用了 ES 和 InfluxDB 这两种辅助数据库,因此整个异步写数据操作有三步:
- MQ 消息不一定包含完整的数据,甚至可能只包含一个最新数据的主键 ID,我们需要根据 ID 从查询服务查询到完整的数据。
- 写入 InfluxDB 的数据一般可以按时间间隔进行简单聚合,定时写入 InfluxDB。因此,这里会进行简单的客户端聚合,然后写入 InfluxDB。
- ES 不适合在各索引之间做连接(Join)操作,适合保存扁平化的数据。比如,我们可以把订单下的用户、商户、商品列表等信息,作为内嵌对象嵌入整个订单 JSON,然后把整个扁平化的 JSON 直接存入 ES。
对于数据写入操作,我们认为操作返回的时候同步数据一定是写入成功的,但是由于各种原因,异步数据写入无法确保立即成功,会有一定延迟,比如:
- 异步消息丢失的情况,需要补偿处理;
- 写入 ES 的索引操作本身就会比较慢;
- 写入 InfluxDB 的数据需要客户端定时聚合。
因此,对于查询服务,如图中红色线所示,我们需要根据一定的上下文条件(比如查询一致性要求、时效性要求、搜索的条件、需要返回的数据字段、搜索时间区间等)来把请求路由到合适的数据库,并且做一些聚合处理:
- 需要根据主键查询单条数据,可以从 MySQL Sharding 集群或 Redis 查询,如果对实时性要求不高也可以从 ES 查询。
- 按照多个条件搜索订单的场景,可以从 MySQL 索引表查询出主键列表,然后再根据主键从 MySQL Sharding 集群或 Redis 获取数据详情。
- 各种后台系统需要使用比较复杂的搜索条件,甚至全文搜索来查询订单数据,或是定时分析任务需要一次查询大量数据,这些场景对数据实时性要求都不高,可以到 ES 进行搜索。此外,MySQL 中的数据可以归档,我们可以在 ES 中保留更久的数据,而且查询历史数据一般并发不会很大,可以统一路由到 ES 查询。
- 监控系统或后台报表系统需要呈现业务监控图表或表格,可以把请求路由到 InfluxDB 查询。
# 问题解答
问题 1:除了模板方法设计模式是减少重复代码的一把好手,观察者模式也常用于减少代码重复(并且是松耦合方式),Spring 也提供了类似工具(点击这里 (opens new window)查看),你能想到观察者模式有哪些应用场景吗?
答:其实,和使用 MQ 来解耦系统和系统的调用类似,应用内各个组件之间的调用也可以使用观察者模式来解耦,特别是当你的应用是一个大单体的时候。观察者模式除了是让组件之间可以更松耦合,还能更有利于消除重复代码。
其原因是,对于一个复杂的业务逻辑,里面必然涉及到大量其它组件的调用,虽然我们没有重复写这些组件内部处理逻辑的代码,但是这些复杂调用本身就构成了重复代码。
我们可以考虑把代码逻辑抽象一下,抽象出许多事件,围绕这些事件来展开处理,那么这种处理模式就从“命令式”变为了“环境感知式”,每一个组件就好像活在一个场景中,感知场景中的各种事件,然后又把发出处理结果作为另一个事件。
经过这种抽象,复杂组件之间的调用逻辑就变成了“事件抽象 + 事件发布 + 事件订阅”,整个代码就会更简化。
补充说明一下,除了观察者模式我们还经常听到发布订阅模式,那么它们有什么区别呢?
其实,观察者模式也可以叫做发布订阅模式。不过在严格定义上,前者属于松耦合,后者必须要 MQ Broker 的介入,实现发布者订阅者的完全解耦。
问题 2:关于 Bean 属性复制工具,除了最简单的 Spring 的 BeanUtils 工具类的使用,你还知道哪些对象映射类库吗?它们又有什么功能呢?
答:在众多对象映射工具中,MapStruct (opens new window) 更具特色一点。它基于 JSR 269 的 Java 注解处理器实现(你可以理解为,它是编译时的代码生成器),使用的是纯 Java 方法而不是反射进行属性赋值,并且做到了编译时类型安全。
如果你使用 IDEA 的话,可以进一步安装 IDEA MapStruct Support (opens new window) 插件,实现映射配置的自动完成、跳转到定义等功能。关于这个插件的具体功能,你可以参考这里 (opens new window)。
问题 3:在“接口的响应要明确表示接口的处理结果”这一节的例子中,接口响应结构体中的 code 字段代表执行结果的错误码,对于业务特别复杂的接口,可能会有很多错误情况,code 可能会有几十甚至几百个。客户端开发人员需要根据每一种错误情况逐一写 if-else 进行不同交互处理,会非常麻烦,你觉得有什么办法来改进吗?作为服务端,是否有必要告知客户端接口执行的错误码呢?
答:服务端把错误码反馈给客户端有两个目的,一是客户端可以展示错误码方便排查问题,二是客户端可以根据不同的错误码来做交互区分。
对于第一点方便客户端排查问题,服务端应该进行适当的收敛和规整错误码,而不是把服务内可能遇到的、来自各个系统各个层次的错误码,一股脑地扔给客户端提示给用户。
建议开发一个错误码服务来专门治理错误码,实现错误码的转码、分类和收敛逻辑,甚至可以开发后台,让产品来录入需要的错误码提示消息。
此外,还建议错误码由一定的规则构成,比如错误码第一位可以是错误类型(比如 A 表示错误来源于用户;B 表示错误来源于当前系统,往往是业务逻辑出错,或程序健壮性差等问题;C 表示错误来源于第三方服务),第二、第三位可以是错误来自的系统编号(比如 01 来自用户服务,02 来自商户服务等等),后面三位是自增错误码 ID。
对于第二点对不同错误码的交互区分,更好的做法是服务端驱动模式,让服务端告知客户端如何处理,说白了就是客户端只需要照做即可,不需要感知错误码的含义(即便客户端显示错误码,也只是用于排错)。
比如,服务端的返回可以包含 actionType 和 actionInfo 两个字段,前者代表客户端应该做的交互动作,后者代表客户端完成这个交互动作需要的信息。其中,actionType 可以是 toast(无需确认的消息提示)、alert(需要确认的弹框提示)、redirectView(转到另一个视图)、redirectWebView(打开 Web 视图)等;actionInfo 就是 toast 的信息、alert 的信息、redirect 的 URL 等。
由服务端来明确客户端在请求 API 后的交互行为,主要的好处是灵活和统一两个方面。
- 灵活在于两个方面:第一,在紧急的时候还可以通过 redirect 方式进行救急。比如,遇到特殊情况需要紧急进行逻辑修改的情况时,我们可以直接在不发版的情况下切换到 H5 实现。第二是,我们可以提供后台,让产品或运营来配置交互的方式和信息(而不是改交互,改提示还需要客户端发版)。
- 统一:有的时候会遇到不同的客户端(比如 iOS、Android、前端),对于交互的实现不统一的情况,如果 API 结果可以规定这部分内容,那就可以彻底避免这个问题。
问题 4:在“要考虑接口变迁的版本控制策略”这一节的例子中,我们在类或方法上标记 @APIVersion 自定义注解,实现了 URL 方式统一的接口版本定义。你可以用类似的方式(也就是自定义 RequestMappingHandlerMapping),来实现一套统一的基于请求头方式的版本控制吗?
答:主要原理是,定义自己的 RequestCondition 来做请求头的匹配:
public class APIVersionCondition implements RequestCondition<APIVersionCondition> { @Getter private String apiVersion; @Getter private String headerKey; public APIVersionCondition(String apiVersion, String headerKey) { this.apiVersion = apiVersion; this.headerKey = headerKey; } @Override public APIVersionCondition combine(APIVersionCondition other) { return new APIVersionCondition(other.getApiVersion(), other.getHeaderKey()); } @Override public APIVersionCondition getMatchingCondition(HttpServletRequest request) { String version = request.getHeader(headerKey); return apiVersion.equals(version) ? this : null; } @Override public int compareTo(APIVersionCondition other, HttpServletRequest request) { return 0; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28并且自定义 RequestMappingHandlerMapping,来把方法关联到自定义的 RequestCondition:
public class APIVersionHandlerMapping extends RequestMappingHandlerMapping { @Override protected boolean isHandler(Class<?> beanType) { return AnnotatedElementUtils.hasAnnotation(beanType, Controller.class); } @Override protected RequestCondition<APIVersionCondition> getCustomTypeCondition(Class<?> handlerType) { APIVersion apiVersion = AnnotationUtils.findAnnotation(handlerType, APIVersion.class); return createCondition(apiVersion); } @Override protected RequestCondition<APIVersionCondition> getCustomMethodCondition(Method method) { APIVersion apiVersion = AnnotationUtils.findAnnotation(method, APIVersion.class); return createCondition(apiVersion); } private RequestCondition<APIVersionCondition> createCondition(APIVersion apiVersion) { return apiVersion == null ? null : new APIVersionCondition(apiVersion.value(), apiVersion.headerKey()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22问题 5:在聊到缓存并发问题时,我们说到热点 Key 回源会对数据库产生的压力问题,如果 Key 特别热的话,可能缓存系统也无法承受,毕竟所有的访问都集中打到了一台缓存服务器。如果我们使用 Redis 来做缓存,那可以把一个热点 Key 的缓存查询压力,分散到多个 Redis 节点上吗?
答:Redis 4.0 以上如果开启了 LFU 算法作为 maxmemory-policy,那么可以使用–hotkeys 配合 redis-cli 命令行工具来探查热点 Key。此外,我们还可以通过 MONITOR 命令来收集 Redis 执行的所有命令,然后配合 redis-faina (opens new window) 工具来分析热点 Key、热点前缀等信息。
对于如何分散热点 Key 对于 Redis 单节点的压力的问题,我们可以考虑为 Key 加上一定范围的随机数作为后缀,让一个 Key 变为多个 Key,相当于对热点 Key 进行分区操作。
当然,除了分散 Redis 压力之外,我们也可以考虑再做一层短时间的本地缓存,结合 Redis 的 Keyspace 通知功能,来处理本地缓存的数据同步。
问题 6:大 Key 也是数据缓存容易出现的一个问题。如果一个 Key 的 Value 特别大,那么可能会对 Redis 产生巨大的性能影响,因为 Redis 是单线程模型,对大 Key 进行查询或删除等操作,可能会引起 Redis 阻塞甚至是高可用切换。你知道怎么查询 Redis 中的大 Key,以及如何在设计上实现大 Key 的拆分吗?
答:Redis 的大 Key 可能会导致集群内存分布不均问题,并且大 Key 的操作可能也会产生阻塞。
关于查询 Redis 中的大 Key,我们可以使用 redis-cli --bigkeys 命令来实时探查大 Key。此外,我们还可以使用 redis-rdb-tools 工具来分析 Redis 的 RDB 快照,得到包含 Key 的字节数、元素个数、最大元素长度等信息的 CSV 文件。然后,我们可以把这个 CSV 文件导入 MySQL 中,写 SQL 去分析。
针对大 Key,我们可以考虑两方面的优化:
- 第一,是否有必要在 Redis 保存这么多数据。一般情况下,我们在缓存系统中保存面向呈现的数据,而不是原始数据;对于原始数据的计算,我们可以考虑其它文档型或搜索型的 NoSQL 数据库。
- 第二,考虑把具有二级结构的 Key(比如 List、Set、Hash)拆分成多个小 Key,来独立获取(或是用 MGET 获取)。
此外值得一提的是,大 Key 的删除操作可能会产生较大性能问题。从 Redis 4.0 开始,我们可以使用 UNLINK 命令而不是 DEL 命令在后台删除大 Key;而对于 4.0 之前的版本,我们可以考虑使用游标删除大 Key 中的数据,而不是直接使用 DEL 命令,比如对于 Hash 使用 HSCAN+HDEL 结合管道功能来删除。
问题 7:Spring Boot Actuator 提供了大量内置端点,你觉得端点和自定义一个 @RestController 有什么区别呢?你能否根据官方文档 (opens new window),开发一个自定义端点呢?
答:Endpoint 是 Spring Boot Actuator 抽象出来的一个概念,主要用于监控和配置。使用 @Endpoint 注解自定义端点,配合方法上的 @ReadOperation、@WriteOperation、@DeleteOperation 注解,分分钟就可以开发出自动通过 HTTP 或 JMX 进行暴露的监控点。
如果只希望通过 HTTP 暴露的话,可以使用 @WebEndpoint 注解;如果只希望通过 JMX 暴露的话,可以使用 @JmxEndpoint 注解。
而使用 @RestController 一般用于定义业务接口,如果数据需要暴露到 JMX 的话需要手动开发。
比如,下面这段代码展示了如何定义一个累加器端点,提供了读取操作和累加两个操作:
@Endpoint(id = "adder") @Component public class TestEndpoint { private static AtomicLong atomicLong = new AtomicLong(); //读取值 @ReadOperation public String get() { return String.valueOf(atomicLong.get()); } //累加值 @WriteOperation public String increment() { return String.valueOf(atomicLong.incrementAndGet()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15然后,我们可以通过 HTTP 或 JMX 来操作这个累加器。这样,我们就实现了一个自定义端点,并且可以通过 JMX 来操作:
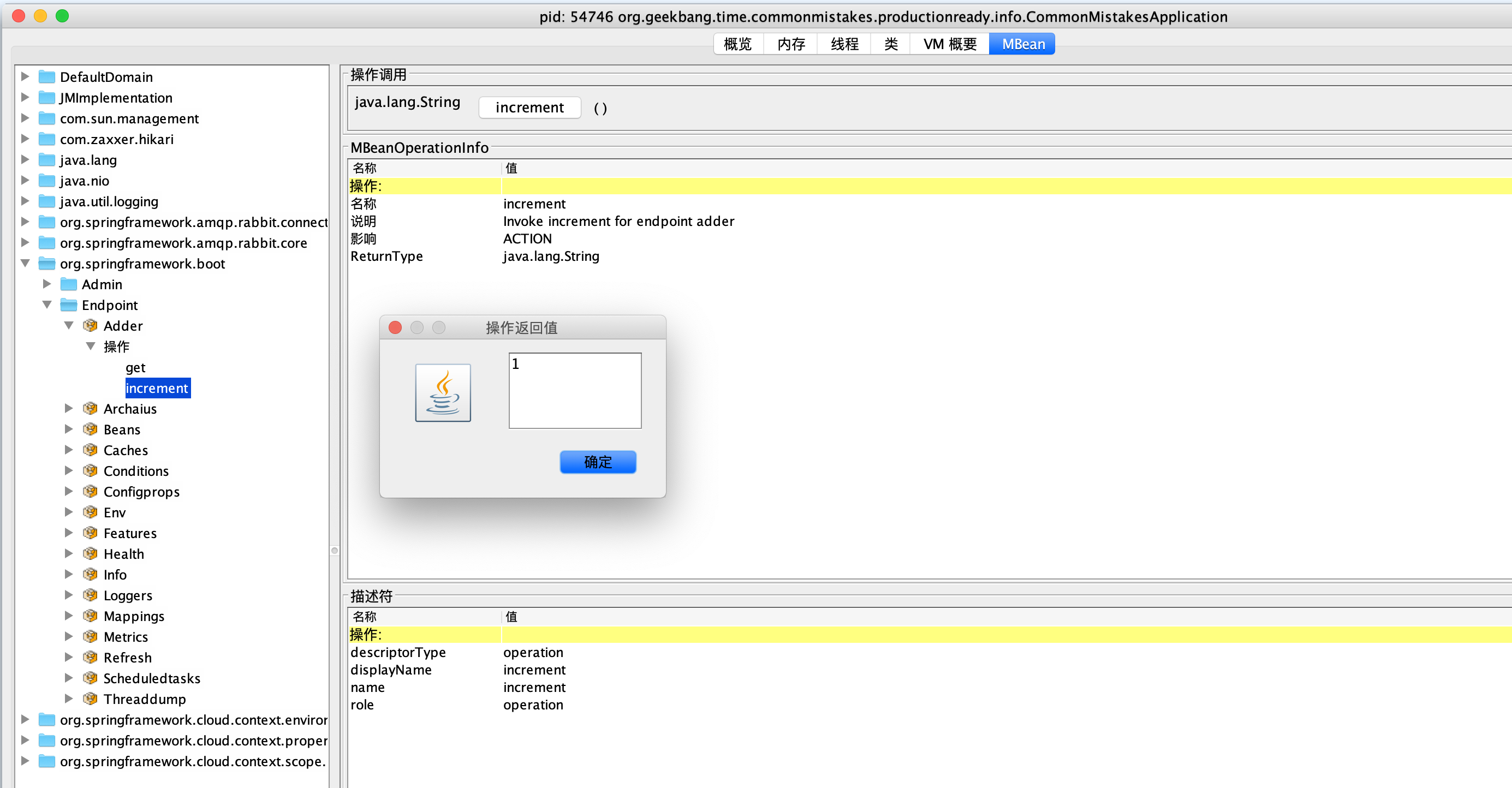
问题 8:在介绍指标 Metrics 时我们看到,InfluxDB 中保存了由 Micrometer 框架自动帮我们收集的一些应用指标。你能否参考源码中两个 Grafana 配置的 JSON 文件,把这些指标在 Grafana 中配置出一个完整的应用监控面板呢?
答:我们可以参考 Micrometer 源码中的 binder 包 (opens new window)下面的类,来了解 Micrometer 帮我们自动做的一些指标。
- JVM 在线时间:process.uptime
- 系统 CPU 使用:system.cpu.usage
- JVM 进程 CPU 使用:process.cpu.usage
- 系统 1 分钟负载:system.load.average.1m
- JVM 使用内存:jvm.memory.used
- JVM 提交内存:jvm.memory.committed
- JVM 最大内存:jvm.memory.max
- JVM 线程情况:jvm.threads.states
- JVM GC 暂停:jvm.gc.pause、jvm.gc.concurrent.phase.time
- 剩余磁盘:disk.free
- Logback 日志数量:logback.eventsTomcat
- 线程情况(最大、繁忙、当前):tomcat.threads.config.max、tomcat.threads.busy、tomcat.threads.current
具体的面板配置方式已讲过,在配置时会用到的两个小技巧。
第一个小技巧是,把公共的标签配置为下拉框固定在页头显示:一般来说,我们会配置一个面板给所有的应用使用(每一个指标中我们都会保存应用名称、IP 地址等信息,这个功能可以使用 Micrometer 的 CommonTags 实现,参考文档 (opens new window)的 5.2 节),我们可以利用 Grafana 的 Variables (opens new window) 功能把应用名称和 IP 展示为两个下拉框显示,同时提供一个 adhoc 筛选器自由增加筛选条件:

来到 Variables 面板,可以看到我配置的三个变量:

Application 和 IP 两个变量的查询语句如下:
SHOW TAG VALUES FROM jvm_memory_used WITH KEY = "application_name" SHOW TAG VALUES FROM jvm_memory_used WITH KEY = "ip" WHERE application_name=~ /^$Application$/1
2第二个小技巧是,利用 GROUP BY 功能展示一些明细的曲线:类似 jvm_threads_states、jvm.gc.pause 等指标中包含了更细节的一些状态区分标签,比如 jvm_threads_states 中的 state 标签代表了线程状态。一般而言,我们在展现图表的时候需要按照线程状态分组分曲线显示:
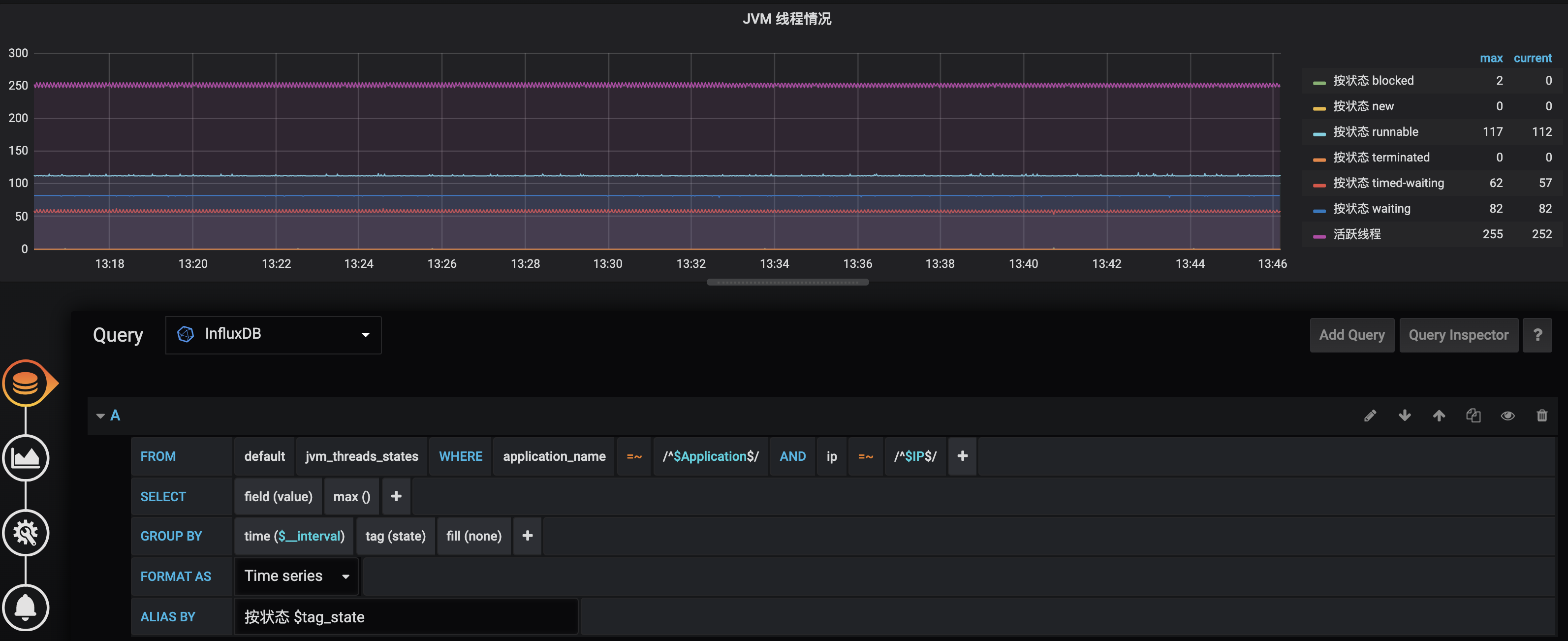
配置的 InfluxDB 查询语句是:
SELECT max("value") FROM "jvm_threads_states" WHERE ("application_name" =~ /^$Application$/ AND "ip" =~ /^$IP$/) AND $timeFilter GROUP BY time($__interval), "state" fill(none)1这里可以看到,application_name 和 ip 两个条件的值,是关联到刚才我们配置的两个变量的,在 GROUP BY 中增加了按照 state 的分组。
问题 9:用户注册后发送消息到 MQ,然后会员服务监听消息进行异步处理的场景下,有些时候我们会发现,虽然用户服务先保存数据再发送 MQ,但会员服务收到消息后去查询数据库,却发现数据库中还没有新用户的信息。你觉得,这可能是什么问题呢,又该如何解决呢?
答:这个问题的真实情况。当时,我们是因为业务代码把保存数据和发 MQ 消息放在了一个事务中,收到消息的时候有可能事务还没有提交完成。为了解决这个问题,开发同学当时的处理方式是,收 MQ 消息的时候 Sleep 1 秒再去处理。这样虽然解决了问题,但却大大降低了消息处理的吞吐量。
更好的做法是先提交事务,完成后再发 MQ 消息。但是,这又引申出来一个问题:MQ 消息发送失败怎么办,如何确保发送消息和本地事务有整体事务性?这就需要进一步考虑建立本地消息表来确保 MQ 消息可补偿,把业务处理和保存 MQ 消息到本地消息表的操作,放在相同事务内处理,然后异步发送和补偿消息表中的消息到 MQ。
问题 10:除了使用 Spring AMQP 实现死信消息的重投递外,RabbitMQ 2.8.0 后支持的死信交换器 DLX 也可以实现类似功能。你能尝试用 DLX 实现吗,并比较下这两种处理机制?
答:其实 RabbitMQ 的 DLX 死信交换器 (opens new window)和普通交换器没有什么区别,只不过它有一个特点是,可以把其它队列关联到这个 DLX 交换器上,然后消息过期后自动会转发到 DLX 交换器。那么,我们就可以利用这个特点来实现延迟消息重投递,经过一定次数之后还是处理失败则作为死信处理。
实现结构如下图所示:
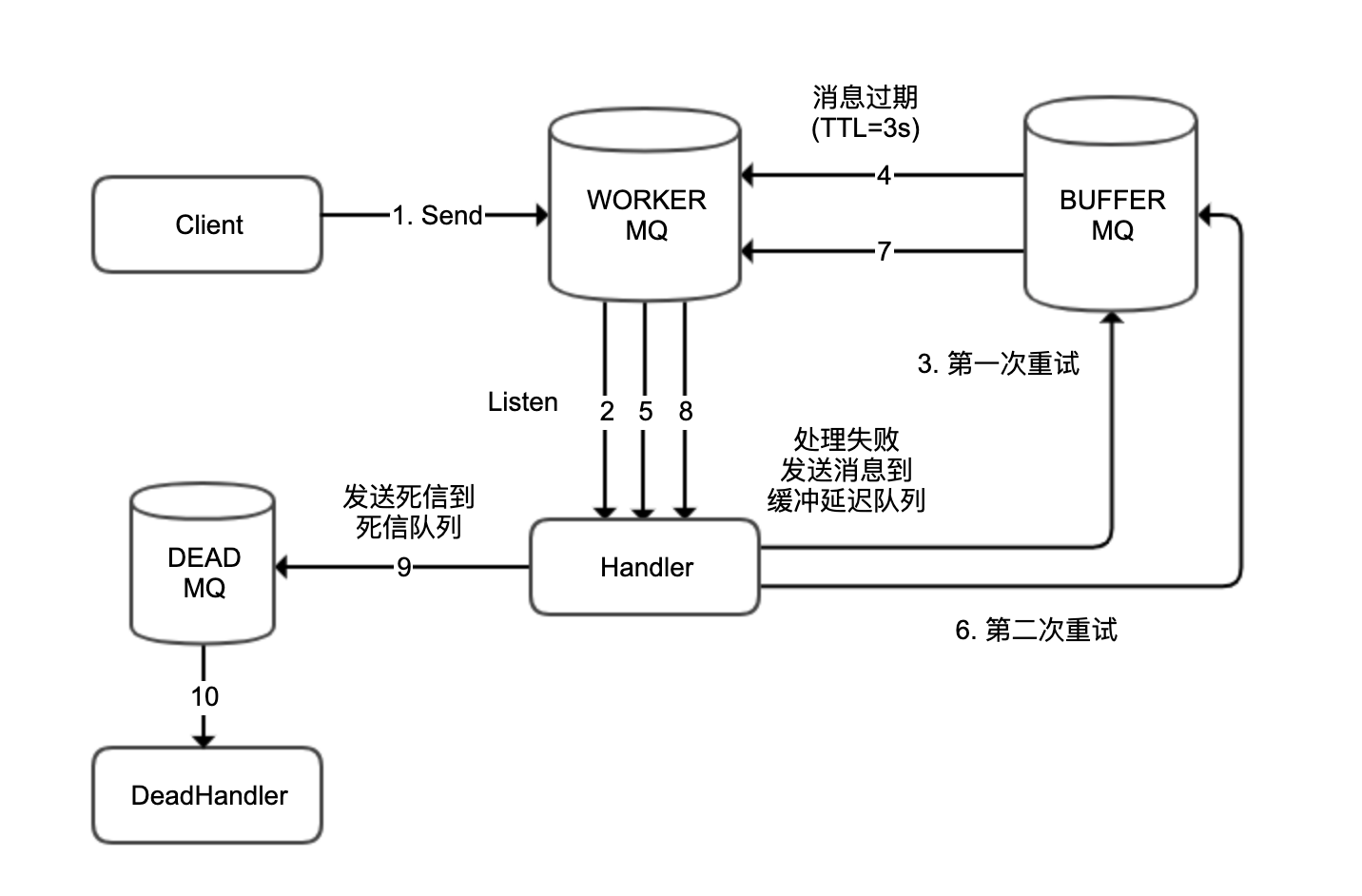
关于这个实现架构图,需要说明的是:
- 为了简单起见,图中圆柱体代表交换器 + 队列,并省去了 RoutingKey。
- WORKER 作为 DLX 用于处理消息,BUFFER 用于临时存放需要延迟重试的消息,WORKER 和 BUFFER 绑定在一起。
- DEAD 用于存放超过重试次数的死信。
- 在这里 WORKER 其实是一个 DLX,我们把它绑定到 BUFFER 实现延迟重试。
通过 RabbitMQ 实现具有延迟重试功能的消息重试以及最后进入死信队列的整个流程如下:
- 客户端发送记录到 WORKER;
- Handler 收到消息后处理失败;
- 第一次重试,发送消息到 BUFFER;
- 3 秒后消息过期,自动转发到 WORKER;
- Handler 再次收到消息后处理失败;
- 第二次重试,发送消息到 BUFFER;
- 3 秒后消息过期,还是自动转发到 WORKER;
- Handler 再次收到消息后处理失败,达到最大重试次数;
- 发送消息到 DEAD(作为死信消息);
- DeadHandler 收到死信处理(比如进行人工处理)。
整个程序的日志输出如下,可以看到输出日志和我们前面贴出的结构图、详细解释的流程一致:
[21:59:48.625] [http-nio-45678-exec-1] [INFO ] [o.g.t.c.a.r.DeadLetterController:24 ] - Client 发送消息 msg1 [21:59:48.640] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:27 ] - Handler 收到消息:msg1 [21:59:48.641] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:33 ] - Handler 消费消息:msg1 异常,准备重试第1次 [21:59:51.643] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:27 ] - Handler 收到消息:msg1 [21:59:51.644] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:33 ] - Handler 消费消息:msg1 异常,准备重试第2次 [21:59:54.646] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:27 ] - Handler 收到消息:msg1 [21:59:54.646] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] [INFO ] [o.g.t.c.a.rabbitmqdlx.MQListener:40 ] - Handler 消费消息:msg1 异常,已重试 2 次,发送到死信队列处理! [21:59:54.649] [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#1-1] [ERROR] [o.g.t.c.a.rabbitmqdlx.MQListener:62 ] - DeadHandler 收到死信消息: msg11
2
3
4
5
6
7
8接下来,我们再对比下这种实现方式和 Spring 重试的区别。其实,这两种实现方式的差别很大,体现在下面两点。
第一点,Spring 的重试是在处理的时候,在线程内休眠进行延迟重试,消息不会重发到 MQ;我们这个方案中处理失败的消息会发送到 RMQ,由 RMQ 做延迟处理。
第二点,Spring 的重试方案,只涉及普通队列和死信队列两个队列(或者说交换器);我们这个方案的实现中涉及工作队列、缓冲队列(用于存放等待延迟重试的消息)和死信队列(真正需要人工处理的消息)三个队列。
当然了,如果你希望把存放正常消息的队列和把存放需要重试处理消息的队列区分开的话,可以把我们这个方案中的队列再拆分下,变为四个队列,也就是工作队列、重试队列、缓冲队列(关联到重试队列作为 DLX)和死信队列。
这里再强调一下,虽然说我们利用了 RMQ 的 DLX 死信交换器的功能,但是我们把 DLX 当做了工作队列来使用,因为我们利用的是其能自动(从 BUFFER 缓冲队列)接收过期消息的特性。
这部分源码比较长,直接放在 GitHub 上了。感兴趣的话,你可以点击这里的链接 (opens new window)查看
问题 11:InfluxDB 不能包含太多 tag。你能写一段测试代码,来模拟这个问题,并观察下 InfluxDB 的内存使用情况吗?
答:我们写一段如下的测试代码:向 InfluxDB 写入大量指标,每一条指标关联 10 个 Tag,每一个 Tag 都是 100000 以内的随机数,这种方式会造成 high series cardinality (opens new window) 问题,从而大量占用 InfluxDB 的内存。
@GetMapping("influxdbwrong") public void influxdbwrong() { OkHttpClient.Builder okHttpClientBuilder = new OkHttpClient().newBuilder() .connectTimeout(1, TimeUnit.SECONDS) .readTimeout(60, TimeUnit.SECONDS) .writeTimeout(60, TimeUnit.SECONDS); try (InfluxDB influxDB = InfluxDBFactory.connect("http://127.0.0.1:8086", "root", "root", okHttpClientBuilder)) { influxDB.setDatabase("performance"); //插入100000条记录 IntStream.rangeClosed(1, 100000).forEach(i -> { Map<String, String> tags = new HashMap<>(); //每条记录10个tag,tag的值是100000以内随机值 IntStream.rangeClosed(1, 10).forEach(j -> tags.put("tagkey" + i, "tagvalue" + ThreadLocalRandom.current().nextInt(100000))); Point point = Point.measurement("bad") .tag(tags) .addField("value", ThreadLocalRandom.current().nextInt(10000)) .time(System.currentTimeMillis(), TimeUnit.MILLISECONDS) .build(); influxDB.write(point); }); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22不过因为 InfluxDB 的默认参数配置限制了 Tag 的值数量以及数据库 Series 数量:
max-values-per-tag = 100000 max-series-per-database = 10000001
2所以这个程序很快就会出错,无法形成 OOM,你可以把这两个参数改为 0 来解除这个限制。
继续运行程序,我们可以发现 InfluxDB 占用大量内存最终出现 OOM。
问题 12:文档数据库 MongoDB,也是一种常用的 NoSQL。你觉得 MongoDB 的优势和劣势是什么呢?它适合用在什么场景下呢?
答:MongoDB 是目前比较火的文档型 NoSQL。虽然 MongoDB 在 4.0 版本后具有了事务功能,但是它整体的稳定性相比 MySQL 还是有些差距。因此,MongoDB 不太适合作为重要数据的主数据库,但可以用来存储日志、爬虫等数据重要程度不那么高,但写入并发量又很大的场景。
虽然 MongoDB 的写入性能较高,但复杂查询性能却相比 Elasticsearch 来说没啥优势;虽然 MongoDB 有 Sharding 功能,但是还不太稳定。因此,个人建议在数据写入量不大、更新不频繁,并且不需要考虑事务的情况下,使用 Elasticsearch 来替换 MongoDB。
# 参考
- 来源:极客时间《Java 业务开发常见错误 100例》