 设计模式 - 行为型(上)
设计模式 - 行为型(上)
# 设计模式 - 行为型(上)
来源:极客时间《设计模式之美》 (opens new window)专栏
行为型设计模式主要解决的是“类或对象之间的交互”问题。
# 1. 观察者模式
# 1.1 观察者模式原理
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。定义:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)。在实际的项目开发中,这两种对象的称呼是比较灵活的,有各种不同的叫法,比如:Subject-Observer、Publisher-Subscriber、Producer-Consumer、EventEmitter-EventListener、Dispatcher-Listener。不管怎么称呼,只要应用场景符合刚刚给出的定义,都可以看作观察者模式。
观察者模式是一个比较抽象的模式,根据不同的应用场景和需求,有完全不同的实现方式。
public interface Subject {
void registerObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObservers(Message message);
}
public interface Observer {
void update(Message message);
}
public class ConcreteSubject implements Subject {
private List<Observer> observers = new ArrayList<Observer>();
@Override
public void registerObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
observers.remove(observer);
}
@Override
public void notifyObservers(Message message) {
for (Observer observer : observers) {
observer.update(message);
}
}
}
public class ConcreteObserverOne implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverOne is notified.");
}
}
public class ConcreteObserverTwo implements Observer {
@Override
public void update(Message message) {
//TODO: 获取消息通知,执行自己的逻辑...
System.out.println("ConcreteObserverTwo is notified.");
}
}
public class Demo {
public static void main(String[] args) {
ConcreteSubject subject = new ConcreteSubject();
subject.registerObserver(new ConcreteObserverOne());
subject.registerObserver(new ConcreteObserverTwo());
subject.notifyObservers(new Message());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
上面的代码算是观察者模式的“模板代码”,只能反映大体的设计思路。在真实的软件开发中,并不需要照搬上面的模板代码。观察者模式的实现方法各式各样,函数、类的命名等会根据业务场景的不同有很大的差别,比如 register 函数还可以叫作 attach,remove 函数还可以叫作 detach 等等。不过,万变不离其宗,设计思路都是差不多的。
假设在开发一个 P2P 投资理财系统,用户注册成功之后,会给用户发放投资体验金。代码大致如下:
public class UserController {
private UserService userService; // 依赖注入
private PromotionService promotionService; // 依赖注入
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
promotionService.issueNewUserExperienceCash(userId);
return userId;
}
}
2
3
4
5
6
7
8
9
10
11
12
虽然注册接口做了两件事情,注册和发放体验金,违反单一职责原则,但是,如果没有扩展和修改的需求,现在的代码实现是可以接受的。如果非得用观察者模式,就需要引入更多的类和更加复杂的代码结构,反倒是一种过度设计。
相反,如果需求频繁变动,比如,用户注册成功之后,不再发放体验金,而是改为发放优惠券,并且还要给用户发送一封“欢迎注册成功”的站内信。这种情况下就需要频繁地修改 register() 函数中的代码,违反开闭原则。而且,如果注册成功之后需要执行的后续操作越来越多,那 register() 函数的逻辑会变得越来越复杂,也就影响到代码的可读性和可维护性。
可以利用观察者模式,对上面的代码进行了重构:
public interface RegObserver {
void handleRegSuccess(long userId);
}
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
public void handleRegSuccess(long userId) {
promotionService.issueNewUserExperienceCash(userId);
}
}
public class RegNotificationObserver implements RegObserver {
private NotificationService notificationService;
@Override
public void handleRegSuccess(long userId) {
notificationService.sendInboxMessage(userId, "Welcome...");
}
}
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
// 一次性设置好,之后也不可能动态的修改
public void setRegObservers(List<RegObserver> observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
observer.handleRegSuccess(userId);
}
return userId;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
当需要添加新的观察者的时候,比如,用户注册成功之后,推送用户注册信息给大数据征信系统,基于观察者模式的代码实现,UserController 类的 register() 函数完全不需要修改,只需要再添加一个实现了 RegObserver 接口的类,并且通过 setRegObservers() 函数将它注册到 UserController 类中即可。
实际上,设计模式要干的事情就是解耦。创建型模式是将创建和使用代码解耦,结构型模式是将不同功能代码解耦,行为型模式是将不同的行为代码解耦,具体到观察者模式,它是将观察者和被观察者代码解耦。借助设计模式,利用更好的代码结构,将一大坨代码拆分成职责更单一的小类,让其满足开闭原则、高内聚松耦合等特性,以此来控制和应对代码的复杂性,提高代码的可扩展性。
# 1.2 观察者模式应用
观察者模式的应用场景非常广泛,小到代码层面的解耦,大到架构层面的系统解耦,再或者一些产品的设计思路,都有这种模式的影子,比如,邮件订阅、RSS Feeds,本质上都是观察者模式。不同的应用场景和需求下,这个模式也有截然不同的实现方式,有同步阻塞的实现方式,也有异步非阻塞的实现方式;有进程内的实现方式,也有跨进程的实现方式。
从上面例子来看,它是一种同步阻塞的实现方式。观察者和被观察者代码在同一个线程内执行,被观察者一直阻塞,直到所有的观察者代码都执行完成之后,才执行后续的代码。对照上面讲到的用户注册的例子,register() 函数依次调用执行每个观察者的 handleRegSuccess() 函数,等到都执行完成之后,才会返回结果给客户端。
如果注册接口是一个调用比较频繁的接口,对性能非常敏感,希望接口的响应时间尽可能短,那可以将同步阻塞的实现方式改为异步非阻塞的实现方式,以此来减少响应时间。具体来讲,当 userService.register() 函数执行完成之后,启动一个新的线程来执行观察者的 handleRegSuccess() 函数,这样 userController.register() 函数就不需要等到所有的 handleRegSuccess() 函数都执行完成之后才返回结果给客户端。
那如何实现一个异步非阻塞的观察者模式呢?简单一点的做法是,在每个 handleRegSuccess() 函数中,创建一个新的线程执行代码。不过还有更加优雅的实现方式,那就是基于 EventBus 来实现。它可以复用在任何需要异步非阻塞观察者模式的应用场景中。
刚刚的两个场景都是进程内的实现方式。如果用户注册成功之后,需要发送用户信息给大数据征信系统,而大数据征信系统是一个独立的系统,跟它之间的交互是跨不同进程的,那如何实现一个跨进程的观察者模式呢?如果大数据征信系统提供了发送用户注册信息的 RPC 接口,仍然可以沿用之前的实现思路,在 handleRegSuccess() 函数中调用 RPC 接口来发送数据。但是还有更加优雅、更加常用的一种实现方式,那就是基于消息队列(Message Queue)来实现。
当然,这种实现方式也有弊端,那就是需要引入一个新的系统(消息队列),增加了维护成本。不过,它的好处也非常明显。在原来的实现方式中,观察者需要注册到被观察者中,被观察者需要依次遍历观察者来发送消息。而基于消息队列的实现方式,被观察者和观察者解耦更加彻底,两部分的耦合更小。被观察者完全不感知观察者,同理,观察者也完全不感知被观察者。被观察者只管发送消息到消息队列,观察者只管从消息队列中读取消息来执行相应的逻辑。
# 1.3 实现一个异步非阻塞的 EvenBus 框架
观察者模式的同步阻塞是最经典的实现方式,主要是为了代码解耦;异步非阻塞除了能实现代码解耦之外,还能提高代码的执行效率;进程间的观察者模式解耦更加彻底,一般是基于消息队列来实现,用来实现不同进程间的被观察者和观察者之间的交互。
下面使用异步非阻塞的观察者模式,实现一个类似 Google Guava EventBus 的通用框架。
# 1.3.1 异步非阻塞观察者模式的简易实现
对于异步非阻塞观察者模式,如果只是实现一个简易版本,不考虑任何通用性、复用性,实际上是非常容易的。其中一种是:在每个 handleRegSuccess() 函数中创建一个新的线程执行代码逻辑;另一种是:在 UserController 的 register() 函数中使用线程池来执行每个观察者的 handleRegSuccess() 函数。代码如下:
// 第一种实现方式,其他类代码不变,就没有再重复罗列
public class RegPromotionObserver implements RegObserver {
private PromotionService promotionService; // 依赖注入
@Override
public void handleRegSuccess(Long userId) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
promotionService.issueNewUserExperienceCash(userId);
}
});
thread.start();
}
}
// 第二种实现方式,其他类代码不变,就没有再重复罗列
public class UserController {
private UserService userService; // 依赖注入
private List<RegObserver> regObservers = new ArrayList<>();
private Executor executor;
public UserController(Executor executor) {
this.executor = executor;
}
public void setRegObservers(List<RegObserver> observers) {
regObservers.addAll(observers);
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
for (RegObserver observer : regObservers) {
executor.execute(new Runnable() {
@Override
public void run() {
observer.handleRegSuccess(userId);
}
});
}
return userId;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
对于第一种实现方式,频繁地创建和销毁线程比较耗时,并且并发线程数无法控制,创建过多的线程会导致堆栈溢出。第二种实现方式,尽管利用了线程池解决了第一种实现方式的问题,但线程池、异步执行逻辑都耦合在了 register() 函数中,增加了这部分业务代码的维护成本。
如果需求更加极端一点,需要在同步阻塞和异步非阻塞之间灵活切换,那就要不停地修改 UserController 的代码。除此之外,如果在项目中,不止一个业务模块需要用到异步非阻塞观察者模式,那这样的代码实现也无法做到复用。框架的作用有:隐藏实现细节,降低开发难度,做到代码复用,解耦业务与非业务代码,让程序员聚焦业务开发。针对异步非阻塞观察者模式,也可以将它抽象成框架来达到这样的效果,而这个框架就是 EventBus。
# 1.3.2 EventBus 框架功能需求
EventBus 翻译为“事件总线”,它提供了实现观察者模式的骨架代码。可以基于此框架,非常容易地在自己的业务场景中实现观察者模式,不需要从零开始开发。其中,Google Guava EventBus 就是一个比较著名的 EventBus 框架,它不仅仅支持异步非阻塞模式,同时也支持同步阻塞模式。用 Guava EventBus 重新实现一下:
public class UserController {
private UserService userService; // 依赖注入
private EventBus eventBus;
private static final int DEFAULT_EVENTBUS_THREAD_POOL_SIZE = 20;
public UserController() {
//eventBus = new EventBus(); // 同步阻塞模式
eventBus = new AsyncEventBus(Executors.newFixedThreadPool(DEFAULT_EVENTBUS_THREAD_POOL_SIZE)); // 异步非阻塞模式
}
public void setRegObservers(List<Object> observers) {
for (Object observer : observers) {
eventBus.register(observer);
}
}
public Long register(String telephone, String password) {
//省略输入参数的校验代码
//省略userService.register()异常的try-catch代码
long userId = userService.register(telephone, password);
eventBus.post(userId);
return userId;
}
}
public class RegPromotionObserver {
private PromotionService promotionService; // 依赖注入
@Subscribe
public void handleRegSuccess(Long userId) {
promotionService.issueNewUserExperienceCash(userId);
}
}
public class RegNotificationObserver {
private NotificationService notificationService;
@Subscribe
public void handleRegSuccess(Long userId) {
notificationService.sendInboxMessage(userId, "...");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
利用 EventBus 框架实现的观察者模式,跟从零开始编写的观察者模式相比,大致实现思路大致一样,都需要定义 Observer,并且通过 register() 函数注册 Observer,也都需要通过调用某个函数(比如,EventBus 中的 post() 函数)来给 Observer 发送消息(在 EventBus 中消息被称作事件 event)。但基于 EventBus 不需要定义 Observer 接口,任意类型的对象都可以注册到 EventBus 中,通过 @Subscribe 注解来标明类中哪个函数可以接收被观察者发送的消息。
Guava EventBus 的几个主要的类和函数。
EventBus、AsyncEventBus
Guava EventBus 对外暴露的所有可调用接口,都封装在 EventBus 类中。其中,EventBus 实现了同步阻塞的观察者模式,AsyncEventBus 继承自 EventBus,提供了异步非阻塞的观察者模式。具体使用方式如下所示:
EventBus eventBus = new EventBus(); // 同步阻塞模式 EventBus eventBus = new AsyncEventBus(Executors.newFixedThreadPool(8));// 异步阻塞模式1
2register() 函数
EventBus 类提供了 register() 函数用来注册观察者。它可以接受任何类型(Object)的观察者。而在经典的观察者模式的实现中,register() 函数必须接受实现了同一 Observer 接口的类对象。
public void register(Object object);1unregister() 函数
相对于 register() 函数,unregister() 函数用来从 EventBus 中删除某个观察者。
public void unregister(Object object);1post() 函数
EventBus 类提供了 post() 函数,用来给观察者发送消息。
public void post(Object event);1跟经典的观察者模式的不同之处在于,当调用 post() 函数发送消息的时候,并非把消息发送给所有的观察者,而是发送给可匹配的观察者。所谓可匹配指的是,能接收的消息类型是发送消息(post 函数定义中的 event)类型的父类。
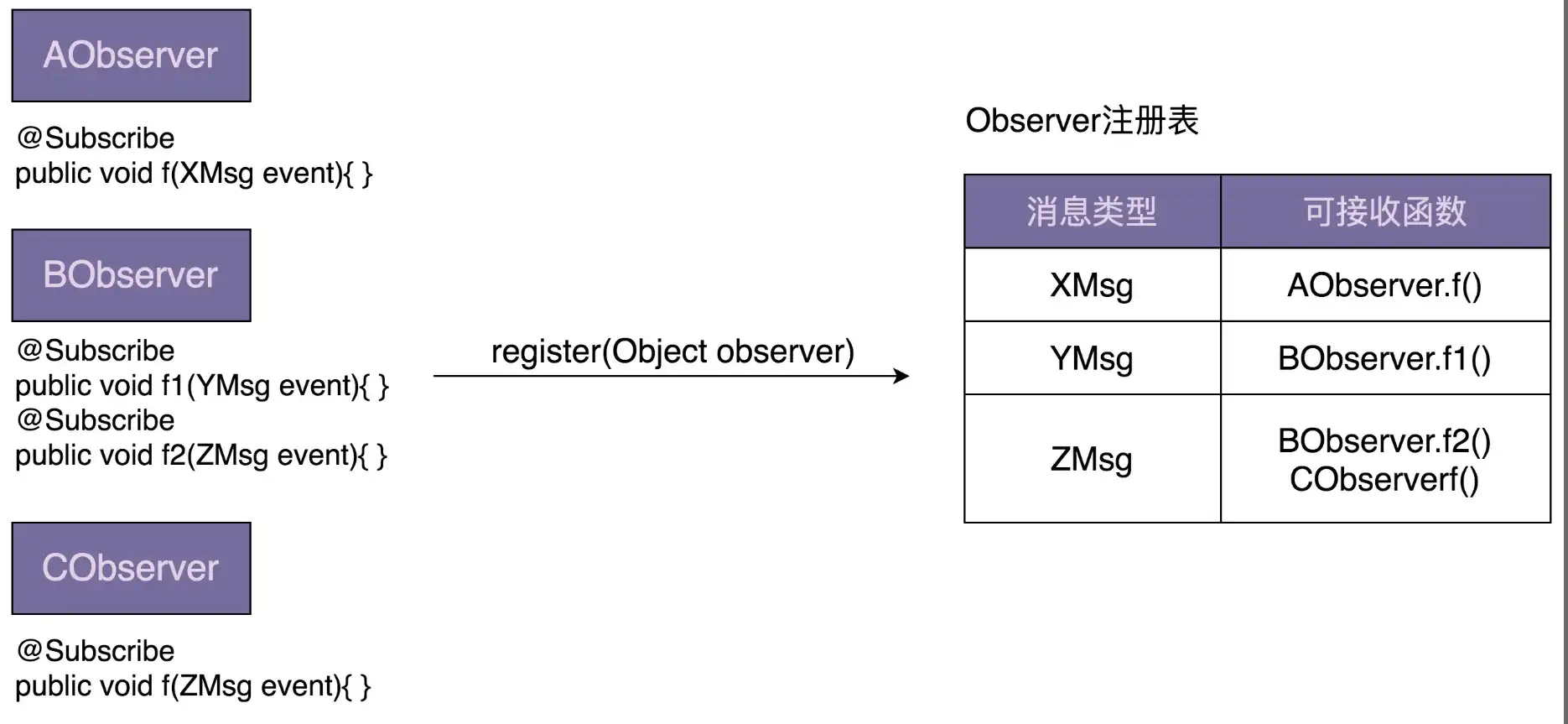
比如,AObserver 能接收的消息类型是 XMsg,BObserver 能接收的消息类型是 YMsg,CObserver 能接收的消息类型是 ZMsg。其中,XMsg 是 YMsg 的父类。当如下发送消息的时候,相应能接收到消息的可匹配观察者如下所示:
XMsg xMsg = new XMsg(); YMsg yMsg = new YMsg(); ZMsg zMsg = new ZMsg(); post(xMsg); => AObserver接收到消息 post(yMsg); => AObserver、BObserver接收到消息 post(zMsg); => CObserver接收到消息1
2
3
4
5
6@Subscribe 注解
EventBus 通过 @Subscribe 注解来标明,某个函数能接收哪种类型的消息。具体的使用代码如下所示。在 DObserver 类中,通过 @Subscribe 注解了两个函数 f1()、f2()。
public DObserver { //...省略其他属性和方法... @Subscribe public void f1(PMsg event) { //... } @Subscribe public void f2(QMsg event) { //... } }1
2
3
4
5
6
7
8
9当通过 register() 函数将 DObserver 类对象注册到 EventBus 的时候,EventBus 会根据 @Subscribe 注解找到 f1() 和 f2(),并且将两个函数能接收的消息类型记录下来(PMsg->f1,QMsg->f2)。当通过 post() 函数发送消息(比如 QMsg 消息)的时候,EventBus 会通过之前的记录(QMsg->f2),调用相应的函数(f2)。
# 1.3.3 实现一个 EventBus 框架
借鉴 Guava EventBus 的功能重复造轮子。EventBus 中两个核心函数 register() 和 post() 的实现原理如图:
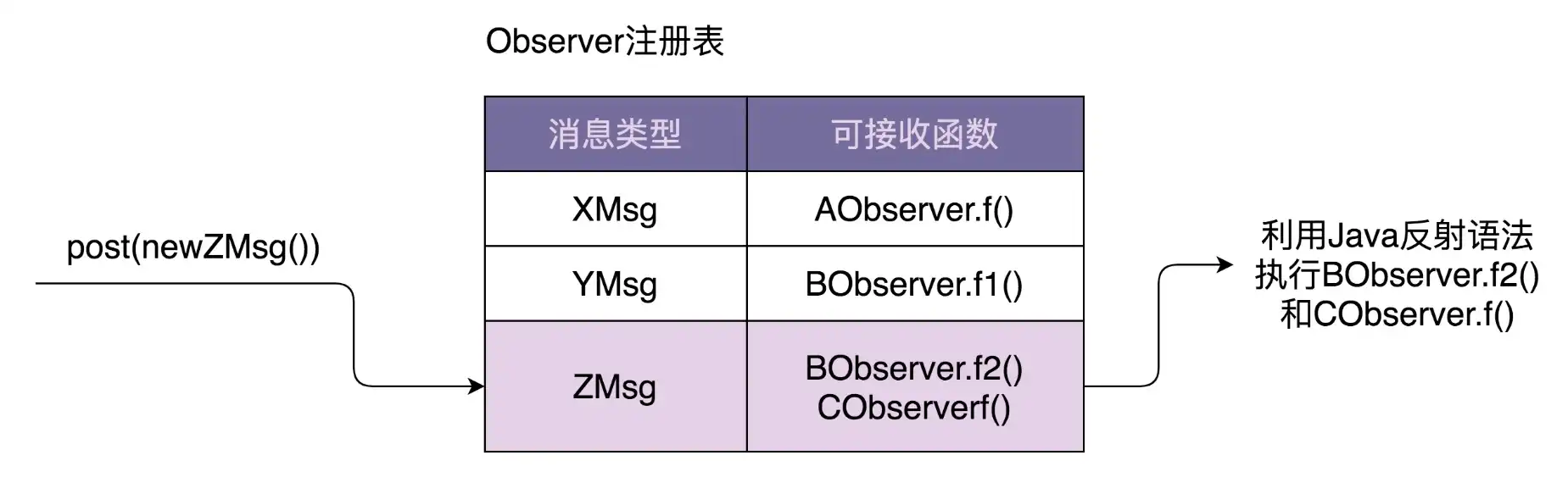
从图中可以看出,最关键的一个数据结构是 Observer 注册表,记录了消息类型和可接收消息函数的对应关系。当调用 register() 函数注册观察者的时候,EventBus 通过解析 @Subscribe 注解,生成 Observer 注册表。当调用 post() 函数发送消息的时候,EventBus 通过注册表找到相应的可接收消息的函数,然后通过 Java 的反射语法来动态地创建对象、执行函数。对于同步阻塞模式,EventBus 在一个线程内依次执行相应的函数。对于异步非阻塞模式,EventBus 通过一个线程池来执行相应的函数。
弄懂了原理,实现起来就简单多了。整个小框架的代码实现包括 5 个类:EventBus、AsyncEventBus、Subscribe、ObserverAction、ObserverRegistry。
Subscribe
Subscribe 是一个注解,用于标明观察者中的哪个函数可以接收消息。
@Retention(RetentionPolicy.RUNTIME) @Target(ElementType.METHOD) @Beta public @interface Subscribe {}1
2
3
4ObserverAction
ObserverAction 类用来表示 @Subscribe 注解的方法,其中,target 表示观察者类,method 表示方法。它主要用在 ObserverRegistry 观察者注册表中。
public class ObserverAction { private Object target; private Method method; public ObserverAction(Object target, Method method) { this.target = Preconditions.checkNotNull(target); this.method = method; this.method.setAccessible(true); } public void execute(Object event) { // event是method方法的参数 try { method.invoke(target, event); } catch (InvocationTargetException | IllegalAccessException e) { e.printStackTrace(); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18ObserverRegistry
ObserverRegistry 是最复杂的一个类,框架中几乎所有的核心逻辑都在这个类中。这个类大量使用了 Java 的反射语法,其中,一个比较有技巧的地方是 CopyOnWriteArraySet 的使用。
CopyOnWriteArraySet,顾名思义,在写入数据的时候,会创建一个新的 set,并且将原始数据 clone 到新的 set 中,在新的 set 中写入数据完成之后,再用新的 set 替换老的 set。这样就能保证在写入数据的时候,不影响数据的读取操作,以此来解决读写并发问题。除此之外,CopyOnWriteSet 还通过加锁的方式,避免了并发写冲突。
public class ObserverRegistry { private ConcurrentMap<Class<?>, CopyOnWriteArraySet<ObserverAction>> registry = new ConcurrentHashMap<>(); public void register(Object observer) { Map<Class<?>, Collection<ObserverAction>> observerActions = findAllObserverActions(observer); for (Map.Entry<Class<?>, Collection<ObserverAction>> entry : observerActions.entrySet()) { Class<?> eventType = entry.getKey(); Collection<ObserverAction> eventActions = entry.getValue(); CopyOnWriteArraySet<ObserverAction> registeredEventActions = registry.get(eventType); if (registeredEventActions == null) { registry.putIfAbsent(eventType, new CopyOnWriteArraySet<>()); registeredEventActions = registry.get(eventType); } registeredEventActions.addAll(eventActions); } } public List<ObserverAction> getMatchedObserverActions(Object event) { List<ObserverAction> matchedObservers = new ArrayList<>(); Class<?> postedEventType = event.getClass(); for (Map.Entry<Class<?>, CopyOnWriteArraySet<ObserverAction>> entry : registry.entrySet()) { Class<?> eventType = entry.getKey(); Collection<ObserverAction> eventActions = entry.getValue(); if (postedEventType.isAssignableFrom(eventType)) { matchedObservers.addAll(eventActions); } } return matchedObservers; } private Map<Class<?>, Collection<ObserverAction>> findAllObserverActions(Object observer) { Map<Class<?>, Collection<ObserverAction>> observerActions = new HashMap<>(); Class<?> clazz = observer.getClass(); for (Method method : getAnnotatedMethods(clazz)) { Class<?>[] parameterTypes = method.getParameterTypes(); Class<?> eventType = parameterTypes[0]; if (!observerActions.containsKey(eventType)) { observerActions.put(eventType, new ArrayList<>()); } observerActions.get(eventType).add(new ObserverAction(observer, method)); } return observerActions; } private List<Method> getAnnotatedMethods(Class<?> clazz) { List<Method> annotatedMethods = new ArrayList<>(); for (Method method : clazz.getDeclaredMethods()) { if (method.isAnnotationPresent(Subscribe.class)) { Class<?>[] parameterTypes = method.getParameterTypes(); Preconditions.checkArgument(parameterTypes.length == 1, "Method %s has @Subscribe annotation but has %s parameters." + "Subscriber methods must have exactly 1 parameter.", method, parameterTypes.length); annotatedMethods.add(method); } } return annotatedMethods; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59EventBus
EventBus 实现的是阻塞同步的观察者模式。MoreExecutors.directExecutor() 是 Google Guava 提供的工具类,看似是多线程,实际上是单线程。之所以要这么实现,主要还是为了跟 AsyncEventBus 统一代码逻辑,做到代码复用。
public class EventBus { private Executor executor; private ObserverRegistry registry = new ObserverRegistry(); public EventBus() { this(MoreExecutors.directExecutor()); } protected EventBus(Executor executor) { this.executor = executor; } public void register(Object object) { registry.register(object); } public void post(Object event) { List<ObserverAction> observerActions = registry.getMatchedObserverActions(event); for (ObserverAction observerAction : observerActions) { executor.execute(new Runnable() { @Override public void run() { observerAction.execute(event); } }); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28AsyncEventBus
有了 EventBus,AsyncEventBus 的实现就非常简单了。为了实现异步非阻塞的观察者模式,它就不能再继续使用 MoreExecutors.directExecutor() 了,而是需要在构造函数中,由调用者注入线程池。
public class AsyncEventBus extends EventBus { public AsyncEventBus(Executor executor) { super(executor); } }1
2
3
4
5
# 2. 模板模式
# 2.1 模板模式原理
模板模式,全称是模板方法设计模式,英文是 Template Method Design Pattern。定义:模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。模板模式有两大作用:复用和扩展。
这里的“算法”,我们可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。
如下所示。templateMethod() 函数定义为 final,是为了避免子类重写它。method1() 和 method2() 定义为 abstract,是为了强迫子类去实现。不过,这些都不是必须的,在实际的项目开发中,模板模式的代码实现比较灵活。
public abstract class AbstractClass {
public final void templateMethod() {
//...
method1();
//...
method2();
//...
}
protected abstract void method1();
protected abstract void method2();
}
public class ConcreteClass1 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
public class ConcreteClass2 extends AbstractClass {
@Override
protected void method1() {
//...
}
@Override
protected void method2() {
//...
}
}
AbstractClass demo = ConcreteClass1();
demo.templateMethod();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 2.2 模板模式应用
模板模式有两大作用:复用和扩展。
# 2.2.1 复用
模板模式把一个算法中不变的流程抽象到父类的模板方法 templateMethod() 中,将可变的部分 method1()、method2() 留给子类 ContreteClass1 和 ContreteClass2 来实现。所有的子类都可以复用父类中模板方法定义的流程代码。
Java InputStream
下面是 InputStream 部分相关代码。在代码中,read() 函数是一个模板方法,定义了读取数据的整个流程,并且暴露了一个可以由子类来定制的抽象方法。不过这个方法也被命名为了 read(),只是参数跟模板方法不同。
public abstract class InputStream implements Closeable { //...省略其他代码... public int read(byte b[], int off, int len) throws IOException { if (b == null) { throw new NullPointerException(); } else if (off < 0 || len < 0 || len > b.length - off) { throw new IndexOutOfBoundsException(); } else if (len == 0) { return 0; } int c = read(); if (c == -1) { return -1; } b[off] = (byte)c; int i = 1; try { for (; i < len ; i++) { c = read(); if (c == -1) { break; } b[off + i] = (byte)c; } } catch (IOException ee) { } return i; } public abstract int read() throws IOException; } public class ByteArrayInputStream extends InputStream { //...省略其他代码... @Override public synchronized int read() { return (pos < count) ? (buf[pos++] & 0xff) : -1; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43Java AbstractList
在 Java AbstractList 类中,addAll() 函数可以看作模板方法,add() 是子类需要重写的方法,尽管没有声明为 abstract 的,但函数实现直接抛出了 UnsupportedOperationException 异常。前提是,如果子类不重写是不能使用的。
public boolean addAll(int index, Collection<? extends E> c) { rangeCheckForAdd(index); boolean modified = false; for (E e : c) { add(index++, e); modified = true; } return modified; } public void add(int index, E element) { throw new UnsupportedOperationException(); }1
2
3
4
5
6
7
8
9
10
11
12
13
# 2.2.2 扩展
模板模式的第二大作用的是扩展。这里的扩展并不是指代码的扩展性,而是指框架的扩展性,有点类似控制反转。基于这个作用,模板模式常用在框架的开发中,让框架用户可以在不修改框架源码的情况下,定制化框架的功能。
Java Selvlet
Java 常用的开发框架是 SpringMVC 中使用比较底层的 Servlet 来开发 Web 时,只需要定义一个继承 HttpServlet 的类,并且重写其中的 doGet() 或 doPost() 方法,来分别处理 get 和 post 请求。具体的代码示例如下所示:
public class HelloServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { resp.getWriter().write("Hello World."); } }1
2
3
4
5
6
7
8
9
10
11还需要在配置文件 web.xml 中做如下配置。Tomcat、Jetty 等 Servlet 容器在启动的时候,会自动加载这个配置文件中的 URL 和 Servlet 之间的映射关系。
<servlet> <servlet-name>HelloServlet</servlet-name> <servlet-class>com.xzg.cd.HelloServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>HelloServlet</servlet-name> <url-pattern>/hello</url-pattern> </servlet-mapping>1
2
3
4
5
6
7
8
9当在浏览器中输入网址(比如,http://127.0.0.1:8080/hello )的时候,Servlet 容器会接收到相应的请求,并且根据 URL 和 Servlet 之间的映射关系,找到相应的 Servlet(HelloServlet),然后执行它的 service() 方法。service() 方法定义在父类 HttpServlet 中,它会调用 doGet() 或 doPost() 方法,然后输出数据(“Hello world”)到网页。HttpServlet 的 service() 函数如下:
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException { HttpServletRequest request; HttpServletResponse response; if (!(req instanceof HttpServletRequest && res instanceof HttpServletResponse)) { throw new ServletException("non-HTTP request or response"); } request = (HttpServletRequest) req; response = (HttpServletResponse) res; service(request, response); } protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String method = req.getMethod(); if (method.equals(METHOD_GET)) { long lastModified = getLastModified(req); if (lastModified == -1) { // servlet doesn't support if-modified-since, no reason // to go through further expensive logic doGet(req, resp); } else { long ifModifiedSince = req.getDateHeader(HEADER_IFMODSINCE); if (ifModifiedSince < lastModified) { // If the servlet mod time is later, call doGet() // Round down to the nearest second for a proper compare // A ifModifiedSince of -1 will always be less maybeSetLastModified(resp, lastModified); doGet(req, resp); } else { resp.setStatus(HttpServletResponse.SC_NOT_MODIFIED); } } } else if (method.equals(METHOD_HEAD)) { long lastModified = getLastModified(req); maybeSetLastModified(resp, lastModified); doHead(req, resp); } else if (method.equals(METHOD_POST)) { doPost(req, resp); } else if (method.equals(METHOD_PUT)) { doPut(req, resp); } else if (method.equals(METHOD_DELETE)) { doDelete(req, resp); } else if (method.equals(METHOD_OPTIONS)) { doOptions(req,resp); } else if (method.equals(METHOD_TRACE)) { doTrace(req,resp); } else { String errMsg = lStrings.getString("http.method_not_implemented"); Object[] errArgs = new Object[1]; errArgs[0] = method; errMsg = MessageFormat.format(errMsg, errArgs); resp.sendError(HttpServletResponse.SC_NOT_IMPLEMENTED, errMsg); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58从上面的代码中可以看出,HttpServlet 的 service() 方法就是一个模板方法,它实现了整个 HTTP 请求的执行流程,doGet()、doPost() 是模板中可以由子类来定制的部分。实际上,这就相当于 Servlet 框架提供了一个扩展点(doGet()、doPost() 方法),让框架用户在不用修改 Servlet 框架源码的情况下,将业务代码通过扩展点镶嵌到框架中执行。
Junit TestCase
JUnit 框架也通过模板模式提供了一些功能扩展点(setUp()、tearDown() 等),让框架用户可以在这些扩展点上扩展功能。
在使用 JUnit 测试框架来编写单元测试的时候,编写的测试类都要继承框架提供的 TestCase 类。在 TestCase 类中,runBare() 函数是模板方法,它定义了执行测试用例的整体流程:先执行 setUp() 做些准备工作,然后执行 runTest() 运行真正的测试代码,最后执行 tearDown() 做扫尾工作。
尽管 setUp()、tearDown() 并不是抽象函数,还提供了默认的实现,不强制子类去重新实现,但这部分也是可以在子类中定制的,所以也符合模板模式的定义。
public abstract class TestCase extends Assert implements Test { public void runBare() throws Throwable { Throwable exception = null; setUp(); try { runTest(); } catch (Throwable running) { exception = running; } finally { try { tearDown(); } catch (Throwable tearingDown) { if (exception == null) exception = tearingDown; } } if (exception != null) throw exception; } /** * Sets up the fixture, for example, open a network connection. * This method is called before a test is executed. */ protected void setUp() throws Exception { } /** * Tears down the fixture, for example, close a network connection. * This method is called after a test is executed. */ protected void tearDown() throws Exception { } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 2.3 模板模式与 Callback 回调函数有何区别
# 2.3.1 回调原理
相对于普通的函数调用来说,回调是一种双向调用关系。A 类事先注册某个函数 F 到 B 类,A 类在调用 B 类的 P 函数的时候,B 类反过来调用 A 类注册给它的 F 函数。这里的 F 函数就是“回调函数”。A 调用 B,B 反过来又调用 A,这种调用机制就叫作“回调”。
Java 则需要使用包裹了回调函数的类对象,简称为回调对象。代码如下所示:
public interface ICallback {
void methodToCallback();
}
public class BClass {
public void process(ICallback callback) {
//...
callback.methodToCallback();
//...
}
}
public class AClass {
public static void main(String[] args) {
BClass b = new BClass();
b.process(new ICallback() { //回调对象
@Override
public void methodToCallback() {
System.out.println("Call back me.");
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
回调跟模板模式一样,也具有复用和扩展的功能。除了回调函数之外,BClass 类的 process() 函数中的逻辑都可以复用。如果 ICallback、BClass 类是框架代码,AClass 是使用框架的客户端代码,可以通过 ICallback 定制 process() 函数,也就是说,框架因此具有了扩展的能力。
实际上,回调不仅可以应用在代码设计上,在更高层次的架构设计上也比较常用。比如,通过三方支付系统来实现支付功能,用户在发起支付请求之后,一般不会一直阻塞到支付结果返回,而是注册回调接口(类似回调函数,一般是一个回调用的 URL)给三方支付系统,等三方支付系统执行完成之后,将结果通过回调接口返回给用户。
回调可以分为同步回调和异步回调(或者延迟回调)。同步回调指在函数返回之前执行回调函数;异步回调指的是在函数返回之后执行回调函数。上面的代码实际上是同步回调的实现方式,在 process() 函数返回之前,执行完回调函数 methodToCallback()。而上面支付的例子是异步回调的实现方式,发起支付之后不需要等待回调接口被调用就直接返回。从应用场景上来看,同步回调看起来更像模板模式,异步回调看起来更像观察者模式。
# 2.3.2 回调的应用
JdbcTemplate
Spring 提供了很多 Template 类,比如,JdbcTemplate、RedisTemplate、RestTemplate。尽管都叫作 xxxTemplate,但它们并非基于模板模式来实现的,而是基于回调来实现的,确切地说应该是同步回调。而同步回调从应用场景上很像模板模式,所以,在命名上,这些类使用 Template(模板)这个单词作为后缀。
直接使用 JDBC 类库来编写操作数据库的代码如下:
public class JdbcDemo { public User queryUser(long id) { Connection conn = null; Statement stmt = null; try { //1.加载驱动 Class.forName("com.mysql.jdbc.Driver"); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/demo", "xzg", "xzg"); //2.创建statement类对象,用来执行SQL语句 stmt = conn.createStatement(); //3.ResultSet类,用来存放获取的结果集 String sql = "select * from user where id=" + id; ResultSet resultSet = stmt.executeQuery(sql); String eid = null, ename = null, price = null; while (resultSet.next()) { User user = new User(); user.setId(resultSet.getLong("id")); user.setName(resultSet.getString("name")); user.setTelephone(resultSet.getString("telephone")); return user; } } catch (ClassNotFoundException e) { // TODO: log... } catch (SQLException e) { // TODO: log... } finally { if (conn != null) try { conn.close(); } catch (SQLException e) { // TODO: log... } if (stmt != null) try { stmt.close(); } catch (SQLException e) { // TODO: log... } } return null; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47queryUser() 函数包含很多流程性质的代码,跟业务无关,比如,加载驱动、创建数据库连接、创建 statement、关闭连接、关闭 statement、处理异常。针对不同的 SQL 执行请求,这些流程性质的代码是相同的、可以复用的,不需要每次都重新敲一遍。
针对这个问题,Spring 提供了 JdbcTemplate,对 JDBC 进一步封装,来简化数据库编程。使用 JdbcTemplate 查询用户信息,只需要编写跟这个业务有关的代码,其中包括,查询用户的 SQL 语句、查询结果与 User 对象之间的映射关系。其他流程性质的代码都封装在了 JdbcTemplate 类中,不需要每次都重新编写。使用 JdbcTemplate 重写后如下:
public class JdbcTemplateDemo { private JdbcTemplate jdbcTemplate; public User queryUser(long id) { String sql = "select * from user where id="+id; return jdbcTemplate.query(sql, new UserRowMapper()).get(0); } class UserRowMapper implements RowMapper<User> { public User mapRow(ResultSet rs, int rowNum) throws SQLException { User user = new User(); user.setId(rs.getLong("id")); user.setName(rs.getString("name")); user.setTelephone(rs.getString("telephone")); return user; } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18部分源码:JdbcTemplate 通过回调的机制,将不变的执行流程抽离出来,放到模板方法 execute() 中,将可变的部分设计成回调 StatementCallback,由用户来定制。query() 函数是对 execute() 函数的二次封装,让接口用起来更加方便。
@Override public <T> List<T> query(String sql, RowMapper<T> rowMapper) throws DataAccessException { return query(sql, new RowMapperResultSetExtractor<T>(rowMapper)); } @Override public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException { Assert.notNull(sql, "SQL must not be null"); Assert.notNull(rse, "ResultSetExtractor must not be null"); if (logger.isDebugEnabled()) { logger.debug("Executing SQL query [" + sql + "]"); } class QueryStatementCallback implements StatementCallback<T>, SqlProvider { @Override public T doInStatement(Statement stmt) throws SQLException { ResultSet rs = null; try { rs = stmt.executeQuery(sql); ResultSet rsToUse = rs; if (nativeJdbcExtractor != null) { rsToUse = nativeJdbcExtractor.getNativeResultSet(rs); } return rse.extractData(rsToUse); } finally { JdbcUtils.closeResultSet(rs); } } @Override public String getSql() { return sql; } } return execute(new QueryStatementCallback()); } @Override public <T> T execute(StatementCallback<T> action) throws DataAccessException { Assert.notNull(action, "Callback object must not be null"); Connection con = DataSourceUtils.getConnection(getDataSource()); Statement stmt = null; try { Connection conToUse = con; if (this.nativeJdbcExtractor != null && this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativeStatements()) { conToUse = this.nativeJdbcExtractor.getNativeConnection(con); } stmt = conToUse.createStatement(); applyStatementSettings(stmt); Statement stmtToUse = stmt; if (this.nativeJdbcExtractor != null) { stmtToUse = this.nativeJdbcExtractor.getNativeStatement(stmt); } T result = action.doInStatement(stmtToUse); handleWarnings(stmt); return result; } catch (SQLException ex) { // Release Connection early, to avoid potential connection pool deadlock // in the case when the exception translator hasn't been initialized yet. JdbcUtils.closeStatement(stmt); stmt = null; DataSourceUtils.releaseConnection(con, getDataSource()); con = null; throw getExceptionTranslator().translate("StatementCallback", getSql(action), ex); } finally { JdbcUtils.closeStatement(stmt); DataSourceUtils.releaseConnection(con, getDataSource()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74setClickListener()
在客户端开发中,经常给控件注册事件监听器,比如下面这段代码,就是在 Android 应用开发中,给 Button 控件的点击事件注册监听器。
Button button = (Button)findViewById(R.id.button); button.setOnClickListener(new OnClickListener() { @Override public void onClick(View v) { System.out.println("I am clicked."); } });1
2
3
4
5
6
7从代码结构上来看,事件监听器很像回调,即传递一个包含回调函数(onClick())的对象给另一个函数。从应用场景上来看,它又很像观察者模式,即事先注册观察者(OnClickListener),当用户点击按钮的时候,发送点击事件给观察者,并且执行相应的 onClick() 函数。
回调分为同步回调和异步回调。这里的回调算是异步回调,往 setOnClickListener() 函数中注册好回调函数之后,并不需要等待回调函数执行。异步回调比较像观察者模式。
addShutdownHook()
Hook 可以翻译成“钩子”,有人觉得 Hook 是 Callback 的一种应用。Callback 更侧重语法机制的描述,Hook 更加侧重应用场景的描述。Hook 比较经典的应用场景是 Tomcat 和 JVM 的 shutdown hook。拿 JVM 来举例说明一下。JVM 提供了 Runtime.addShutdownHook(Thread hook) 方法,可以注册一个 JVM 关闭的 Hook。当应用程序关闭的时候,JVM 会自动调用 Hook 代码。代码示例如下所示:
public class ShutdownHookDemo { private static class ShutdownHook extends Thread { public void run() { System.out.println("I am called during shutting down."); } } public static void main(String[] args) { Runtime.getRuntime().addShutdownHook(new ShutdownHook()); } }1
2
3
4
5
6
7
8
9
10
11
12
13再来看 addShutdownHook() 的部分相关代码:
public class Runtime { public void addShutdownHook(Thread hook) { SecurityManager sm = System.getSecurityManager(); if (sm != null) { sm.checkPermission(new RuntimePermission("shutdownHooks")); } ApplicationShutdownHooks.add(hook); } } class ApplicationShutdownHooks { /* The set of registered hooks */ private static IdentityHashMap<Thread, Thread> hooks; static { hooks = new IdentityHashMap<>(); } catch (IllegalStateException e) { hooks = null; } } static synchronized void add(Thread hook) { if(hooks == null) throw new IllegalStateException("Shutdown in progress"); if (hook.isAlive()) throw new IllegalArgumentException("Hook already running"); if (hooks.containsKey(hook)) throw new IllegalArgumentException("Hook previously registered"); hooks.put(hook, hook); } static void runHooks() { Collection<Thread> threads; synchronized(ApplicationShutdownHooks.class) { threads = hooks.keySet(); hooks = null; } for (Thread hook : threads) { hook.start(); } for (Thread hook : threads) { while (true) { try { hook.join(); break; } catch (InterruptedException ignored) { } } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54从代码中可以发现,有关 Hook 的逻辑都被封装到 ApplicationShutdownHooks 类中了。当应用程序关闭的时候,JVM 会调用这个类的 runHooks() 方法,创建多个线程,并发地执行多个 Hook。在注册完 Hook 之后,并不需要等待 Hook 执行完成,所以,这也算是一种异步回调。
# 2.3.3 模板模式 VS 回调
从应用场景上来看,同步回调跟模板模式几乎一致。它们都是在一个大的算法骨架中,自由替换其中的某个步骤,起到代码复用和扩展的目的。而异步回调跟模板模式有较大差别,更像是观察者模式。
从代码实现上来看,回调和模板模式完全不同。回调基于组合关系来实现,把一个对象传递给另一个对象,是一种对象之间的关系;模板模式基于继承关系来实现,子类重写父类的抽象方法,是一种类之间的关系。
在代码实现上,回调相对于模板模式会更加灵活,主要体现在下面几点:
- 像 Java 这种只支持单继承的语言,基于模板模式编写的子类,已经继承了一个父类,不再具有继承的能力。
- 回调可以使用匿名类来创建回调对象,可以不用事先定义类;而模板模式针对不同的实现都要定义不同的子类。
- 如果某个类中定义了多个模板方法,每个方法都有对应的抽象方法,那即便只用到其中的一个模板方法,子类也必须实现所有的抽象方法。而回调就更加灵活,只需要往用到的模板方法中注入回调对象即可。
# 3. 策略模式
# 3.1 策略模式原理
策略模式,英文全称是 Strategy Design Pattern。定义:定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)
工厂模式是解耦对象的创建和使用,观察者模式是解耦观察者和被观察者。策略模式跟两者类似,也能起到解耦的作用,不过,它解耦的是策略的定义、创建、使用这三部分。
策略的定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。
public interface Strategy { void algorithmInterface(); } public class ConcreteStrategyA implements Strategy { @Override public void algorithmInterface() { //具体的算法... } } public class ConcreteStrategyB implements Strategy { @Override public void algorithmInterface() { //具体的算法... } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,需要对客户端代码屏蔽创建细节。可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。
public class StrategyFactory { private static final Map<String, Strategy> strategies = new HashMap<>(); static { strategies.put("A", new ConcreteStrategyA()); strategies.put("B", new ConcreteStrategyB()); } public static Strategy getStrategy(String type) { if (type == null || type.isEmpty()) { throw new IllegalArgumentException("type should not be empty."); } return strategies.get(type); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15一般来讲,如果策略类是无状态的,不包含成员变量,只是纯粹的算法实现,这样的策略对象是可以被共享使用的,不需要在每次调用 getStrategy() 的时候,都创建一个新的策略对象。针对这种情况,可以使用上面这种工厂类的实现方式,事先创建好每个策略对象,缓存到工厂类中,用的时候直接返回。
相反,如果策略类是有状态的,根据业务场景的需要,希望每次从工厂方法中,获得的都是新创建的策略对象,而不是缓存好可共享的策略对象,那就需要按照如下方式来实现策略工厂类。
public class StrategyFactory { public static Strategy getStrategy(String type) { if (type == null || type.isEmpty()) { throw new IllegalArgumentException("type should not be empty."); } if (type.equals("A")) { return new ConcreteStrategyA(); } else if (type.equals("B")) { return new ConcreteStrategyB(); } return null; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15策略的使用
策略模式包含一组可选策略,客户端代码一般如何确定使用哪个策略呢?最常见的是运行时动态确定使用哪种策略,这也是策略模式最典型的应用场景。
这里的“运行时动态”指的是事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。
// 策略接口:EvictionStrategy // 策略类:LruEvictionStrategy、FifoEvictionStrategy、LfuEvictionStrategy... // 策略工厂:EvictionStrategyFactory public class UserCache { private Map<String, User> cacheData = new HashMap<>(); private EvictionStrategy eviction; public UserCache(EvictionStrategy eviction) { this.eviction = eviction; } //... } // 运行时动态确定,根据配置文件的配置决定使用哪种策略 public class Application { public static void main(String[] args) throws Exception { EvictionStrategy evictionStrategy = null; Properties props = new Properties(); props.load(new FileInputStream("./config.properties")); String type = props.getProperty("eviction_type"); evictionStrategy = EvictionStrategyFactory.getEvictionStrategy(type); UserCache userCache = new UserCache(evictionStrategy); //... } } // 非运行时动态确定,在代码中指定使用哪种策略 public class Application { public static void main(String[] args) { //... EvictionStrategy evictionStrategy = new LruEvictionStrategy(); UserCache userCache = new UserCache(evictionStrategy); //... } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37“非运行时动态确定”,也就是第二个 Application 中的使用方式,并不能发挥策略模式的优势。在这种应用场景下,策略模式实际上退化成了“面向对象的多态特性”或“基于接口而非实现编程原则”。
# 3.2 利用策略模式避免分支判断
实际上,能够移除分支判断逻辑的模式不仅仅有策略模式,状态模式也可以。对于使用哪种模式,具体还要看应用场景来定。 策略模式适用于根据不同类型的动态,决定使用哪种策略这样一种应用场景。
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
if (type.equals(OrderType.NORMAL)) { // 普通订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.GROUPON)) { // 团购订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.PROMOTION)) { // 促销订单
//...省略折扣计算算法代码
}
return discount;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如何来移除掉分支判断逻辑呢?那策略模式就派上用场了。使用策略模式对上面的代码重构,将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。具体的代码如下所示:
// 策略的定义
public interface DiscountStrategy {
double calDiscount(Order order);
}
// 省略NormalDiscountStrategy、GrouponDiscountStrategy、PromotionDiscountStrategy类代码...
// 策略的创建
public class DiscountStrategyFactory {
private static final Map<OrderType, DiscountStrategy> strategies = new HashMap<>();
static {
strategies.put(OrderType.NORMAL, new NormalDiscountStrategy());
strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy());
strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy());
}
public static DiscountStrategy getDiscountStrategy(OrderType type) {
return strategies.get(type);
}
}
// 策略的使用
public class OrderService {
public double discount(Order order) {
OrderType type = order.getType();
DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type);
return discountStrategy.calDiscount(order);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
重构之后的代码就没有了 if-else 分支判断语句了。实际上,这得益于策略工厂类。在工厂类中用 Map 来缓存策略,根据 type 直接从 Map 中获取对应的策略,从而避免 if-else 分支判断逻辑。其实是借助“查表法”,根据 type 查表(代码中的 strategies 就是表)替代根据 type 分支判断。
但是,如果业务场景需要每次都创建不同的策略对象,就要用另外一种工厂类的实现方式了。具体的代码如下所示:
public class DiscountStrategyFactory {
public static DiscountStrategy getDiscountStrategy(OrderType type) {
if (type == null) {
throw new IllegalArgumentException("Type should not be null.");
}
if (type.equals(OrderType.NORMAL)) {
return new NormalDiscountStrategy();
} else if (type.equals(OrderType.GROUPON)) {
return new GrouponDiscountStrategy();
} else if (type.equals(OrderType.PROMOTION)) {
return new PromotionDiscountStrategy();
}
return null;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这种实现方式相当于把原来的 if-else 分支逻辑,从 OrderService 类中转移到了工厂类中,实际上并没有真正将它移除。其实仍然可以用查表法,只不过存储的不再是实例而是 class,使用时获取对应的 class,再通过反射创建实例。
# 3.3 实现一个支持给不同大小文件排序的小程序
# 3.3.1 问题与解决思路
写一个小程序,实现对一个文件进行排序的功能。文件中只包含整型数,并且,相邻的数字通过逗号来区隔。
正常思路:只需要将文件中的内容读取出来,并且通过逗号分割成一个一个的数字,放到内存数组中,然后编写某种排序算法(比如快排),或者直接使用编程语言提供的排序函数,对数组进行排序,最后再将数组中的数据写入文件就可以了。
但如果文件很大,比如有 10GB 大小,因为内存有限(比如只有 8GB 大小),没办法一次性加载文件中的所有数据到内存中,这个时候就要利用外部排序算法了。如果文件更大,比如有 100GB 大小,为了利用 CPU 多核的优势,可以在外部排序的基础之上进行优化,加入多线程并发排序的功能,这就有点类似“单机版”的 MapReduce。如果文件非常大,比如有 1TB 大小,即便是单机多线程排序,这也算很慢了。这个时候可以使用真正的 MapReduce 框架,利用多机的处理能力,提高排序的效率。
# 3.3.2 代码实现与分析
先用最简单直接的方式将它实现出来。具体代码如下(不包括算法):
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
if (fileSize < 6 * GB) { // [0, 6GB)
quickSort(filePath);
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
externalSort(filePath);
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
concurrentExternalSort(filePath);
} else { // [100GB, ~)
mapreduceSort(filePath);
}
}
private void quickSort(String filePath) {
// 快速排序
}
private void externalSort(String filePath) {
// 外部排序
}
private void concurrentExternalSort(String filePath) {
// 多线程外部排序
}
private void mapreduceSort(String filePath) {
// 利用MapReduce多机排序
}
}
public class SortingTool {
public static void main(String[] args) {
Sorter sorter = new Sorter();
sorter.sortFile(args[0]);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
为了避免 sortFile() 函数过长,把每种排序算法从 sortFile() 函数中抽离出来,拆分成 4 个独立的排序函数。如果只是开发一个简单的工具,那上面的代码实现就足够了。毕竟代码不多,后续修改、扩展的需求也不多,怎么写都不会导致代码不可维护。但是,如果是在开发一个大型项目,排序文件只是其中的一个功能模块,那就要在代码设计、代码质量上下点儿功夫了。只有每个小的功能模块都写好,整个项目的代码才能不差。
# 3.3.3 代码优化与重构
public interface ISortAlg {
void sort(String filePath);
}
public class QuickSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class ExternalSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class ConcurrentExternalSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class MapReduceSort implements ISortAlg {
@Override
public void sort(String filePath) {
//...
}
}
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg;
if (fileSize < 6 * GB) { // [0, 6GB)
sortAlg = new QuickSort();
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
sortAlg = new ExternalSort();
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
sortAlg = new ConcurrentExternalSort();
} else { // [100GB, ~)
sortAlg = new MapReduceSort();
}
sortAlg.sort(filePath);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
经过拆分之后,每个类的代码都不会太多,每个类的逻辑都不会太复杂,代码的可读性、可维护性提高了。除此之外,将排序算法设计成独立的类,跟具体的业务逻辑(代码中的 if-else 那部分逻辑)解耦,也让排序算法能够复用。这一步实际上就是策略模式的第一步,也就是将策略的定义分离出来。
实际上,上面的代码还可以继续优化。每种排序类都是无状态的,没必要在每次使用的时候都重新创建一个新的对象。所以可以使用工厂模式对对象的创建进行封装。如下:
public class SortAlgFactory {
private static final Map<String, ISortAlg> algs = new HashMap<>();
static {
algs.put("QuickSort", new QuickSort());
algs.put("ExternalSort", new ExternalSort());
algs.put("ConcurrentExternalSort", new ConcurrentExternalSort());
algs.put("MapReduceSort", new MapReduceSort());
}
public static ISortAlg getSortAlg(String type) {
if (type == null || type.isEmpty()) {
throw new IllegalArgumentException("type should not be empty.");
}
return algs.get(type);
}
}
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg;
if (fileSize < 6 * GB) { // [0, 6GB)
sortAlg = SortAlgFactory.getSortAlg("QuickSort");
} else if (fileSize < 10 * GB) { // [6GB, 10GB)
sortAlg = SortAlgFactory.getSortAlg("ExternalSort");
} else if (fileSize < 100 * GB) { // [10GB, 100GB)
sortAlg = SortAlgFactory.getSortAlg("ConcurrentExternalSort");
} else { // [100GB, ~)
sortAlg = SortAlgFactory.getSortAlg("MapReduceSort");
}
sortAlg.sort(filePath);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
经过上面两次重构之后,现在的代码实际上已经符合策略模式的代码结构了。通过策略模式将策略的定义、创建、使用解耦,让每一部分都不至于太复杂。不过,Sorter 类中的 sortFile() 函数还是有一堆 if-else 逻辑。这里的 if-else 逻辑分支不多、也不复杂,这样写完全没问题。但如果特别想将 if-else 分支判断移除掉,如下:
public class Sorter {
private static final long GB = 1000 * 1000 * 1000;
private static final List<AlgRange> algs = new ArrayList<>();
static {
algs.add(new AlgRange(0, 6*GB, SortAlgFactory.getSortAlg("QuickSort")));
algs.add(new AlgRange(6*GB, 10*GB, SortAlgFactory.getSortAlg("ExternalSort")));
algs.add(new AlgRange(10*GB, 100*GB, SortAlgFactory.getSortAlg("ConcurrentExternalSort")));
algs.add(new AlgRange(100*GB, Long.MAX_VALUE, SortAlgFactory.getSortAlg("MapReduceSort")));
}
public void sortFile(String filePath) {
// 省略校验逻辑
File file = new File(filePath);
long fileSize = file.length();
ISortAlg sortAlg = null;
for (AlgRange algRange : algs) {
if (algRange.inRange(fileSize)) {
sortAlg = algRange.getAlg();
break;
}
}
sortAlg.sort(filePath);
}
private static class AlgRange {
private long start;
private long end;
private ISortAlg alg;
public AlgRange(long start, long end, ISortAlg alg) {
this.start = start;
this.end = end;
this.alg = alg;
}
public ISortAlg getAlg() {
return alg;
}
public boolean inRange(long size) {
return size >= start && size < end;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
现在的代码实现就更加优美了。把可变的部分隔离到了策略工厂类和 Sorter 类中的静态代码段中。当要添加一个新的排序算法时,只需要修改策略工厂类和 Sort 类中的静态代码段,其他代码都不需要修改,这样就将代码改动最小化、集中化了。
即便这样当添加新的排序算法的时候,还是需要修改代码,并不完全符合开闭原则。有什么办法完全满足开闭原则呢?
对于 Java 语言来说,可以通过反射来避免对策略工厂类的修改。具体是这么做的:通过一个配置文件或者自定义的 annotation 来标注都有哪些策略类;策略工厂类读取配置文件或者搜索被 annotation 标注的策略类,然后通过反射动态地加载这些策略类、创建策略对象;当新添加一个策略的时候,只需要将这个新添加的策略类添加到配置文件或者用 annotation 标注即可。
对于 Sorter 来说,可以通过同样的方法来避免修改。通过将文件大小区间和算法之间的对应关系放到配置文件中。当添加新的排序算法时,我们只需要改动配置文件即可,不需要改动代码。
# 4. 职责链模式
模板模式、策略模式,职责链模式这三种模式具有相同的作用:复用和扩展,在实际的项目开发中比较常用,特别是框架开发中可以利用它们来提供框架的扩展点,能够让框架的使用者在不修改框架源码的情况下,基于扩展点定制化框架的功能。
# 4.1 职责链模式的原理
职责链模式的英文翻译是 Chain Of Responsibility Design Pattern。定义:将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。职责链模式有多种实现方式,这里介绍两种比较常用的。
第一种实现方式如下所示。其中,Handler 是所有处理器类的抽象父类,handle() 是抽象方法。每个具体的处理器类(HandlerA、HandlerB)的 handle() 函数的代码结构类似,如果它能处理该请求,就不继续往下传递;如果不能处理,则交由后面的处理器来处理(也就是调用 successor.handle())。HandlerChain 是处理器链,从数据结构的角度来看,它就是一个记录了链头、链尾的链表。其中,记录链尾是为了方便添加处理器。
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public abstract void handle();
}
public class HandlerA extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerB extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
上面的代码实现不够优雅。处理器类的 handle() 函数,不仅包含自己的业务逻辑,还包含对下一个处理器的调用,也就是代码中的 successor.handle()。一个不熟悉这种代码结构的程序员,在添加新的处理器类的时候,很有可能忘记在 handle() 函数中调用 successor.handle(),这就会导致代码出现 bug。
针对这个问题,利用模板模式对代码进行重构,将调用 successor.handle() 的逻辑从具体的处理器类中剥离出来,放到抽象父类中。这样具体的处理器类只需要实现自己的业务逻辑就可以了。重构之后的代码如下所示:
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
boolean handled = doHandle();
if (successor != null && !handled) {
successor.handle();
}
}
protected abstract boolean doHandle();
}
public class HandlerA extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
// HandlerChain和Application代码不变
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
第二种实现方式,代码如下所示。这种实现方式更加简单。HandlerChain 类用数组而非链表来保存所有的处理器,并且需要在 HandlerChain 的 handle() 函数中,依次调用每个处理器的 handle() 函数。
public interface IHandler {
boolean handle();
}
public class HandlerA implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerChain {
private List<IHandler> handlers = new ArrayList<>();
public void addHandler(IHandler handler) {
this.handlers.add(handler);
}
public void handle() {
for (IHandler handler : handlers) {
boolean handled = handler.handle();
if (handled) {
break;
}
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
如果处理器链上的某个处理器能够处理这个请求,那就不会继续往下传递请求。实际上,职责链模式还有一种变体,那就是请求会被所有的处理器都处理一遍,不存在中途终止的情况。这种变体也有两种实现方式:用链表存储处理器和用数组存储处理器,跟上面的两种实现方式类似,只需要稍微修改即可。
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
doHandle();
if (successor != null) {
successor.handle();
}
}
protected abstract void doHandle();
}
public class HandlerA extends Handler {
@Override
protected void doHandle() {
//...
}
}
public class HandlerB extends Handler {
@Override
protected void doHandle() {
//...
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 4.2 实现可灵活扩展算法的敏感信息过滤框架
通过一个实际的例子,来学习一下职责链模式的应用场景。
对于支持 UGC(User Generated Content,用户生成内容)的应用(比如论坛)来说,用户生成的内容(比如,在论坛中发表的帖子)可能会包含一些敏感词(比如涉黄、广告、反动等词汇)。针对这个应用场景,就可以利用职责链模式来过滤这些敏感词。
对于包含敏感词的内容有两种处理方式,一种是直接禁止发布,另一种是给敏感词打马赛克(比如,用 *** 替换敏感词)之后再发布。第一种处理方式符合 GoF 给出的职责链模式的定义,第二种处理方式是职责链模式的变体。
第一种实现方式的代码示例,如下所示(不包括算法):
public interface SensitiveWordFilter {
boolean doFilter(Content content);
}
public class SexyWordFilter implements SensitiveWordFilter {
@Override
public boolean doFilter(Content content) {
boolean legal = true;
//...
return legal;
}
}
// PoliticalWordFilter、AdsWordFilter类代码结构与SexyWordFilter类似
public class SensitiveWordFilterChain {
private List<SensitiveWordFilter> filters = new ArrayList<>();
public void addFilter(SensitiveWordFilter filter) {
this.filters.add(filter);
}
// return true if content doesn't contain sensitive words.
public boolean filter(Content content) {
for (SensitiveWordFilter filter : filters) {
if (!filter.doFilter(content)) {
return false;
}
}
return true;
}
}
public class ApplicationDemo {
public static void main(String[] args) {
SensitiveWordFilterChain filterChain = new SensitiveWordFilterChain();
filterChain.addFilter(new AdsWordFilter());
filterChain.addFilter(new SexyWordFilter());
filterChain.addFilter(new PoliticalWordFilter());
boolean legal = filterChain.filter(new Content());
if (!legal) {
// 不发表
} else {
// 发表
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
像下面这样也可以实现敏感词过滤功能,而且代码更加简单,为什么非要使用职责链模式呢?这是不是过度设计呢?
public class SensitiveWordFilter {
// return true if content doesn't contain sensitive words.
public boolean filter(Content content) {
if (!filterSexyWord(content)) {
return false;
}
if (!filterAdsWord(content)) {
return false;
}
if (!filterPoliticalWord(content)) {
return false;
}
return true;
}
private boolean filterSexyWord(Content content) {
//....
}
private boolean filterAdsWord(Content content) {
//...
}
private boolean filterPoliticalWord(Content content) {
//...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
应用设计模式主要是为了应对代码的复杂性,让其满足开闭原则,提高代码的扩展性。这里应用职责链模式也不例外。
职责链模式如何应对代码的复杂性。将大块代码逻辑拆分成函数,将大类拆分成小类,是应对代码复杂性的常用方法。应用职责链模式,把各个敏感词过滤函数继续拆分出来,设计成独立的类,进一步简化了 SensitiveWordFilter 类,让 SensitiveWordFilter 类的代码不会过多,过复杂。
职责链模式让代码满足开闭原则,提高代码的扩展性。当要扩展新的过滤算法的时候,比如还需要过滤特殊符号,按照非职责链模式的代码实现方式,需要修改 SensitiveWordFilter 的代码,违反开闭原则。不过,这样的修改还算比较集中,也是可以接受的。而职责链模式的实现方式更加优雅,只需要新添加一个 Filter 类,并且通过 addFilter() 函数将它添加到 FilterChain 中即可,其他代码完全不需要修改。
假设敏感词过滤框架是引入的一个第三方框架,要扩展一个新的过滤算法,不可能直接去修改框架的源码。这个时候,利用职责链模式就能达到开篇所说的,在不修改框架源码的情况下,基于职责链模式提供的扩展点,来扩展新的功能。换句话说在框架这个代码范围内实现了开闭原则。
除此之外,利用职责链模式相对于不用职责链的实现方式,还有一个好处,那就是配置过滤算法更加灵活,可以只选择使用某几个过滤算法。
# 4.3 框架中常用的过滤器、拦截器原理
职责链模式最常用来开发框架的过滤器和拦截器。通过 Servlet Filter、Spring Interceptor 这两个 Java 开发中常用的组件,来具体理解在框架开发中的应用。
# 4.3.1 Servlet Filter
Servlet Filter 是 Java Servlet 规范中定义的组件,翻译成中文就是过滤器,它可以实现对 HTTP 请求的过滤功能,比如鉴权、限流、记录日志、验证参数等等。因为它是 Servlet 规范的一部分,所以只要是支持 Servlet 的 Web 容器(比如,Tomcat、Jetty 等),都支持过滤器功能。
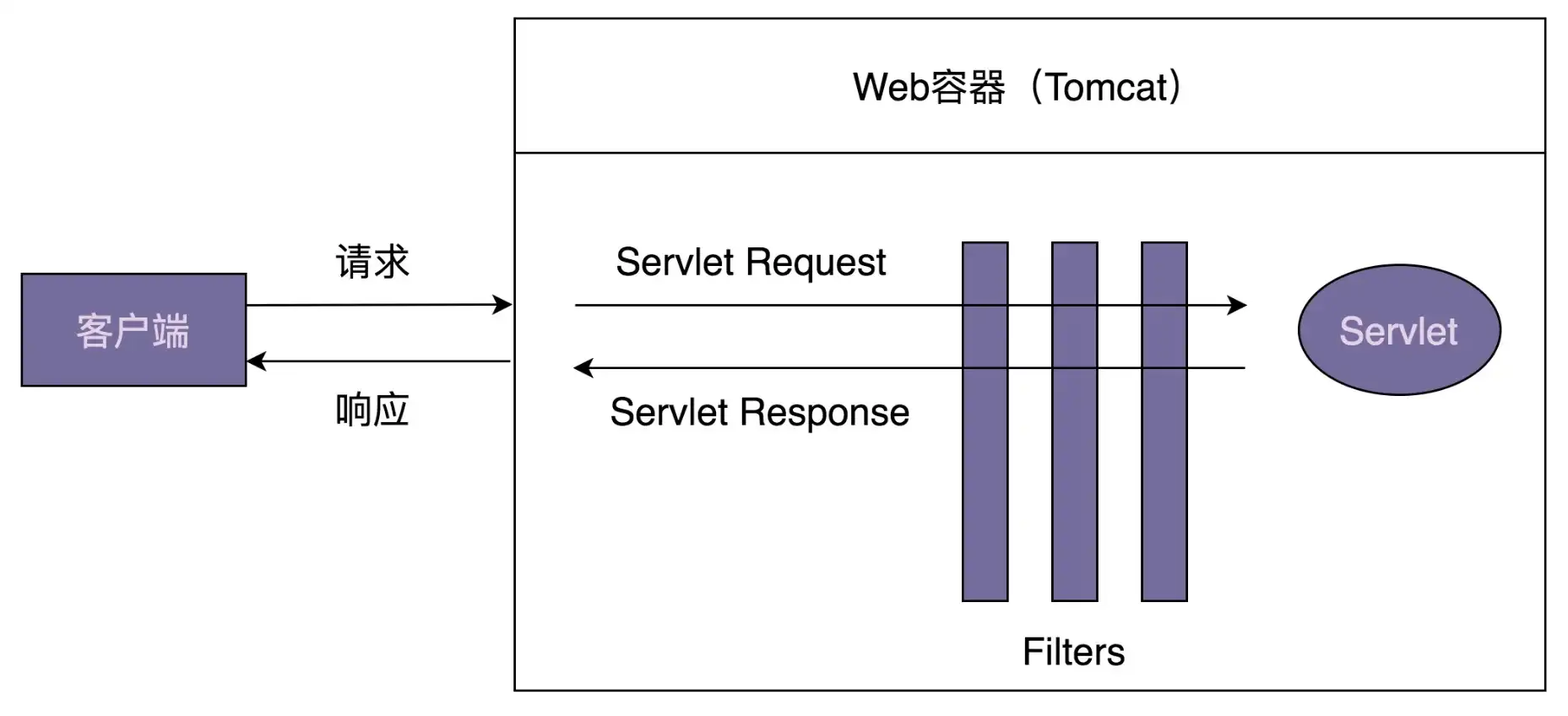
使用 Servlet Filter,添加一个过滤器只需要定义一个实现 javax.servlet.Filter 接口的过滤器类,并且将它配置在 web.xml 配置文件中。Web 容器启动的时候,会读取 web.xml 中的配置,创建过滤器对象。当有请求到来的时候,会先经过过滤器,然后才由 Servlet 来处理。
public class LogFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 在创建Filter时自动调用,
// 其中filterConfig包含这个Filter的配置参数,比如name之类的(从配置文件中读取的)
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response);
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void destroy() {
// 在销毁Filter时自动调用
}
}
// 在web.xml配置文件中如下配置:
<filter>
<filter-name>logFilter</filter-name>
<filter-class>com.xzg.cd.LogFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>logFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
由于 Servlet Filter 使用职责链模式,添加过滤器非常方便,不需要修改任何代码,定义一个实现 javax.servlet.Filter 的类,再改改配置就搞定了,完全符合开闭原则。
职责链模式的实现包含处理器接口(IHandler)或抽象类(Handler),以及处理器链(HandlerChain)。对应到 Servlet Filter,javax.servlet.Filter 就是处理器接口,FilterChain 就是处理器链。
Servlet 只是一个规范,并不包含具体的实现,所以,Servlet 中的 FilterChain 只是一个接口定义。具体的实现类由遵从 Servlet 规范的 Web 容器来提供,比如,ApplicationFilterChain 类就是 Tomcat 提供的 FilterChain 的实现类,源码如下所示(只是代码片段):
public final class ApplicationFilterChain implements FilterChain {
private int pos = 0; //当前执行到了哪个filter
private int n; //filter的个数
private ApplicationFilterConfig[] filters;
private Servlet servlet;
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
public void addFilter(ApplicationFilterConfig filterConfig) {
for (ApplicationFilterConfig filter:filters)
if (filter==filterConfig)
return;
if (n == filters.length) {//扩容
ApplicationFilterConfig[] newFilters = new ApplicationFilterConfig[n + INCREMENT];
System.arraycopy(filters, 0, newFilters, 0, n);
filters = newFilters;
}
filters[n++] = filterConfig;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
ApplicationFilterChain 中的 doFilter() 函数的代码实现比较有技巧,实际上是一个递归调用。可以用每个 Filter(比如 LogFilter)的 doFilter() 的代码实现,直接替换 ApplicationFilterChain 的第 12 行代码,一眼就能看出是递归调用了。
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
//filter.doFilter(request, response, this);
//把filter.doFilter的代码实现展开替换到这里
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response); // chain就是this
System.out.println("拦截发送给客户端的响应.")
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
这样实现主要是为了在一个 doFilter() 方法中,支持双向拦截,既能拦截客户端发送来的请求,也能拦截发送给客户端的响应。
# 4.3.2 Spring Interceptor
Spring Interceptor,翻译成中文就是拦截器。尽管英文单词和中文翻译都不同,但这两者基本上可以看作一个概念,都用来实现对 HTTP 请求进行拦截处理。
它们不同之处在于,Servlet Filter 是 Servlet 规范的一部分,实现依赖于 Web 容器。Spring Interceptor 是 Spring MVC 框架的一部分,由 Spring MVC 框架来提供实现。客户端发送的请求,会先经过 Servlet Filter,然后再经过 Spring Interceptor,最后到达具体的业务代码中。如下所示:
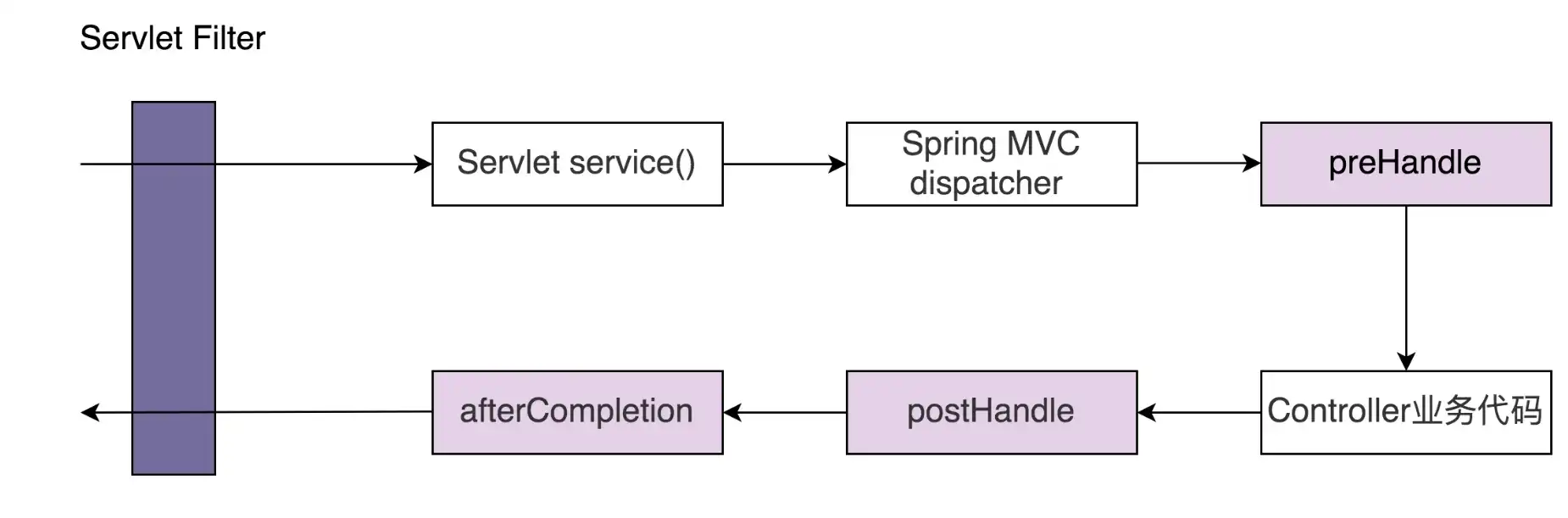
在项目中使用 Spring Interceptor 例子如下。LogInterceptor 实现的功能跟刚才的 LogFilter 完全相同,只是实现方式上稍有区别。LogFilter 对请求和响应的拦截是在 doFilter() 一个函数中实现的,而 LogInterceptor 对请求的拦截在 preHandle() 中实现,对响应的拦截在 postHandle() 中实现。
public class LogInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截客户端发送来的请求.");
return true; // 继续后续的处理
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("这里总是被执行.");
}
}
//在Spring MVC配置文件中配置interceptors
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/*"/>
<bean class="com.xzg.cd.LogInterceptor" />
</mvc:interceptor>
</mvc:interceptors>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Spring Interceptor 也是基于职责链模式实现的。其中,HandlerExecutionChain 类是职责链模式中的处理器链。它的实现相较于 Tomcat 中的 ApplicationFilterChain 来说,逻辑更加清晰,不需要使用递归来实现,主要是因为它将请求和响应的拦截工作,拆分到了两个函数中实现。HandlerExecutionChain 的源码如下所示(只保留了关键代码)。
public class HandlerExecutionChain {
private final Object handler;
private HandlerInterceptor[] interceptors;
public void addInterceptor(HandlerInterceptor interceptor) {
initInterceptorList().add(interceptor);
}
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = 0; i < interceptors.length; i++) {
HandlerInterceptor interceptor = interceptors[i];
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
}
}
return true;
}
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, ModelAndView mv) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = interceptors.length - 1; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
interceptor.postHandle(request, response, this.handler, mv);
}
}
}
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, Exception ex)
throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
try {
interceptor.afterCompletion(request, response, this.handler, ex);
} catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
在 Spring 框架中,DispatcherServlet 的 doDispatch() 方法来分发请求,它在真正的业务逻辑执行前后,执行 HandlerExecutionChain 中的 applyPreHandle() 和 applyPostHandle() 函数,用来实现拦截的功能。
# 4.4 Servlet Filter、Spring Interceptor、Spring AOP
Servlet Filter、Spring Interceptor、Spring AOP 都可以用来实现访问控制,比如鉴权、限流、日志等。那在项目开发中,类似权限这样的访问控制功能,应该选择三者中的哪个来实现呢?有什么参考标准吗?
三者应用范围不同: Servlet Filter 作用于容器,应用范围影响最大;Spring Interceptor 作用于框架,范围影响适中;Spring AOP 作用于业务逻辑,精细化处理,范围影响最小。
例如:
- Servlet Filter:运维部门需要对只供内部访问的服务进行 IP 限制或访问审查时,在容器这一层增加一个 Filter,在发布时发布系统自动加挂这个 Filter,这样对上层应用就是透明的,内网 IP 地址段增减或审查规则调整都不需要上层应用的开发人员去关心。
- Spring Interceptor:由框架或基础服务部门来提供的微服务间相互调用的授权检查时,可以提供统一的 SDK,由程序员在需要的服务上配置。
- Spring AOP: 业务应用内权限检查,可以把权限检查在统一模块中实现,通过配置由 AOP 加插拦截检查。
# 5. 状态模式
状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。不过,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法。
# 5.1 有限状态机
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有 3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
在“超级马里奥”游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加 100 积分。
实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)。
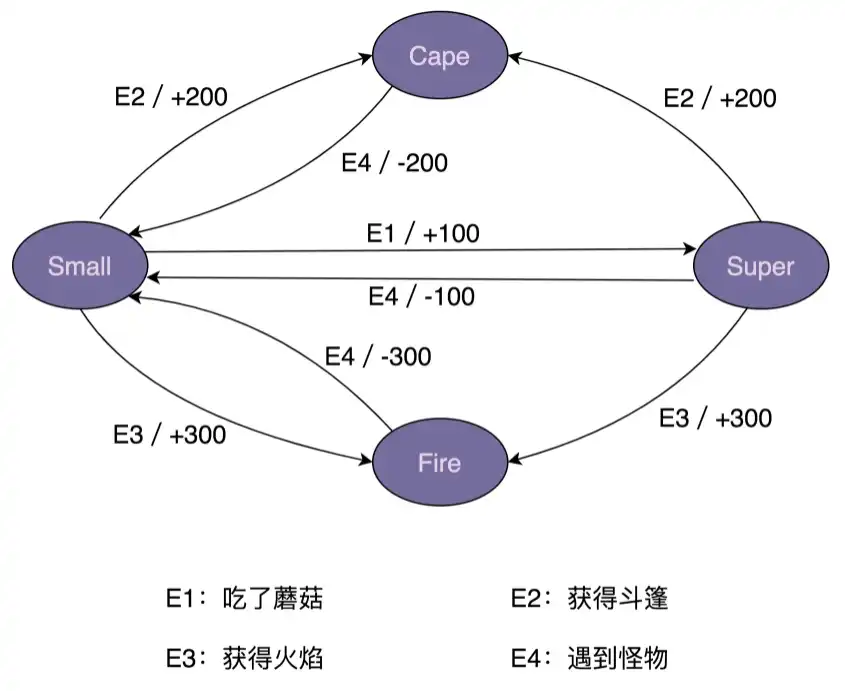
骨架代码如下:
public enum State {
SMALL(0),
SUPER(1),
FIRE(2),
CAPE(3);
private int value;
private State(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
//TODO
}
public void obtainCape() {
//TODO
}
public void obtainFireFlower() {
//TODO
}
public void meetMonster() {
//TODO
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
public class ApplicationDemo {
public static void main(String[] args) {
MarioStateMachine mario = new MarioStateMachine();
mario.obtainMushRoom();
int score = mario.getScore();
State state = mario.getCurrentState();
System.out.println("mario score: " + score + "; state: " + state);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# 5.2 状态机实现方法一:分支逻辑法
最简单直接的实现方式是参照状态转移图,将每一个状态转移,原模原样地直译成代码。这样编写的代码会包含大量的 if-else 或 switch-case 分支判断逻辑,甚至是嵌套的分支判断逻辑,所以把这种方法暂且命名为分支逻辑法。
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
if (currentState.equals(State.SMALL)) {
this.currentState = State.SUPER;
this.score += 100;
}
}
public void obtainCape() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.CAPE;
this.score += 200;
}
}
public void obtainFireFlower() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.FIRE;
this.score += 300;
}
}
public void meetMonster() {
if (currentState.equals(State.SUPER)) {
this.currentState = State.SMALL;
this.score -= 100;
return;
}
if (currentState.equals(State.CAPE)) {
this.currentState = State.SMALL;
this.score -= 200;
return;
}
if (currentState.equals(State.FIRE)) {
this.currentState = State.SMALL;
this.score -= 300;
return;
}
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
对于简单的状态机来说,分支逻辑这种实现方式是可以接受的。但是,对于复杂的状态机来说,这种实现方式极易漏写或者错写某个状态转移。除此之外,代码中充斥着大量的 if-else 或者 switch-case 分支判断逻辑,可读性和可维护性都很差。如果哪天修改了状态机中的某个状态转移,要在冗长的分支逻辑中找到对应的代码进行修改,很容易改错,引入 bug。
# 5.3 状态机实现方法二:查表法
实际上方法一实现方法有点类似 hard code,对于复杂的状态机来说不适用,而状态机的第二种实现方式查表法,就更加合适了。可以利用查表法来补全骨架代码,除了用状态转移图来表示之外,状态机还可以用二维表来表示,如下所示。在这个二维表中,第一维表示当前状态,第二维表示事件,值表示当前状态经过事件之后,转移到的新状态及其执行的动作。

相对于分支逻辑的实现方式,查表法的代码实现更加清晰,可读性和可维护性更好。当修改状态机时只需要修改 transitionTable 和 actionTable 两个二维数组即可。如果把这两个二维数组存储在配置文件中,当需要修改状态机时,甚至可以不修改任何代码,只需要修改配置文件就可以了。具体的代码如下所示:
public enum Event {
GOT_MUSHROOM(0),
GOT_CAPE(1),
GOT_FIRE(2),
MET_MONSTER(3);
private int value;
private Event(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
private static final State[][] transitionTable = {
{SUPER, CAPE, FIRE, SMALL},
{SUPER, CAPE, FIRE, SMALL},
{CAPE, CAPE, CAPE, SMALL},
{FIRE, FIRE, FIRE, SMALL}
};
private static final int[][] actionTable = {
{+100, +200, +300, +0},
{+0, +200, +300, -100},
{+0, +0, +0, -200},
{+0, +0, +0, -300}
};
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
executeEvent(Event.GOT_MUSHROOM);
}
public void obtainCape() {
executeEvent(Event.GOT_CAPE);
}
public void obtainFireFlower() {
executeEvent(Event.GOT_FIRE);
}
public void meetMonster() {
executeEvent(Event.MET_MONSTER);
}
private void executeEvent(Event event) {
int stateValue = currentState.getValue();
int eventValue = event.getValue();
this.currentState = transitionTable[stateValue][eventValue];
this.score += actionTable[stateValue][eventValue];
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 5.4 状态机实现方法三:状态模式
在查表法的代码实现中,事件触发的动作只是简单的积分加减,所以用一个 int 类型的二维数组 actionTable 就能表示,二维数组中的值表示积分的加减值。但如果要执行的动作并非这么简单,而是一系列复杂的逻辑操作(比如加减积分、写数据库,还有可能发送消息通知等等),就没法用如此简单的二维数组来表示了。这也就是说,查表法的实现方式有一定局限性。
虽然分支逻辑的实现方式不存在这个问题,但分支判断逻辑较多,导致代码可读性和可维护性不好等。针对分支逻辑法存在的问题可以使用状态模式来解决。状态模式通过将事件触发的状态转移和动作执行,拆分到不同的状态类中,来避免分支判断逻辑。
利用状态模式实现如下,IMario 是状态的接口,定义了所有的事件。SmallMario、SuperMario、CapeMario、FireMario 是 IMario 接口的实现类,分别对应状态机中的 4 个状态。原来所有的状态转移和动作执行的代码逻辑,都集中在 MarioStateMachine 类中,这些代码逻辑被分散到了这 4 个状态类中。
public interface IMario { //所有状态类的接口
State getName();
//以下是定义的事件
void obtainMushRoom();
void obtainCape();
void obtainFireFlower();
void meetMonster();
}
public class SmallMario implements IMario {
private MarioStateMachine stateMachine;
public SmallMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom() {
stateMachine.setCurrentState(new SuperMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
// do nothing...
}
}
public class SuperMario implements IMario {
private MarioStateMachine stateMachine;
public SuperMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SUPER;
}
@Override
public void obtainMushRoom() {
// do nothing...
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
stateMachine.setCurrentState(new SmallMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() - 100);
}
}
// 省略CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState; // 不再使用枚举来表示状态
public MarioStateMachine() {
this.score = 0;
this.currentState = new SmallMario(this);
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom();
}
public void obtainCape() {
this.currentState.obtainCape();
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower();
}
public void meetMonster() {
this.currentState.meetMonster();
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
MarioStateMachine 和各个状态类之间是双向依赖关系。MarioStateMachine 依赖各个状态类,各个状态类也依赖 MarioStateMachine。因为各个状态类需要更新 MarioStateMachine 中的两个变量,score 和 currentState。
上面的代码还可以继续优化,可以将状态类设计成单例,毕竟状态类中不包含任何成员变量。但当将状态类设计成单例之后,就无法通过构造函数来传递 MarioStateMachine 了,而状态类又要依赖 MarioStateMachine,可以通过函数参数将 MarioStateMachine 传递进状态类。
public interface IMario {
State getName();
void obtainMushRoom(MarioStateMachine stateMachine);
void obtainCape(MarioStateMachine stateMachine);
void obtainFireFlower(MarioStateMachine stateMachine);
void meetMonster(MarioStateMachine stateMachine);
}
public class SmallMario implements IMario {
private static final SmallMario instance = new SmallMario();
private SmallMario() {}
public static SmallMario getInstance() {
return instance;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(SuperMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(CapeMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(FireMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster(MarioStateMachine stateMachine) {
// do nothing...
}
}
// 省略SuperMario、CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = SmallMario.getInstance();
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom(this);
}
public void obtainCape() {
this.currentState.obtainCape(this);
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower(this);
}
public void meetMonster() {
this.currentState.meetMonster(this);
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
实际上,像游戏这种比较复杂的状态机包含的状态比较多,优先推荐使用查表法,而状态模式会引入非常多的状态类,会导致代码比较难维护。像电商下单、外卖下单这种类型的状态机,它们的状态并不多,状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能会比较复杂,所以,更加推荐使用状态模式来实现。
# 6. 迭代器模式
# 6.1 迭代器模式原理
迭代器模式主要作用是解耦容器代码和遍历代码。
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern)。它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。
假设某个新的编程语言的基础类库中,还没有提供线性容器对应的迭代器,需要从零开始开发。线性数据结构包括数组和链表,在大部分编程语言中都有对应的类来封装这两种数据结构,在开发中直接拿来用就可以了。假设在这种新的编程语言中,这两个数据结构分别对应 ArrayList 和 LinkedList 两个类。除此之外从两个类中抽象出公共的接口,定义为 List 接口,以方便开发者基于接口而非实现编程,编写的代码能在两种数据存储结构之间灵活切换。
现在针对 ArrayList 和 LinkedList 两个线性容器,设计实现对应的迭代器。按照之前给出的迭代器模式的类图,定义一个迭代器接口 Iterator,以及针对两种容器的具体的迭代器实现类 ArrayIterator 和 ListIterator。
// 接口定义方式一
public interface Iterator<E> {
boolean hasNext();
void next();
E currentItem();
}
// 接口定义方式二
public interface Iterator<E> {
boolean hasNext();
E next();
}
2
3
4
5
6
7
8
9
10
11
12
Iterator 接口有两种定义方式。在第一种定义中,next() 函数用来将游标后移一位元素,currentItem() 函数用来返回当前游标指向的元素。在第二种定义中,返回当前元素与后移一位这两个操作,要放到同一个函数 next() 中完成。第一种定义方式更加灵活一些,比如可以多次调用 currentItem() 查询当前元素,而不移动游标。
ArrayIterator 的代码实现,具体如下所示:
public class ArrayIterator<E> implements Iterator<E> {
private int cursor;
private ArrayList<E> arrayList;
public ArrayIterator(ArrayList<E> arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor != arrayList.size(); //注意这里,cursor在指向最后一个元素的时候,hasNext()仍旧返回true。
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if (cursor >= arrayList.size()) {
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public class Demo {
public static void main(String[] args) {
ArrayList<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator<String> iterator = new ArrayIterator(names);
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
在上面的代码实现中需要将待遍历的容器对象,通过构造函数传递给迭代器类。实际上,为了封装迭代器的创建细节,可以在容器中定义一个 iterator() 方法,来创建对应的迭代器。为了能实现基于接口而非实现编程,还需要将这个方法定义在 List 接口中。具体的代码实现和使用示例如下所示:
public interface List<E> {
Iterator iterator();
//...省略其他接口函数...
}
public class ArrayList<E> implements List<E> {
//...
public Iterator iterator() {
return new ArrayIterator(this);
}
//...省略其他代码
}
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
总结一下迭代器的设计思路:迭代器中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。待遍历的容器对象通过依赖注入传递到迭代器类中。容器通过 iterator() 方法来创建迭代器。
# 6.2 迭代器模式的优势
一般来讲,遍历集合数据有三种方法:for 循环、foreach 循环、iterator 迭代器。
List<String> names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
// 第一种遍历方式:for循环
for (int i = 0; i < names.size(); i++) {
System.out.print(names.get(i) + ",");
}
// 第二种遍历方式:foreach循环
for (String name : names) {
System.out.print(name + ",")
}
// 第三种遍历方式:迭代器遍历
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");//Java中的迭代器接口是第二种定义方式,next()既移动游标又返回数据
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
实际上,foreach 循环只是一个语法糖,底层是基于迭代器来实现的。也就是说第二和第三这两种遍历方式可以看作同一种遍历方式,也就是迭代器遍历方式。
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用 for 循环来遍历就足够了。但对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
应对复杂性的方法就是拆分。可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,就可以定义 DFSIterator、BFSIterator 两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便在开发的时候基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从 LinkedIterator 切换为 ReversedLinkedIterator 即可,其他代码都不需要修改。除此之外,添加新的遍历算法,只需要扩展新的迭代器类,也更符合开闭原则。
总结一下,相对于 for 循环遍历,利用迭代器来遍历有下面三个优势:
- 迭代器模式封装集合内部的复杂数据结构,开发者不需要了解如何遍历,直接使用容器提供的迭代器即可;
- 迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一;
- 迭代器模式让添加新的遍历算法更加容易,更符合开闭原则。除此之外,因为迭代器都实现自相同的接口,在开发中,基于接口而非实现编程,替换迭代器也变得更加容易。
# 6.3 遍历集合的同时为什么不能增删集合元素
# 6.3.1 在遍历的同时增删集合元素会发生什么?
在通过迭代器来遍历集合元素的同时,增加或者删除集合中的元素,有可能会导致某个元素被重复遍历或遍历不到。不过,并不是所有情况下都会遍历出错,有的时候也可以正常遍历,所以,这种行为称为结果不可预期行为或者未决行为,也就是说,运行结果到底是对还是错,要视情况而定。
public interface Iterator<E> {
boolean hasNext();
void next();
E currentItem();
}
public class ArrayIterator<E> implements Iterator<E> {
private int cursor;
private ArrayList<E> arrayList;
public ArrayIterator(ArrayList<E> arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor < arrayList.size();
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if (cursor >= arrayList.size()) {
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public interface List<E> {
Iterator iterator();
}
public class ArrayList<E> implements List<E> {
//...
public Iterator iterator() {
return new ArrayIterator(this);
}
//...
}
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator<String> iterator = names.iterator();
iterator.next();
names.remove("a");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
ArrayList 底层对应的是数组这种数据结构,在执行完第 55 行代码的时候,数组中存储的是 a、b、c、d 四个元素,迭代器的游标 cursor 指向元素 a。当执行完第 56 行代码的时候,游标指向元素 b,到这里都没有问题。
为了保持数组存储数据的连续性,数组的删除操作会涉及元素的搬移。当执行到第 57 行代码的时候,从数组中将元素 a 删除掉,b、c、d 三个元素会依次往前搬移一位,这就会导致游标本来指向元素 b,现在变成了指向元素 c。原本在执行完第 56 行代码之后,还可以遍历到 b、c、d 三个元素,但在执行完第 57 行代码之后,只能遍历到 c、d 两个元素,b 遍历不到了。
如果第 57 行代码删除的不是游标前面的元素(元素 a)以及游标所在位置的元素(元素 b),而是游标后面的元素(元素 c 和 d),这样就不会存在任何问题了,不会存在某个元素遍历不到的情况了。
所以,在遍历的过程中删除集合元素,结果是不可预期的,有时候没问题(删除元素 c 或 d),有时候就有问题(删除元素 a 或 b),这个要视情况而定(到底删除的是哪个位置的元素),就是这个意思。
在遍历的过程中删除集合元素,有可能会导致某个元素遍历不到,那在遍历的过程中添加集合元素,会发生什么情况呢?
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator<String> iterator = names.iterator();
iterator.next();
names.add(0, "x");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
在执行完第 10 行代码之后,数组中包含 a、b、c、d 四个元素,游标指向 b 这个元素,已经跳过了元素 a。在执行完第 11 行代码之后,我们将 x 插入到下标为 0 的位置,a、b、c、d 四个元素依次往后移动一位。这个时候,游标又重新指向了元素 a。元素 a 被游标重复指向两次,也就是说,元素 a 存在被重复遍历的情况。跟删除情况类似,如果我们在游标的后面添加元素,就不会存在任何问题。所以,在遍历的同时添加集合元素也是一种不可预期行为。
# 6.3.2 如何应对遍历时改变集合导致的未决行为
当通过迭代器来遍历集合的时候,增加、删除集合元素会导致不可预期的遍历结果。有两种比较干脆利索的解决方案:一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错。第一种在实际中很难实现,Java 语言就是采用的是增删元素之后,让遍历报错。
在 ArrayList 中定义一个成员变量 modCount,记录集合被修改的次数,集合每调用一次增加或删除元素的函数,就会给 modCount 加 1。当通过调用集合上的 iterator() 函数来创建迭代器的时候,把 modCount 值传递给迭代器的 expectedModCount 成员变量,之后每次调用迭代器上的 hasNext()、next()、currentItem() 函数,都会检查集合上的 modCount 是否等于 expectedModCount,也就是看,在创建完迭代器之后,modCount 是否改变过。
如果两个值不相同,那就说明集合存储的元素已经改变了,要么增加了元素,要么删除了元素,之前创建的迭代器已经不能正确运行了,再继续使用就会产生不可预期的结果,所以选择 fail-fast 解决方式,抛出运行时异常,结束掉程序,让程序员尽快修复这个因为不正确使用迭代器而产生的 bug。
public class ArrayIterator implements Iterator {
private int cursor;
private ArrayList arrayList;
private int expectedModCount;
public ArrayIterator(ArrayList arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
this.expectedModCount = arrayList.modCount;
}
@Override
public boolean hasNext() {
checkForComodification();
return cursor < arrayList.size();
}
@Override
public void next() {
checkForComodification();
cursor++;
}
@Override
public Object currentItem() {
checkForComodification();
return arrayList.get(cursor);
}
private void checkForComodification() {
if (arrayList.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
//代码示例
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator<String> iterator = names.iterator();
iterator.next();
names.remove("a");
iterator.next();//抛出ConcurrentModificationException异常
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 6.3.3 如何在遍历的同事安全删除集合元素
在 Java 语言的迭代器类中还定义了一个 remove() 方法,能够在遍历集合的同时,安全地删除集合中的元素。不过,需要说明的是,它并没有提供添加元素的方法。毕竟迭代器的主要作用是遍历,添加元素放到迭代器里本身就不合适。
Java 迭代器中提供的 remove() 方法还是比较鸡肋的,作用有限。它只能删除游标指向的前一个元素,而且一个 next() 函数之后,只能跟着最多一个 remove() 操作,多次调用 remove() 操作会报错。
public class Demo {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator<String> iterator = names.iterator();
iterator.next();
iterator.remove();
iterator.remove(); //报错,抛出IllegalStateException异常
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在 Java 实现中,迭代器类是容器类的内部类,并且 next() 函数不仅将游标后移一位,还会返回当前的元素。迭代器的 remove() 函数源码如下:
public class ArrayList<E> {
transient Object[] elementData;
private int size;
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
在上面的代码实现中,迭代器类新增了一个 lastRet 成员变量,用来记录游标指向的前一个元素。通过迭代器去删除这个元素的时候,可以更新迭代器中的游标和 lastRet 值,来保证不会因为删除元素而导致某个元素遍历不到。如果通过容器来删除元素,并且希望更新迭代器中的游标值来保证遍历不出错,就要维护这个容器都创建了哪些迭代器,每个迭代器是否还在使用等信息,代码实现就变得比较复杂了。
# 6.4 设计实现一个支持“快照”功能的 Iterator
问题描述
所谓“快照”,指为容器创建迭代器的时候,相当于给容器拍了一张快照(Snapshot)。之后即便增删容器中的元素,快照中的元素并不会做相应的改动。而迭代器遍历的对象是快照而非容器,这样就避免了在使用迭代器遍历的过程中,增删容器中的元素,导致的不可预期的结果或者报错。
例如下面代码,容器 list 中初始存储了 3、8、2 三个元素。尽管在创建迭代器 iter1 之后,容器 list 删除了元素 3,只剩下 8、2 两个元素,但是,通过 iter1 遍历的对象是快照,而非容器 list 本身。所以,遍历的结果仍然是 3、8、2。同理,iter2、iter3 也是在各自的快照上遍历,输出的结果如代码中注释所示。
List<Integer> list = new ArrayList<>(); list.add(3); list.add(8); list.add(2); Iterator<Integer> iter1 = list.iterator();//snapshot: 3, 8, 2 list.remove(new Integer(2));//list:3, 8 Iterator<Integer> iter2 = list.iterator();//snapshot: 3, 8 list.remove(new Integer(3));//list:8 Iterator<Integer> iter3 = list.iterator();//snapshot: 3 // 输出结果:3 8 2 while (iter1.hasNext()) { System.out.print(iter1.next() + " "); } System.out.println(); // 输出结果:3 8 while (iter2.hasNext()) { System.out.print(iter1.next() + " "); } System.out.println(); // 输出结果:8 while (iter3.hasNext()) { System.out.print(iter1.next() + " "); } System.out.println();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28针对这个功能需求的骨架代码,其中包含 ArrayList、SnapshotArrayIterator 两个类。
public ArrayList<E> implements List<E> { // TODO: 成员变量、私有函数等随便你定义 @Override public void add(E obj) { //TODO: 由你来完善 } @Override public void remove(E obj) { // TODO: 由你来完善 } @Override public Iterator<E> iterator() { return new SnapshotArrayIterator(this); } } public class SnapshotArrayIterator<E> implements Iterator<E> { // TODO: 成员变量、私有函数等随便你定义 @Override public boolean hasNext() { // TODO: 由你来完善 } @Override public E next() {//返回当前元素,并且游标后移一位 // TODO: 由你来完善 } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32解决方案一
在迭代器类中定义一个成员变量 snapshot 来存储快照。每当创建迭代器的时候,都拷贝一份容器中的元素到快照中,后续的遍历操作都基于这个迭代器自己持有的快照来进行。具体的代码实现如下所示:
public class SnapshotArrayIterator<E> implements Iterator<E> { private int cursor; private ArrayList<E> snapshot; public SnapshotArrayIterator(ArrayList<E> arrayList) { this.cursor = 0; this.snapshot = new ArrayList<>(); this.snapshot.addAll(arrayList); } @Override public boolean hasNext() { return cursor < snapshot.size(); } @Override public E next() { E currentItem = snapshot.get(cursor); cursor++; return currentItem; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22这个解决方案虽然简单,但代价也有点高。每次创建迭代器的时候,都要拷贝一份数据到快照中,会增加内存的消耗。如果一个容器同时有多个迭代器在遍历元素,就会导致数据在内存中重复存储多份。不过,庆幸的是,Java 中的拷贝属于浅拷贝,也就是说,容器中的对象并非真的拷贝了多份,而只是拷贝了对象的引用而已。
解决方案二
可以在容器中,为每个元素保存两个时间戳,一个是添加时间戳 addTimestamp,一个是删除时间戳 delTimestamp。当元素被加入到集合中的时候,我们将 addTimestamp 设置为当前时间,将 delTimestamp 设置成最大长整型值(Long.MAX_VALUE)。当元素被删除时,将 delTimestamp 更新为当前时间,表示已经被删除。这里只是标记删除,而非真正将它从容器中删除。
同时,每个迭代器也保存一个迭代器创建时间戳 snapshotTimestamp,也就是迭代器对应的快照的创建时间戳。当使用迭代器来遍历容器的时候,只有满足 addTimestamp<snapshotTimestamp<delTimestamp 的元素,才是属于这个迭代器的快照。
如果元素的 addTimestamp>snapshotTimestamp,说明元素在创建了迭代器之后才加入的,不属于这个迭代器的快照;如果元素的 delTimestamp<snapshotTimestamp,说明元素在创建迭代器之前就被删除掉了,也不属于这个迭代器的快照。
这样就在不拷贝容器的情况下,在容器本身上借助时间戳实现了快照功能。具体的代码实现如下所示。
public class ArrayList<E> implements List<E> { private static final int DEFAULT_CAPACITY = 10; private int actualSize; //不包含标记删除元素 private int totalSize; //包含标记删除元素 private Object[] elements; private long[] addTimestamps; private long[] delTimestamps; public ArrayList() { this.elements = new Object[DEFAULT_CAPACITY]; this.addTimestamps = new long[DEFAULT_CAPACITY]; this.delTimestamps = new long[DEFAULT_CAPACITY]; this.totalSize = 0; this.actualSize = 0; } @Override public void add(E obj) { elements[totalSize] = obj; addTimestamps[totalSize] = System.currentTimeMillis(); delTimestamps[totalSize] = Long.MAX_VALUE; totalSize++; actualSize++; } @Override public void remove(E obj) { for (int i = 0; i < totalSize; ++i) { if (elements[i].equals(obj)) { delTimestamps[i] = System.currentTimeMillis(); actualSize--; } } } public int actualSize() { return this.actualSize; } public int totalSize() { return this.totalSize; } public E get(int i) { if (i >= totalSize) { throw new IndexOutOfBoundsException(); } return (E)elements[i]; } public long getAddTimestamp(int i) { if (i >= totalSize) { throw new IndexOutOfBoundsException(); } return addTimestamps[i]; } public long getDelTimestamp(int i) { if (i >= totalSize) { throw new IndexOutOfBoundsException(); } return delTimestamps[i]; } } public class SnapshotArrayIterator<E> implements Iterator<E> { private long snapshotTimestamp; private int cursorInAll; // 在整个容器中的下标,而非快照中的下标 private int leftCount; // 快照中还有几个元素未被遍历 private ArrayList<E> arrayList; public SnapshotArrayIterator(ArrayList<E> arrayList) { this.snapshotTimestamp = System.currentTimeMillis(); this.cursorInAll = 0; this.leftCount = arrayList.actualSize();; this.arrayList = arrayList; justNext(); // 先跳到这个迭代器快照的第一个元素 } @Override public boolean hasNext() { return this.leftCount >= 0; // 注意是>=, 而非> } @Override public E next() { E currentItem = arrayList.get(cursorInAll); justNext(); return currentItem; } private void justNext() { while (cursorInAll < arrayList.totalSize()) { long addTimestamp = arrayList.getAddTimestamp(cursorInAll); long delTimestamp = arrayList.getDelTimestamp(cursorInAll); if (snapshotTimestamp > addTimestamp && snapshotTimestamp < delTimestamp) { leftCount--; break; } cursorInAll++; } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106