 Java 业务开发常见错误(二)
Java 业务开发常见错误(二)
# Java 业务开发常见错误(二)
# 判等问题
# 注意 equals 和 == 的区别
在业务代码中,我们通常使用 equals 或 == 进行判等操作。equals 是方法而 == 是操作符,它们的使用是有区别的:
- 对基本类型,比如 int、long,进行判等,只能使用 ==,比较的是直接值。因为基本类型的值就是其数值。
- 对引用类型,比如 Integer、Long 和 String,进行判等,需要使用 equals 进行内容判等。因为引用类型的直接值是指针,使用 == 的话,比较的是指针,也就是两个对象在内存中的地址,即比较它们是不是同一个对象,而不是比较对象的内容。
比较值,除了基本类型只能使用 == 外,其他类型都需要使用 equals。原理看:自动拆箱和装箱、int 和 Integer 的区别 (opens new window)
案例:有这么一个枚举定义了订单状态和对于状态的描述:
enum StatusEnum {
CREATED(1000, "已创建"),
PAID(1001, "已支付"),
DELIVERED(1002, "已送到"),
FINISHED(1003, "已完成");
private final Integer status; //注意这里的Integer
private final String desc;
StatusEnum(Integer status, String desc) {
this.status = status;
this.desc = desc;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在业务代码中,开发同学使用了 == 对枚举和入参 OrderQuery 中的 status 属性进行判等:
@Data
public class OrderQuery {
private Integer status;
private String name;
}
@PostMapping("enumcompare")
public void enumcompare(@RequestBody OrderQuery orderQuery){
StatusEnum statusEnum = StatusEnum.DELIVERED;
log.info("orderQuery:{} statusEnum:{} result:{}", orderQuery, statusEnum, statusEnum.status == orderQuery.getStatus());
}
2
3
4
5
6
7
8
9
10
11
因为枚举和入参 OrderQuery 中的 status 都是包装类型,所以通过 == 判等肯定是有问题的。只是这个问题比较隐晦,究其原因在于:
- 只看枚举的定义 CREATED(1000, “已创建”),容易让人误解 status 值是基本类型;
- 因为有 Integer 缓存机制的存在,所以使用 == 判等并不是所有情况下都有问题。在这次事故中,订单状态的值从 100 开始增长,程序一开始不出问题,直到订单状态超过 127 后才出现 Bug。
在了解清楚为什么 Integer 使用 == 判等有时候也有效的原因之后,我们再来看看为什么 String 也有这个问题。
Java 的字符串常量池机制。首先要明确的是其设计初衷是节省内存。当代码中出现双引号形式创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。这种机制,就是字符串驻留或池化。虽然使用 new 声明的字符串调用 intern 方法,也可以让字符串进行驻留,但在业务代码中滥用 intern,可能会产生性能问题。
# 实现一个 equals 没有这么简单
如果看过 Object 类源码,你可能就知道,equals 的实现其实是比较对象引用:
public boolean equals(Object obj) {
return (this == obj);
}
2
3
之所以 Integer 或 String 能通过 equals 实现内容判等,是因为它们都重写了这个方法。比如,String 的 equals 的实现:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
对于自定义类型,如果不重写 equals 的话,默认就是使用 Object 基类的按引用的比较方式。我们写一个自定义类测试一下。
假设有这样一个描述点的类 Point,有 x、y 和描述三个属性:
class Point {
private int x;
private int y;
private final String desc;
public Point(int x, int y, String desc) {
this.x = x;
this.y = y;
this.desc = desc;
}
}
2
3
4
5
6
7
8
9
10
11
定义三个点 p1、p2 和 p3,其中 p1 和 p2 的描述属性不同,p1 和 p3 的三个属性完全相同,并写一段代码测试一下默认行为:
Point p1 = new Point(1, 2, "a");
Point p2 = new Point(1, 2, "b");
Point p3 = new Point(1, 2, "a");
log.info("p1.equals(p2) ? {}", p1.equals(p2));
log.info("p1.equals(p3) ? {}", p1.equals(p3));
2
3
4
5
通过 equals 方法比较 p1 和 p2、p1 和 p3 均得到 false,原因正如刚才所说,我们并没有为 Point 类实现自定义的 equals 方法,Object 超类中的 equals 默认使用 == 判等,比较的是对象的引用。
我们期望的逻辑是,只要 x 和 y 这 2 个属性一致就代表是同一个点,所以写出了如下的改进代码,重写 equals 方法,把参数中的 Object 转换为 Point 比较其 x 和 y 属性:
class PointWrong {
private int x;
private int y;
private final String desc;
public PointWrong(int x, int y, String desc) {
this.x = x;
this.y = y;
this.desc = desc;
}
@Override
public boolean equals(Object o) {
PointWrong that = (PointWrong) o;
return x == that.x && y == that.y;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
为测试改进后的 Point 是否可以满足需求,我们定义了三个用例:
- 比较一个 Point 对象和 null;
- 比较一个 Object 对象和一个 Point 对象;
- 比较两个 x 和 y 属性值相同的 Point 对象。
PointWrong p1 = new PointWrong(1, 2, "a");
try {
log.info("p1.equals(null) ? {}", p1.equals(null));
} catch (Exception ex) {
log.error(ex.getMessage());
}
Object o = new Object();
try {
log.info("p1.equals(expression) ? {}", p1.equals(o));
} catch (Exception ex) {
log.error(ex.getMessage());
}
PointWrong p2 = new PointWrong(1, 2, "b");
log.info("p1.equals(p2) ? {}", p1.equals(p2));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
通过日志中的结果可以看到,第一次比较出现了空指针异常,第二次比较出现了类型转换异常,第三次比较符合预期输出了 true。
[17:54:39.120] [http-nio-45678-exec-1] [ERROR] [t.c.e.demo1.EqualityMethodController:32 ] - java.lang.NullPointerException
[17:54:39.120] [http-nio-45678-exec-1] [ERROR] [t.c.e.demo1.EqualityMethodController:39 ] - java.lang.ClassCastException: java.lang.Object cannot be cast to org.geekbang.time.commonmistakes.equals.demo1.EqualityMethodController$PointWrong
[17:54:39.120] [http-nio-45678-exec-1] [INFO ] [t.c.e.demo1.EqualityMethodController:43 ] - p1.equals(p2) ? true
2
3
通过这些失效的用例,我们大概可以总结出实现一个更好的 equals 应该注意的点:
- 考虑到性能,可以先进行指针判等,如果对象是同一个那么直接返回 true;
- 需要对另一方进行判空,空对象和自身进行比较,结果一定是 fasle;
- 需要判断两个对象的类型,如果类型都不同,那么直接返回 false;
- 确保类型相同的情况下再进行类型强制转换,然后逐一判断所有字段。
修复和改进后的 equals 方法如下:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
PointRight that = (PointRight) o;
return x == that.x && y == that.y;
}
2
3
4
5
6
7
改进后的 equals 看起来完美了,但还没完。我们继续往下看。
# hashCode 和 equals 要配对实现
我们来试试下面这个用例,定义两个 x 和 y 属性值完全一致的 Point 对象 p1 和 p2,把 p1 加入 HashSet,然后判断这个 Set 中是否存在 p2:
PointWrong p1 = new PointWrong(1, 2, "a");
PointWrong p2 = new PointWrong(1, 2, "b");
HashSet<PointWrong> points = new HashSet<>();
points.add(p1);
log.info("points.contains(p2) ? {}", points.contains(p2));
2
3
4
5
6
按照改进后的 equals 方法,这 2 个对象可以认为是同一个,Set 中已经存在了 p1 就应该包含 p2,但结果却是 false。
出现这个 Bug 的原因是,散列表需要使用 hashCode 来定位元素放到哪个桶。如果自定义对象没有实现自定义的 hashCode 方法,就会使用 Object 超类的默认实现,得到的两个 hashCode 是不同的,导致无法满足需求。
要自定义 hashCode,我们可以直接使用 Objects.hash 方法来实现,改进后的 Point 类如下:
class PointRight {
private final int x;
private final int y;
private final String desc;
...
@Override
public boolean equals(Object o) {
...
}
@Override
public int hashCode() {
return Objects.hash(x, y);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
改进 equals 和 hashCode 后,再测试下之前的四个用例,结果全部符合预期。
[18:25:23.091] [http-nio-45678-exec-4] [INFO ] [t.c.e.demo1.EqualityMethodController:54 ] - p1.equals(null) ? false
[18:25:23.093] [http-nio-45678-exec-4] [INFO ] [t.c.e.demo1.EqualityMethodController:61 ] - p1.equals(expression) ? false
[18:25:23.094] [http-nio-45678-exec-4] [INFO ] [t.c.e.demo1.EqualityMethodController:67 ] - p1.equals(p2) ? true
[18:25:23.094] [http-nio-45678-exec-4] [INFO ] [t.c.e.demo1.EqualityMethodController:71 ] - points.contains(p2) ? true
2
3
4
# 注意 compareTo 和 equals 的逻辑一致性
除了自定义类型需要确保 equals 和 hashCode 要逻辑一致外,还有一个更容易被忽略的问题,即 compareTo 同样需要和 equals 确保逻辑一致性。
案例:代码里本来使用了 ArrayList 的 indexOf 方法进行元素搜索,但是一位好心的开发同学觉得逐一比较的时间复杂度是 O(n),效率太低了,于是改为了排序后通过 Collections.binarySearch 方法进行搜索,实现了 O(log n) 的时间复杂度。没想到,这么一改却出现了 Bug。
我们来重现下这个问题。首先,定义一个 Student 类,有 id 和 name 两个属性,并实现了一个 Comparable 接口来返回两个 id 的值:
@Data
@AllArgsConstructor
class Student implements Comparable<Student>{
private int id;
private String name;
@Override
public int compareTo(Student other) {
int result = Integer.compare(other.id, id);
if (result==0)
log.info("this {} == other {}", this, other);
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
然后,写一段测试代码分别通过 indexOf 方法和 Collections.binarySearch 方法进行搜索。列表中我们存放了两个学生,第一个学生 id 是 1 叫 zhang,第二个学生 id 是 2 叫 wang,搜索这个列表是否存在一个 id 是 2 叫 li 的学生:
@GetMapping("wrong")
public void wrong(){
List<Student> list = new ArrayList<>();
list.add(new Student(1, "zhang"));
list.add(new Student(2, "wang"));
Student student = new Student(2, "li");
log.info("ArrayList.indexOf");
int index1 = list.indexOf(student);
Collections.sort(list);
log.info("Collections.binarySearch");
int index2 = Collections.binarySearch(list, student);
log.info("index1 = " + index1);
log.info("index2 = " + index2);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
代码输出的日志如下:
[18:46:50.226] [http-nio-45678-exec-1] [INFO ] [t.c.equals.demo2.CompareToController:28 ] - ArrayList.indexOf
[18:46:50.226] [http-nio-45678-exec-1] [INFO ] [t.c.equals.demo2.CompareToController:31 ] - Collections.binarySearch
[18:46:50.227] [http-nio-45678-exec-1] [INFO ] [t.c.equals.demo2.CompareToController:67 ] - this CompareToController.Student(id=2, name=wang) == other CompareToController.Student(id=2, name=li)
[18:46:50.227] [http-nio-45678-exec-1] [INFO ] [t.c.equals.demo2.CompareToController:34 ] - index1 = -1
[18:46:50.227] [http-nio-45678-exec-1] [INFO ] [t.c.equals.demo2.CompareToController:35 ] - index2 = 1
2
3
4
5
我们注意到如下几点:
- binarySearch 方法内部调用了元素的 compareTo 方法进行比较;
- indexOf 的结果没问题,列表中搜索不到 id 为 2、name 是 li 的学生;
- binarySearch 返回了索引 1,代表搜索到的结果是 id 为 2,name 是 wang 的学生。
修复方式很简单,确保 compareTo 的比较逻辑和 equals 的实现一致即可。重新实现一下 Student 类,通过 Comparator.comparing 这个便捷的方法来实现两个字段的比较:
@Data
@AllArgsConstructor
class StudentRight implements Comparable<StudentRight>{
private int id;
private String name;
@Override
public int compareTo(StudentRight other) {
return Comparator.comparing(StudentRight::getName)
.thenComparingInt(StudentRight::getId)
.compare(this, other);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
其实,这个问题容易被忽略的原因在于两方面:
- 一是,我们使用了 Lombok 的 @Data 标记了 Student,@Data 注解(详见这里)其实包含了 @EqualsAndHashCode 注解(详见这里)的作用,也就是默认情况下使用类型所有的字段(不包括 static 和 transient 字段)参与到 equals 和 hashCode 方法的实现中。因为这两个方法的实现不是我们自己实现的,所以容易忽略其逻辑。
- 二是,compareTo 方法需要返回数值,作为排序的依据,容易让人使用数值类型的字段随意实现。
对于自定义的类型,如果要实现 Comparable,请记得 equals、hashCode、compareTo 三者逻辑一致。
# 小心 Lombok 生成代码的“坑”
Lombok 的 @Data 注解会帮我们实现 equals 和 hashcode 方法,但是有继承关系时,Lombok 自动生成的方法可能就不是我们期望的了。
我们先来研究一下其实现:定义一个 Person 类型,包含姓名和身份证两个字段:
@Data
class Person {
private String name;
private String identity;
public Person(String name, String identity) {
this.name = name;
this.identity = identity;
}
}
2
3
4
5
6
7
8
9
10
对于身份证相同、姓名不同的两个 Person 对象:
Person person1 = new Person("zhuye","001");
Person person2 = new Person("Joseph","001");
log.info("person1.equals(person2) ? {}", person1.equals(person2));
2
3
使用 equals 判等会得到 false。如果你希望只要身份证一致就认为是同一个人的话,可以使用 @EqualsAndHashCode.Exclude 注解来修饰 name 字段,从 equals 和 hashCode 的实现中排除 name 字段:
@EqualsAndHashCode.Exclude
private String name;
2
修改后得到 true。打开编译后的代码可以看到,Lombok 为 Person 生成的 equals 方法的实现,确实只包含了 identity 属性:
public boolean equals(final Object o) {
if (o == this) {
return true;
} else if (!(o instanceof LombokEquealsController.Person)) {
return false;
} else {
LombokEquealsController.Person other = (LombokEquealsController.Person)o;
if (!other.canEqual(this)) {
return false;
} else {
Object this$identity = this.getIdentity();
Object other$identity = other.getIdentity();
if (this$identity == null) {
if (other$identity != null) {
return false;
}
} else if (!this$identity.equals(other$identity)) {
return false;
}
return true;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
但到这里还没完,如果类型之间有继承,Lombok 会怎么处理子类的 equals 和 hashCode 呢?我们来测试一下,写一个 Employee 类继承 Person,并新定义一个公司属性:
@Data
class Employee extends Person {
private String company;
public Employee(String name, String identity, String company) {
super(name, identity);
this.company = company;
}
}
2
3
4
5
6
7
8
9
在如下的测试代码中,声明两个 Employee 实例,它们具有相同的公司名称,但姓名和身份证均不同:
Employee employee1 = new Employee("zhuye","001", "bkjk.com");
Employee employee2 = new Employee("Joseph","002", "bkjk.com");
log.info("employee1.equals(employee2) ? {}", employee1.equals(employee2));
2
3
很遗憾,结果是 true,显然是没有考虑父类的属性,而认为这两个员工是同一人,说明 @EqualsAndHashCode 默认实现没有使用父类属性。
为解决这个问题,我们可以手动设置 callSuper 开关为 true,来覆盖这种默认行为:
@Data
@EqualsAndHashCode(callSuper = true)
class Employee extends Person {
2
3
修改后的代码,实现了同时以子类的属性 company 加上父类中的属性 identity,作为 equals 和 hashCode 方法的实现条件(实现上其实是调用了父类的 equals 和 hashCode)。
# 数值计算
# 集合类
# 使用 Arrays.asList 把数据转换为 List 的三个坑
使用 Arrays.asList 方法可以把数组一键转换为 List,但其实没这么简单。接下来,就让我们看看其中的缘由,以及使用 Arrays.asList 把数组转换为 List 的几个坑。
在如下代码中,我们初始化三个数字的 int[]数组,然后使用 Arrays.asList 把数组转换为 List:
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
2
3
但,这样初始化的 List 并不是我们期望的包含 3 个数字的 List。通过日志可以发现,这个 List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。
12:50:39.445 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[[I@1c53fd30] size:1 class:class [I
其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。我们知道,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
2
3
直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
int[] arr1 = {1, 2, 3};
List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList());
log.info("list:{} size:{} class:{}", list1, list1.size(), list1.get(0).getClass());
Integer[] arr2 = {1, 2, 3};
List list2 = Arrays.asList(arr2);
log.info("list:{} size:{} class:{}", list2, list2.size(), list2.get(0).getClass());
2
3
4
5
6
7
修复后的代码得到如下日志,可以看到 List 具有三个元素,元素类型是 Integer:
13:10:57.373 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[1, 2, 3] size:3 class:class java.lang.Integer
可以看到第一个坑是,不能直接使用 Arrays.asList 来转换基本类型数组。那么,我们获得了正确的 List,是不是就可以像普通的 List 那样使用了呢?我们继续往下看。
把三个字符串 1、2、3 构成的字符串数组,使用 Arrays.asList 转换为 List 后,将原始字符串数组的第二个字符修改为 4,然后为 List 增加一个字符串 5,最后数组和 List 会是怎样呢?
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);
2
3
4
5
6
7
8
9
可以看到,日志里有一个 UnsupportedOperationException,为 List 新增字符串 5 的操作失败了,而且把原始数组的第二个元素从 2 修改为 4 后,asList 获得的 List 中的第二个元素也被修改为 4 了:
java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at org.geekbang.time.commonmistakes.collection.aslist.AsListApplication.wrong2(AsListApplication.java:41)
at org.geekbang.time.commonmistakes.collection.aslist.AsListApplication.main(AsListApplication.java:15)
13:15:34.699 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - arr:[1, 4, 3] list:[1, 4, 3]
2
3
4
5
6
这里,又引出了两个坑。
第二个坑,Arrays.asList 返回的 List 不支持增删操作。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。相关源码如下所示:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
...
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
...
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
第三个坑,对原始数组的修改会影响到我们获得的那个 List。看一下 ArrayList 的实现,可以发现 ArrayList 其实是直接使用了原始的数组。所以,我们要特别小心,把通过 Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生 Bug。
修复方式比较简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
String[] arr = {"1", "2", "3"};
List list = new ArrayList(Arrays.asList(arr));
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);
2
3
4
5
6
7
8
9
修改后的代码实现了原始数组和 List 的“解耦”,不再相互影响。同时,因为操作的是真正的 ArrayList,add 也不再出错:
13:34:50.829 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - arr:[1, 4, 3] list:[1, 2, 3, 5]
# 使用 List.subList 进行切片操作居然会导致 OOM?
业务开发时常常要对 List 做切片处理,即取出其中部分元素构成一个新的 List,我们通常会想到使用 List.subList 方法。但和 Arrays.asList 的问题类似,List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题。接下来,我们就一起分析下其中的坑。
如下代码所示,定义一个名为 data 的静态 List 来存放 Integer 的 List,也就是说 data 的成员本身是包含了多个数字的 List。循环 1000 次,每次都从一个具有 10 万个 Integer 的 List 中,使用 subList 方法获得一个只包含一个数字的子 List,并把这个子 List 加入 data 变量:
private static List<List<Integer>> data = new ArrayList<>();
private static void oom() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}
2
3
4
5
6
7
8
你可能会觉得,这个 data 变量里面最终保存的只是 1000 个具有 1 个元素的 List,不会占用很大空间,但程序运行不久就出现了 OOM:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:265)
2
3
出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。那么,返回的子 List 为什么会强引用原始的 List,它们又有什么关系呢?我们再继续做实验观察一下这个子 List 的特性。
首先初始化一个包含数字 1 到 10 的 ArrayList,然后通过调用 subList 方法取出 2、3、4;随后删除这个 SubList 中的元素数字 3,并打印原始的 ArrayList;最后为原始的 ArrayList 增加一个元素数字 0,遍历 SubList 输出所有元素:
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.subList(1, 4);
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
try {
subList.forEach(System.out::println);
} catch (Exception ex) {
ex.printStackTrace();
}
2
3
4
5
6
7
8
9
10
11
代码运行后得到如下输出:
[2, 3, 4]
[1, 2, 4, 5, 6, 7, 8, 9, 10]
java.util.ConcurrentModificationException
at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1239)
at java.util.ArrayList$SubList.listIterator(ArrayList.java:1099)
at java.util.AbstractList.listIterator(AbstractList.java:299)
at java.util.ArrayList$SubList.iterator(ArrayList.java:1095)
at java.lang.Iterable.forEach(Iterable.java:74)
2
3
4
5
6
7
8
可以看到两个现象:
- 原始 List 中数字 3 被删除了,说明删除子 List 中的元素影响到了原始 List;
- 尝试为原始 List 增加数字 0 之后再遍历子 List,会出现 ConcurrentModificationException。
我们分析下 ArrayList 的源码,看看为什么会是这样。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected transient int modCount = 0;
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E element) {
rangeCheck(index);
checkForComodification();
return l.set(index+offset, element);
}
public ListIterator<E> listIterator(final int index) {
checkForComodification();
...
}
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
第一,ArrayList 维护了一个叫作 modCount 的字段,表示集合结构性修改的次数。所谓结构性修改,指的是影响 List 大小的修改,所以 add 操作必然会改变 modCount 的值。
第二,分析第 21 到 24 行的 subList 方法可以看到,获得的 List 其实是内部类 SubList,并不是普通的 ArrayList,在初始化的时候传入了 this。
第三,分析第 26 到 39 行代码可以发现,这个 SubList 中的 parent 字段就是原始的 List。SubList 初始化的时候,并没有把原始 List 中的元素复制到独立的变量中保存。我们可以认为 SubList 是原始 List 的视图,并不是独立的 List。双方对元素的修改会相互影响,而且 SubList 强引用了原始的 List,所以大量保存这样的 SubList 会导致 OOM。
第四,分析第 47 到 55 行代码可以发现,遍历 SubList 的时候会先获得迭代器,比较原始 ArrayList modCount 的值和 SubList 当前 modCount 的值。获得了 SubList 后,我们为原始 List 新增了一个元素修改了其 modCount,所以判等失败抛出 ConcurrentModificationException 异常。
既然 SubList 相当于原始 List 的视图,那么避免相互影响的修复方式有两种:
- 一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;
- 另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
//方式一:
List<Integer> subList = new ArrayList<>(list.subList(1, 4));
//方式二:
List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());
2
3
4
5
修复后代码输出如下:
[2, 3, 4]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
2
4
2
3
4
可以看到,删除 SubList 的元素不再影响原始 List,而对原始 List 的修改也不会再出现 List 迭代异常。
# 一定要让合适的数据结构做合适的事情
第一个误区是,使用数据结构不考虑平衡时间和空间。
首先,定义一个只有一个 int 类型订单号字段的 Order 类:
@Data
@NoArgsConstructor
@AllArgsConstructor
static class Order {
private int orderId;
}
2
3
4
5
6
然后,定义一个包含 elementCount 和 loopCount 两个参数的 listSearch 方法,初始化一个具有 elementCount 个订单对象的 ArrayList,循环 loopCount 次搜索这个 ArrayList,每次随机搜索一个订单号:
private static Object listSearch(int elementCount, int loopCount) {
List<Order> list = IntStream.rangeClosed(1, elementCount).mapToObj(i -> new Order(i)).collect(Collectors.toList());
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = list.stream().filter(order -> order.getOrderId() == search).findFirst().orElse(null);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return list;
}
2
3
4
5
6
7
8
9
随后,定义另一个 mapSearch 方法,从一个具有 elementCount 个元素的 Map 中循环 loopCount 次查找随机订单号。Map 的 Key 是订单号,Value 是订单对象:
private static Object mapSearch(int elementCount, int loopCount) {
Map<Integer, Order> map = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toMap(Function.identity(), i -> new Order(i)));
IntStream.rangeClosed(1, loopCount).forEach(i -> {
int search = ThreadLocalRandom.current().nextInt(elementCount);
Order result = map.get(search);
Assert.assertTrue(result != null && result.getOrderId() == search);
});
return map;
}
2
3
4
5
6
7
8
9
我们知道,搜索 ArrayList 的时间复杂度是 O(n),而 HashMap 的 get 操作的时间复杂度是 O(1)。所以,要对大 List 进行单值搜索的话,可以考虑使用 HashMap,其中 Key 是要搜索的值,Value 是原始对象,会比使用 ArrayList 有非常明显的性能优势。
如下代码所示,对 100 万个元素的 ArrayList 和 HashMap,分别调用 listSearch 和 mapSearch 方法进行 1000 次搜索:
int elementCount = 1000000;
int loopCount = 1000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("listSearch");
Object list = listSearch(elementCount, loopCount);
System.out.println(ObjectSizeCalculator.getObjectSize(list));
stopWatch.stop();
stopWatch.start("mapSearch");
Object map = mapSearch(elementCount, loopCount);
stopWatch.stop();
System.out.println(ObjectSizeCalculator.getObjectSize(map));
System.out.println(stopWatch.prettyPrint());
2
3
4
5
6
7
8
9
10
11
12
可以看到,仅仅是 1000 次搜索,listSearch 方法耗时 3.3 秒,而 mapSearch 耗时仅仅 108 毫秒。
20861992
72388672
StopWatch '': running time = 3506699764 ns
---------------------------------------------
ns % Task name
---------------------------------------------
3398413176 097% listSearch
108286588 003% mapSearch
2
3
4
5
6
7
8
即使我们要搜索的不是单值而是条件区间,也可以尝试使用 HashMap 来进行“搜索性能优化”。如果你的条件区间是固定的话,可以提前把 HashMap 按照条件区间进行分组,Key 就是不同的区间。
的确,如果业务代码中有频繁的大 ArrayList 搜索,使用 HashMap 性能会好很多。类似,如果要对大 ArrayList 进行去重操作,也不建议使用 contains 方法,而是可以考虑使用 HashSet 进行去重。说到这里,还有一个问题,使用 HashMap 是否会牺牲空间呢?
为此,我们使用 ObjectSizeCalculator 工具打印 ArrayList 和 HashMap 的内存占用,可以看到 ArrayList 占用内存 21M,而 HashMap 占用的内存达到了 72M,是 List 的三倍多。进一步使用 MAT 工具分析堆可以再次证明,ArrayList 在内存占用上性价比很高,77% 是实际的数据(如第 1 个图所示,16000000/20861992),而 HashMap 的“含金量”只有 22%(如第 2 个图所示,16000000/72386640)。


所以,在应用内存吃紧的情况下,我们需要考虑是否值得使用更多的内存消耗来换取更高的性能。这里我们看到的是平衡的艺术,空间换时间,还是时间换空间,只考虑任何一个方面都是不对的。
第二个误区是,过于迷信教科书的大 O 时间复杂度。
数据结构中要实现一个列表,有基于连续存储的数组和基于指针串联的链表两种方式。在 Java 中,有代表性的实现是 ArrayList 和 LinkedList,前者背后的数据结构是数组,后者则是(双向)链表。
在选择数据结构的时候,我们通常会考虑每种数据结构不同操作的时间复杂度,以及使用场景两个因素。数组和链表大 O 时间复杂度的显著差异:
- 对于数组,随机元素访问的时间复杂度是 O(1),元素插入操作是 O(n);
- 对于链表,随机元素访问的时间复杂度是 O(n),元素插入操作是 O(1)。
那么,在大量的元素插入、很少的随机访问的业务场景下,是不是就应该使用 LinkedList 呢?接下来,我们写一段代码测试下两者随机访问和插入的性能吧。
定义四个参数一致的方法,分别对元素个数为 elementCount 的 LinkedList 和 ArrayList,循环 loopCount 次,进行随机访问和增加元素到随机位置的操作:
//LinkedList访问
private static void linkedListGet(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(LinkedList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.get(ThreadLocalRandom.current().nextInt(elementCount)));
}
//ArrayList访问
private static void arrayListGet(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(ArrayList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.get(ThreadLocalRandom.current().nextInt(elementCount)));
}
//LinkedList插入
private static void linkedListAdd(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(LinkedList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.add(ThreadLocalRandom.current().nextInt(elementCount),1));
}
//ArrayList插入
private static void arrayListAdd(int elementCount, int loopCount) {
List<Integer> list = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(ArrayList::new));
IntStream.rangeClosed(1, loopCount).forEach(i -> list.add(ThreadLocalRandom.current().nextInt(elementCount),1));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
测试代码如下,10 万个元素,循环 10 万次:
int elementCount = 100000;
int loopCount = 100000;
StopWatch stopWatch = new StopWatch();
stopWatch.start("linkedListGet");
linkedListGet(elementCount, loopCount);
stopWatch.stop();
stopWatch.start("arrayListGet");
arrayListGet(elementCount, loopCount);
stopWatch.stop();
System.out.println(stopWatch.prettyPrint());
StopWatch stopWatch2 = new StopWatch();
stopWatch2.start("linkedListAdd");
linkedListAdd(elementCount, loopCount);
stopWatch2.stop();
stopWatch2.start("arrayListAdd");
arrayListAdd(elementCount, loopCount);
stopWatch2.stop();
System.out.println(stopWatch2.prettyPrint());
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
运行结果可能会让你大跌眼镜。在随机访问方面,我们看到了 ArrayList 的绝对优势,耗时只有 11 毫秒,而 LinkedList 耗时 6.6 秒,这符合上面我们所说的时间复杂度;但,随机插入操作居然也是 LinkedList 落败,耗时 9.3 秒,ArrayList 只要 1.5 秒:
---------------------------------------------
ns % Task name
---------------------------------------------
6604199591 100% linkedListGet
011494583 000% arrayListGet
StopWatch '': running time = 10729378832 ns
---------------------------------------------
ns % Task name
---------------------------------------------
9253355484 086% linkedListAdd
1476023348 014% arrayListAdd
2
3
4
5
6
7
8
9
10
11
12
13
翻看 LinkedList 源码发现,插入操作的时间复杂度是 O(1) 的前提是,你已经有了那个要插入节点的指针。但,在实现的时候,我们需要先通过循环获取到那个节点的 Node,然后再执行插入操作。前者也是有开销的,不可能只考虑插入操作本身的代价:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
所以,对于插入操作,LinkedList 的时间复杂度其实也是 O(n)。继续做更多实验的话你会发现,在各种常用场景下,LinkedList 几乎都不能在性能上胜出 ArrayList。
讽刺的是,LinkedList 的作者约书亚 · 布洛克(Josh Bloch),在其推特上回复别人时说,虽然 LinkedList 是我写的但我从来不用,有谁会真的用吗?
这告诉我们,任何东西理论上和实际上是有差距的,请勿迷信教科书的理论,最好在下定论之前实际测试一下。抛开算法层面不谈,由于 CPU 缓存、内存连续性等问题,链表这种数据结构的实现方式对性能并不友好,即使在它最擅长的场景都不一定可以发挥威力。
# 空值处理
程序中的变量是 null,就意味着它没有引用指向或者说没有指针。这时,我们对这个变量进行任何操作,都必然会引发空指针异常,在 Java 中就是 NullPointerException。那么,空指针异常容易在哪些情况下出现,又应该如何修复呢?
空指针异常虽然恼人但好在容易定位,更麻烦的是要弄清楚 null 的含义。比如,客户端给服务端的一个数据是 null,那么其意图到底是给一个空值,还是没提供值呢?再比如,数据库中字段的 NULL 值,是否有特殊的含义呢,针对数据库中的 NULL 值,写 SQL 需要特别注意什么呢?
# 修复和定位恼人的空指针问题
NullPointerException 是 Java 代码中最常见的异常,将其最可能出现的场景归为以下 5 种:
- 参数值是 Integer 等包装类型,使用时因为自动拆箱出现了空指针异常;
- 字符串比较出现空指针异常;
- 诸如 ConcurrentHashMap 这样的容器不支持 Key 和 Value 为 null,强行 put null 的 Key 或 Value 会出现空指针异常;
- A 对象包含了 B,在通过 A 对象的字段获得 B 之后,没有对字段判空就级联调用 B 的方法出现空指针异常;
- 方法或远程服务返回的 List 不是空而是 null,没有进行判空就直接调用 List 的方法出现空指针异常。
为模拟说明这 5 种场景,写了一个 wrongMethod 方法,并用一个 wrong 方法来调用它。wrong 方法的入参 test 是一个由 0 和 1 构成的、长度为 4 的字符串,第几位设置为 1 就代表第几个参数为 null,用来控制 wrongMethod 方法的 4 个入参,以模拟各种空指针情况:
private List<String> wrongMethod(FooService fooService, Integer i, String s, String t) {
log.info("result {} {} {} {}", i + 1, s.equals("OK"), s.equals(t),
new ConcurrentHashMap<String, String>().put(null, null));
if (fooService.getBarService().bar().equals("OK"))
log.info("OK");
return null;
}
@GetMapping("wrong")
public int wrong(@RequestParam(value = "test", defaultValue = "1111") String test) {
return wrongMethod(test.charAt(0) == '1' ? null : new FooService(),
test.charAt(1) == '1' ? null : 1,
test.charAt(2) == '1' ? null : "OK",
test.charAt(3) == '1' ? null : "OK").size();
}
class FooService {
@Getter
private BarService barService;
}
class BarService {
String bar() {
return "OK";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
很明显,这个案例出现空指针异常是因为变量是一个空指针,尝试获得变量的值或访问变量的成员会获得空指针异常。但这个异常的定位比较麻烦。
在测试方法 wrongMethod 中,我们通过一行日志记录的操作,在一行代码中模拟了 4 处空指针异常:
- 对入参 Integer i 进行 +1 操作;
- 对入参 String s 进行比较操作,判断内容是否等于"OK";
- 对入参 String s 和入参 String t 进行比较操作,判断两者是否相等;
- 对 new 出来的 ConcurrentHashMap 进行 put 操作,Key 和 Value 都设置为 null。
输出的异常信息如下:
java.lang.NullPointerException: null
at org.geekbang.time.commonmistakes.nullvalue.demo2.AvoidNullPointerExceptionController.wrongMethod(AvoidNullPointerExceptionController.java:37)
at org.geekbang.time.commonmistakes.nullvalue.demo2.AvoidNullPointerExceptionController.wrong(AvoidNullPointerExceptionController.java:20)
2
3
这段信息确实提示了这行代码出现了空指针异常,但我们很难定位出到底是哪里出现了空指针,可能是把入参 Integer 拆箱为 int 的时候出现的,也可能是入参的两个字符串任意一个为 null,也可能是因为把 null 加入了 ConcurrentHashMap。
这段信息确实提示了这行代码出现了空指针异常,但我们很难定位出到底是哪里出现了空指针,可能是把入参 Integer 拆箱为 int 的时候出现的,也可能是入参的两个字符串任意一个为 null,也可能是因为把 null 加入了 ConcurrentHashMap。
在这里,推荐使用阿里开源的 Java 故障诊断神器 Arthas。Arthas 简单易用功能强大,可以定位出大多数的 Java 生产问题。
接下来演示下如何在 30 秒内知道 wrongMethod 方法的入参,从而定位到空指针到底是哪个入参引起的。如下截图中有三个红框,我先和你分析第二和第三个红框:
- 第二个红框表示,Arthas 启动后被附加到了 JVM 进程;
- 第三个红框表示,通过 watch 命令监控 wrongMethod 方法的入参。
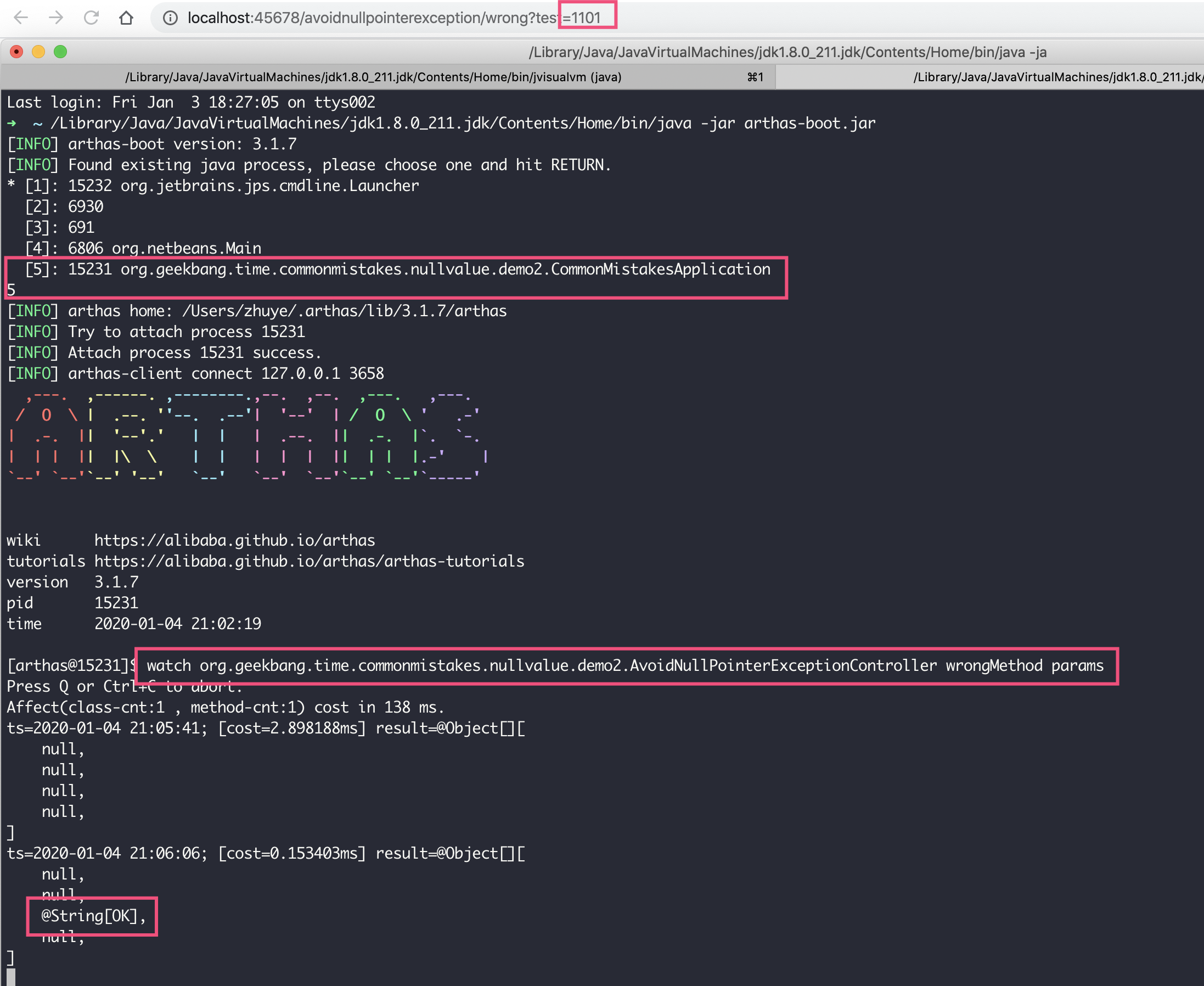
watch 命令的参数包括类名表达式、方法表达式和观察表达式。这里,我们设置观察类为 AvoidNullPointerExceptionController,观察方法为 wrongMethod,观察表达式为 params 表示观察入参:
watch org.geekbang.time.commonmistakes.nullvalue.demo2.AvoidNullPointerExceptionController wrongMethod params
开启 watch 后,执行 2 次 wrong 方法分别设置 test 入参为 1111 和 1101,也就是第一次传入 wrongMethod 的 4 个参数都为 null,第二次传入的第 1、2 和 4 个参数为 null。
配合图中第一和第四个红框可以看到,第二次调用时,第三个参数是字符串 OK 其他参数是 null,Archas 正确输出了方法的所有入参,这样我们很容易就能定位到空指针的问题了。
这里,如果是简单的业务逻辑的话,你就可以定位到空指针异常了;如果是分支复杂的业务逻辑,你需要再借助 stack 命令来查看 wrongMethod 方法的调用栈,并配合 watch 命令查看各方法的入参,就可以很方便地定位到空指针的根源了。
下图演示了通过 stack 命令观察 wrongMethod 的调用路径:

接下来,我们看看如何修复上面出现的 5 种空指针异常。
其实,对于任何空指针异常的处理,最直白的方式是先判空后操作。不过,这只能让异常不再出现,我们还是要找到程序逻辑中出现的空指针究竟是来源于入参还是 Bug:
- 如果是来源于入参,还要进一步分析入参是否合理等;
- 如果是来源于 Bug,那空指针不一定是纯粹的程序 Bug,可能还涉及业务属性和接口调用规范等。
在这里,因为是 Demo,所以我们只考虑纯粹的空指针判空这种修复方式。如果要先判空后处理,大多数人会想到使用 if-else 代码块。但,这种方式既增加代码量又会降低易读性,我们可以尝试利用 Java 8 的 Optional 类来消除这样的 if-else 逻辑,使用一行代码进行判空和处理。
在这里,因为是 Demo,所以我们只考虑纯粹的空指针判空这种修复方式。如果要先判空后处理,大多数人会想到使用 if-else 代码块。但,这种方式既增加代码量又会降低易读性,我们可以尝试利用 Java 8 的 Optional 类来消除这样的 if-else 逻辑,使用一行代码进行判空和处理。
在这里,因为是 Demo,所以我们只考虑纯粹的空指针判空这种修复方式。如果要先判空后处理,大多数人会想到使用 if-else 代码块。但,这种方式既增加代码量又会降低易读性,我们可以尝试利用 Java 8 的 Optional 类来消除这样的 if-else 逻辑,使用一行代码进行判空和处理。
修复思路如下:
- 对于 Integer 的判空,可以使用 Optional.ofNullable 来构造一个 Optional,然后使用 orElse(0) 把 null 替换为默认值再进行 +1 操作。
- 对于 String 和字面量的比较,可以把字面量放在前面,比如"OK".equals(s),这样即使 s 是 null 也不会出现空指针异常;
- 而对于两个可能为 null 的字符串变量的 equals 比较,可以使用 Objects.equals,它会做判空处理。
- 对于 ConcurrentHashMap,既然其 Key 和 Value 都不支持 null,修复方式就是不要把 null 存进去。HashMap 的 Key 和 Value 可以存入 null,而 ConcurrentHashMap 看似是 HashMap 的线程安全版本,却不支持 null 值的 Key 和 Value,这是容易产生误区的一个地方。
- 对于类似 fooService.getBarService().bar().equals(“OK”) 的级联调用,需要判空的地方有很多,包括 fooService、getBarService() 方法的返回值,以及 bar 方法返回的字符串。如果使用 if-else 来判空的话可能需要好几行代码,但使用 Optional 的话一行代码就够了。
- 对于 rightMethod 返回的 List,由于不能确认其是否为 null,所以在调用 size 方法获得列表大小之前,同样可以使用 Optional.ofNullable 包装一下返回值,然后通过.orElse(Collections.emptyList()) 实现在 List 为 null 的时候获得一个空的 List,最后再调用 size 方法。
private List<String> rightMethod(FooService fooService, Integer i, String s, String t) {
log.info("result {} {} {} {}", Optional.ofNullable(i).orElse(0) + 1, "OK".equals(s), Objects.equals(s, t), new HashMap<String, String>().put(null, null));
Optional.ofNullable(fooService)
.map(FooService::getBarService)
.filter(barService -> "OK".equals(barService.bar()))
.ifPresent(result -> log.info("OK"));
return new ArrayList<>();
}
@GetMapping("right")
public int right(@RequestParam(value = "test", defaultValue = "1111") String test) {
return Optional.ofNullable(rightMethod(test.charAt(0) == '1' ? null : new FooService(),
test.charAt(1) == '1' ? null : 1,
test.charAt(2) == '1' ? null : "OK",
test.charAt(3) == '1' ? null : "OK"))
.orElse(Collections.emptyList()).size();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
经过修复后,调用 right 方法传入 1111,也就是给 rightMethod 的 4 个参数都设置为 null,日志中也看不到任何空指针异常了:
[21:43:40.619] [http-nio-45678-exec-2] [INFO ] [.AvoidNullPointerExceptionController:45 ] - result 1 false true null
但是,如果我们修改 right 方法入参为 0000,即传给 rightMethod 方法的 4 个参数都不可能是 null,最后日志中也无法出现 OK 字样。这又是为什么呢,BarService 的 bar 方法不是返回了 OK 字符串吗?
我们还是用 Arthas 来定位问题,使用 watch 命令来观察方法 rightMethod 的入参,-x 参数设置为 2 代表参数打印的深度为 2 层:

可以看到,FooService 中的 barService 字段为 null,这样也就可以理解为什么最终出现这个 Bug 了。
这又引申出一个问题,使用判空方式或 Optional 方式来避免出现空指针异常,不一定是解决问题的最好方式,空指针没出现可能隐藏了更深的 Bug。因此,解决空指针异常,还是要真正 case by case 地定位分析案例,然后再去做判空处理,而处理时也并不只是判断非空然后进行正常业务流程这么简单,同样需要考虑为空的时候是应该出异常、设默认值还是记录日志等。
# POJO 中属性的 null 到底代表了什么?
比判空避免空指针异常,更容易出错的是 null 的定位问题。对程序来说,null 就是指针没有任何指向,而结合业务逻辑情况就复杂得多,我们需要考虑:
- DTO 中字段的 null 到底意味着什么?是客户端没有传给我们这个信息吗?
- 既然空指针问题很讨厌,那么 DTO 中的字段要设置默认值么?
- 如果数据库实体中的字段有 null,那么通过数据访问框架保存数据是否会覆盖数据库中的既有数据?
如果不能明确地回答这些问题,那么写出的程序逻辑很可能会混乱不堪。接下来,我们看一个实际案例吧。
有一个 User 的 POJO,同时扮演 DTO 和数据库 Entity 角色,包含用户 ID、姓名、昵称、年龄、注册时间等属性:
@Data
@Entity
public class User {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String name;
private String nickname;
private Integer age;
private Date createDate = new Date();
}
2
3
4
5
6
7
8
9
10
11
有一个 Post 接口用于更新用户数据,更新逻辑非常简单,根据用户姓名自动设置一个昵称,昵称的规则是“用户类型 + 姓名”,然后直接把客户端在 RequestBody 中使用 JSON 传过来的 User 对象通过 JPA 更新到数据库中,最后返回保存到数据库的数据。
@Autowired
private UserRepository userRepository;
@PostMapping("wrong")
public User wrong(@RequestBody User user) {
user.setNickname(String.format("guest%s", user.getName()));
return userRepository.save(user);
}
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
}
2
3
4
5
6
7
8
9
10
11
12
首先,在数据库中初始化一个用户,age=36、name=zhuye、create_date=2020 年 1 月 4 日、nickname 是 NULL:

然后,使用 cURL 测试一下用户信息更新接口 Post,传入一个 id=1、name=null 的 JSON 字符串,期望把 ID 为 1 的用户姓名设置为空:
curl -H "Content-Type:application/json" -X POST -d '{ "id":1, "name":null}' http://localhost:45678/pojonull/wrong
{"id":1,"name":null,"nickname":"guestnull","age":null,"createDate":"2020-01-05T02:01:03.784+0000"}%
2
3
接口返回的结果和数据库中记录一致:

可以看到,这里存在如下三个问题:
- 调用方只希望重置用户名,但 age 也被设置为了 null;
- nickname 是用户类型加姓名,name 重置为 null 的话,访客用户的昵称应该是 guest,而不是 guestnull;
- 用户的创建时间原来是 1 月 4 日,更新了用户信息后变为了 1 月 5 日。
归根结底,这是如下 5 个方面的问题:
- 明确 DTO 中 null 的含义。对于 JSON 到 DTO 的反序列化过程,null 的表达是有歧义的,客户端不传某个属性,或者传 null,这个属性在 DTO 中都是 null。但,对于用户信息更新操作,不传意味着客户端不需要更新这个属性,维持数据库原先的值;传了 null,意味着客户端希望重置这个属性。因为 Java 中的 null 就是没有这个数据,无法区分这两种表达,所以本例中的 age 属性也被设置为了 null,或许我们可以借助 Optional 来解决这个问题。
- POJO 中的字段有默认值。如果客户端不传值,就会赋值为默认值,导致创建时间也被更新到了数据库中。
- 注意字符串格式化时可能会把 null 值格式化为 null 字符串。比如昵称的设置,我们只是进行了简单的字符串格式化,存入数据库变为了 guestnull。显然,这是不合理的,还需要进行判断。
- DTO 和 Entity 共用了一个 POJO。对于用户昵称的设置是程序控制的,我们不应该把它们暴露在 DTO 中,否则很容易把客户端随意设置的值更新到数据库中。此外,创建时间最好让数据库设置为当前时间,不用程序控制,可以通过在字段上设置 columnDefinition 来实现。
- 数据库字段允许保存 null,会进一步增加出错的可能性和复杂度。因为如果数据真正落地的时候也支持 NULL 的话,可能就有 NULL、空字符串和字符串 null 三种状态。如果所有属性都有默认值,问题会简单一点。
按照这个思路,我们对 DTO 和 Entity 进行拆分,修改后代码如下所示:
- UserDto 中只保留 id、name 和 age 三个属性,且 name 和 age 使用 Optional 来包装,以区分客户端不传数据还是故意传 null。
- 在 UserEntity 的字段上使用 @Column 注解,把数据库字段 name、nickname、age 和 createDate 都设置为 NOT NULL,并设置 createDate 的默认值为 CURRENT_TIMESTAMP,由数据库来生成创建时间。
- 使用 Hibernate 的 @DynamicUpdate 注解实现更新 SQL 的动态生成,实现只更新修改后的字段,不过需要先查询一次实体,让 Hibernate 可以“跟踪”实体属性的当前状态,以确保有效。
@Data
public class UserDto {
private Long id;
private Optional<String> name;
private Optional<Integer> age;
;
@Data
@Entity
@DynamicUpdate
public class UserEntity {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private String nickname;
@Column(nullable = false)
private Integer age;
@Column(nullable = false, columnDefinition = "TIMESTAMP DEFAULT CURRENT_TIMESTAMP")
private Date createDate;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在重构了 DTO 和 Entity 后,我们重新定义一个 right 接口,以便对更新操作进行更精细化的处理。首先是参数校验:
- 对传入的 UserDto 和 ID 属性先判空,如果为空直接抛出 IllegalArgumentException。
- 根据 id 从数据库中查询出实体后进行判空,如果为空直接抛出 IllegalArgumentException。
然后,由于 DTO 中已经巧妙使用了 Optional 来区分客户端不传值和传 null 值,那么业务逻辑实现上就可以按照客户端的意图来分别实现逻辑。如果不传值,那么 Optional 本身为 null,直接跳过 Entity 字段的更新即可,这样动态生成的 SQL 就不会包含这个列;如果传了值,那么进一步判断传的是不是 null。
下面,我们根据业务需要分别对姓名、年龄和昵称进行更新:
- 对于姓名,我们认为客户端传 null 是希望把姓名重置为空,允许这样的操作,使用 Optional 的 orElse 方法一键把空转换为空字符串即可。
- 对于年龄,我们认为如果客户端希望更新年龄就必须传一个有效的年龄,年龄不存在重置操作,可以使用 Optional 的 orElseThrow 方法在值为空的时候抛出 IllegalArgumentException。
- 对于昵称,因为数据库中姓名不可能为 null,所以可以放心地把昵称设置为 guest 加上数据库取出来的姓名。
@PostMapping("right")
public UserEntity right(@RequestBody UserDto user) {
if (user == null || user.getId() == null)
throw new IllegalArgumentException("用户Id不能为空");
UserEntity userEntity = userEntityRepository.findById(user.getId())
.orElseThrow(() -> new IllegalArgumentException("用户不存在"));
if (user.getName() != null) {
userEntity.setName(user.getName().orElse(""));
}
userEntity.setNickname("guest" + userEntity.getName());
if (user.getAge() != null) {
userEntity.setAge(user.getAge().orElseThrow(() -> new IllegalArgumentException("年龄不能为空")));
}
return userEntityRepository.save(userEntity);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
假设数据库中已经有这么一条记录,id=1、age=36、create_date=2020 年 1 月 4 日、name=zhuye、nickname=guestzhuye:

使用相同的参数调用 right 接口,再来试试是否解决了所有问题。传入一个 id=1、name=null 的 JSON 字符串,期望把 id 为 1 的用户姓名设置为空:
curl -H "Content-Type:application/json" -X POST -d '{ "id":1, "name":null}' http://localhost:45678/pojonull/right
{"id":1,"name":"","nickname":"guest","age":36,"createDate":"2020-01-04T11:09:20.000+0000"}%
2
3
结果如下:

可以看到,right 接口完美实现了仅重置 name 属性的操作,昵称也不再有 null 字符串,年龄和创建时间字段也没被修改。
通过日志可以看到,Hibernate 生成的 SQL 语句只更新了 name 和 nickname 两个字段:
Hibernate: update user_entity set name=?, nickname=? where id=?
接下来,为了测试使用 Optional 是否可以有效区分 JSON 中没传属性还是传了 null,我们在 JSON 中设置了一个 null 的 age,结果是正确得到了年龄不能为空的错误提示:
curl -H "Content-Type:application/json" -X POST -d '{ "id":1, "age":null}' http://localhost:45678/pojonull/right
{"timestamp":"2020-01-05T03:14:40.324+0000","status":500,"error":"Internal Server Error","message":"年龄不能为空","path":"/pojonull/right"}%
2
3
# 小心 MySQL 中有关 NULL 的三个坑
前面提到,数据库表字段允许存 NULL 除了会让我们困惑外,还容易有坑。这里会结合 NULL 字段,着重说明 sum 函数、count 函数,以及 NULL 值条件可能踩的坑。
为方便演示,首先定义一个只有 id 和 score 两个字段的实体:
@Entity
@Data
public class User {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private Long score;
}
2
3
4
5
6
7
8
程序启动的时候,往实体初始化一条数据,其 id 是自增列自动设置的 1,score 是 NULL:
@Autowired
private UserRepository userRepository;
@PostConstruct
public void init() {
userRepository.save(new User());
}
2
3
4
5
6
7
然后,测试下面三个用例,来看看结合数据库中的 null 值可能会出现的坑:
- 通过 sum 函数统计一个只有 NULL 值的列的总和,比如 SUM(score);
- select 记录数量,count 使用一个允许 NULL 的字段,比如 COUNT(score);
- 使用 =NULL 条件查询字段值为 NULL 的记录,比如 score=null 条件。
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
@Query(nativeQuery=true,value = "SELECT SUM(score) FROM `user`")
Long wrong1();
@Query(nativeQuery = true, value = "SELECT COUNT(score) FROM `user`")
Long wrong2();
@Query(nativeQuery = true, value = "SELECT * FROM `user` WHERE score=null")
List<User> wrong3();
}
2
3
4
5
6
7
8
9
得到的结果,分别是 null、0 和空 List:
[11:38:50.137] [http-nio-45678-exec-1] [INFO ] [t.c.nullvalue.demo3.DbNullController:26 ] - result: null 0 []
显然,这三条 SQL 语句的执行结果和我们的期望不同:
- 虽然记录的 score 都是 NULL,但 sum 的结果应该是 0 才对;
- 虽然这条记录的 score 是 NULL,但记录总数应该是 1 才对;
- 使用 =NULL 并没有查询到 id=1 的记录,查询条件失效。
原因是:
- MySQL 中 sum 函数没统计到任何记录时,会返回 null 而不是 0,可以使用 IFNULL 函数把 null 转换为 0;
- MySQL 中 count 字段不统计 null 值,COUNT(*) 才是统计所有记录数量的正确方式。
- MySQL 中使用诸如 =、<、> 这样的算数比较操作符比较 NULL 的结果总是 NULL,这种比较就显得没有任何意义,需要使用 IS NULL、IS NOT NULL 或 ISNULL() 函数来比较。
修改一下 SQL:
@Query(nativeQuery = true, value = "SELECT IFNULL(SUM(score),0) FROM `user`")
Long right1();
@Query(nativeQuery = true, value = "SELECT COUNT(*) FROM `user`")
Long right2();
@Query(nativeQuery = true, value = "SELECT * FROM `user` WHERE score IS NULL")
List<User> right3();
2
3
4
5
6
可以得到三个正确结果,分别为 0、1、[User(id=1, score=null)] :
[14:50:35.768] [http-nio-45678-exec-1] [INFO ] [t.c.nullvalue.demo3.DbNullController:31 ] - result: 0 1 [User(id=1, score=null)]
# 问题解答
问题 1:通过 getClass 方法判断两个对象的类型,还可以使用 instanceof 来判断。这两种实现方式的区别吗?
答:事实上,使用 getClass 和 instanceof 这两种方案都是可以判断对象类型的。它们的区别就是,getClass 限制了这两个对象只能属于同一个类,而 instanceof 却允许两个对象是同一个类或其子类。
正是因为这种区别,不同的人对这两种方案有不同的喜好,争论也很多。只需要根据自己的要求去选择。补充说明一下,Lombok 使用的是 instanceof 的方案。
问题 2:通过 HashSet 的 contains 方法判断元素是否在 HashSet 中。那同样是 Set 的 TreeSet,其 contains 方法和 HashSet 的 contains 方法有什么区别吗?
答:HashSet 基于 HashMap,数据结构是哈希表。所以,HashSet 的 contains 方法,其实就是根据 hashcode 和 equals 去判断相等的。
TreeSet 基于 TreeMap,数据结构是红黑树。所以,TreeSet 的 contains 方法,其实就是根据 compareTo 去判断相等的。
问题 3:BigDecimal 提供了 8 种舍入模式,能通过一些例子说说它们的区别吗?
第一种,ROUND_UP,舍入远离零的舍入模式,在丢弃非零部分之前始终增加数字(始终对非零舍弃部分前面的数字加 1)。 需要注意的是,此舍入模式始终不会减少原始值。
第二种,ROUND_DOWN,接近零的舍入模式,在丢弃某部分之前始终不增加数字(从不对舍弃部分前面的数字加 1,即截断)。 需要注意的是,此舍入模式始终不会增加原始值。
第三种,ROUND_CEILING,接近正无穷大的舍入模式。 如果 BigDecimal 为正,则舍入行为与 ROUND_UP 相同; 如果为负,则舍入行为与 ROUND_DOWN 相同。 需要注意的是,此舍入模式始终不会减少原始值。
第四种,ROUND_FLOOR,接近负无穷大的舍入模式。 如果 BigDecimal 为正,则舍入行为与 ROUND_DOWN 相同; 如果为负,则舍入行为与 ROUND_UP 相同。 需要注意的是,此舍入模式始终不会增加原始值。
第五种,ROUND_HALF_UP,向“最接近的”数字舍入。如果舍弃部分 >= 0.5,则舍入行为与 ROUND_UP 相同;否则,舍入行为与 ROUND_DOWN 相同。 需要注意的是,这是我们大多数人在小学时就学过的舍入模式(四舍五入)。
第六种,ROUND_HALF_DOWN,向“最接近的”数字舍入。如果舍弃部分 > 0.5,则舍入行为与 ROUND_UP 相同;否则,舍入行为与 ROUND_DOWN 相同(五舍六入)。
第七种,ROUND_HALF_EVEN,向“最接近的”数字舍入。这种算法叫做银行家算法,具体规则是,四舍六入,五则看前一位,如果是偶数舍入,如果是奇数进位,比如 5.5 -> 6,2.5 -> 2。
第八种,ROUND_UNNECESSARY,假设请求的操作具有精确的结果,也就是不需要进行舍入。如果计算结果产生不精确的结果,则抛出 ArithmeticException。
问题 4:数据库(比如 MySQL)中的浮点数和整型数字,应该怎样定义吗?又如何实现浮点数的准确计算呢?
答:MySQL 中的整数根据能表示的范围有 TINYINT、SMALLINT、MEDIUMINT、INTEGER、BIGINT 等类型,浮点数包括单精度浮点数 FLOAT 和双精度浮点数 DOUBLE 和 Java 中的 float/double 一样,同样有精度问题。
要解决精度问题,主要有两个办法:
- 第一,使用 DECIMAL 类型(和那些 INT 类型一样,都属于严格数值数据类型),比如 DECIMAL(13, 2) 或 DECIMAL(13, 4)。
- 第二,使用整数保存到分,这种方式容易出错,万一读的时候忘记 /100 或者是存的时候忘记 *100,可能会引起重大问题。当然了,我们也可以考虑将整数和小数分开保存到两个整数字段。
问题 5:调用类型是 Integer 的 ArrayList 的 remove 方法删除元素,传入一个 Integer 包装类的数字和传入一个 int 基本类型的数字,结果一样吗?
答:传 int 基本类型的 remove 方法是按索引值移除,返回移除的值;传 Integer 包装类的 remove 方法是按值移除,返回列表移除项目之前是否包含这个值(是否移除成功)。
为了验证两个 remove 方法重载的区别,我们写一段测试代码比较一下:
private static void removeByIndex(int index) { List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toCollection(ArrayList::new)); System.out.println(list.remove(index)); System.out.println(list); } private static void removeByValue(Integer index) { List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toCollection(ArrayList::new)); System.out.println(list.remove(index)); System.out.println(list); }1
2
3
4
5
6
7
8
9
10
11
12测试一下 removeByIndex(4),通过输出可以看到第五项被移除了,返回 5:
5 [1, 2, 3, 4, 6, 7, 8, 9, 10]1
2而调用 removeByValue(Integer.valueOf(4)),通过输出可以看到值 4 被移除了,返回 true:
true [1, 2, 3, 5, 6, 7, 8, 9, 10]1
2问题 6:循环遍历 List,调用 remove 方法删除元素,往往会遇到 ConcurrentModificationException,原因是什么,修复方式又是什么呢?
答:原因是,remove 的时候会改变 modCount,通过迭代器遍历就会触发 ConcurrentModificationException。我们看下 ArrayList 类内部迭代器的相关源码:
public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16要修复这个问题,有以下两种解决方案。
第一种,通过 ArrayList 的迭代器 remove。迭代器的 remove 方法会维护一个 expectedModCount,使其与 ArrayList 的 modCount 保持一致:
List<String> list = IntStream.rangeClosed(1, 10).mapToObj(String::valueOf).collect(Collectors.toCollection(ArrayList::new)); for (Iterator<String> iterator = list.iterator(); iterator.hasNext(); ) { String next = iterator.next(); if ("2".equals(next)) { iterator.remove(); } } System.out.println(list);1
2
3
4
5
6
7
8
9第二种,直接使用 removeIf 方法,其内部使用了迭代器的 remove 方法:
List<String> list = IntStream.rangeClosed(1, 10).mapToObj(String::valueOf).collect(Collectors.toCollection(ArrayList::new)); list.removeIf(item -> item.equals("2")); System.out.println(list);1
2
3
4问题 7:ConcurrentHashMap 的 Key 和 Value 都不能为 null,而 HashMap 却可以,你知道这么设计的原因是什么吗?TreeMap、Hashtable 等 Map 的 Key 和 Value 是否支持 null 呢?
答:原因正如 ConcurrentHashMap 的作者所说:The main reason that nulls aren’t allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can’t be accommodated. The main one is that if map.get(key) returns null, you can’t detect whether the key explicitly maps to null vs the key isn’t mapped. In a non-concurrent map, you can check this via map.contains(key), but in a concurrent one, the map might have changed between calls.
如果 Value 为 null 会增加二义性,也就是说多线程情况下 map.get(key) 返回 null,我们无法区分 Value 原本就是 null 还是 Key 没有映射,Key 也是类似的原因。此外,就是普通的 Map 允许 null 是否是一个正确的做法,也值得商榷,因为这会增加犯错的可能性。
Hashtable 也是线程安全的,所以 Key 和 Value 不可以是 null。
TreeMap 是线程不安全的,但是因为需要排序,需要进行 key 的 compareTo 方法,所以 Key 不能是 null,而 Value 可以是 null。
问题 8:对于 Hibernate 框架,我们可以使用 @DynamicUpdate 注解实现字段的动态更新。那么,对于 MyBatis 框架来说,要如何实现类似的动态 SQL 功能,实现插入和修改 SQL 只包含 POJO 中的非空字段呢?
答:MyBatis 可以通过动态 SQL 实现:
<select id="findUser" resultType="User"> SELECT * FROM USER WHERE 1=1 <if test="name != null"> AND name like #{name} </if> <if test="email != null"> AND email = #{email} </if> </select>1
2
3
4
5
6
7
8
9
10如果使用 MyBatisPlus 的话,实现类似的动态 SQL 功能会更方便。我们可以直接在字段上加 @TableField 注解来实现,可以设置 insertStrategy、updateStrategy、whereStrategy 属性。关于这三个属性的使用方式,你可以参考如下源码,或是这里 (opens new window)的官方文档:
/** * 字段验证策略之 insert: 当insert操作时,该字段拼接insert语句时的策略 * IGNORED: 直接拼接 insert into table_a(column) values (#{columnProperty}); * NOT_NULL: insert into table_a(<if test="columnProperty != null">column</if>) values (<if test="columnProperty != null">#{columnProperty}</if>) * NOT_EMPTY: insert into table_a(<if test="columnProperty != null and columnProperty!=''">column</if>) values (<if test="columnProperty != null and columnProperty!=''">#{columnProperty}</if>) * * @since 3.1.2 */ FieldStrategy insertStrategy() default FieldStrategy.DEFAULT; /** * 字段验证策略之 update: 当更新操作时,该字段拼接set语句时的策略 * IGNORED: 直接拼接 update table_a set column=#{columnProperty}, 属性为null/空string都会被set进去 * NOT_NULL: update table_a set <if test="columnProperty != null">column=#{columnProperty}</if> * NOT_EMPTY: update table_a set <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> * * @since 3.1.2 */ FieldStrategy updateStrategy() default FieldStrategy.DEFAULT; /** * 字段验证策略之 where: 表示该字段在拼接where条件时的策略 * IGNORED: 直接拼接 column=#{columnProperty} * NOT_NULL: <if test="columnProperty != null">column=#{columnProperty}</if> * NOT_EMPTY: <if test="columnProperty != null and columnProperty!=''">column=#{columnProperty}</if> * * @since 3.1.2 */ FieldStrategy whereStrategy() default FieldStrategy.DEFAULT;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 参考
- 来源:极客时间《Java 业务开发常见错误 100例》