 Java 业务开发常见错误(六)
Java 业务开发常见错误(六)
# Java 业务开发常见错误(六)
# 数据源头:任何客户端的东西都不可信任
对于 HTTP 请求,我们要在脑子里有一个根深蒂固的概念,那就是任何客户端传过来的数据都是不能直接信任的。客户端传给服务端的数据只是信息收集,数据需要经过有效性验证、权限验证等后才能使用,并且这些数据只能认为是用户操作的意图,不能直接代表数据当前的状态。
举一个简单的例子,我们打游戏的时候,客户端发给服务端的只是用户的操作,比如移动了多少位置,由服务端根据用户当前的状态来设置新的位置再返回给客户端。为了防止作弊,不可能由客户端直接告诉服务端用户当前的位置。
因此,客户端发给服务端的指令,代表的只是操作指令,并不能直接决定用户的状态,对于状态改变的计算在服务端。而网络不好时,我们往往会遇到走了 10 步又被服务端拉回来的现象,就是因为有指令丢失,客户端使用服务端计算的实际位置修正了客户端玩家的位置。
# 客户端的计算不可信
我们先看一个电商下单操作的案例。在这个场景下,可能会暴露这么一个 /order 的 POST 接口给客户端,让客户端直接把组装后的订单信息 Order 传给服务端:
@PostMapping("/order")
public void wrong(@RequestBody Order order) {
this.createOrder(order);
}
2
3
4
订单信息 Order 可能包括商品 ID、商品价格、数量、商品总价:
@Data
public class Order {
private long itemId; //商品ID
private BigDecimal itemPrice; //商品价格
private int quantity; //商品数量
private BigDecimal itemTotalPrice; //商品总价
}
2
3
4
5
6
7
虽然用户下单时客户端肯定有商品的价格等信息,也会计算出订单的总价给用户确认,但是这些信息只能用于呈现和核对。即使客户端传给服务端的 POJO 中包含了这些信息,服务端也一定要重新从数据库来初始化商品的价格,重新计算最终的订单价格。如果不这么做的话,很可能会被黑客利用,商品总价被恶意修改为比较低的价格。
因此,我们真正直接使用的、可信赖的只是客户端传过来的商品 ID 和数量,服务端会根据这些信息重新计算最终的总价。如果服务端计算出来的商品价格和客户端传过来的价格不匹配的话,可以给客户端友好提示,让用户重新下单。修改后的代码如下:
@PostMapping("/orderRight")
public void right(@RequestBody Order order) {
//根据ID重新查询商品
Item item = Db.getItem(order.getItemId());
//客户端传入的和服务端查询到的商品单价不匹配的时候,给予友好提示
if (!order.getItemPrice().equals(item.getItemPrice())) {
throw new RuntimeException("您选购的商品价格有变化,请重新下单");
}
//重新设置商品单价
order.setItemPrice(item.getItemPrice());
//重新计算商品总价
BigDecimal totalPrice = item.getItemPrice().multiply(BigDecimal.valueOf(order.getQuantity()));
//客户端传入的和服务端查询到的商品总价不匹配的时候,给予友好提示
if (order.getItemTotalPrice().compareTo(totalPrice)!=0) {
throw new RuntimeException("您选购的商品总价有变化,请重新下单");
}
//重新设置商品总价
order.setItemTotalPrice(totalPrice);
createOrder(order);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
还有一种可行的做法是,让客户端仅传入需要的数据给服务端,像这样重新定义一个 POJO CreateOrderRequest 作为接口入参,比直接使用领域模型 Order 更合理。在设计接口时,我们会思考哪些数据需要客户端提供,而不是把一个大而全的对象作为参数提供给服务端,以避免因为忘记在服务端重置客户端数据而导致的安全问题。
下单成功后,服务端处理完成后会返回诸如商品单价、总价等信息给客户端。此时,客户端可以进行一次判断,如果和之前客户端的数据不一致的话,给予用户提示,用户确认没问题后再进入支付阶段:
@Data
public class CreateOrderRequest {
private long itemId; //商品ID
private int quantity; //商品数量
}
@PostMapping("orderRight2")
public Order right2(@RequestBody CreateOrderRequest createOrderRequest) {
//商品ID和商品数量是可信的没问题,其他数据需要由服务端计算
Item item = Db.getItem(createOrderRequest.getItemId());
Order order = new Order();
order.setItemPrice(item.getItemPrice());
order.setItemTotalPrice(item.getItemPrice().multiply(BigDecimal.valueOf(order.getQuantity())));
createOrder(order);
return order;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
通过这个案例我们可以看到,在处理客户端提交过来的数据时,服务端需要明确区分,哪些数据是需要客户端提供的,哪些数据是客户端从服务端获取后在客户端计算的。其中,前者可以信任;而后者不可信任,服务端需要重新计算,如果客户端和服务端计算结果不一致的话,可以给予友好提示。
# 客户端提交的参数需要校验
对于客户端的数据,我们还容易忽略的一点是,误以为客户端的数据来源是服务端,客户端就不可能提交异常数据。我们看一个案例。
有一个用户注册页面要让用户选择所在国家,我们会把服务端支持的国家列表返回给页面,供用户选择。如下代码所示,我们的注册只支持中国、美国和英国三个国家,并不对其他国家开放,因此从数据库中筛选了 id<4 的国家返回给页面进行填充:
@Slf4j
@RequestMapping("trustclientdata")
@Controller
public class TrustClientDataController {
//所有支持的国家
private HashMap<Integer, Country> allCountries = new HashMap<>();
public TrustClientDataController() {
allCountries.put(1, new Country(1, "China"));
allCountries.put(2, new Country(2, "US"));
allCountries.put(3, new Country(3, "UK"));
allCountries.put(4, new Country(4, "Japan"));
}
@GetMapping("/")
public String index(ModelMap modelMap) {
List<Country> countries = new ArrayList<>();
//从数据库查出ID<4的三个国家作为白名单在页面显示
countries.addAll(allCountries.values().stream().filter(country -> country.getId()<4).collect(Collectors.toList()));
modelMap.addAttribute("countries", countries);
return "index";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
我们通过服务端返回的数据来渲染模板:
...
<form id="myForm" method="post" th:action="@{/trustclientdata/wrong}">
<select id="countryId" name="countryId">
<option value="0">Select country</option>
<option th:each="country : ${countries}" th:text="${country.name}" th:value="${country.id}"></option>
</select>
<button th:text="Register" type="submit"/>
</form>
...
2
3
4
5
6
7
8
9
10
11
12
13
但我们要知道的是,页面是给普通用户使用的,而黑客不会在乎页面显示什么,完全有可能尝试给服务端返回页面上没显示的其他国家 ID。如果像这样直接信任客户端传来的国家 ID 的话,很可能会把用户注册功能开放给其他国家的人:
@PostMapping("/wrong")
@ResponseBody
public String wrong(@RequestParam("countryId") int countryId) {
return allCountries.get(countryId).getName();
}
2
3
4
5
即使我们知道参数的范围来自下拉框,而下拉框的内容也来自服务端,也需要对参数进行校验。因为接口不一定要通过浏览器请求,只要知道接口定义完全可以通过其他工具提交:
curl http://localhost:45678/trustclientdata/wrong\?countryId=4 -X POST
修改方式是,在使用客户端传过来的参数之前,对参数进行有效性校验:
@PostMapping("/right")
@ResponseBody
public String right(@RequestParam("countryId") int countryId) {
if (countryId < 1 || countryId > 3)
throw new RuntimeException("非法参数");
return allCountries.get(countryId).getName();
}
2
3
4
5
6
7
或者是,使用 Spring Validation 采用注解的方式进行参数校验,更优雅:
@Validated
public class TrustClientParameterController {
@PostMapping("/better")
@ResponseBody
public String better(
@RequestParam("countryId")
@Min(value = 1, message = "非法参数")
@Max(value = 3, message = "非法参数") int countryId) {
return allCountries.get(countryId).getName();
}
}
2
3
4
5
6
7
8
9
10
11
客户端提交的参数需要校验的问题,可以引申出一个更容易忽略的点是,我们可能会把一些服务端的数据暂存在网页的隐藏域中,这样下次页面提交的时候可以把相关数据再传给服务端。虽然用户通过网页界面的操作无法修改这些数据,但这些数据对于 HTTP 请求来说就是普通数据,完全可以随时修改为任意值。所以,服务端在使用这些数据的时候,也同样要特别小心。
# 不能信任请求头里的任何内容
刚才我们介绍了,不能直接信任客户端的传参,也就是通过 GET 或 POST 方法传过来的数据,此外请求头的内容也不能信任。
一个比较常见的需求是,为了防刷,我们需要判断用户的唯一性。比如,针对未注册的新用户发送一些小奖品,我们不希望相同用户多次获得奖品。考虑到未注册的用户因为没有登录过所以没有用户标识,我们可能会想到根据请求的 IP 地址,来判断用户是否已经领过奖品。
比如,下面的这段测试代码。我们通过一个 HashSet 模拟已发放过奖品的 IP 名单,每次领取奖品后把 IP 地址加入这个名单中。IP 地址的获取方式是:优先通过 X-Forwarded-For 请求头来获取,如果没有的话再通过 HttpServletRequest 的 getRemoteAddr 方法来获取。
@Slf4j
@RequestMapping("trustclientip")
@RestController
public class TrustClientIpController {
HashSet<String> activityLimit = new HashSet<>();
@GetMapping("test")
public String test(HttpServletRequest request) {
String ip = getClientIp(request);
if (activityLimit.contains(ip)) {
return "您已经领取过奖品";
} else {
activityLimit.add(ip);
return "奖品领取成功";
}
}
private String getClientIp(HttpServletRequest request) {
String xff = request.getHeader("X-Forwarded-For");
if (xff == null) {
return request.getRemoteAddr();
} else {
return xff.contains(",") ? xff.split(",")[0] : xff;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
之所以这么做是因为,通常我们的应用之前都部署了反向代理或负载均衡器,remoteAddr 获得的只能是代理的 IP 地址,而不是访问用户实际的 IP。这不符合我们的需求,因为反向代理在转发请求时,通常会把用户真实 IP 放入 X-Forwarded-For 这个请求头中。
这种过于依赖 X-Forwarded-For 请求头来判断用户唯一性的实现方式,是有问题的:
完全可以通过 cURL 类似的工具来模拟请求,随意篡改头的内容:
curl http://localhost:45678/trustclientip/test -H "X-Forwarded-For:183.84.18.71, 10.253.15.1"1网吧、学校等机构的出口 IP 往往是同一个,在这个场景下,可能只有最先打开这个页面的用户才能领取到奖品,而其他用户会被阻拦。
因此,IP 地址或者说请求头里的任何信息,包括 Cookie 中的信息、Referer,只能用作参考,不能用作重要逻辑判断的依据。而对于类似这个案例唯一性的判断需求,更好的做法是,让用户进行登录或三方授权登录(比如微信),拿到用户标识来做唯一性判断。
# 用户标识不能从客户端获取
聊到用户登录,业务代码非常容易犯错的一个地方是,使用了客户端传给服务端的用户 ID,类似这样:
@GetMapping("wrong")
public String wrong(@RequestParam("userId") Long userId) {
return "当前用户Id:" + userId;
}
2
3
4
你可能觉得没人会这么干,案例:一个大项目因为服务端直接使用了客户端传过来的用户标识,导致了安全问题。
犯类似低级错误的原因,有三个:
- 开发同学没有正确认识接口或服务面向的用户。如果接口面向内部服务,由服务调用方传入用户 ID 没什么不合理,但是这样的接口不能直接开放给客户端或 H5 使用。
- 在测试阶段为了方便测试调试,我们通常会实现一些无需登录即可使用的接口,直接使用客户端传过来的用户标识,却在上线之前忘记删除类似的超级接口。
- 一个大型网站前端可能由不同的模块构成,不一定是一个系统,而用户登录状态可能也没有打通。有些时候,我们图简单可能会在 URL 中直接传用户 ID,以实现通过前端传值来打通用户登录状态。
如果你的接口直面用户(比如给客户端或 H5 页面调用),那么一定需要用户先登录才能使用。登录后用户标识保存在服务端,接口需要从服务端(比如 Session 中)获取。这里有段代码演示了一个最简单的登录操作,登录后在 Session 中设置了当前用户的标识:
@GetMapping("login")
public long login(@RequestParam("username") String username, @RequestParam("password") String password, HttpSession session) {
if (username.equals("admin") && password.equals("admin")) {
session.setAttribute("currentUser", 1L);
return 1L;
}
return 0L;
}
2
3
4
5
6
7
8
如果希望每一个需要登录的方法,都从 Session 中获得当前用户标识,并进行一些后续处理的话,我们没有必要在每一个方法内都复制粘贴相同的获取用户身份的逻辑,可以定义一个自定义注解 @LoginRequired 到 userId 参数上,然后通过 HandlerMethodArgumentResolver 自动实现参数的组装:
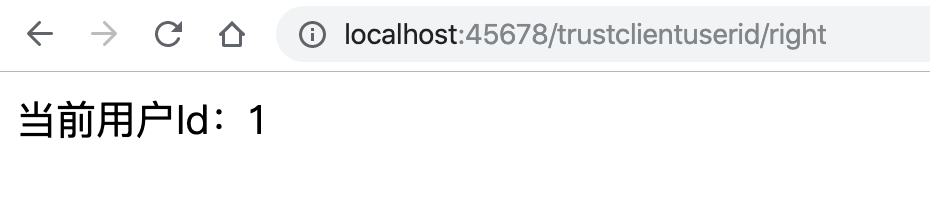
@GetMapping("right")
public String right(@LoginRequired Long userId) {
return "当前用户Id:" + userId;
}
2
3
4
@LoginRequired 本身并无特殊,只是一个自定义注解:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.PARAMETER)
@Documented
public @interface LoginRequired {
String sessionKey() default "currentUser";
}
2
3
4
5
6
魔法来自 HandlerMethodArgumentResolver。我们自定义了一个实现类 LoginRequiredArgumentResolver,实现了 HandlerMethodArgumentResolver 接口的 2 个方法:
- supportsParameter 方法判断当参数上有 @LoginRequired 注解时,再做自定义参数解析的处理;
- resolveArgument 方法用来实现解析逻辑本身。在这里,我们尝试从 Session 中获取当前用户的标识,如果无法获取到的话提示非法调用的错误,如果获取到则返回 userId。这样一来,Controller 中的 userId 参数就可以自动赋值了。
@Slf4j
public class LoginRequiredArgumentResolver implements HandlerMethodArgumentResolver {
//解析哪些参数
@Override
public boolean supportsParameter(MethodParameter methodParameter) {
//匹配参数上具有@LoginRequired注解的参数
return methodParameter.hasParameterAnnotation(LoginRequired.class);
}
@Override
public Object resolveArgument(MethodParameter methodParameter, ModelAndViewContainer modelAndViewContainer, NativeWebRequest nativeWebRequest, WebDataBinderFactory webDataBinderFactory) throws Exception {
//从参数上获得注解
LoginRequired loginRequired = methodParameter.getParameterAnnotation(LoginRequired.class);
//根据注解中的Session Key,从Session中查询用户信息
Object object = nativeWebRequest.getAttribute(loginRequired.sessionKey(), NativeWebRequest.SCOPE_SESSION);
if (object == null) {
log.error("接口 {} 非法调用!", methodParameter.getMethod().toString());
throw new RuntimeException("请先登录!");
}
return object;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
当然,我们要实现 WebMvcConfigurer 接口的 addArgumentResolvers 方法,来增加这个自定义的处理器 LoginRequiredArgumentResolver:
SpringBootApplication
public class CommonMistakesApplication implements WebMvcConfigurer {
...
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) {
resolvers.add(new LoginRequiredArgumentResolver());
}
}
2
3
4
5
6
7
8
测试发现,经过这样的实现,登录后所有需要登录的方法都可以一键通过加 @LoginRequired 注解来拿到用户标识,方便且安全:
# 安全兜底:涉及钱时,必须考虑防刷、限量和防重
任何涉及钱的代码必须要考虑防刷、限量和防重,要做好安全兜底。涉及钱的代码,主要有以下三类。
第一,代码本身涉及有偿使用的三方服务。如果因为代码本身缺少授权、用量控制而被利用导致大量调用,势必会消耗大量的钱,给公司造成损失。有些三方服务可能采用后付款方式的结算,出现问题后如果没及时发现,下个月结算时就会收到一笔数额巨大的账单。
第二,代码涉及虚拟资产的发放,比如积分、优惠券等。虽然说虚拟资产不直接对应货币,但一般可以在平台兑换具有真实价值的资产。比如,优惠券可以在下单时使用,积分可以兑换积分商城的商品。所以从某种意义上说,虚拟资产就是具有一定价值的钱,但因为不直接涉及钱和外部资金通道,所以容易产生随意性发放而导致漏洞。
第三,代码涉及真实钱的进出。比如,对用户扣款,如果出现非正常的多次重复扣款,小则用户投诉、用户流失,大则被相关管理机构要求停业整改,影响业务。又比如,给用户发放返现的付款功能,如果出现漏洞造成重复付款,涉及 B 端的可能还好,但涉及 C 端用户的重复付款可能永远无法追回。
# 开放平台资源的使用需要考虑防刷
案例:有次短信账单月结时发现,之前每个月是几千元的短信费用,这个月突然变为了几万元。查数据库记录发现,之前是每天发送几千条短信验证码,从某天开始突然变为了每天几万条,但注册用户数并没有激增。显然,这是短信接口被刷了。
我们知道,短信验证码服务属于开放性服务,由用户侧触发,且因为是注册验证码所以不需要登录就可以使用。如果我们的发短信接口像这样没有任何防刷的防护,直接调用三方短信通道,就相当于“裸奔”,很容易被短信轰炸平台利用:
@GetMapping("wrong")
public void wrong() {
sendSMSCaptcha("13600000000");
}
private void sendSMSCaptcha(String mobile) {
//调用短信通道
}
2
3
4
5
6
7
8
对于短信验证码这种开放接口,程序逻辑内需要有防刷逻辑。好的防刷逻辑是,对正常使用的用户毫无影响,只有疑似异常使用的用户才会感受到。对于短信验证码,有如下 4 种可行的方式来防刷。
第一种方式,只有固定的请求头才能发送验证码。
也就是说,我们通过请求头中网页或 App 客户端传给服务端的一些额外参数,来判断请求是不是 App 发起的。其实,这种方式“防君子不防小人”。
比如,判断是否存在浏览器或手机型号、设备分辨率请求头。对于那些使用爬虫来抓取短信接口地址的程序来说,往往只能抓取到 URL,而难以分析出请求发送短信还需要的额外请求头,可以看作第一道基本防御。
第二种方式,只有先到过注册页面才能发送验证码。
对于普通用户来说,不管是通过 App 注册还是 H5 页面注册,一定是先进入注册页面才能看到发送验证码按钮,再点击发送。我们可以在页面或界面打开时请求固定的前置接口,为这个设备开启允许发送验证码的窗口,之后的请求发送验证码才是有效请求。
这种方式可以防御直接绕开固定流程,通过接口直接调用的发送验证码请求,并不会干扰普通用户。
第三种方式,控制相同手机号的发送次数和发送频次。
除非是短信无法收到,否则用户不太会请求了验证码后不完成注册流程,再重新请求。因此,我们可以限制同一手机号每天的最大请求次数。验证码的到达需要时间,太短的发送间隔没有意义,所以我们还可以控制发送的最短间隔。比如,我们可以控制相同手机号一天只能发送 10 次验证码,最短发送间隔 1 分钟。
第四种方式,增加前置图形验证码。
短信轰炸平台一般会收集很多免费短信接口,一个接口只会给一个用户发一次短信,所以控制相同手机号发送次数和间隔的方式不够有效。这时,我们可以考虑对用户体验稍微有影响,但也是最有效的方式作为保底,即将弹出图形验证码作为前置。
除了图形验证码,我们还可以使用其他更友好的人机验证手段(比如滑动、点击验证码等),甚至是引入比较新潮的无感知验证码方案(比如,通过判断用户输入手机号的打字节奏,来判断是用户还是机器),来改善用户体验。
此外,我们也可以考虑在监测到异常的情况下再弹出人机检测。比如,短时间内大量相同远端 IP 发送验证码的时候,才会触发人机检测。
总之,我们要确保,只有正常用户经过正常的流程才能使用开放平台资源,并且资源的用量在业务需求合理范围内。此外,还需要考虑做好短信发送量的实时监控,遇到发送量激增要及时报警。
# 虚拟资产并不能凭空产生无限使用
虚拟资产虽然是平台方自己生产和控制,但如果生产出来可以立即使用就有立即变现的可能性。比如,因为平台 Bug 有大量用户领取高额优惠券,并立即下单使用。
在商家看来,这很可能只是一个用户支付的订单,并不会感知到用户使用平台方优惠券的情况;同时,因为平台和商家是事后结算的,所以会马上安排发货。而发货后基本就不可逆了,一夜之间造成了大量资金损失。
我们从代码层面模拟一个优惠券被刷的例子。
假设有一个 CouponCenter 类负责优惠券的产生和发放。如下是错误做法,只要调用方需要,就可以凭空产生无限的优惠券:
@Slf4j
public class CouponCenter {
//用于统计发了多少优惠券
AtomicInteger totalSent = new AtomicInteger(0);
public void sendCoupon(Coupon coupon) {
if (coupon != null)
totalSent.incrementAndGet();
}
public int getTotalSentCoupon() {
return totalSent.get();
}
//没有任何限制,来多少请求生成多少优惠券
public Coupon generateCouponWrong(long userId, BigDecimal amount) {
return new Coupon(userId, amount);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
这样一来,使用 CouponCenter 的 generateCouponWrong 方法,想发多少优惠券就可以发多少:
@GetMapping("wrong")
public int wrong() {
CouponCenter couponCenter = new CouponCenter();
//发送10000个优惠券
IntStream.rangeClosed(1, 10000).forEach(i -> {
Coupon coupon = couponCenter.generateCouponWrong(1L, new BigDecimal("100"));
couponCenter.sendCoupon(coupon);
});
return couponCenter.getTotalSentCoupon();
}
2
3
4
5
6
7
8
9
10
更合适的做法是,把优惠券看作一种资源,其生产不是凭空的,而是需要事先申请,理由是:
- 虚拟资产如果最终可以对应到真实金钱上的优惠,那么,能发多少取决于运营和财务的核算,应该是有计划、有上限的。引言提到的无门槛优惠券,需要特别小心。有门槛优惠券的大量使用至少会带来大量真实的消费,而使用无门槛优惠券下的订单,可能用户一分钱都没有支付。
- 即使虚拟资产不值钱,大量不合常规的虚拟资产流入市场,也会冲垮虚拟资产的经济体系,造成虚拟货币的极速贬值。有量的控制才有价值。
- 资产的申请需要理由,甚至需要走流程,这样才可以追溯是什么活动需要、谁提出的申请,程序依据申请批次来发放。
接下来,我们按照这个思路改进一下程序。
首先,定义一个 CouponBatch 类,要产生优惠券必须先向运营申请优惠券批次,批次中包含了固定张数的优惠券、申请原因等信息:
//优惠券批次
@Data
public class CouponBatch {
private long id;
private AtomicInteger totalCount;
private AtomicInteger remainCount;
private BigDecimal amount;
private String reason;
}
2
3
4
5
6
7
8
9
在业务需要发放优惠券的时候,先申请批次,然后再通过批次发放优惠券:
@GetMapping("right")
public int right() {
CouponCenter couponCenter = new CouponCenter();
//申请批次
CouponBatch couponBatch = couponCenter.generateCouponBatch();
IntStream.rangeClosed(1, 10000).forEach(i -> {
Coupon coupon = couponCenter.generateCouponRight(1L, couponBatch);
//发放优惠券
couponCenter.sendCoupon(coupon);
});
return couponCenter.getTotalSentCoupon();
}
2
3
4
5
6
7
8
9
10
11
12
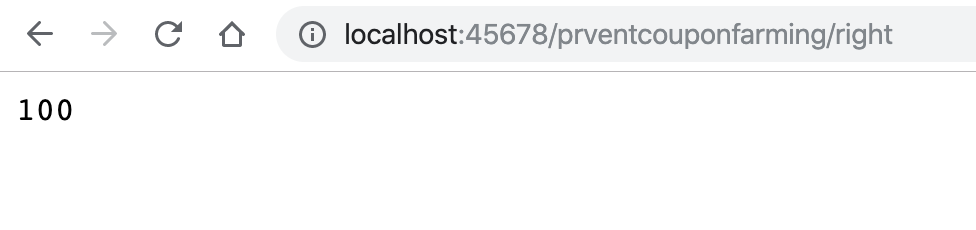
可以看到,generateCouponBatch 方法申请批次时,设定了这个批次包含 100 张优惠券。在通过 generateCouponRight 方法发放优惠券时,每发一次都会从批次中扣除一张优惠券,发完了就没有了:
这样改进后的程序,一个批次最多只能发放 100 张优惠券:
因为是 Demo,所以我们只是凭空 new 出来一个 Coupon。在真实的生产级代码中,一定是根据 CouponBatch 在数据库中插入一定量的 Coupon 记录,每一个优惠券都有唯一的 ID,可跟踪、可注销。
# 钱的进出要和订单挂钩且实现幂等
涉及钱的进出,需要做好以下两点。
第一,任何资金操作都需要在平台侧生成业务属性的订单,可以是优惠券发放订单,可以是返现订单,也可以是借款订单,一定是先有订单再去做资金操作。同时,订单的产生需要有业务属性。业务属性是指,订单不是凭空产生的,否则就没有控制的意义。比如,返现发放订单必须关联到原先的商品订单产生;再比如,借款订单必须关联到同一个借款合同产生。
第二,一定要做好防重,也就是实现幂等处理,并且幂等处理必须是全链路的。这里的全链路是指,从前到后都需要有相同的业务订单号来贯穿,实现最终的支付防重。
关于这两点,你可以参考下面的代码示例:
//错误:每次使用UUID作为订单号
@GetMapping("wrong")
public void wrong(@RequestParam("orderId") String orderId) {
PayChannel.pay(UUID.randomUUID().toString(), "123", new BigDecimal("100"));
}
//正确:使用相同的业务订单号
@GetMapping("right")
public void right(@RequestParam("orderId") String orderId) {
PayChannel.pay(orderId, "123", new BigDecimal("100"));
}
//三方支付通道
public class PayChannel {
public static void pay(String orderId, String account, BigDecimal amount) {
...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
对于支付操作,我们一定是调用三方支付公司的接口或银行接口进行处理的。一般而言,这些接口都会有商户订单号的概念,对于相同的商户订单号,无法进行重复的资金处理,所以三方公司的接口可以实现唯一订单号的幂等处理。
但是业务系统在实现资金操作时容易犯的错是,没有自始至终地使用一个订单号作为商户订单号,透传给三方支付接口。出现这个问题的原因是,比较大的互联网公司一般会把支付独立一个部门。支付部门可能会针对支付做聚合操作,内部会维护一个支付订单号,然后使用支付订单号和三方支付接口交互。最终虽然商品订单是一个,但支付订单是多个,相同的商品订单因为产生多个支付订单导致多次支付。
如果说支付出现了重复扣款,我们可以给用户进行退款操作,但给用户付款的操作一旦出现重复付款,就很难把钱追回来了,所以更要小心。
这就是全链路的意义,从一开始就需要先有业务订单产生,然后使用相同的业务订单号一直贯穿到最后的资金通路,才能真正避免重复资金操作。
# 数据和代码:数据就是数据,代码就是代码
正如这一讲标题“数据就是数据,代码就是代码”所说,Web 安全方面的很多漏洞,都是源自把数据当成了代码来执行,也就是注入类问题,比如:
- 客户端提供给服务端的查询值,是一个数据,会成为 SQL 查询的一部分。黑客通过修改这个值注入一些 SQL,来达到在服务端运行 SQL 的目的,相当于把查询条件的数据变为了查询代码。这种攻击方式,叫做 SQL 注入。
- 对于规则引擎,我们可能会用动态语言做一些计算,和 SQL 注入一样外部传入的数据只能当做数据使用,如果被黑客利用传入了代码,那么代码可能就会被动态执行。这种攻击方式,叫做代码注入。
- 对于用户注册、留言评论等功能,服务端会从客户端收集一些信息,本来用户名、邮箱这类信息是纯文本信息,但是黑客把信息替换为了 JavaScript 代码。那么,这些信息在页面呈现时,可能就相当于执行了 JavaScript 代码。甚至是,服务端可能把这样的代码,当作普通信息保存到了数据库。黑客通过构建 JavaScript 代码来实现修改页面呈现、盗取信息,甚至蠕虫攻击的方式,叫做 XSS(跨站脚本)攻击。
# SQL 注入能干的事比你想象的更多
我们应该都听说过 SQL 注入,也可能知道最经典的 SQL 注入的例子,是通过构造’or’1’='1 作为密码实现登录。这种简单的攻击方式,在十几年前可以突破很多后台的登录,但现在很难奏效了。
最近几年,我们的安全意识增强了,都知道使用参数化查询来避免 SQL 注入问题。其中的原理是,使用参数化查询的话,参数只能作为普通数据,不可能作为 SQL 的一部分,以此有效避免 SQL 注入问题。
虽然我们已经开始关注 SQL 注入的问题,但还是有一些认知上的误区,主要表现在以下三个方面:
第一,认为 SQL 注入问题只可能发生于 Http Get 请求,也就是通过 URL 传入的参数才可能产生注入点。这是很危险的想法。从注入的难易度上来说,修改 URL 上的 QueryString 和修改 Post 请求体中的数据,没有任何区别,因为黑客是通过工具来注入的,而不是通过修改浏览器上的 URL 来注入的。甚至 Cookie 都可以用来 SQL 注入,任何提供数据的地方都可能成为注入点。
第二,认为不返回数据的接口,不可能存在注入问题。其实,黑客完全可以利用 SQL 语句构造出一些不正确的 SQL,导致执行出错。如果服务端直接显示了错误信息,那黑客需要的数据就有可能被带出来,从而达到查询数据的目的。甚至是,即使没有详细的出错信息,黑客也可以通过所谓盲注的方式进行攻击。
第三,认为 SQL 注入的影响范围,只是通过短路实现突破登录,只需要登录操作加强防范即可。首先,SQL 注入完全可以实现拖库,也就是下载整个数据库的内容(之后我们会演示),SQL 注入的危害不仅仅是突破后台登录。其次,根据木桶原理,整个站点的安全性受限于安全级别最低的那块短板。因此,对于安全问题,站点的所有模块必须一视同仁,并不是只加强防范所谓的重点模块。
在日常开发中,虽然我们是使用框架来进行数据访问的,但还可能会因为疏漏而导致注入问题。接下来就用一个实际的例子配合专业的 SQL 注入工具 sqlmap (opens new window),来测试下 SQL 注入。
首先,在程序启动的时候使用 JdbcTemplate 创建一个 userdata 表(表中只有 ID、用户名、密码三列),并初始化两条用户信息。然后,创建一个不返回任何数据的 Http Post 接口。在实现上,我们通过 SQL 拼接的方式,把传入的用户名入参拼接到 LIKE 子句中实现模糊查询。
//程序启动时进行表结构和数据初始化
@PostConstruct
public void init() {
//删除表
jdbcTemplate.execute("drop table IF EXISTS `userdata`;");
//创建表,不包含自增ID、用户名、密码三列
jdbcTemplate.execute("create TABLE `userdata` (\n" +
" `id` bigint(20) NOT NULL AUTO_INCREMENT,\n" +
" `name` varchar(255) NOT NULL,\n" +
" `password` varchar(255) NOT NULL,\n" +
" PRIMARY KEY (`id`)\n" +
") ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;");
//插入两条测试数据
jdbcTemplate.execute("INSERT INTO `userdata` (name,password) VALUES ('test1','haha1'),('test2','haha2')");
}
@Autowired
private JdbcTemplate jdbcTemplate;
//用户模糊搜索接口
@PostMapping("jdbcwrong")
public void jdbcwrong(@RequestParam("name") String name) {
//采用拼接SQL的方式把姓名参数拼到LIKE子句中
log.info("{}", jdbcTemplate.queryForList("SELECT id,name FROM userdata WHERE name LIKE '%" + name + "%'"));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
使用 sqlmap 来探索这个接口:
python sqlmap.py -u http://localhost:45678/sqlinject/jdbcwrong --data name=test
一段时间后,sqlmap 给出了如下结果:
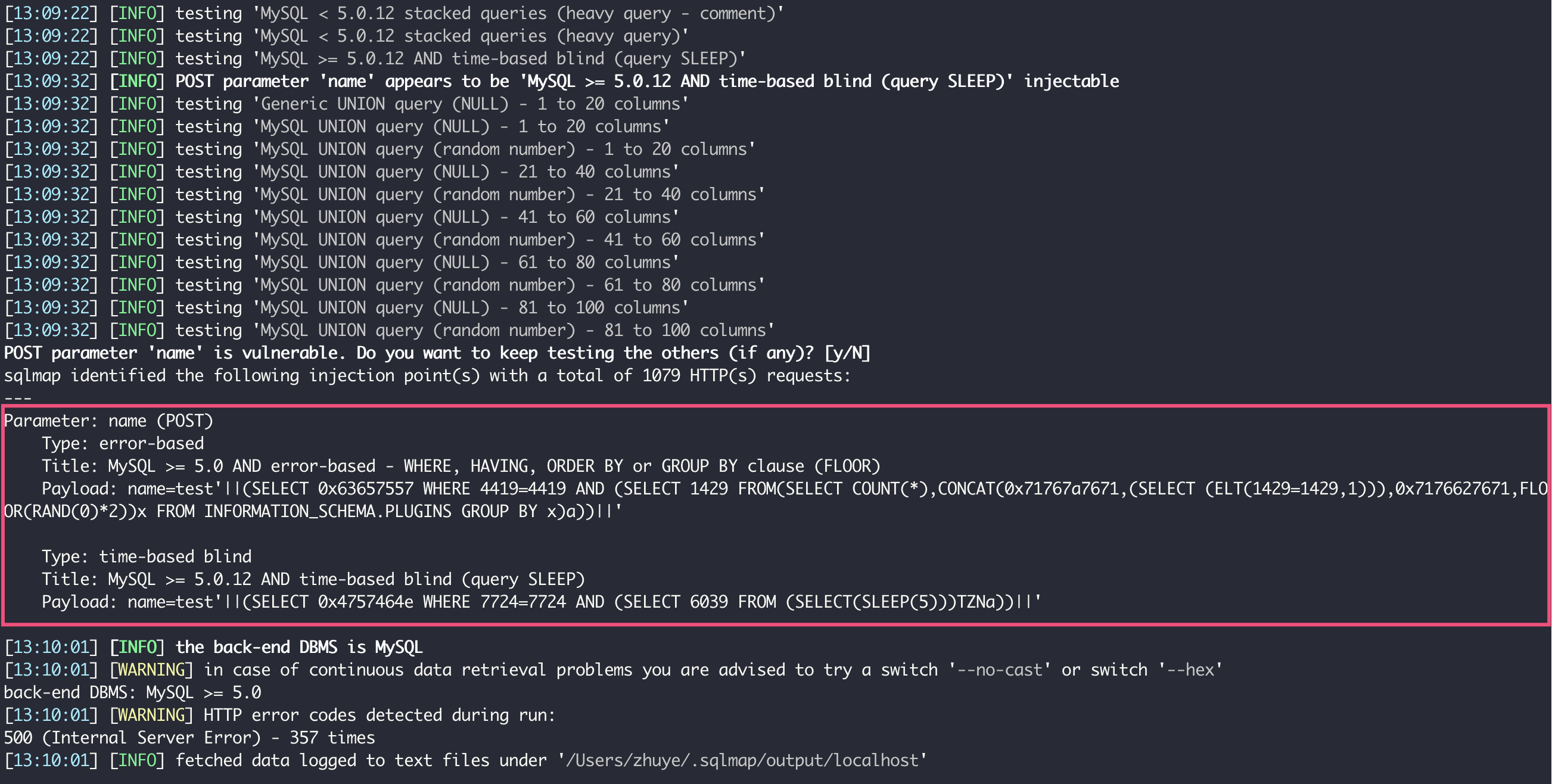
可以看到,这个接口的 name 参数有两种可能的注入方式:一种是报错注入,一种是基于时间的盲注。
接下来,仅需简单的三步,就可以直接导出整个用户表的内容了。
第一步,查询当前数据库:
python sqlmap.py -u http://localhost:45678/sqlinject/jdbcwrong --data name=test --current-db
可以得到当前数据库是 common_mistakes:
current database: 'common_mistakes'
第二步,查询数据库下的表:
python sqlmap.py -u http://localhost:45678/sqlinject/jdbcwrong --data name=test --tables -D "common_mistakes"
可以看到其中有一个敏感表 userdata:
Database: common_mistakes
[7 tables]
+--------------------+
| user |
| common_store |
| hibernate_sequence |
| m |
| news |
| r |
| userdata |
+--------------------+
2
3
4
5
6
7
8
9
10
11
第三步,查询 userdata 的数据:
python sqlmap.py -u http://localhost:45678/sqlinject/jdbcwrong --data name=test -D "common_mistakes" -T "userdata" --dump
你看,用户密码信息一览无遗。当然,你也可以继续查看其他表的数据:
Database: common_mistakes
Table: userdata
[2 entries]
+----+-------+----------+
| id | name | password |
+----+-------+----------+
| 1 | test1 | haha1 |
| 2 | test2 | haha2 |
+----+-------+----------+
2
3
4
5
6
7
8
9
在日志中可以看到,sqlmap 实现拖库的方式是,让 SQL 执行后的出错信息包含字段内容。注意看下错误日志的第二行,错误信息中包含 ID 为 2 的用户的密码字段的值“haha2”。这,就是报错注入的基本原理:
[13:22:27.375] [http-nio-45678-exec-10] [ERROR] [o.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.dao.DuplicateKeyException: StatementCallback; SQL [SELECT id,name FROM userdata WHERE name LIKE '%test'||(SELECT 0x694a6e64 WHERE 3941=3941 AND (SELECT 9927 FROM(SELECT COUNT(*),CONCAT(0x71626a7a71,(SELECT MID((IFNULL(CAST(password AS NCHAR),0x20)),1,54) FROM common_mistakes.userdata ORDER BY id LIMIT 1,1),0x7170706271,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a))||'%']; Duplicate entry 'qbjzqhaha2qppbq1' for key '<group_key>'; nested exception is java.sql.SQLIntegrityConstraintViolationException: Duplicate entry 'qbjzqhaha2qppbq1' for key '<group_key>'] with root cause
java.sql.SQLIntegrityConstraintViolationException: Duplicate entry 'qbjzqhaha2qppbq1' for key '<group_key>'
2
既然是这样,我们就实现一个 ExceptionHandler 来屏蔽异常,看看能否解决注入问题:
@ExceptionHandler
public void handle(HttpServletRequest req, HandlerMethod method, Exception ex) {
log.warn(String.format("访问 %s -> %s 出现异常!", req.getRequestURI(), method.toString()), ex);
}
2
3
4
重启程序后重新运行刚才的 sqlmap 命令,可以看到报错注入是没戏了,但使用时间盲注还是可以查询整个表的数据:
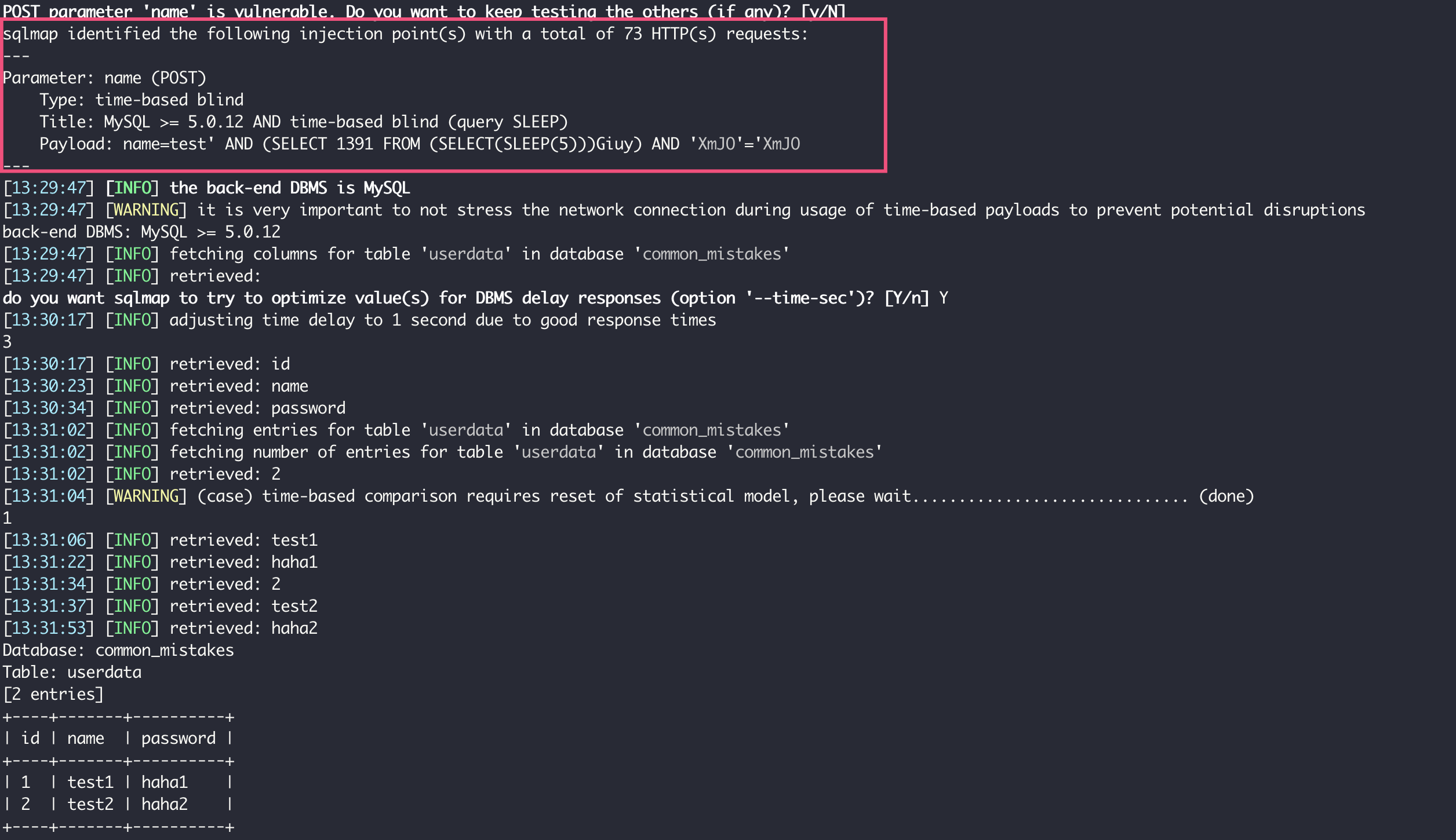
所谓盲注,指的是注入后并不能从服务器得到任何执行结果(甚至是错误信息),只能寄希望服务器对于 SQL 中的真假条件表现出不同的状态。比如,对于布尔盲注来说,可能是“真”可以得到 200 状态码,“假”可以得到 500 错误状态码;或者,“真”可以得到内容输出,“假”得不到任何输出。总之,对于不同的 SQL 注入可以得到不同的输出即可。
在这个案例中,因为接口没有输出,也彻底屏蔽了错误,布尔盲注这招儿行不通了。那么退而求其次的方式,就是时间盲注。也就是说,通过在真假条件中加入 SLEEP,来实现通过判断接口的响应时间,知道条件的结果是真还是假。
不管是什么盲注,都是通过真假两种状态来完成的。你可能会好奇,通过真假两种状态如何实现数据导出?
其实你可以想一下,我们虽然不能直接查询出 password 字段的值,但可以按字符逐一来查,判断第一个字符是否是 a、是否是 b……,查询到 h 时发现响应变慢了,自然知道这就是真的,得出第一位就是 h。以此类推,可以查询出整个值。
所以,sqlmap 在返回数据的时候,也是一个字符一个字符跳出结果的,并且时间盲注的整个过程会比报错注入慢许多。
你可以引入 p6spy (opens new window) 工具打印出所有执行的 SQL,观察 sqlmap 构造的一些 SQL,来分析其中原理:
<dependency>
<groupId>com.github.gavlyukovskiy</groupId>
<artifactId>p6spy-spring-boot-starter</artifactId>
<version>1.6.1</version>
</dependency>
2
3
4
5

所以说,即使屏蔽错误信息错误码,也不能彻底防止 SQL 注入。真正的解决方式,还是使用参数化查询,让任何外部输入值只可能作为数据来处理。
比如,对于之前那个接口,在 SQL 语句中使用“?”作为参数占位符,然后提供参数值。这样修改后,sqlmap 也就无能为力了:
@PostMapping("jdbcright")
public void jdbcright(@RequestParam("name") String name) {
log.info("{}", jdbcTemplate.queryForList("SELECT id,name FROM userdata WHERE name LIKE ?", "%" + name + "%"));
}
2
3
4
对于 MyBatis 来说,同样需要使用参数化的方式来写 SQL 语句。在 MyBatis 中,“#{}”是参数化的方式,“${}”只是占位符替换。
比如 LIKE 语句。因为使用“#{}”会为参数带上单引号,导致 LIKE 语法错误,所以一些同学会退而求其次,选择“${}”的方式,比如:
@Select("SELECT id,name FROM `userdata` WHERE name LIKE '%${name}%'")
List<UserData> findByNameWrong(@Param("name") String name);
2
你可以尝试一下,使用 sqlmap 同样可以实现注入。正确的做法是,使用“#{}”来参数化 name 参数,对于 LIKE 操作可以使用 CONCAT 函数来拼接 % 符号:
@Select("SELECT id,name FROM `userdata` WHERE name LIKE CONCAT('%',#{name},'%')")
List<UserData> findByNameRight(@Param("name") String name);
2
又比如 IN 子句。因为涉及多个元素的拼接,一些同学不知道如何处理,也可能会选择使用“${}”。因为使用“#{}”会把输入当做一个字符串来对待:
<select id="findByNamesWrong" resultType="org.geekbang.time.commonmistakes.codeanddata.sqlinject.UserData">
SELECT id,name FROM `userdata` WHERE name in (${names})
</select>
2
3
但是,这样直接把外部传入的内容替换到 IN 内部,同样会有注入漏洞:
@PostMapping("mybatiswrong2")
public List mybatiswrong2(@RequestParam("names") String names) {
return userDataMapper.findByNamesWrong(names);
}
2
3
4
你可以使用下面这条命令测试下:
python sqlmap.py -u http://localhost:45678/sqlinject/mybatiswrong2 --data names="'test1','test2'"
最后可以发现,有 4 种可行的注入方式,分别是布尔盲注、报错注入、时间盲注和联合查询注入:
修改方式是,给 MyBatis 传入一个 List,然后使用其 foreach 标签来拼接出 IN 中的内容,并确保 IN 中的每一项都是使用“#{}”来注入参数:
@PostMapping("mybatisright2")
public List mybatisright2(@RequestParam("names") List<String> names) {
return userDataMapper.findByNamesRight(names);
}
<select id="findByNamesRight" resultType="org.geekbang.time.commonmistakes.codeanddata.sqlinject.UserData">
SELECT id,name FROM `userdata` WHERE name in
<foreach collection="names" item="item" open="(" separator="," close=")">
#{item}
</foreach>
</select>
2
3
4
5
6
7
8
9
10
11
修改后这个接口就不会被注入了,你可以自行测试一下。
# 小心动态执行代码时代码注入漏洞
总结下,我们刚刚看到的 SQL 注入漏洞的原因是,黑客把 SQL 攻击代码通过传参混入 SQL 语句中执行。同样,对于任何解释执行的其他语言代码,也可以产生类似的注入漏洞。我们看一个动态执行 JavaScript 代码导致注入漏洞的案例。
现在,我们要对用户名实现动态的规则判断:通过 ScriptEngineManager 获得一个 JavaScript 脚本引擎,使用 Java 代码来动态执行 JavaScript 代码,实现当外部传入的用户名为 admin 的时候返回 1,否则返回 0:
private ScriptEngineManager scriptEngineManager = new ScriptEngineManager();
//获得JavaScript脚本引擎
private ScriptEngine jsEngine = scriptEngineManager.getEngineByName("js");
@GetMapping("wrong")
public Object wrong(@RequestParam("name") String name) {
try {
//通过eval动态执行JavaScript脚本,这里name参数通过字符串拼接方式混入JavaScript代码
return jsEngine.eval(String.format("var name='%s'; name=='admin'?1:0;", name));
} catch (ScriptException e) {
e.printStackTrace();
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这个功能本身没什么问题:

但是,如果我们把传入的用户名修改为这样:
haha';java.lang.System.exit(0);'
就可以达到关闭整个程序的目的。原因是,我们直接把代码和数据拼接在了一起。外部如果构造了一个特殊的用户名先闭合字符串的单引号,再执行一条 System.exit 命令的话,就可以满足脚本不出错,命令被执行。
解决这个问题有两种方式。
第一种方式和解决 SQL 注入一样,需要把外部传入的条件数据仅仅当做数据来对待。我们可以通过 SimpleBindings 来绑定参数初始化 name 变量,而不是直接拼接代码:
@GetMapping("right")
public Object right(@RequestParam("name") String name) {
try {
//外部传入的参数
Map<String, Object> parm = new HashMap<>();
parm.put("name", name);
//name参数作为绑定传给eval方法,而不是拼接JavaScript代码
return jsEngine.eval("name=='admin'?1:0;", new SimpleBindings(parm));
} catch (ScriptException e) {
e.printStackTrace();
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
这样就避免了注入问题:

第二种解决方法是,使用 SecurityManager 配合 AccessControlContext,来构建一个脚本运行的沙箱环境。脚本能执行的所有操作权限,是通过 setPermissions 方法精细化设置的:
@Slf4j
public class ScriptingSandbox {
private ScriptEngine scriptEngine;
private AccessControlContext accessControlContext;
private SecurityManager securityManager;
private static ThreadLocal<Boolean> needCheck = ThreadLocal.withInitial(() -> false);
public ScriptingSandbox(ScriptEngine scriptEngine) throws InstantiationException {
this.scriptEngine = scriptEngine;
securityManager = new SecurityManager(){
//仅在需要的时候检查权限
@Override
public void checkPermission(Permission perm) {
if (needCheck.get() && accessControlContext != null) {
super.checkPermission(perm, accessControlContext);
}
}
};
//设置执行脚本需要的权限
setPermissions(Arrays.asList(
new RuntimePermission("getProtectionDomain"),
new PropertyPermission("jdk.internal.lambda.dumpProxyClasses","read"),
new FilePermission(Shell.class.getProtectionDomain().getPermissions().elements().nextElement().getName(),"read"),
new RuntimePermission("createClassLoader"),
new RuntimePermission("accessClassInPackage.jdk.internal.org.objectweb.*"),
new RuntimePermission("accessClassInPackage.jdk.nashorn.internal.*"),
new RuntimePermission("accessDeclaredMembers"),
new ReflectPermission("suppressAccessChecks")
));
}
//设置执行上下文的权限
public void setPermissions(List<Permission> permissionCollection) {
Permissions perms = new Permissions();
if (permissionCollection != null) {
for (Permission p : permissionCollection) {
perms.add(p);
}
}
ProtectionDomain domain = new ProtectionDomain(new CodeSource(null, (CodeSigner[]) null), perms);
accessControlContext = new AccessControlContext(new ProtectionDomain[]{domain});
}
public Object eval(final String code) {
SecurityManager oldSecurityManager = System.getSecurityManager();
System.setSecurityManager(securityManager);
needCheck.set(true);
try {
//在AccessController的保护下执行脚本
return AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
try {
return scriptEngine.eval(code);
} catch (ScriptException e) {
e.printStackTrace();
}
return null;
}, accessControlContext);
} catch (Exception ex) {
log.error("抱歉,无法执行脚本 {}", code, ex);
} finally {
needCheck.set(false);
System.setSecurityManager(oldSecurityManager);
}
return null;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
写一段测试代码,使用刚才定义的 ScriptingSandbox 沙箱工具类来执行脚本:
@GetMapping("right2")
public Object right2(@RequestParam("name") String name) throws InstantiationException {
//使用沙箱执行脚本
ScriptingSandbox scriptingSandbox = new ScriptingSandbox(jsEngine);
return scriptingSandbox.eval(String.format("var name='%s'; name=='admin'?1:0;", name));
}
2
3
4
5
6
这次,我们再使用之前的注入脚本调用这个接口:
http://localhost:45678/codeinject/right2?name=haha%27;java.lang.System.exit(0);%27
可以看到,结果中抛出了 AccessControlException 异常,注入攻击失效了:
[13:09:36.080] [http-nio-45678-exec-1] [ERROR] [o.g.t.c.c.codeinject.ScriptingSandbox:77 ] - 抱歉,无法执行脚本 var name='haha';java.lang.System.exit(0);''; name=='admin'?1:0;
java.security.AccessControlException: access denied ("java.lang.RuntimePermission" "exitVM.0")
at java.security.AccessControlContext.checkPermission(AccessControlContext.java:472)
at java.lang.SecurityManager.checkPermission(SecurityManager.java:585)
at org.geekbang.time.commonmistakes.codeanddata.codeinject.ScriptingSandbox$1.checkPermission(ScriptingSandbox.java:30)
at java.lang.SecurityManager.checkExit(SecurityManager.java:761)
at java.lang.Runtime.exit(Runtime.java:107)
2
3
4
5
6
7
在实际应用中,我们可以考虑同时使用这两种方法,确保代码执行的安全性。
# XSS 必须全方位严防死堵
对于业务开发来说,XSS 的问题同样要引起关注。
XSS 问题的根源在于,原本是让用户传入或输入正常数据的地方,被黑客替换为了 JavaScript 脚本,页面没有经过转义直接显示了这个数据,然后脚本就被执行了。更严重的是,脚本没有经过转义就保存到了数据库中,随后页面加载数据的时候,数据中混入的脚本又当做代码执行了。黑客可以利用这个漏洞来盗取敏感数据,诱骗用户访问钓鱼网站等。
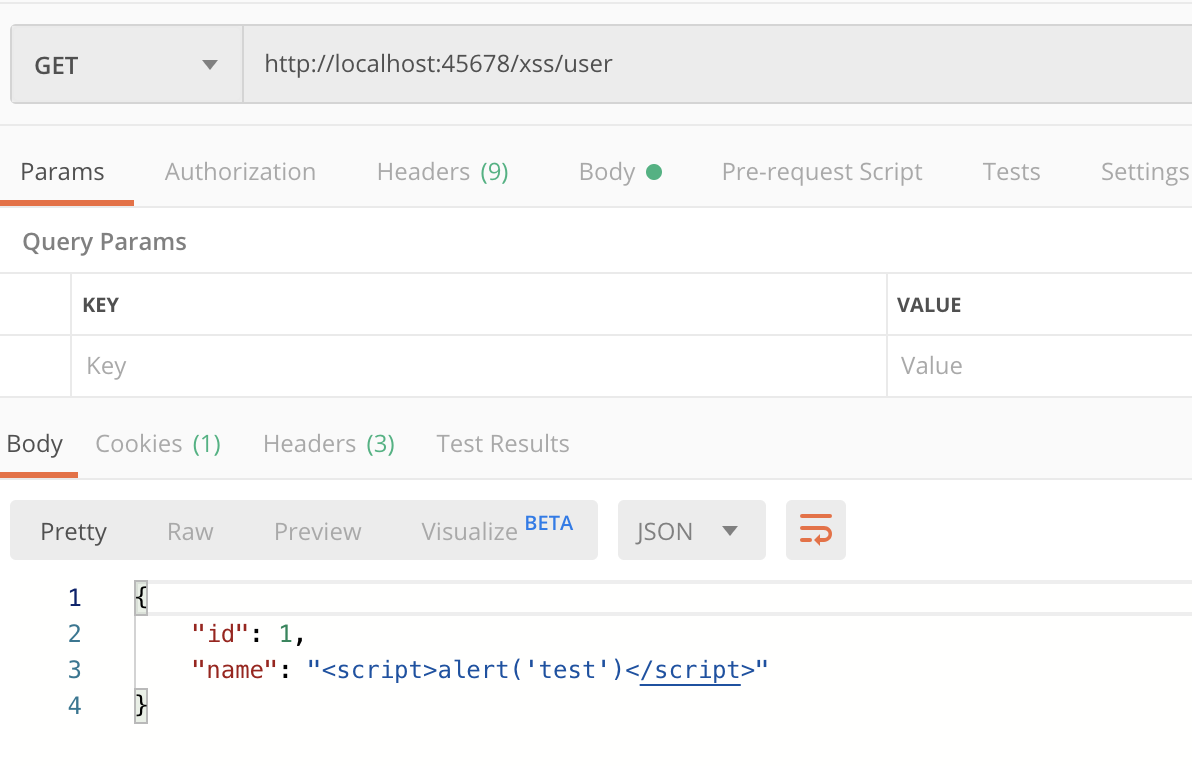
我们写一段代码测试下。首先,服务端定义两个接口,其中 index 接口查询用户名信息返回给 xss 页面,save 接口使用 @RequestParam 注解接收用户名,并创建用户保存到数据库;然后,重定向浏览器到 index 接口:
@RequestMapping("xss")
@Slf4j
@Controller
public class XssController {
@Autowired
private UserRepository userRepository;
//显示xss页面
@GetMapping
public String index(ModelMap modelMap) {
//查数据库
User user = userRepository.findById(1L).orElse(new User());
//给View提供Model
modelMap.addAttribute("username", user.getName());
return "xss";
}
//保存用户信息
@PostMapping
public String save(@RequestParam("username") String username, HttpServletRequest request) {
User user = new User();
user.setId(1L);
user.setName(username);
userRepository.save(user);
//保存完成后重定向到首页
return "redirect:/xss/";
}
}
//用户类,同时作为DTO和Entity
@Entity
@Data
public class User {
@Id
private Long id;
private String name;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
我们使用 Thymeleaf 模板引擎来渲染页面。模板代码比较简单,页面加载的时候会在标签显示用户名,用户输入用户名提交后调用 save 接口创建用户:
<div style="font-size: 14px">
<form id="myForm" method="post" th:action="@{/xss/}">
<label th:utext="${username}"/>
<input id="username" name="username" size="100" type="text"/>
<button th:text="Register" type="submit"/>
</form>
</div>
2
3
4
5
6
7
打开 xss 页面后,在文本框中输入 点击 Register 按钮提交,页面会弹出 alert 对话框:

并且,脚本被保存到了数据库:

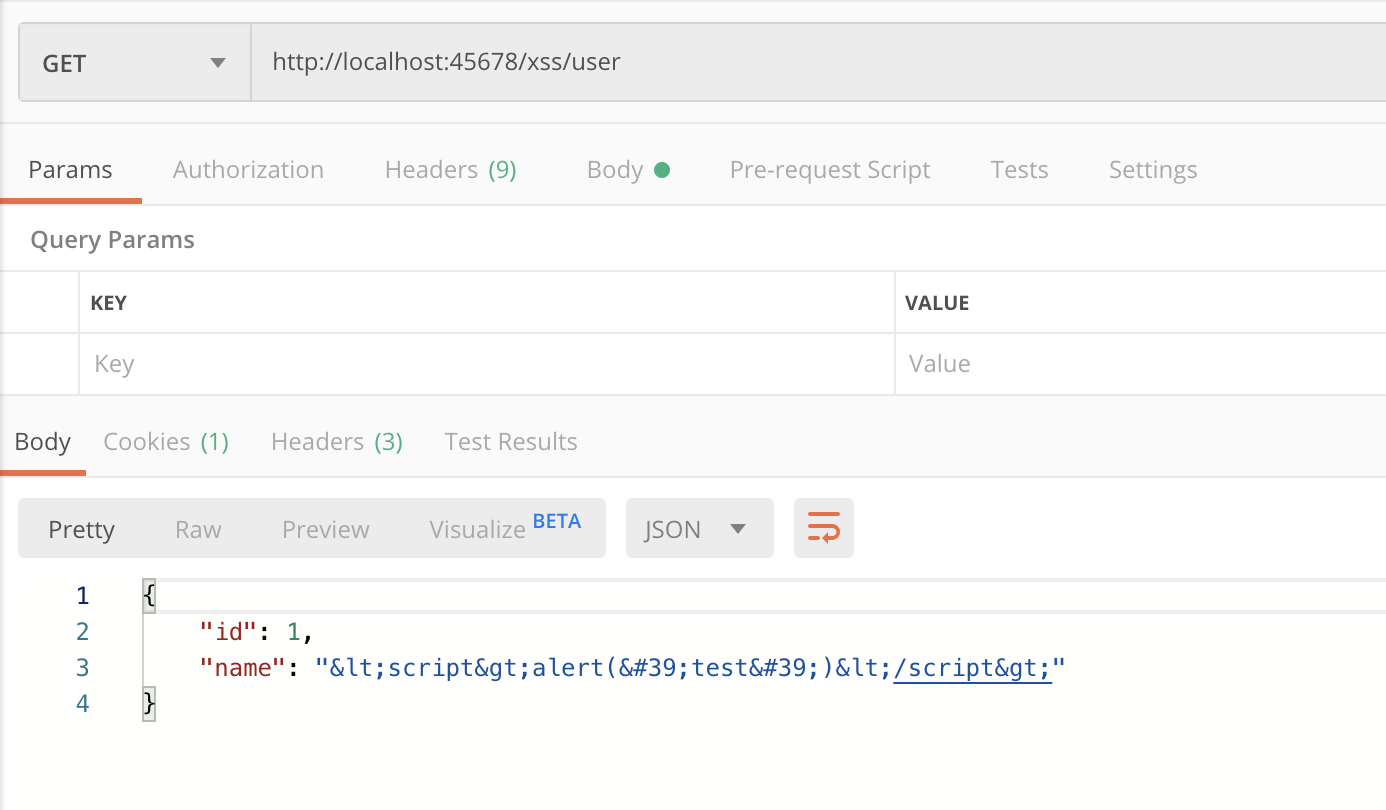
你可能想到了,解决方式就是 HTML 转码。既然是通过 @RequestParam 来获取请求参数,那我们定义一个 @InitBinder 实现数据绑定的时候,对字符串进行转码即可:
@ControllerAdvice
public class SecurityAdvice {
@InitBinder
protected void initBinder(WebDataBinder binder) {
//注册自定义的绑定器
binder.registerCustomEditor(String.class, new PropertyEditorSupport() {
@Override
public String getAsText() {
Object value = getValue();
return value != null ? value.toString() : "";
}
@Override
public void setAsText(String text) {
//赋值时进行HTML转义
setValue(text == null ? null : HtmlUtils.htmlEscape(text));
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
的确,针对这个场景,这种做法是可行的。数据库中保存了转义后的数据,因此数据会被当做 HTML 显示在页面上,而不是当做脚本执行:

但是,这种处理方式犯了一个严重的错误,那就是没有从根儿上来处理安全问题。因为 @InitBinder 是 Spring Web 层面的处理逻辑,如果有代码不通过 @RequestParam 来获取数据,而是直接从 HTTP 请求获取数据的话,这种方式就不会奏效。比如这样:
user.setName(request.getParameter("username"));
更合理的解决方式是,定义一个 servlet Filter,通过 HttpServletRequestWrapper 实现 servlet 层面的统一参数替换:
//自定义过滤器
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class XssFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
chain.doFilter(new XssRequestWrapper((HttpServletRequest) request), response);
}
}
public class XssRequestWrapper extends HttpServletRequestWrapper {
public XssRequestWrapper(HttpServletRequest request) {
super(request);
}
@Override
public String[] getParameterValues(String parameter) {
//获取多个参数值的时候对所有参数值应用clean方法逐一清洁
return Arrays.stream(super.getParameterValues(parameter)).map(this::clean).toArray(String[]::new);
}
@Override
public String getHeader(String name) {
//同样清洁请求头
return clean(super.getHeader(name));
}
@Override
public String getParameter(String parameter) {
//获取参数单一值也要处理
return clean(super.getParameter(parameter));
}
//clean方法就是对值进行HTML转义
private String clean(String value) {
return StringUtils.isEmpty(value)? "" : HtmlUtils.htmlEscape(value);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
这样,我们就可以实现所有请求参数的 HTML 转义了。不过,这种方式还是不够彻底,原因是无法处理通过 @RequestBody 注解提交的 JSON 数据。比如,有这样一个 PUT 接口,直接保存了客户端传入的 JSON User 对象:
@PutMapping
public void put(@RequestBody User user) {
userRepository.save(user);
}
2
3
4
通过 Postman 请求这个接口,保存到数据库中的数据还是没有转义:

我们需要自定义一个 Jackson 反列化器,来实现反序列化时的字符串的 HTML 转义:
//注册自定义的Jackson反序列器
@Bean
public Module xssModule() {
SimpleModule module = new SimpleModule();
module.module.addDeserializer(String.class, new XssJsonDeserializer());
return module;
}
public class XssJsonDeserializer extends JsonDeserializer<String> {
@Override
public String deserialize(JsonParser jsonParser, DeserializationContext ctxt) throws IOException, JsonProcessingException {
String value = jsonParser.getValueAsString();
if (value != null) {
//对于值进行HTML转义
return HtmlUtils.htmlEscape(value);
}
return value;
}
@Override
public Class<String> handledType() {
return String.class;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
这样就实现了既能转义 Get/Post 通过请求参数提交的数据,又能转义请求体中直接提交的 JSON 数据。
你可能觉得做到这里,我们的防范已经很全面了,但其实不是。这种只能堵新漏,确保新数据进入数据库之前转义。如果因为之前的漏洞,数据库中已经保存了一些 JavaScript 代码,那么读取的时候同样可能出问题。因此,我们还要实现数据读取的时候也转义。
接下来,我们看一下具体的实现方式。
首先,之前我们处理了 JSON 反序列化问题,那么就需要同样处理序列化,实现数据从数据库中读取的时候转义,否则读出来的 JSON 可能包含 JavaScript 代码。
比如,我们定义这样一个 GET 接口以 JSON 来返回用户信息:
@GetMapping("user")
@ResponseBody
public User query() {
return userRepository.findById(1L).orElse(new User());
}
2
3
4
5
修改之前的 SimpleModule 加入自定义序列化器,并且实现序列化时处理字符串转义:
//注册自定义的Jackson序列器
@Bean
public Module xssModule() {
SimpleModule module = new SimpleModule();
module.addDeserializer(String.class, new XssJsonDeserializer());
module.addSerializer(String.class, new XssJsonSerializer());
return module;
}
public class XssJsonSerializer extends JsonSerializer<String> {
@Override
public Class<String> handledType() {
return String.class;
}
@Override
public void serialize(String value, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
if (value != null) {
//对字符串进行HTML转义
jsonGenerator.writeString(HtmlUtils.htmlEscape(value));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
可以看到,这次读到的 JSON 也转义了:
其次,我们还需要处理 HTML 模板。对于 Thymeleaf 模板引擎,需要注意的是,使用 th:utext 来显示数据是不会进行转义的,需要使用 th:text:
<label th:text="${username}"/>
经过修改后,即使数据库中已经保存了 JavaScript 代码,呈现的时候也只能作为 HTML 显示了。现在,对于进和出两个方向,我们都实现了补漏。
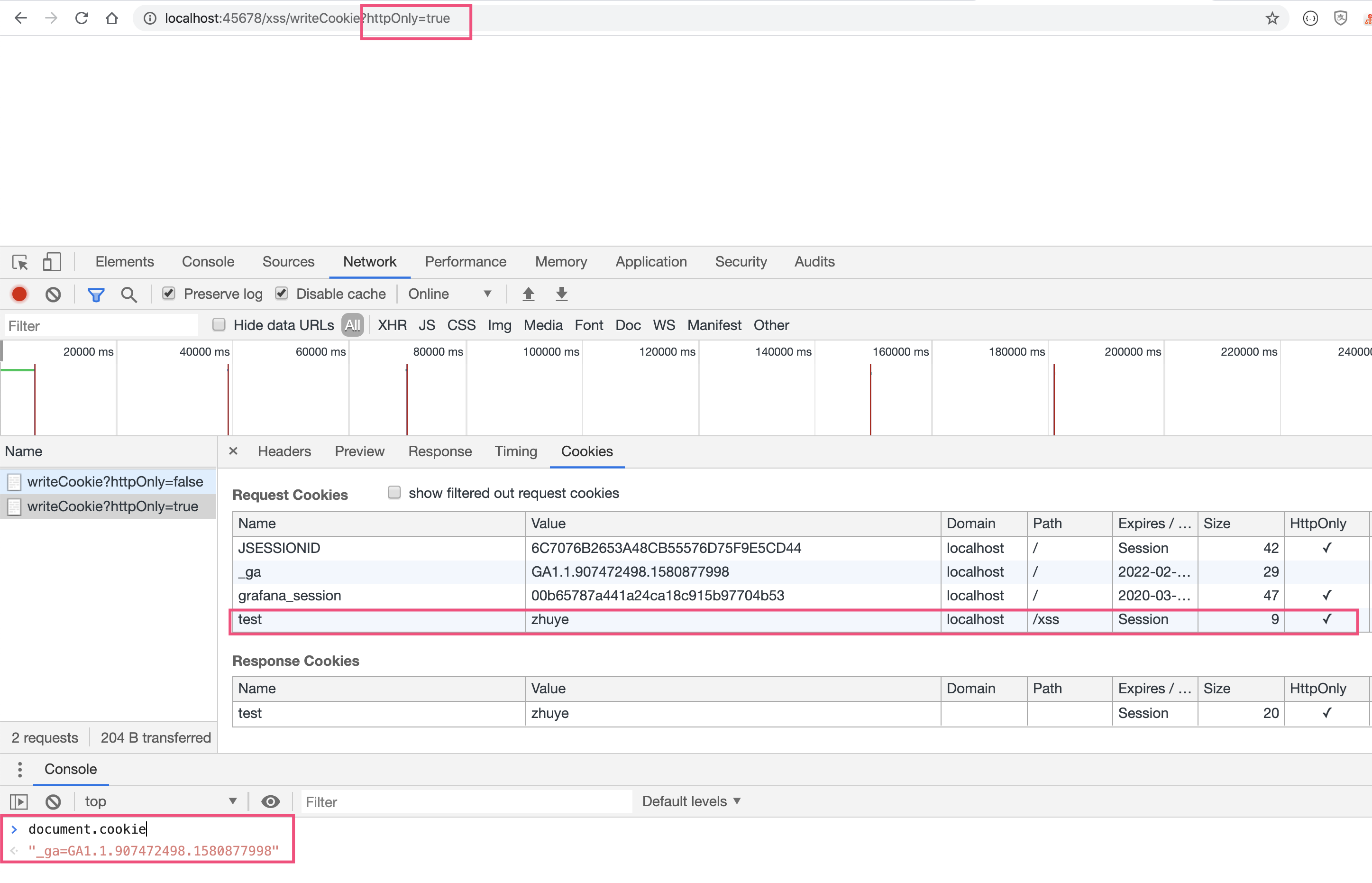
但所谓百密总有一疏。为了避免疏漏,进一步控制 XSS 可能带来的危害,我们还要考虑一种情况:如果需要在 Cookie 中写入敏感信息的话,我们可以开启 HttpOnly 属性。这样 JavaScript 代码就无法读取 Cookie 了,即便页面被 XSS 注入了攻击代码,也无法获得我们的 Cookie。
写段代码测试一下。定义两个接口,其中 readCookie 接口读取 Key 为 test 的 Cookie,writeCookie 接口写入 Cookie,根据参数 HttpOnly 确定 Cookie 是否开启 HttpOnly:
//服务端读取Cookie
@GetMapping("readCookie")
@ResponseBody
public String readCookie(@CookieValue("test") String cookieValue) {
return cookieValue;
}
//服务端写入Cookie
@GetMapping("writeCookie")
@ResponseBody
public void writeCookie(@RequestParam("httpOnly") boolean httpOnly, HttpServletResponse response) {
Cookie cookie = new Cookie("test", "zhuye");
//根据httpOnly入参决定是否开启HttpOnly属性
cookie.setHttpOnly(httpOnly);
response.addCookie(cookie);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
可以看到,由于 test 和 _ga 这两个 Cookie 不是 HttpOnly 的。通过 document.cookie 可以输出这两个 Cookie 的内容:
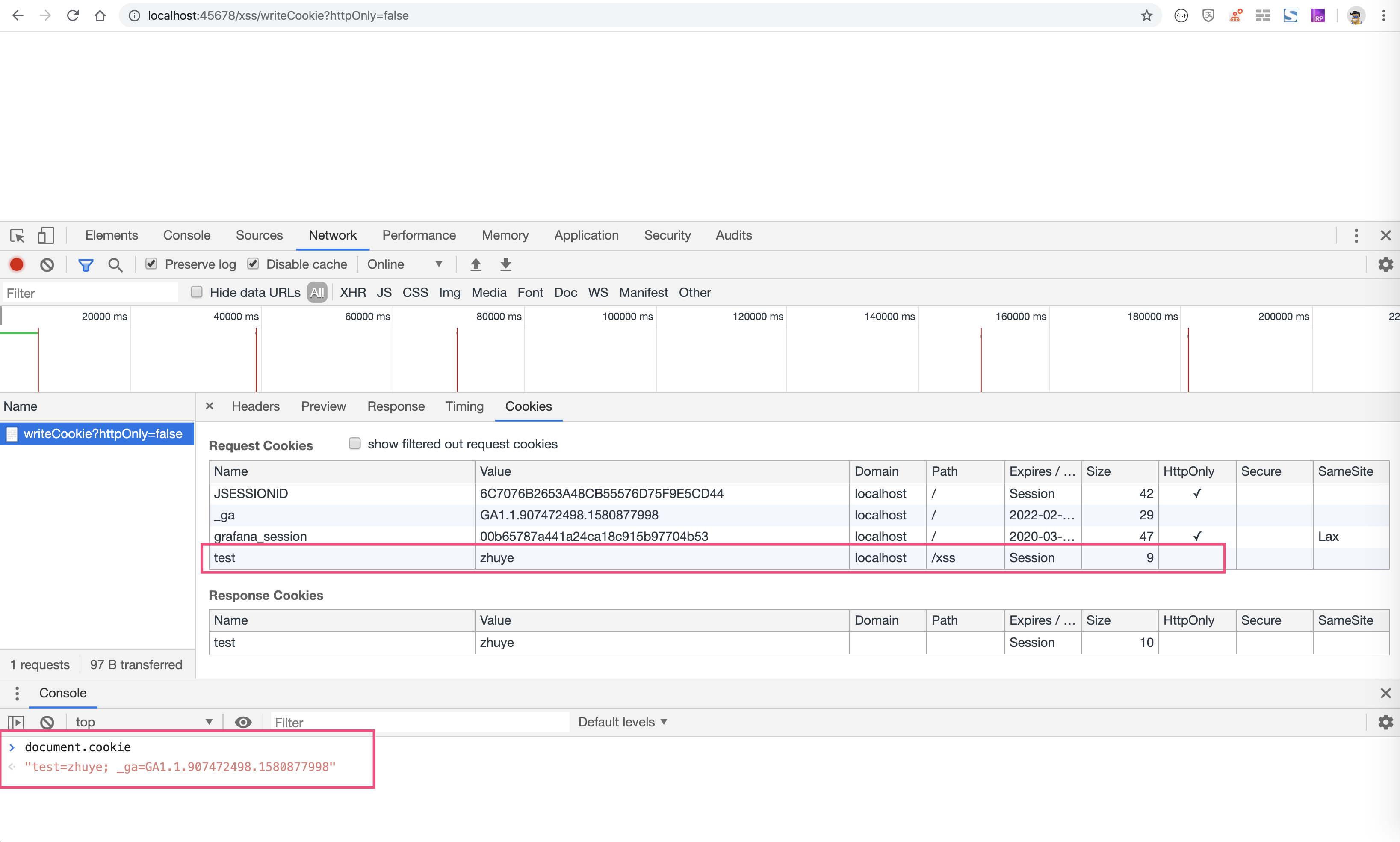
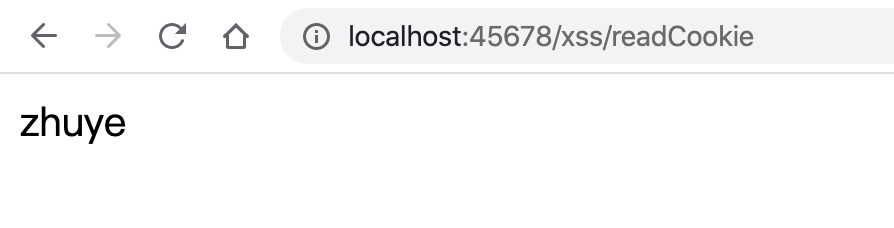
为 test 这个 Cookie 启用了 HttpOnly 属性后,就不能被 document.cookie 读取到了,输出中只有 _ga 一项:
但是服务端可以读取到这个 cookie:
# 如何正确保存和传输敏感数据?
# 应该怎样保存用户密码?
最敏感的数据恐怕就是用户的密码了。黑客一旦窃取了用户密码,或许就可以登录进用户的账号,消耗其资产、发布不良信息等;更可怕的是,有些用户至始至终都是使用一套密码,密码一旦泄露,就可以被黑客用来登录全网。
为了防止密码泄露,最重要的原则是不要保存用户密码。你可能会觉得很好笑,不保存用户密码,之后用户登录的时候怎么验证?其实指的是不保存原始密码,这样即使拖库也不会泄露用户密码。
经常会听到大家说,不要明文保存用户密码,应该把密码通过 MD5 加密后保存。这的确是一个正确的方向,但这个说法并不准确。
首先,MD5 其实不是真正的加密算法。所谓加密算法,是可以使用密钥把明文加密为密文,随后还可以使用密钥解密出明文,是双向的。
而 MD5 是散列、哈希算法或者摘要算法。不管多长的数据,使用 MD5 运算后得到的都是固定长度的摘要信息或指纹信息,无法再解密为原始数据。所以 MD5 是单向的。最重要的是,仅仅使用 MD5 对密码进行摘要,并不安全。
比如,使用如下代码在保持用户信息时,对密码进行了 MD5 计算:
UserData userData = new UserData();
userData.setId(1L);
userData.setName(name);
//密码字段使用MD5哈希后保存
userData.setPassword(DigestUtils.md5Hex(password));
return userRepository.save(userData);
2
3
4
5
6
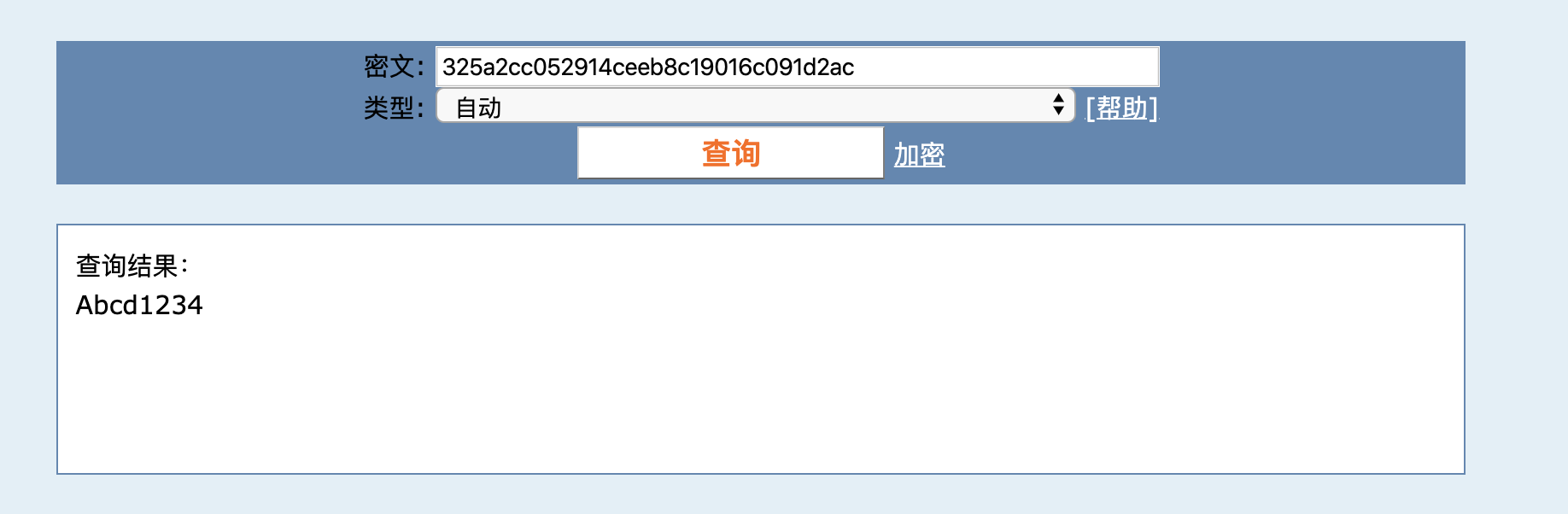
通过输出,可以看到密码是 32 位的 MD5:
"password": "325a2cc052914ceeb8c19016c091d2ac"
到某 MD5 破解网站上输入这个 MD5,不到 1 秒就得到了原始密码:
其实你可以想一下,虽然 MD5 不可解密,但是我们可以构建一个超大的数据库,把所有 20 位以内的数字和字母组合的密码全部计算一遍 MD5 存进去,需要解密的时候搜索一下 MD5 就可以得到原始值了。这就是字典表。
目前,有些 MD5 解密网站使用的是彩虹表,是一种使用时间空间平衡的技术,即可以使用更大的空间来降低破解时间,也可以使用更长的破解时间来换取更小的空间。
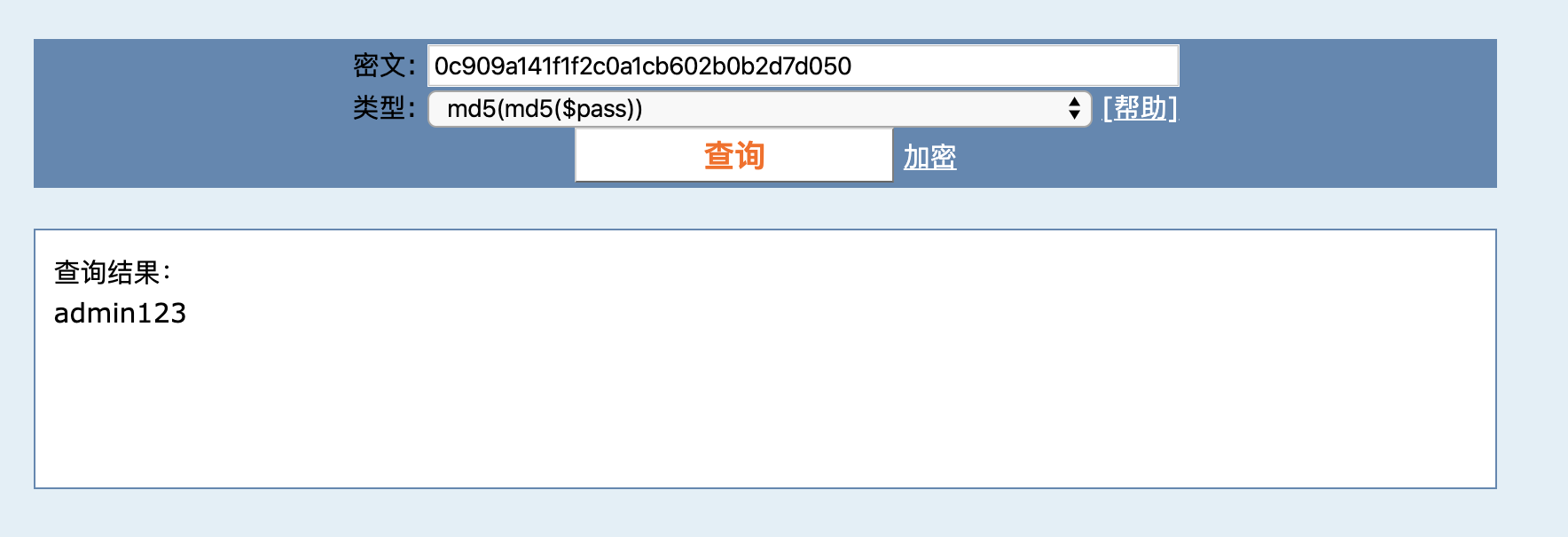
此外,你可能会觉得多次 MD5 比较安全,其实并不是这样。比如,如下代码使用两次 MD5 进行摘要:
userData.setPassword(DigestUtils.md5Hex(DigestUtils.md5Hex( password)));
得到下面的 MD5:
"password": "ebbca84993fe002bac3a54e90d677d09"
也可以破解出密码,并且破解网站还告知我们这是两次 MD5 算法:
所以直接保存 MD5 后的密码是不安全的。一些同学可能会说,还需要加盐。是的,但是加盐如果不当,还是非常不安全,比较重要的有两点。
第一,不能在代码中写死盐,且盐需要有一定的长度,比如这样:
userData.setPassword(DigestUtils.md5Hex("salt" + password));
得到了如下 MD5:
"password": "58b1d63ed8492f609993895d6ba6b93a"
对于这样一串 MD5,虽然破解网站上找不到原始密码,但是黑客可以自己注册一个账号,使用一个简单的密码,比如 1:
"password": "55f312f84e7785aa1efa552acbf251db"
然后,再去破解网站试一下这个 MD5,就可以得到原始密码是 salt,也就知道了盐值是 salt:
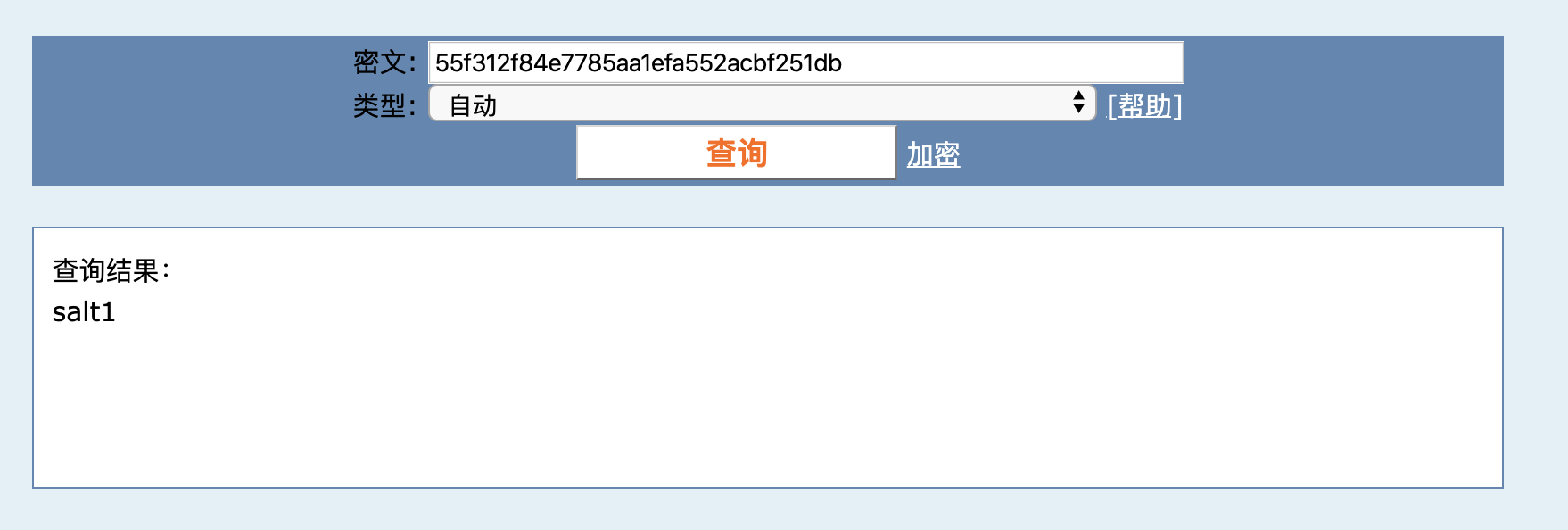
其实,知道盐是什么没什么关系,关键的是我们是在代码里写死了盐,并且盐很短、所有用户都是这个盐。这么做有三个问题:
- 因为盐太短、太简单了,如果用户原始密码也很简单,那么整个拼起来的密码也很短,这样一般的 MD5 破解网站都可以直接解密这个 MD5,除去盐就知道原始密码了。
- 相同的盐,意味着使用相同密码的用户 MD5 值是一样的,知道了一个用户的密码就可能知道了多个。
- 我们也可以使用这个盐来构建一张彩虹表,虽然会花不少代价,但是一旦构建完成,所有人的密码都可以被破解。
所以,最好是每一个密码都有独立的盐,并且盐要长一点,比如超过 20 位。
第二,虽然说每个人的盐最好不同,但也不建议将一部分用户数据作为盐。比如,使用用户名作为盐:
userData.setPassword(DigestUtils.md5Hex(name + password));
如果世界上所有的系统都是按照这个方案来保存密码,那么 root、admin 这样的用户使用再复杂的密码也总有一天会被破解,因为黑客们完全可以针对这些常用用户名来做彩虹表。所以,盐最好是随机的值,并且是全球唯一的,意味着全球不可能有现成的彩虹表给你用。
正确的做法是,使用全球唯一的、和用户无关的、足够长的随机值作为盐。比如,可以使用 UUID 作为盐,把盐一起保存到数据库中:
userData.setSalt(UUID.randomUUID().toString());
userData.setPassword(DigestUtils.md5Hex(userData.getSalt() + password));
2
并且每次用户修改密码的时候都重新计算盐,重新保存新的密码。你可能会问,盐保存在数据库中,那被拖库了不是就可以看到了吗?难道不应该加密保存吗?
一般盐没有必要加密保存。盐的作用是,防止通过彩虹表快速实现密码“解密”,如果用户的盐都是唯一的,那么生成一次彩虹表只可能拿到一个用户的密码,这样黑客的动力会小很多。
更好的做法是,不要使用像 MD5 这样快速的摘要算法,而是使用慢一点的算法。比如 Spring Security 已经废弃了 MessageDigestPasswordEncoder,推荐使用 BCryptPasswordEncoder,也就是 BCrypt (opens new window) 来进行密码哈希。BCrypt 是为保存密码设计的算法,相比 MD5 要慢很多。
写段代码来测试一下 MD5,以及使用不同代价因子的 BCrypt,看看哈希一次密码的耗时。
private static BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
@GetMapping("performance")
public void performance() {
StopWatch stopWatch = new StopWatch();
String password = "Abcd1234";
stopWatch.start("MD5");
//MD5
DigestUtils.md5Hex(password);
stopWatch.stop();
stopWatch.start("BCrypt(10)");
//代价因子为10的BCrypt
String hash1 = BCrypt.gensalt(10);
BCrypt.hashpw(password, hash1);
System.out.println(hash1);
stopWatch.stop();
stopWatch.start("BCrypt(12)");
//代价因子为12的BCrypt
String hash2 = BCrypt.gensalt(12);
BCrypt.hashpw(password, hash2);
System.out.println(hash2);
stopWatch.stop();
stopWatch.start("BCrypt(14)");
//代价因子为14的BCrypt
String hash3 = BCrypt.gensalt(14);
BCrypt.hashpw(password, hash3);
System.out.println(hash3);
stopWatch.stop();
log.info("{}", stopWatch.prettyPrint());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
可以看到,MD5 只需要 0.8 毫秒,而三次 BCrypt 哈希(代价因子分别设置为 10、12 和 14)耗时分别是 82 毫秒、312 毫秒和 1.2 秒:

也就是说,如果制作 8 位密码长度的 MD5 彩虹表需要 5 个月,那么对于 BCrypt 来说,可能就需要几十年,大部分黑客应该都没有这个耐心。
我们写一段代码观察下,BCryptPasswordEncoder 生成的密码哈希的规律:
@GetMapping("better")
public UserData better(@RequestParam(value = "name", defaultValue = "zhuye") String name, @RequestParam(value = "password", defaultValue = "Abcd1234") String password) {
UserData userData = new UserData();
userData.setId(1L);
userData.setName(name);
//保存哈希后的密码
userData.setPassword(passwordEncoder.encode(password));
userRepository.save(userData);
//判断密码是否匹配
log.info("match ? {}", passwordEncoder.matches(password, userData.getPassword()));
return userData;
}
2
3
4
5
6
7
8
9
10
11
12
我们可以发现三点规律。
第一,我们调用 encode、matches 方法进行哈希、做密码比对的时候,不需要传入盐。BCrypt 把盐作为了算法的一部分,强制我们遵循安全保存密码的最佳实践。
第二,生成的盐和哈希后的密码拼在了一起:$ 是字段分隔符,其中第一个 $ 后的 2a 代表算法版本,第二个 $ 后的 10 是代价因子(默认是 10,代表 2 的 10 次方次哈希),第三个 $ 后的 22 个字符是盐,再后面是摘要。所以说,我们不需要使用单独的数据库字段来保存盐。
"password": "$2a$10$wPWdQwfQO2lMxqSIb6iCROXv7lKnQq5XdMO96iCYCj7boK9pk6QPC"
//格式为:$<ver>$<cost>$<salt><digest>
2
第三,代价因子的值越大,BCrypt 哈希的耗时越久。因此,对于代价因子的值,更建议的实践是,根据用户的忍耐程度和硬件,设置一个尽可能大的值。
最后,我们需要注意的是,虽然黑客已经很难通过彩虹表来破解密码了,但是仍然有可能暴力破解密码,也就是对于同一个用户名使用常见的密码逐一尝试登录。因此,除了做好密码哈希保存的工作外,我们还要建设一套完善的安全防御机制,在感知到暴力破解危害的时候,开启短信验证、图形验证码、账号暂时锁定等防御机制来抵御暴力破解。
# 应该怎么保存姓名和身份证?
我们把姓名和身份证,叫做二要素。
现在互联网非常发达,很多服务都可以在网上办理,很多网站仅仅依靠二要素来确认你是谁。所以,二要素是比较敏感的数据,如果在数据库中明文保存,那么数据库被攻破后,黑客就可能拿到大量的二要素信息。如果这些二要素被用来申请贷款等,后果不堪设想。
之前我们提到的单向散列算法,显然不适合用来加密保存二要素,因为数据无法解密。这个时候,我们需要选择真正的加密算法。可供选择的算法,包括对称加密和非对称加密算法两类。
对称加密算法,是使用相同的密钥进行加密和解密。使用对称加密算法来加密双方的通信的话,双方需要先约定一个密钥,加密方才能加密,接收方才能解密。如果密钥在发送的时候被窃取,那么加密就是白忙一场。因此,这种加密方式的特点是,加密速度比较快,但是密钥传输分发有泄露风险。
非对称加密算法,或者叫公钥密码算法。公钥密码是由一对密钥对构成的,使用公钥或者说加密密钥来加密,使用私钥或者说解密密钥来解密,公钥可以任意公开,私钥不能公开。使用非对称加密的话,通信双方可以仅分享公钥用于加密,加密后的数据没有私钥无法解密。因此,这种加密方式的特点是,加密速度比较慢,但是解决了密钥的配送分发安全问题。
但是,对于保存敏感信息的场景来说,加密和解密都是我们的服务端程序,不太需要考虑密钥的分发安全性,也就是说使用非对称加密算法没有太大的意义。在这里,我们使用对称加密算法来加密数据。
接下来就重点与你说说对称加密算法。对称加密常用的加密算法,有 DES、3DES 和 AES。
虽然,现在仍有许多老项目使用了 DES 算法,但不推荐使用。在 1999 年的 DES 挑战赛 3 中,DES 密码破解耗时不到一天,而现在 DES 密码破解更快,使用 DES 来加密数据非常不安全。因此,在业务代码中要避免使用 DES 加密。
而 3DES 算法,是使用不同的密钥进行三次 DES 串联调用,虽然解决了 DES 不够安全的问题,但是比 AES 慢,也不太推荐。
AES 是当前公认的比较安全,兼顾性能的对称加密算法。不过严格来说,AES 并不是实际的算法名称,而是算法标准。2000 年,NIST 选拔出 Rijndael 算法作为 AES 的标准。
AES 有一个重要的特点就是分组加密体制,一次只能处理 128 位的明文,然后生成 128 位的密文。如果要加密很长的明文,那么就需要迭代处理,而迭代方式就叫做模式。网上很多使用 AES 来加密的代码,使用的是最简单的 ECB 模式(也叫电子密码本模式),其基本结构如下:
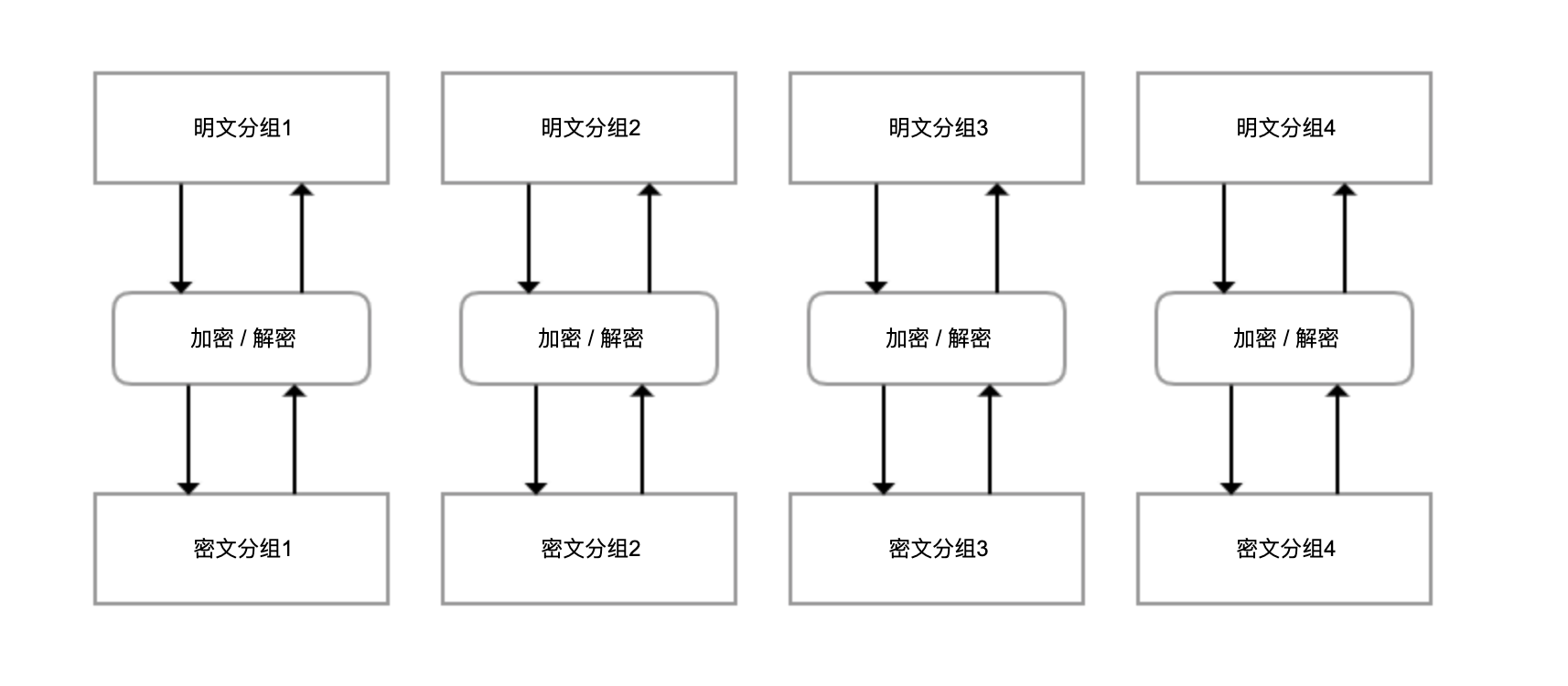
可以看到,这种结构有两个风险:明文和密文是一一对应的,如果明文中有重复的分组,那么密文中可以观察到重复,掌握密文的规律;因为每一个分组是独立加密和解密的 ,如果密文分组的顺序,也可以反过来操纵明文,那么就可以实现不解密密文的情况下,来修改明文。
我们写一段代码来测试下。在下面的代码中,我们使用 ECB 模式测试:
- 加密一段包含 16 个字符的字符串,得到密文 A;然后把这段字符串复制一份成为一个 32 个字符的字符串,再进行加密得到密文 B。我们验证下密文 B 是不是重复了一遍的密文 A。
- 模拟银行转账的场景,假设整个数据由发送方账号、接收方账号、金额三个字段构成。我们尝试改变密文中数据的顺序来操纵明文。
private static final String KEY = "secretkey1234567"; //密钥
//测试ECB模式
@GetMapping("ecb")
public void ecb() throws Exception {
Cipher cipher = Cipher.getInstance("AES/ECB/NoPadding");
test(cipher, null);
}
//获取加密秘钥帮助方法
private static SecretKeySpec setKey(String secret) {
return new SecretKeySpec(secret.getBytes(), "AES");
}
//测试逻辑
private static void test(Cipher cipher, AlgorithmParameterSpec parameterSpec) throws Exception {
//初始化Cipher
cipher.init(Cipher.ENCRYPT_MODE, setKey(KEY), parameterSpec);
//加密测试文本
System.out.println("一次:" + Hex.encodeHexString(cipher.doFinal("abcdefghijklmnop".getBytes())));
//加密重复一次的测试文本
System.out.println("两次:" + Hex.encodeHexString(cipher.doFinal("abcdefghijklmnopabcdefghijklmnop".getBytes())));
//下面测试是否可以通过操纵密文来操纵明文
//发送方账号
byte[] sender = "1000000000012345".getBytes();
//接收方账号
byte[] receiver = "1000000000034567".getBytes();
//转账金额
byte[] money = "0000000010000000".getBytes();
//加密发送方账号
System.out.println("发送方账号:" + Hex.encodeHexString(cipher.doFinal(sender)));
//加密接收方账号
System.out.println("接收方账号:" + Hex.encodeHexString(cipher.doFinal(receiver)));
//加密金额
System.out.println("金额:" + Hex.encodeHexString(cipher.doFinal(money)));
//加密完整的转账信息
byte[] result = cipher.doFinal(ByteUtils.concatAll(sender, receiver, money));
System.out.println("完整数据:" + Hex.encodeHexString(result));
//用于操纵密文的临时字节数组
byte[] hack = new byte[result.length];
//把密文前两段交换
System.arraycopy(result, 16, hack, 0, 16);
System.arraycopy(result, 0, hack, 16, 16);
System.arraycopy(result, 32, hack, 32, 16);
cipher.init(Cipher.DECRYPT_MODE, setKey(KEY), parameterSpec);
//尝试解密
System.out.println("原始明文:" + new String(ByteUtils.concatAll(sender, receiver, money)));
System.out.println("操纵密文:" + new String(cipher.doFinal(hack)));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
输出如下:

可以看到:
- 两个相同明文分组产生的密文,就是两个相同的密文分组叠在一起。
- 在不知道密钥的情况下,我们操纵密文实现了对明文数据的修改,对调了发送方账号和接收方账号。
所以说,ECB 模式虽然简单,但是不安全,不推荐使用。我们再看一下另一种常用的加密模式,CBC 模式。
CBC 模式,在解密或解密之前引入了 XOR 运算,第一个分组使用外部提供的初始化向量 IV,从第二个分组开始使用前一个分组的数据,这样即使明文是一样的,加密后的密文也是不同的,并且分组的顺序不能任意调换。这就解决了 ECB 模式的缺陷:

我们把之前的代码修改为 CBC 模式,再次进行测试:
private static final String initVector = "abcdefghijklmnop"; //初始化向量
@GetMapping("cbc")
public void cbc() throws Exception {
Cipher cipher = Cipher.getInstance("AES/CBC/NoPadding");
IvParameterSpec iv = new IvParameterSpec(initVector.getBytes("UTF-8"));
test(cipher, iv);
}
2
3
4
5
6
7
8
可以看到,相同的明文字符串复制一遍得到的密文并不是重复两个密文分组,并且调换密文分组的顺序无法操纵明文:

其实,除了 ECB 模式和 CBC 模式外,AES 算法还有 CFB、OFB、CTR 模式,你可以参考这里 (opens new window)了解它们的区别。《实用密码学》一书比较推荐的是 CBC 和 CTR 模式。还需要注意的是,ECB 和 CBC 模式还需要设置合适的填充模式,才能处理超过一个分组的数据。
对于敏感数据保存,除了选择 AES+ 合适模式进行加密外,还推荐以下几个实践:
- 不要在代码中写死一个固定的密钥和初始化向量,最好和之前提到的盐一样,是唯一、独立并且每次都变化的。
- 推荐使用独立的加密服务来管控密钥、做加密操作,千万不要把密钥和密文存在一个数据库,加密服务需要设置非常高的管控标准。
- 数据库中不能保存明文的敏感信息,但可以保存脱敏的信息。普通查询的时候,直接查脱敏信息即可。
接下来,我们按照这个策略完成相关代码实现。
第一步,对于用户姓名和身份证,我们分别保存三个信息,脱敏后的明文、密文和加密 ID。加密服务加密后返回密文和加密 ID,随后使用加密 ID 来请求加密服务进行解密:
@Data
@Entity
public class UserData {
@Id
private Long id;
private String idcard;//脱敏的身份证
private Long idcardCipherId;//身份证加密ID
private String idcardCipherText;//身份证密文
private String name;//脱敏的姓名
private Long nameCipherId;//姓名加密ID
private String nameCipherText;//姓名密文
}
2
3
4
5
6
7
8
9
10
11
12
第二步,加密服务数据表保存加密 ID、初始化向量和密钥。加密服务表中没有密文,实现了密文和密钥分离保存:
@Data
@Entity
public class CipherData {
@Id
@GeneratedValue(strategy = AUTO)
private Long id;
private String iv;//初始化向量
private String secureKey;//密钥
}
2
3
4
5
6
7
8
9
第三步,加密服务使用 GCM 模式( Galois/Counter Mode)的 AES-256 对称加密算法,也就是 AES-256-GCM。
这是一种 AEAD (opens new window)(Authenticated Encryption with Associated Data)认证加密算法,除了能实现普通加密算法提供的保密性之外,还能实现可认证性和密文完整性,是目前最推荐的 AES 模式。
使用类似 GCM 的 AEAD 算法进行加解密,除了需要提供初始化向量和密钥之外,还可以提供一个 AAD(附加认证数据,additional authenticated data),用于验证未包含在明文中的附加信息,解密时不使用加密时的 AAD 将解密失败。其实,GCM 模式的内部使用的就是 CTR 模式,只不过还使用了 GMAC 签名算法,对密文进行签名实现完整性校验。
接下来,我们实现基于 AES-256-GCM 的加密服务,包含下面的主要逻辑:
- 加密时允许外部传入一个 AAD 用于认证,加密服务每次都会使用新生成的随机值作为密钥和初始化向量。
- 在加密后,加密服务密钥和初始化向量保存到数据库中,返回加密 ID 作为本次加密的标识。
- 应用解密时,需要提供加密 ID、密文和加密时的 AAD 来解密。加密服务使用加密 ID,从数据库查询出密钥和初始化向量。
这段逻辑的实现代码比较长,加了详细注释方便你仔细阅读:
@Service
public class CipherService {
//密钥长度
public static final int AES_KEY_SIZE = 256;
//初始化向量长度
public static final int GCM_IV_LENGTH = 12;
//GCM身份认证Tag长度
public static final int GCM_TAG_LENGTH = 16;
@Autowired
private CipherRepository cipherRepository;
//内部加密方法
public static byte[] doEncrypt(byte[] plaintext, SecretKey key, byte[] iv, byte[] aad) throws Exception {
//加密算法
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
//Key规范
SecretKeySpec keySpec = new SecretKeySpec(key.getEncoded(), "AES");
//GCM参数规范
GCMParameterSpec gcmParameterSpec = new GCMParameterSpec(GCM_TAG_LENGTH * 8, iv);
//加密模式
cipher.init(Cipher.ENCRYPT_MODE, keySpec, gcmParameterSpec);
//设置aad
if (aad != null)
cipher.updateAAD(aad);
//加密
byte[] cipherText = cipher.doFinal(plaintext);
return cipherText;
}
//内部解密方法
public static String doDecrypt(byte[] cipherText, SecretKey key, byte[] iv, byte[] aad) throws Exception {
//加密算法
Cipher cipher = Cipher.getInstance("AES/GCM/NoPadding");
//Key规范
SecretKeySpec keySpec = new SecretKeySpec(key.getEncoded(), "AES");
//GCM参数规范
GCMParameterSpec gcmParameterSpec = new GCMParameterSpec(GCM_TAG_LENGTH * 8, iv);
//解密模式
cipher.init(Cipher.DECRYPT_MODE, keySpec, gcmParameterSpec);
//设置aad
if (aad != null)
cipher.updateAAD(aad);
//解密
byte[] decryptedText = cipher.doFinal(cipherText);
return new String(decryptedText);
}
//加密入口
public CipherResult encrypt(String data, String aad) throws Exception {
//加密结果
CipherResult encryptResult = new CipherResult();
//密钥生成器
KeyGenerator keyGenerator = KeyGenerator.getInstance("AES");
//生成密钥
keyGenerator.init(AES_KEY_SIZE);
SecretKey key = keyGenerator.generateKey();
//IV数据
byte[] iv = new byte[GCM_IV_LENGTH];
//随机生成IV
SecureRandom random = new SecureRandom();
random.nextBytes(iv);
//处理aad
byte[] aaddata = null;
if (!StringUtils.isEmpty(aad))
aaddata = aad.getBytes();
//获得密文
encryptResult.setCipherText(Base64.getEncoder().encodeToString(doEncrypt(data.getBytes(), key, iv, aaddata)));
//加密上下文数据
CipherData cipherData = new CipherData();
//保存IV
cipherData.setIv(Base64.getEncoder().encodeToString(iv));
//保存密钥
cipherData.setSecureKey(Base64.getEncoder().encodeToString(key.getEncoded()));
cipherRepository.save(cipherData);
//返回本地加密ID
encryptResult.setId(cipherData.getId());
return encryptResult;
}
//解密入口
public String decrypt(long cipherId, String cipherText, String aad) throws Exception {
//使用加密ID找到加密上下文数据
CipherData cipherData = cipherRepository.findById(cipherId).orElseThrow(() -> new IllegalArgumentException("invlaid cipherId"));
//加载密钥
byte[] decodedKey = Base64.getDecoder().decode(cipherData.getSecureKey());
//初始化密钥
SecretKey originalKey = new SecretKeySpec(decodedKey, 0, decodedKey.length, "AES");
//加载IV
byte[] decodedIv = Base64.getDecoder().decode(cipherData.getIv());
//处理aad
byte[] aaddata = null;
if (!StringUtils.isEmpty(aad))
aaddata = aad.getBytes();
//解密
return doDecrypt(Base64.getDecoder().decode(cipherText.getBytes()), originalKey, decodedIv, aaddata);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
第四步,分别实现加密和解密接口用于测试。
我们可以让用户选择,如果需要保护二要素的话,就自己输入一个查询密码作为 AAD。系统需要读取用户敏感信息的时候,还需要用户提供这个密码,否则无法解密。这样一来,即使黑客拿到了用户数据库的密文、加密服务的密钥和 IV,也会因为缺少 AAD 无法解密:
@Autowired
private CipherService cipherService;
//加密
@GetMapping("right")
public UserData right(@RequestParam(value = "name", defaultValue = "朱晔") String name,
@RequestParam(value = "idcard", defaultValue = "300000000000001234") String idCard,
@RequestParam(value = "aad", required = false)String aad) throws Exception {
UserData userData = new UserData();
userData.setId(1L);
//脱敏姓名
userData.setName(chineseName(name));
//脱敏身份证
userData.setIdcard(idCard(idCard));
//加密姓名
CipherResult cipherResultName = cipherService.encrypt(name,aad);
userData.setNameCipherId(cipherResultName.getId());
userData.setNameCipherText(cipherResultName.getCipherText());
//加密身份证
CipherResult cipherResultIdCard = cipherService.encrypt(idCard,aad);
userData.setIdcardCipherId(cipherResultIdCard.getId());
userData.setIdcardCipherText(cipherResultIdCard.getCipherText());
return userRepository.save(userData);
}
//解密
@GetMapping("read")
public void read(@RequestParam(value = "aad", required = false)String aad) throws Exception {
//查询用户信息
UserData userData = userRepository.findById(1L).get();
//使用AAD来解密姓名和身份证
log.info("name : {} idcard : {}",
cipherService.decrypt(userData.getNameCipherId(), userData.getNameCipherText(),aad),
cipherService.decrypt(userData.getIdcardCipherId(), userData.getIdcardCipherText(),aad));
}
//脱敏身份证
private static String idCard(String idCard) {
String num = StringUtils.right(idCard, 4);
return StringUtils.leftPad(num, StringUtils.length(idCard), "*");
}
//脱敏姓名
public static String chineseName(String chineseName) {
String name = StringUtils.left(chineseName, 1);
return StringUtils.rightPad(name, StringUtils.length(chineseName), "*");
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
访问加密接口获得如下结果,可以看到数据库表中只有脱敏数据和密文:
{"id":1,"name":"朱*","idcard":"**************1234","idcardCipherId":26346,"idcardCipherText":"t/wIh1XTj00wJP1Lt3aGzSvn9GcqQWEwthN58KKU4KZ4Tw==","nameCipherId":26347,"nameCipherText":"+gHrk1mWmveBMVUo+CYon8Zjj9QAtw=="}
访问解密接口,可以看到解密成功了:
[21:46:00.079] [http-nio-45678-exec-6] [INFO ] [o.g.t.c.s.s.StoreIdCardController:102 ] - name : 朱晔 idcard : 300000000000001234
如果 AAD 输入不对,会得到如下异常:
javax.crypto.AEADBadTagException: Tag mismatch!
at com.sun.crypto.provider.GaloisCounterMode.decryptFinal(GaloisCounterMode.java:578)
at com.sun.crypto.provider.CipherCore.finalNoPadding(CipherCore.java:1116)
at com.sun.crypto.provider.CipherCore.fillOutputBuffer(CipherCore.java:1053)
at com.sun.crypto.provider.CipherCore.doFinal(CipherCore.java:853)
at com.sun.crypto.provider.AESCipher.engineDoFinal(AESCipher.java:446)
at javax.crypto.Cipher.doFinal(Cipher.java:2164)
2
3
4
5
6
7
经过这样的设计,二要素就比较安全了。黑客要查询用户二要素的话,需要同时拿到密文、IV+ 密钥、AAD。而这三者可能由三方掌管,要全部拿到比较困难。
# 用一张图说清楚 HTTPS
我们知道,HTTP 协议传输数据使用的是明文。那在传输敏感信息的场景下,如果客户端和服务端中间有一个黑客作为中间人拦截请求,就可以窃听到这些数据,还可以修改客户端传过来的数据。这就是很大的安全隐患。
为解决这个安全隐患,有了 HTTPS 协议。HTTPS=SSL/TLS+HTTP,通过使用一系列加密算法来确保信息安全传输,以实现数据传输的机密性、完整性和权威性。
- 机密性:使用非对称加密来加密密钥,然后使用密钥来加密数据,既安全又解决了非对称加密大量数据慢的问题。你可以做一个实验来测试两者的差距。
- 完整性:使用散列算法对信息进行摘要,确保信息完整无法被中间人篡改。
- 权威性:使用数字证书,来确保我们是在和合法的服务端通信。
可以看出,理解 HTTPS 的流程,将有助于我们理解各种加密算法的区别,以及证书的意义。此外,SSL/TLS 还是混合加密系统的一个典范,如果你需要自己开发应用层数据加密系统,也可以参考它的流程。
那么,我们就来看看 HTTPS TLS 1.2 连接(RSA 握手)的整个过程吧。
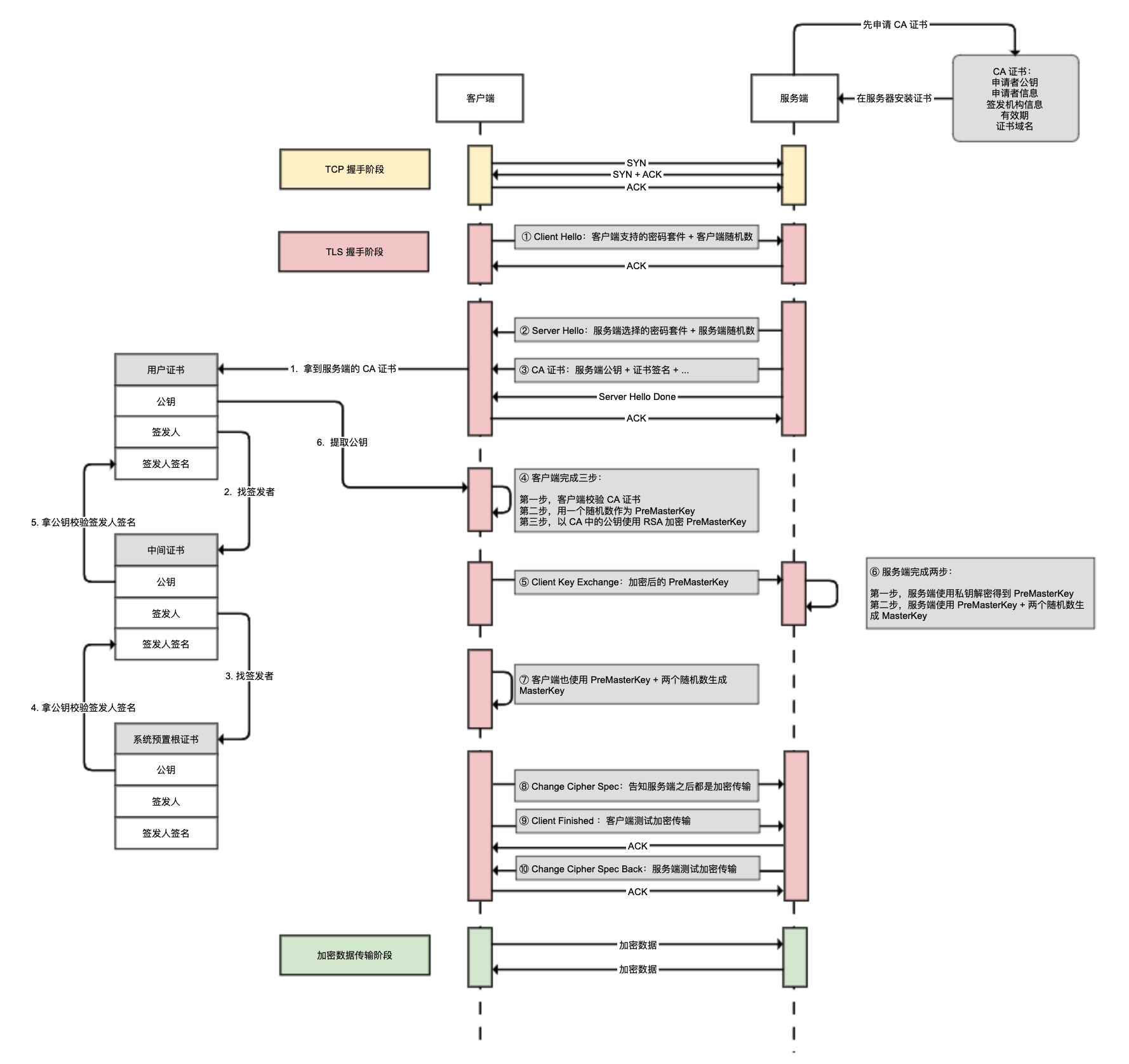
作为准备工作,网站管理员需要申请并安装 CA 证书到服务端。CA 证书中包含非对称加密的公钥、网站域名等信息,密钥是服务端自己保存的,不会在任何地方公开。
建立 HTTPS 连接的过程,首先是 TCP 握手,然后是 TLS 握手的一系列工作,包括:
- 客户端告知服务端自己支持的密码套件(比如 TLS_RSA_WITH_AES_256_GCM_SHA384,其中 RSA 是密钥交换的方式,AES_256_GCM 是加密算法,SHA384 是消息验证摘要算法),提供客户端随机数。
- 服务端应答选择的密码套件,提供服务端随机数。
- 服务端发送 CA 证书给客户端,客户端验证 CA 证书(后面详细说明)。
- 客户端生成 PreMasterKey,并使用非对称加密 + 公钥加密 PreMasterKey。
- 客户端把加密后的 PreMasterKey 传给服务端。
- 服务端使用非对称加密 + 私钥解密得到 PreMasterKey,并使用 PreMasterKey+ 两个随机数,生成 MasterKey。
- 客户端也使用 PreMasterKey+ 两个随机数生成 MasterKey。
- 客户端告知服务端之后将进行加密传输。
- 客户端使用 MasterKey 配合对称加密算法,进行对称加密测试。
- 服务端也使用 MasterKey 配合对称加密算法,进行对称加密测试。
接下来,客户端和服务端的所有通信都是加密通信,并且数据通过签名确保无法篡改。你可能会问,客户端怎么验证 CA 证书呢?
其实,CA 证书是一个证书链,你可以看一下上图的左边部分:
- 从服务端拿到的 CA 证书是用户证书,我们需要通过证书中的签发人信息找到上级中间证书,再网上找到根证书。
- 根证书只有为数不多的权威机构才能生成,一般预置在 OS 中,根本无法伪造。
- 找到根证书后,提取其公钥来验证中间证书的签名,判断其权威性。
- 最后再拿到中间证书的公钥,验证用户证书的签名。
这,就验证了用户证书的合法性,然后再校验其有效期、域名等信息进一步验证有效性。
总结一下,TLS 通过巧妙的流程和算法搭配解决了传输安全问题:使用对称加密加密数据,使用非对称加密算法确保密钥无法被中间人解密;使用 CA 证书链认证,确保中间人无法伪造自己的证书和公钥。
如果网站涉及敏感数据的传输,必须使用 HTTPS 协议。作为用户,如果你看到网站不是 HTTPS 的或者看到无效证书警告,也不应该继续使用这个网站,以免敏感信息被泄露。
# 问题解答
问题 1:在讲述用户标识不能从客户端获取这个要点的时候,提到开发同学可能会因为用户信息未打通而通过前端来传用户 ID。那我们有什么好办法,来打通不同的系统甚至不同网站的用户标识吗?
答:打通用户在不同系统之间的登录,大致有以下三种方案。
第一种,把用户身份放在统一的服务端,每一个系统都需要到这个服务端来做登录状态的确认,确认后在自己网站的 Cookie 中保存会话,这就是单点登录的做法。这种方案要求所有关联系统都对接一套中央认证服务器(中央保存用户会话),在未登录的时候跳转到中央认证服务器进行登录或登录状态确认。因此,这种方案适合一个公司内部的不同域名下的网站。
第二种,把用户身份信息直接放在 Token 中,在客户端任意传递,Token 由服务端进行校验(如果共享密钥话,甚至不需要同一个服务端进行校验),无需采用中央认证服务器,相对比较松耦合,典型的标准是 JWT。这种方案适合异构系统的跨系统用户认证打通,而且相比单点登录的方案,用户体验会更好一些。
第三种,如果需要打通不同公司系统的用户登录状态,那么一般都会采用 OAuth 2.0 的标准中的授权码模式,基本流程如下:
- 第三方网站客户端转到授权服务器,上送 ClientID、重定向地址 RedirectUri 等信息。
- 用户在授权服务器进行登录并且进行授权批准(授权批准这步可以配置为自动完成)。
- 授权完成后,重定向回到之前客户端提供的重定向地址,附上授权码。
- 第三方网站服务端通过授权码 +ClientID+ClientSecret 去授权服务器换取 Token。这里的 Token 包含访问 Token 和刷新 Token,访问 Token 过期后用刷新 Token 去获得新的访问 Token。
因为我们不会对外暴露 ClientSecret,也不会对外暴露访问 Token,同时使用授权码换取 Token 的过程是服务端进行的,客户端拿到的只是一次性的授权码,所以这种模式比较安全。
问题 2:还有一类和客户端数据相关的漏洞非常重要,那就是 URL 地址中的数据。在把匿名用户重定向到登录页面的时候,我们一般会带上 redirectUrl,这样用户登录后可以快速返回之前的页面。黑客可能会伪造一个活动链接,由真实的网站 + 钓鱼的 redirectUrl 构成,发邮件诱导用户进行登录。用户登录时访问的其实是真的网站,所以不容易察觉到 redirectUrl 是钓鱼网站,登录后却来到了钓鱼网站,用户可能会不知不觉就把重要信息泄露了。这种安全问题,我们叫做开放重定向问题。你觉得,从代码层面应该怎么预防开放重定向问题呢?
答:要从代码层面预防开放重定向问题,有以下三种做法可供参考:
- 第一种,固定重定向的目标 URL。
- 第二种,可采用编号方式指定重定向的目标 URL,也就是重定向的目标 URL 只能是在我们的白名单内的。
- 第三种,用合理充分的校验方式来校验跳转的目标地址,如果是非己方地址,就告知用户跳转有风险,小心钓鱼网站的威胁。
问题 3:防重、防刷都是事前手段,如果我们的系统正在被攻击或利用,你有什么办法及时发现问题吗?
答:对于及时发现系统正在被攻击或利用,监控是较好的手段,关键点在于报警阈值怎么设置。可以对比昨天同时、上周同时的量,发现差异达到一定百分比报警,而且报警需要有升级机制。此外,有的时候大盘很大的话,活动给整个大盘带来的变化不明显,如果进行整体监控可能出了问题也无法及时发现,因此可以考虑对于活动做独立的监控报警。
问题 4:任何三方资源的使用一般都会定期对账,如果在对账中发现我们系统记录的调用量低于对方系统记录的使用量,你觉得一般是什么问题引起的呢?
答:比如在事务内调用外部接口,调用超时后本地事务回滚本地就没有留下数据。更合适的做法是:
- 请求发出之前先记录请求数据提交事务,记录状态为未知。
- 发布调用外部接口的请求,如果可以拿到明确的结果,则更新数据库中记录的状态为成功或失败。如果出现超时或未知异常,不能假设第三方接口调用失败,需要通过查询接口查询明确的结果。
- 写一个定时任务补偿数据库中所有未知状态的记录,从第三方接口同步结果。
值得注意的是,对账的时候一定要对两边,不管哪方数据缺失都可能是因为程序逻辑有 bug,需要重视。此外,任何涉及第三方系统的交互,都建议在数据库中保持明细的请求 / 响应报文,方便在出问题的时候定位 Bug 根因。
问题 5:在讨论 SQL 注入案例时,最后那次测试我们看到 sqlmap 返回了 4 种注入方式。其中,布尔盲注、时间盲注和报错注入,我都介绍过了。你知道联合查询注入,是什么吗?
答:联合查询注入,也就是通过 UNION 来实现我们需要的信息露出,一般属于回显的注入方式。我们知道,UNION 可以用于合并两个 SELECT 查询的结果集,因此可以把注入脚本来 UNION 到原始的 SELECT 后面。这样就可以查询我们需要的数据库元数据以及表数据了。
注入的关键点在于:
- 第一,UNION 的两个 SELECT 语句的列数和字段类型需要一致。
- 第二,需要探查 UNION 后的结果和页面回显呈现数据的对应关系。
问题 6:在讨论 XSS 的时候,对于 Thymeleaf 模板引擎,我们知道如何让文本进行 HTML 转义显示。FreeMarker 也是 Java 中很常用的模板引擎,你知道如何处理转义吗?
答:其实,现在大多数的模板引擎都使用了黑名单机制,而不是白名单机制来做 HTML 转义,这样更能有效防止 XSS 漏洞。也就是,默认开启 HTML 转义,如果某些情况你不需要转义可以临时关闭。
比如,FreeMarker(2.3.24 以上版本)默认对 HTML、XHTML、XML 等文件类型(输出格式)设置了各种转义规则,你可以使用?no_esc:
<#-- 假设默认是HTML输出 --> ${'<b>test</b>'} <#-- 输出: <b>test</b> --> ${'<b>test</b>'?no_esc} <#-- 输出: <b>test</b> -->1
2
3或 noautoesc 指示器:
${'&'} <#-- 输出: & --> <#noautoesc> ${'&'} <#-- 输出: & --> ... ${'&'} <#-- 输出: & --> </#noautoesc> ${'&'} <#-- 输出: & -->1
2
3
4
5
6
7来临时关闭转义。又比如,对于模板引擎Mustache,可以使用三个花括号而不是两个花括号,来取消变量自动转义:
模板: * {{name}} * {{company}} * {{{company}}} 数据: { "name": "Chris", "company": "<b>GitHub</b>" } 输出: * Chris * * <b>GitHub</b> * <b>GitHub</b>1
2
3
4
5
6
7
8
9
10
11
12
13
14问题 7:虽然我们把用户名和密码脱敏加密保存在数据库中,但日志中可能还存在明文的敏感数据。你有什么思路在框架或中间件层面,对日志进行脱敏吗?
答:如果我们希望在日志的源头进行脱敏,那么可以在日志框架层面做。比如对于 logback 日志框架,我们可以自定义 MessageConverter,通过正则表达式匹配敏感信息脱敏。
需要注意的是,这种方式有两个缺点。
第一,正则表达式匹配敏感信息的格式不一定精确,会出现误杀漏杀的现象。一般来说,这个问题不会很严重。要实现精确脱敏的话,就只能提供各种脱敏工具类,然后让业务应用在日志中记录敏感信息的时候,先手动调用工具类进行脱敏。
第二,如果数据量比较大的话,脱敏操作可能会增加业务应用的 CPU 和内存使用,甚至会导致应用不堪负荷出现不可用。考虑到目前大部分公司都引入了 ELK 来集中收集日志,并且一般而言都不允许上服务器直接看文件日志,因此我们可以考虑在日志收集中间件中(比如 logstash)写过滤器进行脱敏。这样可以把脱敏的消耗转义到 ELK 体系中,不过这种方式同样有第一点提到的字段不精确匹配导致的漏杀误杀的缺点。
问题 8:你知道 HTTPS 双向认证的目的是什么吗?流程上又有什么区别呢?
答:单向认证一般用于 Web 网站,浏览器只需要验证服务端的身份。对于移动端 App,如果我们希望有更高的安全性,可以引入 HTTPS 双向认证,也就是除了客户端验证服务端身份之外,服务端也验证客户端的身份。
单向认证和双向认证的流程区别,主要包括以下三个方面。
第一,不仅仅服务端需要有 CA 证书,客户端也需要有 CA 证书。
第二,双向认证的流程中,客户端校验服务端 CA 证书之后,客户端会把自己的 CA 证书发给服务端,然后服务端需要校验客户端 CA 证书的真实性。
第三,客户端给服务端的消息会使用自己的私钥签名,服务端可以使用客户端 CA 证书中的公钥验签。
这里还想补充一点,对于移动应用程序考虑到更强的安全性,我们一般也会把服务端的公钥配置在客户端中,这种方式的叫做 SSL Pinning。也就是说由客户端直接校验服务端证书的合法性,而不是通过证书信任链来校验。采用 SSL Pinning,由于客户端绑定了服务端公钥,因此我们无法通过在移动设备上信用根证书实现抓包。不过这种方式的缺点是需要小心服务端 CA 证书过期后续证书注意不要修改公钥。
# 参考
- 来源:极客时间[《Java 业务开发常见错误 100例》](