 Collections 框架概览
Collections 框架概览
# Collections 框架概览
# 框架介绍
容器,就是可以容纳其他Java对象的对象。*Java Collections Framework(JCF)*为Java开发者提供了通用的容器,其始于JDK 1.2,优点是:
- 降低编程难度
- 提高程序性能
- 提高API间的互操作性
- 降低学习难度
- 降低设计和实现相关API的难度
- 增加程序的重用性
Java 容器里只能放对象,对于基本类型(int, long, float, double 等),需要将其包装成对象类型后(Integer, Long, Float, Double 等)才能放到容器里。很多时候拆包装和解包装能够自动完成。这虽然会导致额外的性能和空间开销,但简化了设计和编程。
Java 容器能够容纳任何类型的对象,这一点表面上是通过泛型机制完成,Java 泛型不是什么神奇的东西,只是编译器为我们提供的一个“语法糖”,泛型本身并不需要 Java 虚拟机的支持,只需要在编译阶段做一下简单的字符串替换即可。
由于Java 里对象都在堆上,且对象只能通过引用访问,容器里存放的其实是对象的引用而不是对象本身。
# 接口和实现
为了规范容器的行为和统一设计,JCF 定义了 14 种容器接口(collection interfaces),它们的关系如下图所示:
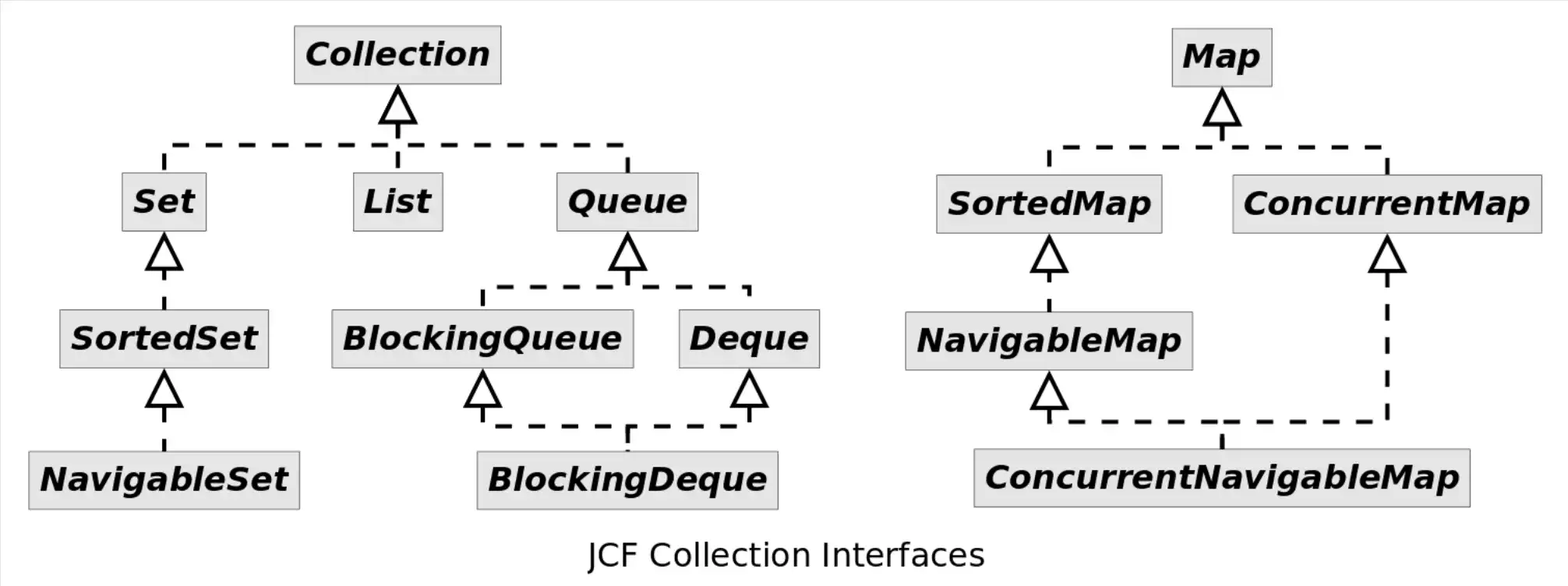
Map接口没有继承自 Collection 接口,因为 Map 表示的是关联式容器而不是集合。但 Java 为我们提供了从 Map 转换到 Collection 的方法,可以方便的将 Map 切换到集合。 上图中提供了Queue 接口,却没有 Stack,这是因为 Stack 的功能已被JDK 1.6 引入的Deque取代。
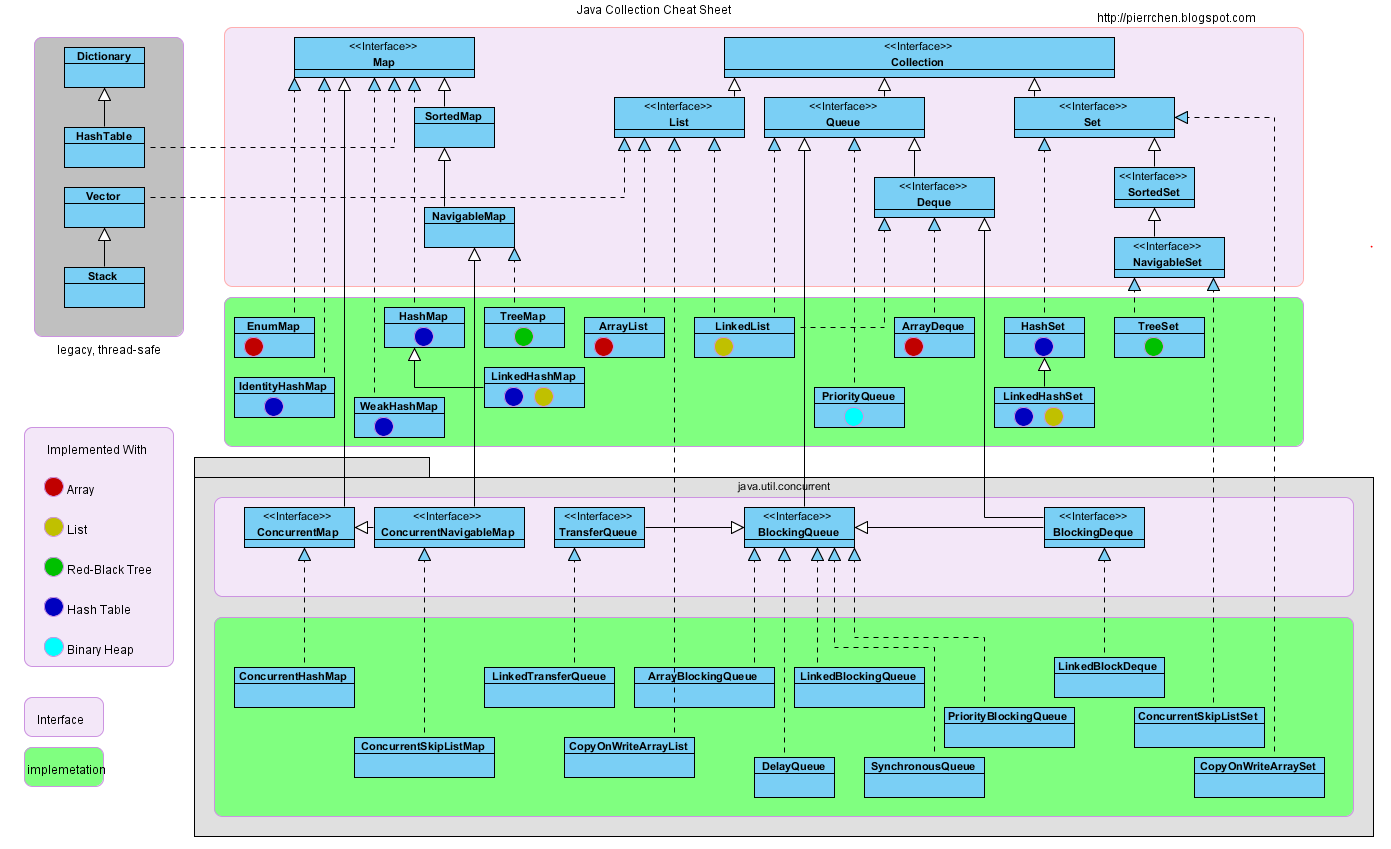
JCF 容器的数据结构和算法时间复杂度列表:

# Collection 三大集合类
Collection 是所有集合的基本接口,Collection 接口继承 Iterable 接口,定义了对集合的通用操作方法,如 add()、remove()、contains()、size()、iterator()等。iterator() 方法返回一个实现 Iterator 接口的对象,可以使用迭代器访问集合中的所有元素。
Java 的迭代器可以认为是位于两个元素之间,当调用 next 时,迭代器就越过下个元素,并返回刚刚越过的那个元素的引用。
对有实现 Iterable 接口的对象采用 foreach 语法糖,Java 编译器会将 foreach 语句转换为迭代器方式,如;
Collection<String> c = ...;
for (String element : c) {
// do something with element
}
// 编译器会将上面代码编译为迭代器
Iterator<String> ite = c.iterator();
while (ite.hasNext()) {
String element = ite.next();
// do something with element;
}
2
3
4
5
6
7
8
9
10
11
由 Collection 接口扩展出三大集合类:
- List:有序集合,提供方便的访问、插入、删除等操作
- Set:无序集合,不允许重复元素
- Queue / Deque:标准队列结构,除了集合的基本功能,还支持先进先出,后进先出等特性功能
每种集合的通用逻辑都被抽象到相应的抽象类中,如 AbstractList、AbstractSet、AbstractQueue。
Collections 工具类:提供了创建线程安全的集合静态方法,原理是在集合添加、删除、截取等修改操作前添加 synchronized 关键字。
# List
有序集合
Vector、ArrayList、LinkedList ,它们都实现了 Java 集合框架的 List 接口,都是有序集合。功能相似,都提供按照位置进行定位、添加或删除等操作,都提供迭代器遍历所有元素。区别如下:
- Vector:动态数组,线程安全(方法都是同步的 synchronized ),自动扩容,每次扩容1倍;内部元素以数组形式顺序存储(随机访问效率高
item.get(n)),插入或删除效率低 - ArrayList:动态数组,非线程安全,自动扩容,每次扩容50%,性能比 Vector 好;内部元素以数组形式顺序存储(随机访问效率高
item.get(n)),插入或删除效率低 - LinkedList:双向链表,非线程安全,无需扩容;节点插入或删除效率高,随机访问效率低;
Vector 和 ArrayList 的缺陷:
Vector 与 ArrayList 内部元素以数组形式顺序存储,适合随机访问的场合(索引序列,随机访问效率高);指定位置插入或删除效率很低(除在尾部插入或删除),因需要前移或后移指定位置开始的所有元素。
# 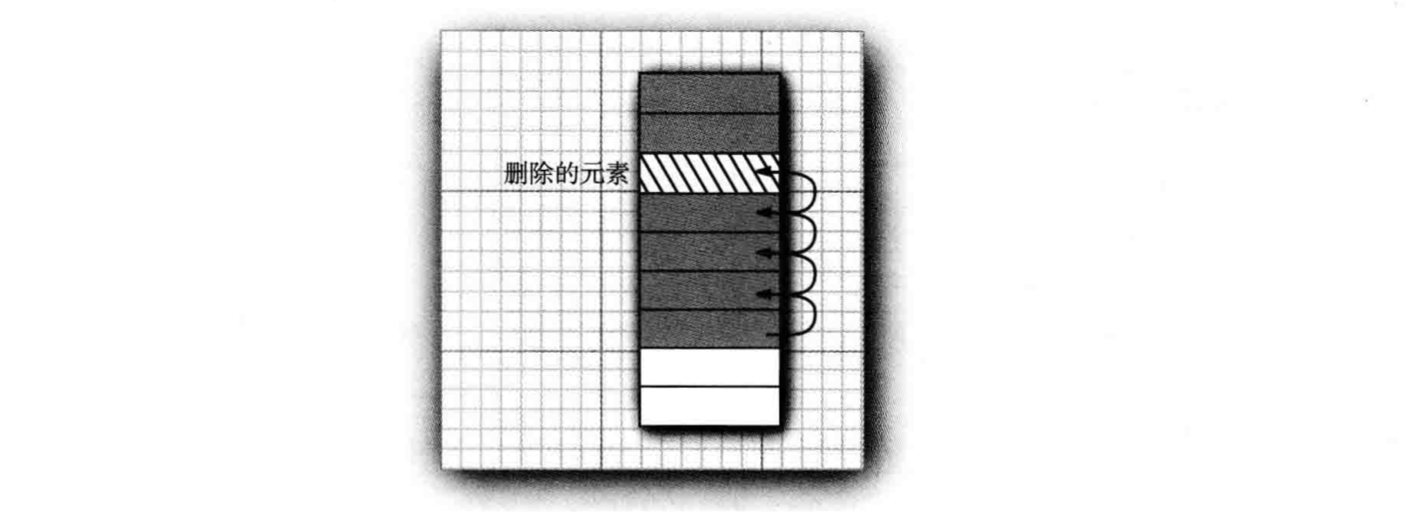
LinkedList 解决了这个问题
链表结构解决了数组结构删除和插入元素效率低的问题。链表(Java中链表都是双向链表)的每个节点存放对象数据、下一个节点的引用和上一个节点的引用。要想删除元素只需修改被删除元素附近的链接即可。unlink(Node<E> x)
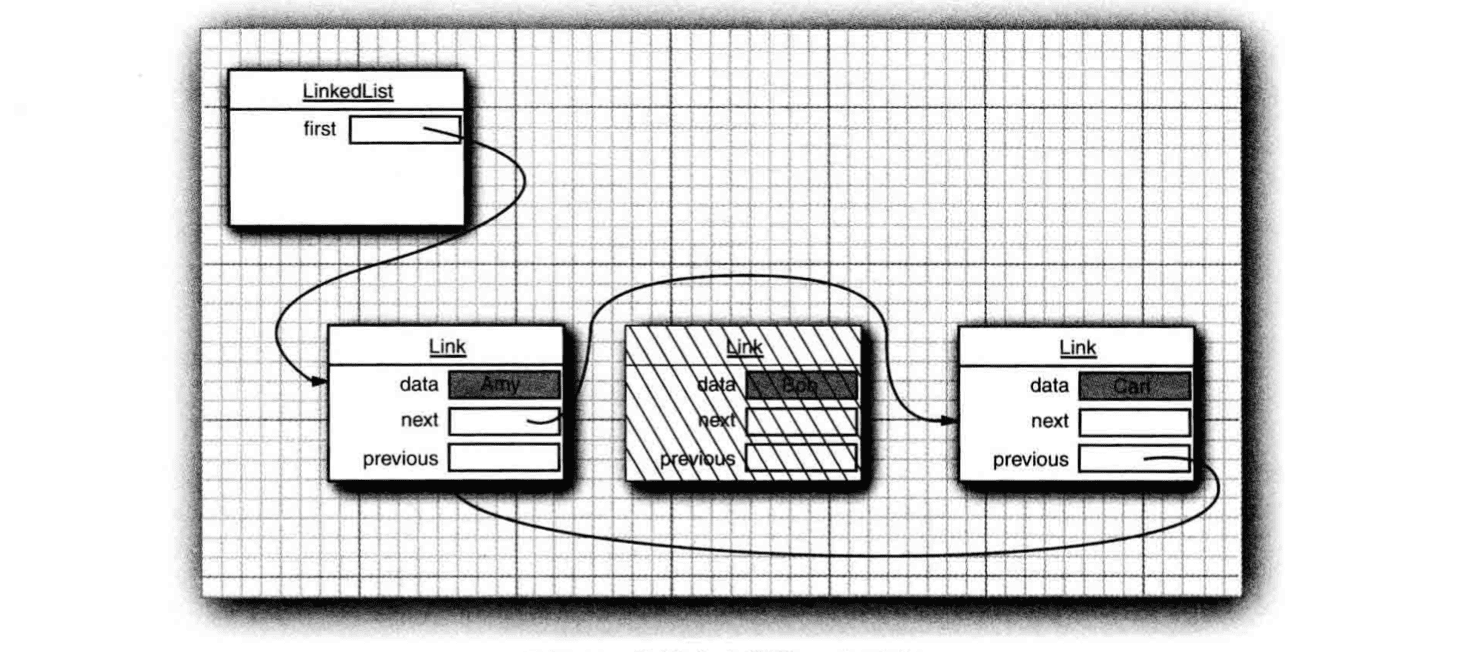
但 LinkedList 的缺点也很明细,在要访问第 n 个元素时,必须从头开始,越过 n-1 个元素才能得到。所以当程序需要采用整数索引访问元素时,通常不选用链表。
小结:
- 需要采用整数索引访问列表元素时,使用 ArrayList 或 Vector(线程安全);
- 列表只有少量元素,插入和删除操作代价不高,可以使用 ArrayList 或 Vector(线程安全)
- 列表元素比较多,且需要插入和删除操作,使用 LinkedList。
# Set
不允许存在重复元素,快速查找指定元素
场景:查看某个指定元素,但不知其位置,则需要遍历整个集合直到找到为止。如果集合的元素很多,将消耗很多时间
**解决方式:**有几种快速查找元素的数据结构,如下:
- 散列表(hash table):无序
- 红黑树:有序
散列表:一种可以快速查找所需对象的数据结构。散列表为每一个对象计算一个整数,称为散列码(hash code)。具有不同数据域的对象将产生不同的散列码。
Java 中散列表使用链表数组实现。每个列表称为桶(bucket),要想查找表中的对象位置,要先计算出对象的散列码,然后与桶的总数相除取余,所得到的结果就是保存这个桶的索引。
例如:某个对象的散列码是 76268,并且有 128 个桶,对象应该保存在第 108 号桶中(76268 / 128 余 108)。如果桶中没有其他元素则直接插入到桶中即可。
若知道会有多少个元素要插入散列表中,可以设置初始桶数为元素总数的 75% - 150%;标准类库默认的桶数为16;
如果散列表太满,就需要再散列。装填因子的值决定什么时候对散列表进行再散列,其值默认为 0.75。即表在超过 75% 的位置已经填入元素,这个表就用双倍桶数自动进行再散列。
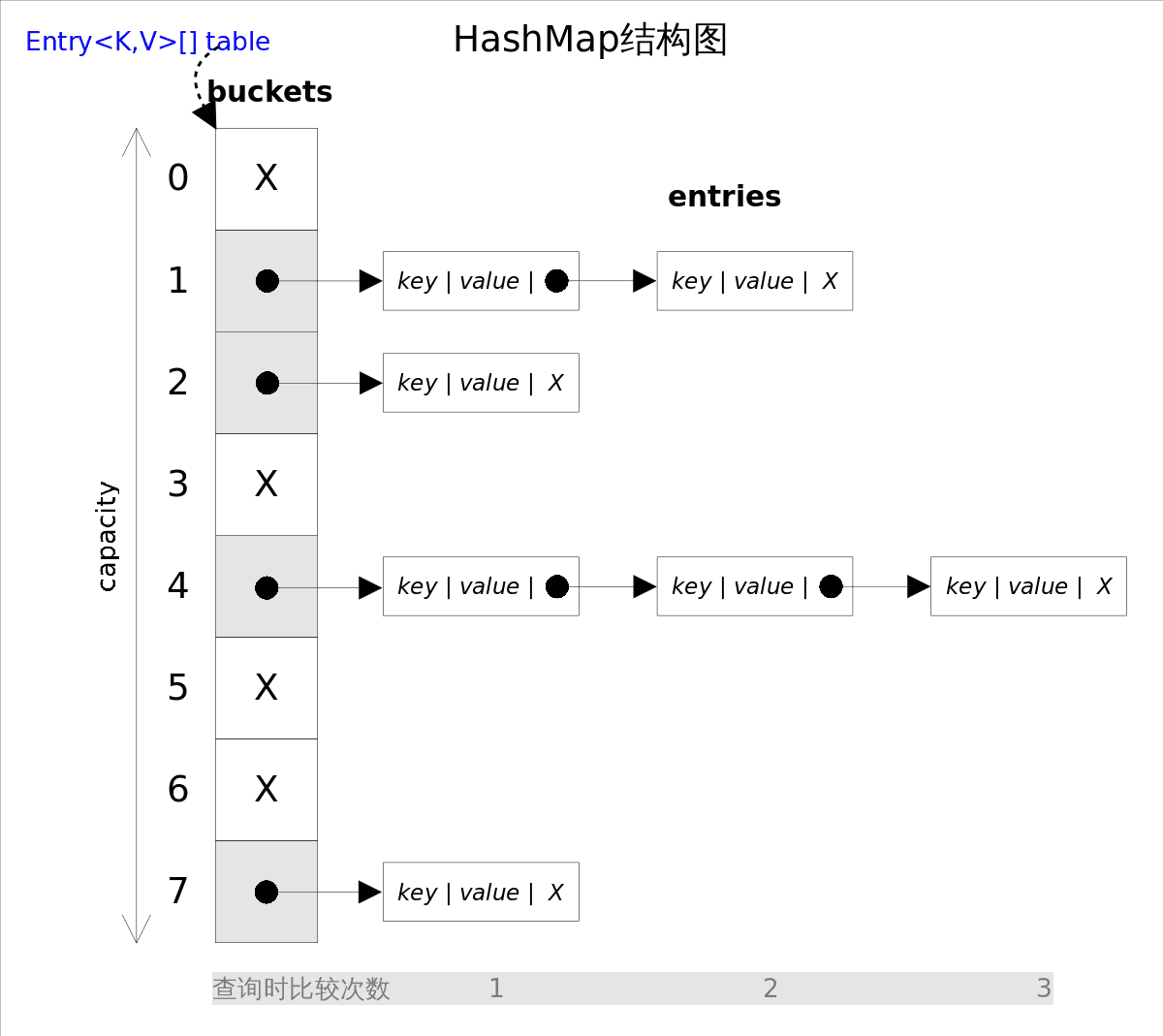
TreeSet、HashSet、LinkedHashSet ,它们都实现了 Java 集合框架的 Set 接口。区别如下:
- TreeSet:树集,红黑树数据结构,支持自然顺序访问,但添加、删除、包含等操作相对低效 O(logN) 时间,有序集合
- HashSet:散列集,散列表数据结构,理想情况下,如果哈希散列正常,可以提供常数时间 O(1) 的添加、删除、包含等操作。无序集合。
- LinkedHashSet:散列表数据结构,内部构建了一个记录插入顺序的双向链表,因此提供了按照插入顺序遍历的能力,与此同时,也保证了常数时间的添加、删除、包含等操作,这些操作性能略低于 HashSet,因为需要维护链表的开销
- 在遍历元素时,HashSet 性能受自身容量影响,所以初始化时,除非有必要,不然不要将其背后的 HashMap 容量设置过大。而对于 LinkedHashSet,由于其内部链表提供的方便,遍历性能只和元素多少有关系
# Queue/Deque
标准队列结构
Queue 队列:可以在尾部添加一个元素,在头部删除一个元素。
Deque 双端队列:可以在尾部和头部同时添加和删除元素
PriorityQueue、ArrayQueue 区别:
- PriorityQueue:优先级队列,一种高效删除最小元素的集合,使用堆数据结构,按任意顺序插入,但删除时是最小元素。适用于任务调度。当调用
peek()或者poll()方法获取队列元素时,获取的是队列最小元素,而不是先入队列的元素。有点反先入先出规则。 - ArrayQueue:底层实现类似于 ArrayList,都是通过动态、可分配的 Object[] 数组来实现元素存储,当集合元素超过数组容量,会重新分配一个新的数组来存储集合元素。
# Map
# TreeMap
基于红黑树实现。树映射,用键的整体顺序进行排序,并将其组织成搜索树。速度慢
# HashMap
基于哈希表实现。散列映射,对键进行散列。速度快,无需按照排列顺序访问键,最好选择散列映射
# HashTable
和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程可以同时写入 HashTable 并且不会导致数据不一致。它是遗留类,不应该去使用它。现在可以使用 ConcurrentHashMap 来支持线程安全,并且 ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
# LinkedHashMap
使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
# 考察点
Java 集合框架考察点 ,有很多方面需要掌握:
- Java 集合框架的设计结构,至少要有一个整体印象。
- Java 提供的主要容器(集合和 Map)类型,了解或掌握对应的数据结构、算法,思考具体技术选择。
- 将问题扩展到性能、并发等领域。
- 集合框架的演进与发展。
# 数据结构
数组、双向链表、队列、散列表、二叉树、红黑树、堆等等
# 算法
典型排序算法为例,至少需要熟知:
- 内部排序,至少掌握基础算法如归并排序、交换排序(冒泡、快排)、选择排序、插入排序等。
- 外部排序,掌握利用内存和外部存储处理超大数据集,至少要理解过程和思路。
考察算法不仅仅是如何简单实现,面试官往往会刨根问底,比如哪些是排序是不稳定的呢(快排、堆排),或者思考稳定意味着什么;对不同数据集,各种排序的最好或最差情况;从某个角度如何进一步优化(比如空间占用,假设业务场景需要最小辅助空间,这个角度堆排序就比归并优异)等
# 参考
https://github.com/CarpenterLee/JCFInternals