开始
开始
# 开始
课程源码:https://github.com/xuwenhao/geektime-ai-course
# 获取 openAI secret key
# 开发环境搭建
使用 docker 按照 jupyter labs
docker pull jupyter/base-notebook
docker run -p 8888:8888 --name jupyter -v /Users/jason/jupyter:/home/jovyan/work -d jupyter/base-notebook
-- 查看日志,获取带有 token 的访问链接
docker logs jupyter
2
3
4
5
6
在 jupyter notebook 中安装 openAI
!pip install openai
设置 openAI api key 环境变量
%env OPENAI_API_KEY=在这里写你获取到的ApiKey
体验测试 openAI 接口
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ['OPENAI_API_KEY'],
)
COMPLETION_MODEL = "text-davinci-003"
prompt = """
Consideration proudct : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具
1. Compose human readale product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
def get_response(prompt):
completions = client.completions.create (
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.0,
)
message = completions.choices[0].text
return message
print(get_response(prompt))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
运行结果:
NotFoundError: Error code: 404 - {'error': {'message': 'The model `text-davinci-003` has been deprecated, learn more here: https://platform.openai.com/docs/deprecations', 'type': 'invalid_request_error', 'param': None, 'code': 'model_not_found'}}
报错原因是 text-davinci-003 模型不推荐使用,查看文档后使用 gpt-3.5-turbo-instruct 模型代替,重新运行上面代码。
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ['OPENAI_API_KEY'],
)
COMPLETION_MODEL = "gpt-3.5-turbo-instruct"
prompt = """
Consideration proudct : 工厂现货PVC充气青蛙夜市地摊热卖充气玩具发光蛙儿童水上玩具
1. Compose human readale product title used on Amazon in english within 20 words.
2. Write 5 selling points for the products in Amazon.
3. Evaluate a price range for this product in U.S.
Output the result in json format with three properties called title, selling_points and price_range
"""
def get_response(prompt):
completions = client.completions.create (
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.0,
)
message = completions.choices[0].text
return message
print(get_response(prompt))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
运行结果:
RateLimitError: Error code: 429 - {'error': {'message': 'You exceeded your current quota, please check your plan and billing details. For more information on this error, read the docs: https://platform.openai.com/docs/guides/error-codes/api-errors.', 'type': 'insufficient_quota', 'param': None, 'code': 'insufficient_quota'}}
报错原因是 openAI 接口没有免费配额了,需要绑定信用卡付费(且不支持中国地区)。
TODO 付费问题待解决、或者使用其他平台
正确的返回结果:
{
"title": "Glow-in-the-Dark Inflatable PVC Frog Night Market Hot Selling Water Toy for Kids",
"selling_points": [
"Made of durable PVC material",
"Glow-in-the-dark design for night play",
"Inflatable design for easy storage and transport",
"Perfect for water play and outdoor activities",
"Great gift for kids"
],
"price_range": "$10 - $20"
}
2
3
4
5
6
7
8
9
10
11
这个商品名称不是构造的,而是直接找了 1688 里一个真实存在的商品。

这段代码里面,我们调用了 OpenAI 的 Completion 接口,然后向它提了一个需求,也就是为一个在 1688 上找到的中文商品名称做三件事情。
- 为这个商品写一个适合在亚马逊上使用的英文标题。
- 给这个商品写 5 个卖点。
- 估计一下,这个商品在美国卖多少钱比较合适。
同时,我们告诉 OpenAI,我们希望返回的结果是 JSON 格式的,并且上面的三个事情用 title、selling_points 和 price_range 三个字段返回。
神奇的是,OpenAI 真的理解了我们的需求,返回了一个符合我们要求的 JSON 字符串给我们。在这个过程中,它完成了好几件不同的事情。
第一个是翻译,我们给的商品名称是中文的,返回的内容是英文的。
第二个是理解你的语义去生成文本,我们这里希望它写一个在亚马逊电商平台上适合人读的标题,所以在返回的英文结果里面,AI 没有保留原文里有的“工厂现货”的含义,因为那个明显不适合在亚马逊这样的平台上作为标题。下面 5 条描述也没有包含“工厂现货”这样的信息。而且,其中的第三条卖点 “Inflatable design for easy storage and transport”,也就是作为一个充气的产品易于存放和运输,这一点其实是从“充气”这个信息 AI 推理出来的,原来的中文标题里并没有这样的信息。
第三个是利用 AI 自己有的知识给商品定价,这里它为这个商品定的价格是在 10~20 美元之间。而我用 “Glow-in-the-Dark frog” 在亚马逊里搜索,搜索结果的第一行里,就有一个 16 美元发光的青蛙。
最后是根据我们的要求把我们想要的结果,通过一个 JSON 结构化地返回给我们。而且,尽管我们没有提出要求,但是 AI 还是很贴心地把 5 个卖点放在了一个数组里,方便你后续只选取其中的几个来用。返回的结果是 JSON,这样方便了我们进一步利用返回结果。比如,我们就可以把这个结果解析之后存储到数据库里,然后展现给商品运营人员。
好了,如果看到这个结果你有些激动的话,请你先平复一下,我们马上来看一个新例子。
prompt = """
Man Utd must win trophies, says Ten Hag ahead of League Cup final
请将上面这句话的人名提取出来,并用json的方式展示出来
"""
print(get_response(prompt))
2
3
4
5
6
7
输出结果:
{
"names": ["Ten Hag"]
}
2
3
我们给了它一个英文的体育新闻的标题,然后让 AI 把其中的人名提取出来。可以看到,返回的结果也准确地把新闻里面唯一出现的人名——曼联队的主教练滕哈格的名字提取了出来。
和之前的例子不同,这个例子里,我们希望 AI 处理的内容是英文,给出的指令则是中文。不过 AI 都处理得很好,而且我们的输入完全是自然的中英文混合在一起,并没有使用特定的标识符或者分隔符。
我们这里的两个例子,其实对应着很多不同的问题,其中就包括机器翻译、文本生成、知识推理、命名实体识别等等。在传统的机器学习领域,对于其中任何一个问题,都可能需要一个独立的机器学习模型。就算把这些模型都免费提供给你,把这些独立的机器学习模型组合到一起实现上面的效果,还需要海量的工程研发工作。没有一个数十人的团队,工作量根本看不到头。
然而,OpenAI 通过一个包含 1750 亿参数的大语言模型,就能理解自然的语言输入,直接完成各种不同的问题。而这个让人惊艳的表现,也是让很多人惊呼“通用人工智能(AGI)要来了”的原因。
# 情感分析
大型语言模型的接口其实非常简单。像 OpenAI 就只提供了 Complete 和 Embedding 两个接口,其中,Complete 可以让模型根据你的输入进行自动续写,Embedding 可以将你输入的文本转化成向量。
不过到这里,你的疑问可能就来了。不是说现在的大语言模型很厉害吗?传统的自然语言处理问题都可以通过大模型解决。可是用这么简单的两个 API,能够完成原来需要通过各种 NLP 技术解决的问题吗?比如情感分析、文本分类、文章聚类、摘要撰写、搜索,这一系列问题怎么通过这两个接口解决呢?
别急,在接下来的几讲里,我会告诉你,怎么利用大语言模型提供的这两个简单的 API 来解决传统的自然语言处理问题。这一讲我们就先从一个最常见的自然语言处理问题——“情感分析”开始,来看看我们怎么把大语言模型用起来。
# 传统的二分类方法:朴素贝叶斯与逻辑回归
“情感分析”问题,是指我们根据一段文字,去判断它的态度是正面的还是负面的。在传统的互联网产品里,经常会被用来分析用户对产品、服务的评价。比如大众点评里面,你对餐馆的评论,在京东买个东西,你对商品的评论,都会被平台拿去分析,给商家或者餐馆的评分做参考。也有些品牌,会专门抓取社交网络里用户对自己产品的评价,来进行情感分析,判断消费者对自己的产品评价是正面还是负面的,并且会根据这些评价来改进自己的产品。
对于“情感分析”类型的问题,传统的解决方案就是把它当成是一个分类问题,也就是先拿一部分评论数据,人工标注一下这些评论是正面还是负面的。如果有个用户说“这家餐馆真好吃”,那么就标注成“正面情感”。如果有个用户说“这个手机质量不好”,那么就把对应的评论标注成负面的。
我们把标注好的数据,喂给一个机器学习模型,训练出一组参数。然后把剩下的没有人工标注过的数据也拿给训练好的模型计算一下。模型就会给你一个分数或者概率,告诉你这一段评论的感情是正面的,还是负面的。
可以用来做情感分析的模型有很多,这些算法背后都是基于某一个数学模型。比如,很多教科书里,就会教你用朴素贝叶斯算法来进行垃圾邮件分类。朴素贝叶斯的模型,就是简单地统计每个单词和好评差评之间的条件概率。一般来说,如果一个词语在差评里出现的概率比好评里高得多,那这个词语所在的评论,就更有可能是一个差评。
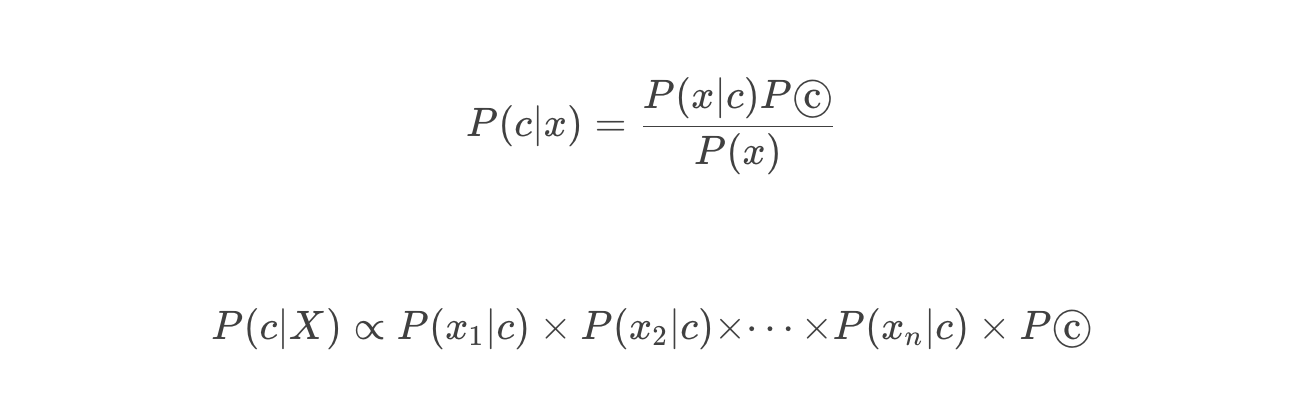
假设我们有一个训练集包含 4 封邮件,其中 2 封是垃圾邮件,2 封是非垃圾邮件。训练集里的邮件包含这些单词。
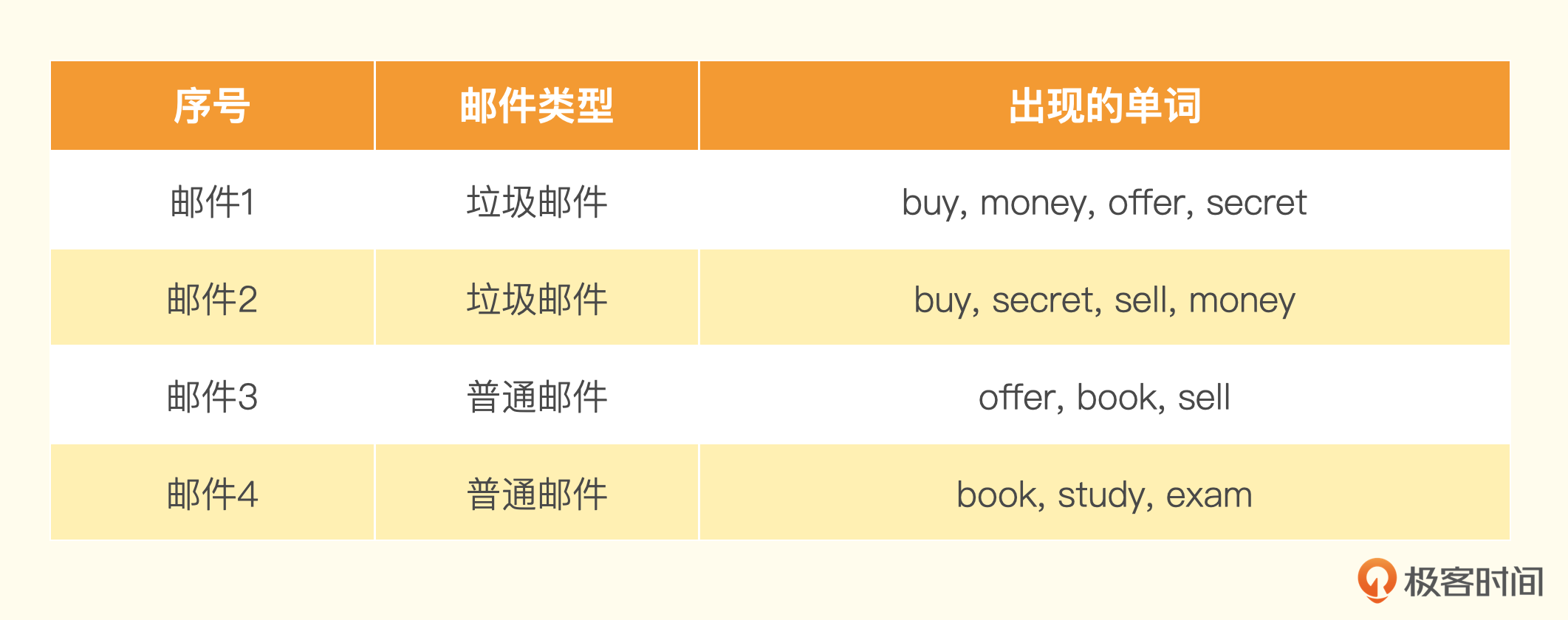
然后来了一封新邮件,里面的单词是:buy、money、sell。
通过这些单词出现的概率,我们很容易就可以预先算出这封邮件是垃圾邮件还是普通邮件。
- P(buy|垃圾)=2÷2=1
- P(money|垃圾)=2÷2=1
- P(sell|垃圾)=1÷2=0.5
- P(buy|普通)=0÷2=0
- P(money|普通)=0÷2=0
- P(sell|普通)=1div2=0.5
然后我们把这封邮件里所有词语的条件概率用全概率公式乘起来,就得到了这封邮件是垃圾邮件还有普通邮件的概率。
P(垃圾∣X)∝P(buy∣垃圾)×P(money∣垃圾)×P(sell∣垃圾)×P(垃圾)=1×1×0.5×0.5=0.25
P(普通∣X)∝P(buy∣普通)×P(money∣普通)×P(sell∣普通)×P(普通)=0×0×0.5×0.5=0
在这里,我们发现 P(垃圾∣X)>P(普通∣X),而且 P(普通∣X) 其实等于 0。那如果用朴素贝叶斯算法,我们就会认为这封邮件 100% 是垃圾邮件。如果你觉得自己数学不太好,这个例子没有看明白也没有关系,因为我们接下来的 AI 应用开发都不需要预先掌握这些数学知识,所以不要有心理负担。
类似的,像逻辑回归、随机森林等机器学习算法都可以拿来做分类。你在网上,特别是 Kaggle 这个机器学习比赛的网站里,可以搜索到很多其他人使用这些传统方法来设计情感分析的解决方案。这些方案都以 Jupyter Notebook 的形式出现,我在这里放个链接 (opens new window),你有兴趣的话也可以去研究一下。
# 传统方法的挑战:特征工程与模型调参
但这些传统的机器学习算法,想要取得好的效果,还是颇有门槛的。除了要知道有哪些算法可以用,还有两方面的工作非常依赖经验。
# 特征工程
第一个是特征工程。对于很多自然语言问题,如果我们只是拿一段话里面是否出现了特定的词语来计算概率,不一定是最合适的。比如“这家餐馆太糟糕了,一点都不好吃”和 “这家餐馆太好吃了,一点都不糟糕”这样两句话,从意思上是完全相反的。但是里面出现的词语其实是相同的。在传统的自然语言处理中,我们会通过一些特征工程的方法来解决这个问题。
比如,我们不只是采用单个词语出现的概率,还增加前后两个或者三个相连词语的组合,也就是通过所谓的 2-Gram(Bigram 双字节词组)和 3-Gram(Trigram 三字节词组)也来计算概率。在上面这个例子里,第一句差评,就会有“太”和“糟糕”组合在一起的“太糟糕”,以及“不”和“好吃”组合在一起的“不好吃”。而后面一句里就有“太好吃”和“不糟糕”两个组合。有了这样的 2-Gram 的组合,我们判断用户好评差评的判断能力就比光用单个词语是否出现要好多了。
这样的特征工程的方式有很多,比如去除停用词,也就是“的地得”这样的词语,去掉过于低频的词语,比如一些偶尔出现的专有名词。或者对于有些词语特征采用 TF-IDF(词频 - 逆文档频率)这样的统计特征,还有在英语里面对不同时态的单词统一换成现在时。
不同的特征工程方式,在不同的问题上效果不一样,比如我们做情感分析,可能就需要保留标点符号,因为像“!”这样的符号往往蕴含着强烈的情感特征。但是,这些种种细微的技巧,让我们在想要解决一个简单的情感分析问题时,也需要撰写大量文本处理的代码,还要了解针对当前特定场景的技巧,这非常依赖工程师的经验。
# 机器学习相关经验
第二个就是你需要有相对丰富的机器学习经验。除了通过特征工程设计更多的特征之外,我们还需要了解很多机器学习领域里常用的知识和技巧。比如,我们需要将数据集切分成训练(Training)、验证(Validation)、测试(Test)三组数据,然后通过 AUC 或者混淆矩阵(Confusion Matrix)来衡量效果。如果数据量不够多,为了训练效果的稳定性,可能需要采用 K-Fold 的方式来进行训练。
如果你没有接触过机器学习,看到这里,可能已经看懵了。没关系,上面的大部分知识你未来可能都不需要了解了,因为我们有了大语言模型,可以通过它提供的 Completion 和 Embedding 这两个 API,用不到 10 行代码就能完成情感分析,并且能获得非常好的效果。
# 大语言模型:20 行代码的情感分析解决方案
通过大语言模型来进行情感分析,最简单的方式就是利用它提供的 Embedding 这个 API。这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
我们需要提前计算“好评”和“差评”这两个字的 Embedding。而对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。那么,我们把这段文本的 Embedding 和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。
下面我们就用这个方法分析一下两条在京东上购买了 iPhone 用户的评论。

这个使用大模型的方法一共不到 40 行代码,我们看看它能否帮助我们快速对这两条评论进行情感分析。
from openai import OpenAI
import numpy as np
import os
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
EMBEDDING_MODEL = "text-embedding-ada-002"
def get_embedding(text, model=EMBEDDING_MODEL):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
def cosine_similarity(vector_a, vector_b):
dot_product = np.dot(vector_a, vector_b)
norm_a = np.linalg.norm(vector_a)
norm_b = np.linalg.norm(vector_b)
epsilon = 1e-10
cosine_similarity = dot_product / (norm_a * norm_b + epsilon)
return cosine_similarity
positive_review = get_embedding("好评")
negative_review = get_embedding("差评")
positive_example = get_embedding("买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质")
negative_example = get_embedding("随意降价,不予价保,服务态度差")
def get_score(sample_embedding):
return cosine_similarity(sample_embedding, positive_review) - cosine_similarity(sample_embedding, negative_review)
positive_score = get_score(positive_example)
negative_score = get_score(negative_example)
print("好评例子的评分 : %f" % (positive_score))
print("差评例子的评分 : %f" % (negative_score))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
输出结果:
好评例子的评分 : 0.070963
差评例子的评分 : -0.081472
2
正如我们所料,京东上的好评通过 Embedding 相似度计算得到的分数是大于 0 的,京东上面的差评,这个分数是小于 0 的。
这样的方法,是不是特别简单?我们再拿刚才的例子试一下,看看这个方法是不是对所有词语都管用,只是出现的位置不同但含义截然相反的评论,能得到什么样的结果。
good_restraurant = get_embedding("这家餐馆太好吃了,一点都不糟糕")
bad_restraurant = get_embedding("这家餐馆太糟糕了,一点都不好吃")
good_score = get_score(good_restraurant)
bad_score = get_score(bad_restraurant)
print("好评餐馆的评分 : %f" % (good_score))
print("差评餐馆的评分 : %f" % (bad_score))
2
3
4
5
6
7
输出结果:
好评餐馆的评分 : 0.062719
差评餐馆的评分 : -0.074591
2
可以看到,虽然两句话分别是“太好吃”“不糟糕”和“太糟糕”“不好吃”,其实词语都一样,但是大语言模型一样能够帮助我们判断出来他们的含义是不同的,一个更接近好评,一个更接近差评。
更大的数据集上的真实案例
在这里,我们只举了几个例子,看起来效果还不错。这会不会只是我们运气好呢?我们再来拿一个真实的数据集验证一下,利用这种方法进行情感分析的准确率能够到多少。
下面这段代码,是来自 OpenAI Cookbook 里面的一个例子。它是用同样的方法,来判断亚马逊提供的用户对一些食物的评价,这个评价数据里面,不只有用户给出的评论内容,还有用户给这些食物打了几颗星。这些几颗星的信息,正好可以拿来验证我们这个方法有多准。对于用户打出 1~2 星的,我们认为是差评,对于 4~5 星的,我们认为是好评。
我们可以通过 Pandas,将这个 CSV 数据读取到内存里面。为了避免重新调用 OpenAI 的 API 浪费钱,这个数据集里,已经将获取到的 Embedding 信息保存下来了,不需要再重新计算。
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(eval).apply(np.array)
# convert 5-star rating to binary sentiment
df = df[df.Score != 3]
df["sentiment"] = df.Score.replace({1: "negative", 2: "negative", 4: "positive", 5: "positive"})
2
3
4
5
6
7
8
9
10
11
12
13
每一条评论都用我们上面的方法,和一个预先设定好的好评和差评的文本去做对比,然后看它离哪个近一些。这里的好评和差评,我们写得稍微长了一点,分别是 “An Amazon review with a negative sentiment.” 和 “An Amazon review with a positive sentiment.”。
在计算完结果之后,我们利用 Scikit-learn 这个机器学习的库,将我们的预测值和实际用户打出的星数做个对比,然后输出对比结果。需要的代码,也就不到 20 行。
from sklearn.metrics import PrecisionRecallDisplay
def evaluate_embeddings_approach(
labels = ['negative', 'positive'],
model = EMBEDDING_MODEL,
):
label_embeddings = [get_embedding(label, engine=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
probas = df["embedding"].apply(lambda x: label_score(x, label_embeddings))
preds = probas.apply(lambda x: 'positive' if x>0 else 'negative')
report = classification_report(df.sentiment, preds)
print(report)
display = PrecisionRecallDisplay.from_predictions(df.sentiment, probas, pos_label='positive')
_ = display.ax_.set_title("2-class Precision-Recall curve")
evaluate_embeddings_approach(labels=['An Amazon review with a negative sentiment.', 'An Amazon review with a positive sentiment.'])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
输出结果:
precision recall f1-score support
negative 0.98 0.73 0.84 136
positive 0.96 1.00 0.98 789
accuracy 0.96 925
macro avg 0.97 0.86 0.91 925
weighted avg 0.96 0.96 0.96 925
2
3
4
5
6

在结果里面可以看到,我们这个简单方法判定的好评差评的精度,也就是 precision 在 negative 和 positive 里,分别是 0.98 和 0.96,也就是在 95% 以上。
而召回率,也就是图里的 recall,在差评里稍微欠缺一点,只有 73%,这说明还是有不少差评被误判为了好评。不过在好评里,召回率则是 100%,也就是 100% 的好评都被模型找到了。这样综合考虑下来的整体准确率,高达 96%。而要达到这么好的效果,我们不需要进行任何机器学习训练,只需要几行代码调用一下大模型的接口,计算一下几个向量的相似度就好了。
# AI 客服和聊天机器人
我们来看看 Open AI 提供的 Completion 这个 API 接口。相信已经有不少人试过和 ChatGPT 聊天了,也有过非常惊艳的体验,特别是让 ChatGPT 帮我们写各种材料。那么,我们不妨也从这样一个需求开始吧。
这一讲里,我们没有选用目前常用的 gpt-3.5-turbo 或者 gpt-4 相关的模型,而是使用了 text-davinci-003 这个不是为了对话使用的模型。之所以这么做,是为了让你理解,其实基于大语言模型的聊天机器人,并没有什么秘密,也不过是通过简单的提示词进行“文本补全”的方式实现的。
# AI 客服
在这一波 AIGC 浪潮之前,我也做过一个智能客服的产品。我发现智能客服的回答,往往是套用固定的模版。这个的缺点,就是每次的回答都一模一样。当然,我们可以设计多个模版轮换着表达相同的意思,但是最多也就是三四个模版,整体的体验还是相当呆板。
不过,有了 GPT 这样的生成式的语言模型,我们就可以让 AI 自动根据我们的需求去写文案了。只要把我们的需求提给 Open AI 提供的 Completion 接口,它就会自动为我们写出这样一段文字。
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ.get("OPENAI_API_KEY"))
COMPLETION_MODEL = "text-davinci-003"
prompt = '请你用朋友的语气回复给到客户,并称他为“亲”,他的订单已经发货在路上了,预计在3天之内会送达,订单号2021AEDG,我们很抱歉因为天气的原因物流时间比原来长,感谢他选购我们的商品。'
def get_response(prompt, temperature = 1.0, stop=None):
completions = client.completions.create (
model=COMPLETION_MODEL,
prompt=prompt,
max_tokens=1024,
n=1,
stop=stop,
temperature=temperature,
)
message = completions.choices[0].text
return message
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
print(get_response(prompt))
亲,您的订单已经顺利发货啦!订单号是 2021AEDG,预计在 3 天之内会寄到您指定的地址。不好意思,给您带来了不便,原计划到货时间受天气原因影响而有所延迟。期待您收到衣服后给我们反馈意见哦!谢谢你选购我们的商品!
print(get_response(prompt))
亲,您的订单 2021AEDG 刚刚已经发出,预计 3 天之内就会送达您的手中。抱歉由于天气的原因造成了物流延迟,但我们会尽快将订单发到您的手中。感谢您对我们的支持!
相同的提示语,连续调用两次之后,给到了含义相同、遣词造句不同的结果。
我在这里列出了一段非常简单的代码。代码里面,我们给 Open AI 提供的 Completion 接口发送了一段小小的提示语(Prompt)。这段提示语要求 AI 用亲切的语气,告诉客户他的订单虽然已经发货,但是因为天气原因延迟了。并且我们还加了一个小小的语言风格上的要求,我们希望 AI 用朋友的口吻向用户说话,并且称用户为“亲”。然后,我们尝试连续用完全相同的参数调用了两次 AI。
可以看到,AI 的确理解了我们的意思,满足了我们的要求,给出了一段正确合理的回复。其中有两点我觉得殊为不易。
- 他的确用“亲”来称呼了用户,并且用了一些语气词,显得比较亲切。
- 他正确地提取到了输入内容里的订单号,并且在回复内容里也把这个订单号返回给了用户。
而且,两次返回的文案内容意思是相同的,但是具体的遣词造句又有所不同。这样通过一句合理的提示语,我们就可以让自己的智能客服自己遣词造句,而不是只能套用一个固定的模版。
而每次回复的内容不一样,则归功于我们使用的一个参数 temperature。这个参数的输入范围是 0-2 之间的浮点数,代表输出结果的随机性或者说多样性。在这里,我们选择了 1.0,也就是还是让每次生成的内容都有些不一样。你也可以把这个参数设置为 0,这样,每次输出的结果的随机性就会比较小。
我将 temperature 设置为 0,你可以看到两句内容的遣词造句就基本一致了。
print(get_response(prompt, 0.0))
亲,您的订单 2021AEDG 已经发货,预计在 3 天之内会送达,由于天气原因,物流时间比原来长,我们深表歉意。感谢您选购我们的商品,祝您购物愉快!
print(get_response(prompt, 0.0))
亲,您的订单 2021AEDG 已经发货,预计在 3 天之内会送达。很抱歉因为天气的原因物流时间比原来长,感谢您选购我们的商品,祝您购物愉快!
这个参数该怎么设置,取决于实际使用的场景。如果对应的场景比较严肃,不希望出现差错,那么设得低一点比较合适,比如银行客服的场景。如果场景没那么严肃,有趣更加重要,比如讲笑话的机器人,那么就可以设置得高一些。
既然看了 temperature 参数,我们也就一并看一下 Completion 这个接口里面的其他参数吧。
第一个参数是 engine,也就是我们使用的是 Open AI 的哪一个引擎,这里我们使用的是 text-davinci-003,也就是现在可以使用到的最擅长根据你的指令输出内容的模型。当然,也是调用成本最高的模型。
第二个参数是 prompt,自然就是我们输入的提示语。接下来,我还会给你更多使用提示语解决不同需求的例子。
第三个参数是 max_tokens,也就是调用生成的内容允许的最大 token 数量。你可以简单地把 token 理解成一个单词。实际上,token 是分词之后的一个字符序列里的一个单元。有时候,一个单词会被分解成两个 token。比如,icecream 是一个单词,但是实际在大语言模型里,会被拆分成 ice 和 cream 两个 token。这样分解可以帮助模型更好地捕捉到单词的含义和语法结构。一般来说,750 个英语单词就需要 1000 个 token。我们这里用的 text-davinci-003 模型,允许最多有 4096 个 token。需要注意,这个数量既包括你输入的提示语,也包括 AI 产出的回答,两个加起来不能超过 4096 个 token。比如,你的输入有 1000 个 token,那么你这里设置的 max_tokens 就不能超过 3096。不然调用就会报错。
第四个参数 n,代表你希望 AI 给你生成几条内容供你选择。在这样自动生成客服内容的场景里,我们当然设置成 1。但是如果在一些辅助写作的场景里,你可以设置成 3 或者更多,供用户在多个结果里面自己选择自己想要的。
print(get_response(prompt, 0.0, ","))
亲
Completion 这个接口当然还有其他参数,不过一时半会儿我们还用不着,后面实际用得上的时候我们再具体介绍。如果你现在就想知道,那么可以去查看一下官方文档 (opens new window)。如果你觉得英语不太好,可以试着用“请用中文解释一下这段话的意思”作为提示语,调用 Open AI 的模型来理解文档的含义。
# AI 聊天机器人
上面我们知道了怎么用一句提示语让 AI 完成一个任务,就是回答一个问题。不过,我们怎么能让 AI 和人“聊起来”呢?特别是怎么完成多轮对话,让 GPT 能够记住上下文。比如,当用户问我们,“iPhone14 拍照好不好”,我们回答说“很好”。然后又问“它的价格是多少的时候”,我们需要理解,用户这里问的“它”就是指上面的 iPhone。
对于聊天机器人来说,只理解当前用户的句子是不够的,能够理解整个上下文是必不可少的。而 GPT 的模型,要完成支持多轮的问答也并不复杂。我们只需要在提示语里增加一些小小的工作就好了。
想要实现问答,我们只需要在提示语里,在问题之前加上 “Q :” 表示这是一个问题,然后另起一行,加上 “A :” 表示我想要一个回答,那么 Completion 的接口就会回答你在 “Q : ” 里面跟的问题。比如下面,我们问 AI “鱼香肉丝怎么做”。它就一步一步地列出了制作步骤。
question = """
Q : 鱼香肉丝怎么做?
A :
"""
print(get_response(question))
2
3
4
5
- 准备好食材:500 克猪里脊肉,2 个青椒,2 个红椒,1 个洋葱,2 勺蒜蓉,3 勺白糖,适量料酒,半勺盐,2 勺生抽,2 勺酱油,2 勺醋,少许花椒粉,半勺老抽,适量水淀粉。
- 将猪里脊肉洗净,沥干水分,放入料酒、盐,抓捏抓匀,腌制 20 分钟。
- 将青红椒洗净,切成丝,洋葱洗净,切成葱花,蒜末拌入小苏打水中腌制。
- 将猪里脊肉切成丝,放入锅中,加入洋葱,炒制至断生,加入青红椒,炒匀,加入腌制好的蒜末,炒制至断生。
- 将白糖、生抽、酱油、醋、花椒粉、老抽、水淀粉倒入锅中,翻炒匀,用小火收汁,调味即可。
而要完成多轮对话其实也不麻烦,我们只要把之前对话的内容也都放到提示语里面,把整个上下文都提供给 AI。AI 就能够自动根据上下文,回答第二个问题。比如,你接着问“那蚝油牛肉呢?”。我们不要只是把这个问题传给 AI,而是把前面的对话也一并传给 AI,那么 AI 自然知道你问的“那蚝油牛肉呢?”是指怎么做,而不是去哪里买或者需要多少钱。
question = """
Q : 鱼香肉丝怎么做?
A :
1.准备好食材:500克猪里脊肉,2个青椒,2个红椒,1个洋葱,2勺蒜蓉,3勺白糖,适量料酒,半勺盐,2勺生抽,2勺酱油,2勺醋,少许花椒粉,半勺老抽,适量水淀粉。
2.将猪里脊肉洗净,沥干水分,放入料酒、盐,抓捏抓匀,腌制20分钟。
3.将青红椒洗净,切成丝,洋葱洗净,切成葱花,蒜末拌入小苏打水中腌制。
4.将猪里脊肉切成丝,放入锅中,加入洋葱,炒制至断生,加入青红椒,炒匀,加入腌制好的蒜末,炒制至断生。
5.将白糖、生抽、酱油、醋、花椒粉、老抽、水淀粉倒入锅中,翻炒匀,用小火收汁,调味即可。
Q : 那蚝油牛肉呢?
A :
"""
print(get_response(question))
2
3
4
5
6
7
8
9
10
11
12
13
- 准备好食材:500 克牛肉,2 茶匙葱姜蒜末,6 茶匙蚝油,4 茶匙米醋,3 茶匙白糖,3 茶匙酱油,1 茶匙料酒,半茶匙盐。
- 将牛肉洗净,放入清水中,加入料酒、盐,煮至牛肉熟透,捞出沥干水分,放入碗中。
- 在另一锅中,倒入蚝油,米醋,白糖,酱油翻炒均匀,加入葱姜蒜末,翻炒均匀。
- 将牛肉碗中放入蚝油汁中,炒匀,加入酱油,翻炒至汁呈红色,收汁成浓稠状即可。
我在下面贴了一段完整的 Python 代码叫做 food_chatbot,它会从命令行读入你的问题,然后给出回答。你可以继续提问,然后我们把整个对话过程都发送给 AI 来回答。你可以尝试着体验一下,AI 是不是能够理解整个对话过程的上下文。你想要退出的时候,就在需要提问的时候,输入 “bye” 就好了。
from openai import OpenAI
import os
client = OpenAI(api_key = os.environ["OPENAI_API_KEY"])
def ask_gpt3(prompt):
response = client.completions.create(
model="text-davinci-003",
prompt=prompt,
max_tokens=512,
n=1,
stop=None,
temperature=0.5,
)
message = response.choices[0].text.strip()
return message
print("你好,我是一个聊天机器人,请你提出你的问题吧?")
questions = []
answers = []
def generate_prompt(prompt, questions, answers):
num = len(answers)
for i in range(num):
prompt += "\n Q : " + questions[i]
prompt += "\n A : " + answers[i]
prompt += "\n Q : " + questions[num] + "\n A : "
return prompt
while True:
user_input = input("> ")
questions.append(user_input)
if user_input.lower() in ["bye", "goodbye", "exit"]:
print("Goodbye!")
break
prompt = generate_prompt("", questions, answers)
answer = ask_gpt3(prompt)
print(answer)
answers.append(answer)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 让 AI 帮我解决情感分析问题
可以看到,巧妙地利用提示语,我们就能够让 AI 完成多轮的问答。那你是不是想到了,我们能不能用同样的方式,来解决上一讲我们说到的情感分析问题呢?毕竟,很多人可能没有学习过任何机器学习知识,对于向量距离之类的概念也忘得差不多了。那么,我们能不能不用任何数学概念,完全用自然语言的提示语,让 AI 帮助我们判断一下用户评论的情感是正面还是负面的呢?
那我们不妨来试一下,告诉 AI 我们想要它帮助我们判断用户的评论情感上是正面的还是负面的,并且把上一讲两个 iPhone 评论的例子给它,告诉它什么是正面的,什么是负面的。然后,再给他一段新的评论,看看他是不是会回复正确的答案。
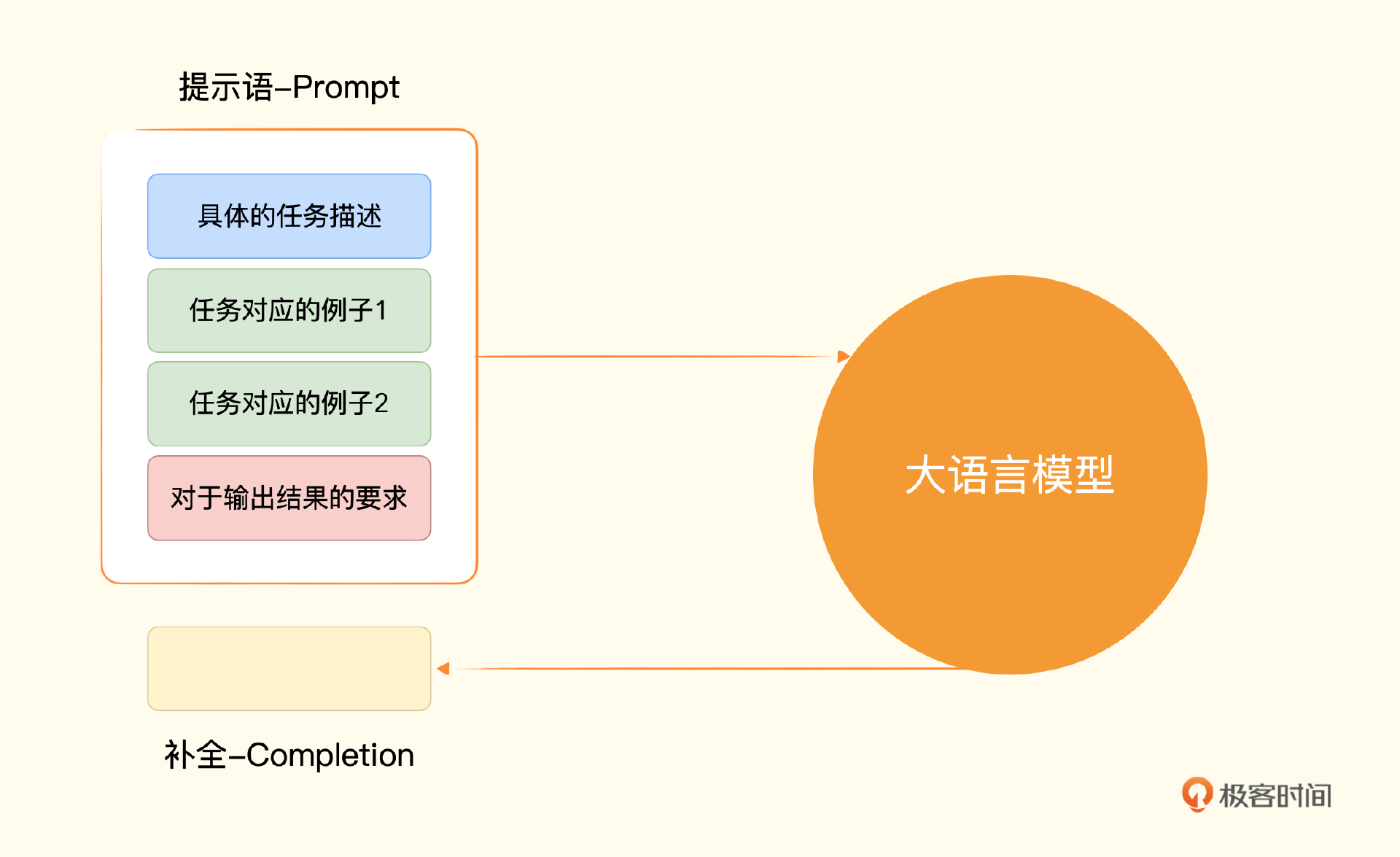
我把对应的代码放在了下面,我们仍然只是简单地调用 Completion 的 API 一次。只是需要再把提示语分成三个组成部分。
- 第一部分是我们给到 AI 的指令,也就是告诉它要去判断用户评论的情感。
- 第二部分是按照一个固定格式给它两个例子,一行以“评论:”开头,后面跟着具体的评论,另一行以“情感:”开头,后面跟着这个例子的情感。
- 第三部分是给出我们希望 AI 判定的评论,同样以“评论:”开头跟着我们想要它判定的评论,另一行也以“情感:”开头,不过后面没有内容,而是等着 AI 给出判定。
prompts = """判断一下用户的评论情感上是正面的还是负面的
评论:买的银色版真的很好看,一天就到了,晚上就开始拿起来完系统很丝滑流畅,做工扎实,手感细腻,很精致哦苹果一如既往的好品质
情感:正面
评论:随意降价,不予价保,服务态度差
情感:负面
"""
good_case = prompts + """
评论:外形外观:苹果审美一直很好,金色非常漂亮
拍照效果:14pro升级的4800万像素真的是没的说,太好了,
运行速度:苹果的反应速度好,用上三五年也不会卡顿的,之前的7P用到现在也不卡
其他特色:14pro的磨砂金真的太好看了,不太高调,也不至于没有特点,非常耐看,很好的
情感:
"""
print(get_response(good_case))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
正面
bad_case = prompts + """
评论:信号不好电池也不耐电不推荐购买
情感
"""
print(get_response(bad_case))
2
3
4
5
6
负面
我们重新从京东商城的 iPhone 评论区随机找两个和上次不太一样的好评和差评,可以看到,结果是准确的。这是不是很棒?我们不需要任何机器学习的相关知识,用几句话就能够轻松搞定情感分析问题。
 注:常见的大模型的上下文学习能力,通过几个例子,就能回答正确的结果。
注:常见的大模型的上下文学习能力,通过几个例子,就能回答正确的结果。
而上面这个“给一个任务描述、给少数几个例子、给需要解决的问题”这样三个步骤的组合,也是大语言模型里使用提示语的常见套路。一般我们称之为 Few-Shots Learning(少样本学习),也就是给一个或者少数几个例子,AI 就能够举一反三,回答我们的问题。
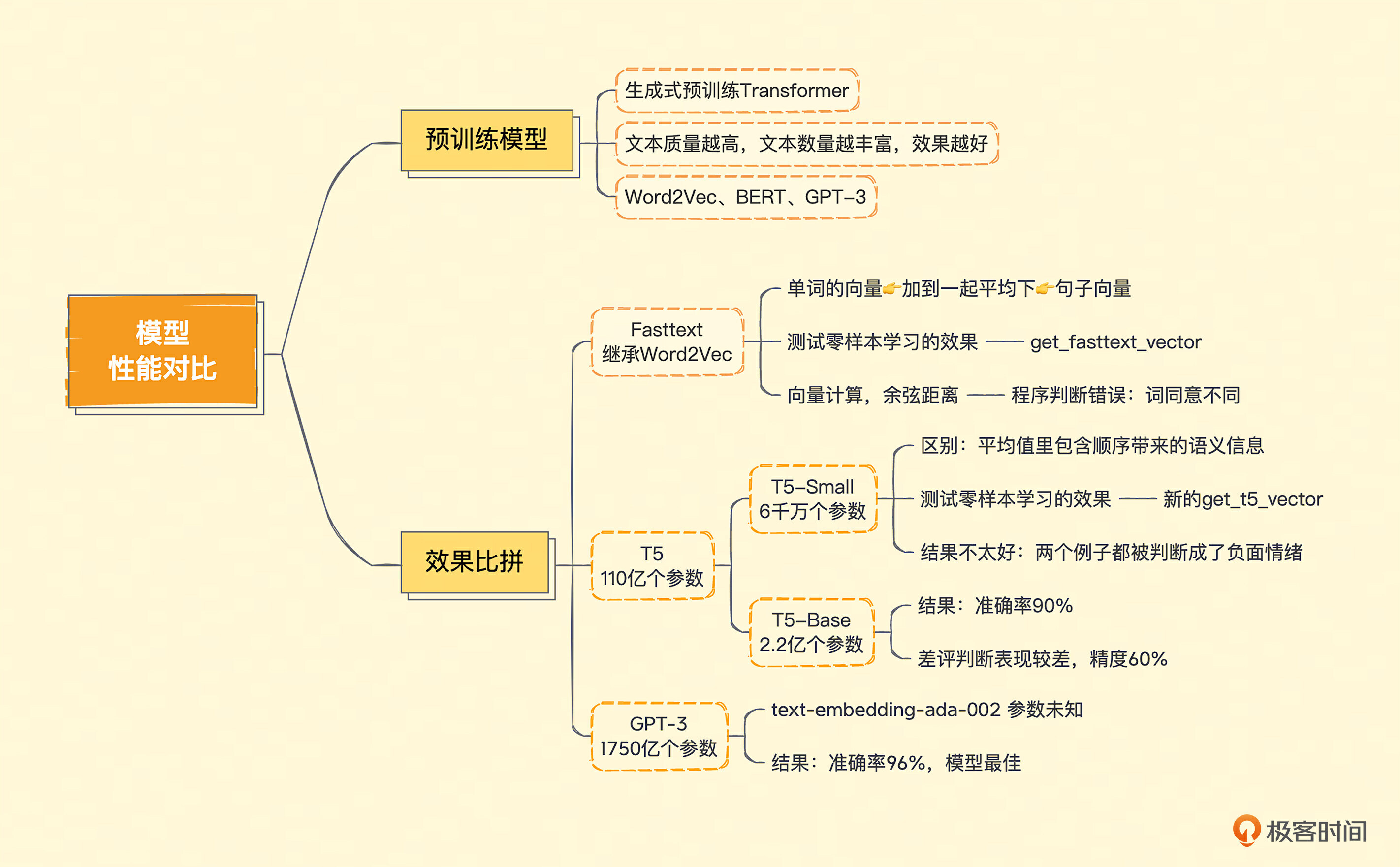
# 模型新能对比

# 什么是预训练模型?
给出一段文本,OpenAI 就能返回给你一个 Embedding 向量,这是因为它的背后是 GPT-3 这个超大规模的预训练模型(Pre-trained Model)。事实上,GPT 的英文全称翻译过来就是“生成式预训练 Transformer(Generative Pre-trained Transformer)”。
所谓预训练模型,就是虽然我们没有看过你想要解决的问题,比如这里我们在情感分析里看到的用户评论和评分。但是,我可以拿很多我能找到的文本,比如网页文章、维基百科里的文章,各种书籍的电子版等等,作为理解文本内容的一个学习资料。
我们不需要对这些数据进行人工标注,只根据这些文本前后的内容,来习得文本之间内在的关联。比如,网上的资料里,会有很多“小猫很可爱”、“小狗很可爱”这样的文本。小猫和小狗后面都会跟着“很可爱”,那么我们就会知道小猫和小狗应该是相似的词,都是宠物。同时,一般我们对于它们的情感也是正面的。这些隐含的内在信息,在我们做情感分析的时候,就带来了少量用户评论和评分数据里缺少的“常识”,这些“常识”也有助于我们更好地预测。
比如,文本里有“白日依山尽”,那么模型就知道后面应该跟“黄河入海流”。文本前面是“今天天气真”,后面跟着的大概率是“不错”,小概率是“糟糕”。这些文本关系,最后以一堆参数的形式体现出来。对于你输入的文本,它可以根据这些参数计算出一个向量,然后根据这个向量,来推算这个文本后面的内容。
可以这样来理解:用来训练的语料文本越丰富,模型中可以放的参数越多,那模型能够学到的关系也就越多。类似的情况在文本里出现得越多,那么将来模型猜得也就越准。
预训练模型在自然语言处理领域并不是 OpenAI 的专利。早在 2013 年,就有一篇叫做 Word2Vec 的经典论文谈到过。它能够通过预训练,根据同一个句子里一个单词前后出现的单词,来得到每个单词的向量。而在 2018 年,Google 关于 BERT 的论文发表之后,整个业界也都会使用 BERT 这样的预训练模型,把一段文本变成向量用来解决自己的自然语言处理任务。在 GPT-3 论文发表之前,大家普遍的结论是,BERT 作为预训练的模型效果也是优于 GPT 的。
# Fasttext T5 GPT-3 模型效果大比拼
第一个是来自 Facebook 的 Fasttext,它继承了 Word2Vec 的思路,能够把一个个单词表示成向量。第二个是来自 Google 的 T5,T5 的全称是 Text-to-Text Transfer Trasnformer,是适合做迁移学习的一个模型。所谓迁移学习,也就是它推理出来向量的结果,常常被拿来再进行机器学习,去解决其他自然语言处理问题。通常很多新发表的论文,会把 T5 作为预训练模型进行微调和训练,或者把它当作 Benchmark 来对比、评估。