 MySQl - 性能优化
MySQl - 性能优化
# MySQL 性能优化
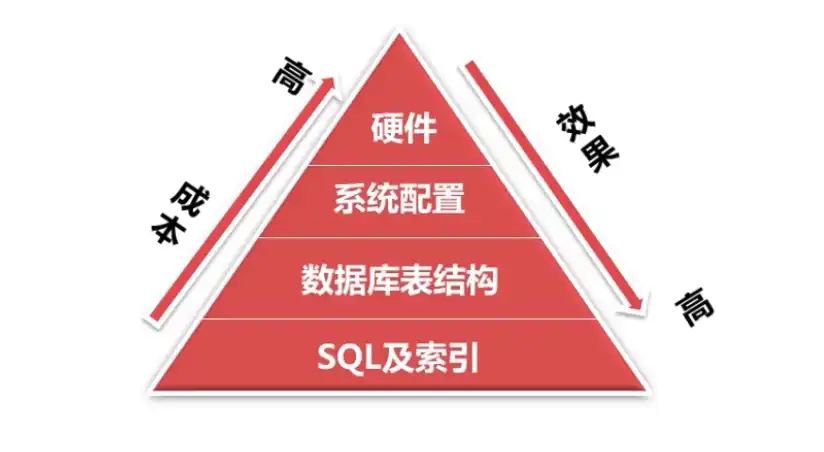
# 1. SQL 语句优化
# 1.1 发现有问题的 SQL
开启慢查询日志:
show variables like 'slow_query_log';
set global slow_query_log = on;
set global slow_query_log_file = '/usr/local/var/mysql/jason-slow.log';
set global log_queries_not_using_indexes = on;
set global long_query_time = 1;
2
3
4
5
慢查询分析工具:
mysqldumpslow
mysqldumpslow -t 3 /usr/local/var/mysql/jason-slow.log1pt-query-digest 参考:pt-query-digest 分析慢查询日志 (opens new window)
pt-query-digest slow.log1- 查询次数多且每次查询占用时间长的 SQL:通常为 pt-query-digest 分析的前几个查询
- IO 大的SQL:注意 pt-query-digest 分析中的 Rows examine 项
- 注意 pt-query-digest 分析中 Rows examine 和 Rows Send 的对比,前者远大于后者
# 1.2 分析 SQL 查询
使用 explain 查询 SQL 的执行计划,
explain 字段:
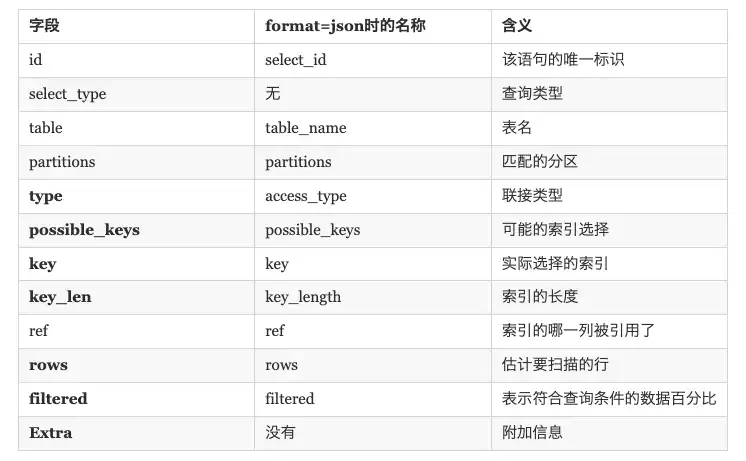
字段详解:
id
该语句的唯一标识。如果 explain 的结果包括多个 id 值,则数字越大越先执行;而对于相同 id 的行,则表示从上往下依次执行。
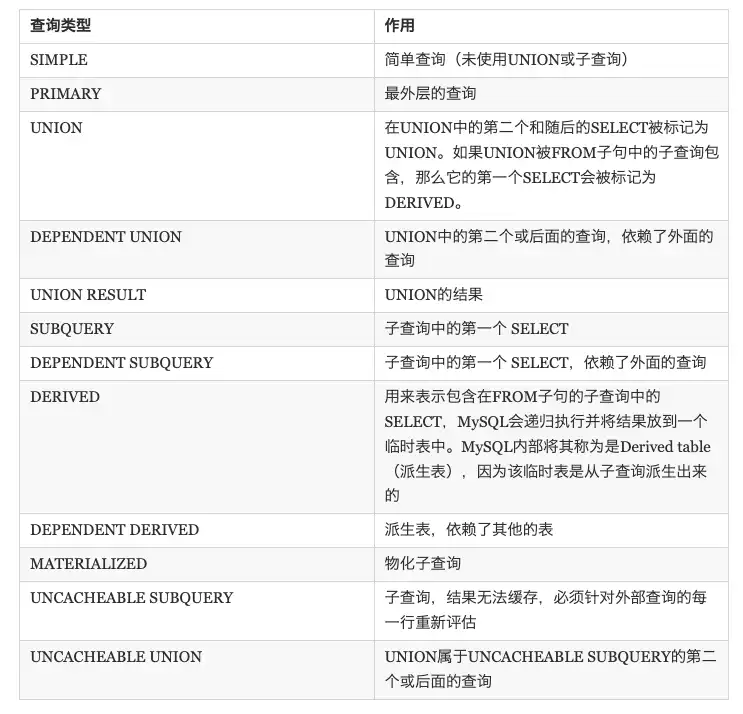
select_type
查询类型,有如下几种取值:
table
表示当前这一行正在访问哪张表,如果 SQL 定义了别名,则展示表的别名
partitions
当前查询匹配记录的分区。对于未分区的表,返回 null
type
连接类型,有如下几种取值,性能从好到坏排序 如下:
- system:该表只有一行(相当于系统表),system 是 const 类型的特例
- const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
- eq_ref:当使用了索引的全部组成部分,并且索引是 PRIMARY KEY 或 UNIQUE NOT NULL 才会使用该类型,性能仅次于 system 及 const。
- ref:当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。如果使用的索引只会匹配到少量的行,性能也是不错的。
- fulltext:全文索引
- ref_or_null:该类型类似于 ref,但是 MySQL 会额外搜索哪些行包含了 NULL。这种类型常见于解析子查询
- index_merge:此类型表示使用了索引合并优化,表示一个查询里面用到了多个索引
- unique_subquery:该类型和 eq_ref 类似,但是使用了 IN 查询,且子查询是主键或者唯一索引
- index_subquery:和 unique_subquery 类似,只是子查询使用的是非唯一索引
- range:范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有 BETWEEN 子句或 WHERE 子句里有 >、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN() 等操作符。
- index:全索引扫描,和 ALL 类似,只不过 index 是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
- 如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain 的 Extra 列的结果是 Using index。index 通常比 ALL 快,因为索引的大小通常小于表数据。
- 按索引的顺序来查找数据行,执行了全表扫描。此时,explain 的 Extra 列的结果不会出现 Uses index。
- ALL:全表扫描,性能最差
possible_keys
展示当前查询可以使用哪些索引,这一列的数据是在优化过程的早期创建的,因此有些索引可能对于后续优化过程是没用的。
key
表示MySQL实际选择的索引
key_len
索引使用的字节数。由于存储格式,当字段允许为 NULL 时,key_len 比不允许为空时大 1 字节。
ref
表示将哪个字段或常量和key列所使用的字段进行比较。
如果 ref 是一个函数,则使用的值是函数的结果。要想查看是哪个函数,可在 EXPLAIN 语句之后紧跟一个 SHOW WARNING 语句。
rows
MySQL估算会扫描的行数,数值越小越好。
filtered
表示符合查询条件的数据百分比,最大 100。用 rows × filtered 可获得和下一张表连接的行数。例如 rows = 1000,filtered = 50%,则和下一张表连接的行数是 500。
Extra
展示有关本次查询的附加信息,常见取值如下:
Using filesort
当Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain不会显示的告诉客户端用哪种排序。官方解释:“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行”
Using index
仅使用索引树中的信息从表中检索列信息,而不必进行其他查找以读取实际行。当查询仅使用属于单个索引的列时,可以使用此策略
Using index condition
表示先按条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。通过这种方式,除非有必要,否则索引信息将可以延迟“下推”读取整个行的数据。详见 “Index Condition Pushdown Optimization (opens new window)” 。
Using index for group-by
数据访问和 Using index 一样,所需数据只须要读取索引,当 Query 中使用 GROUP BY 或 DISTINCT 子句时,如果分组字段也在索引中,Extra 中的信息就会是 Using index for group-by。详见 “GROUP BY Optimization” (opens new window)
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access)
使用 Block Nested Loop 或Batched Key Access 算法提高join的性能。详见 https://www.cnblogs.com/chenpingzhao/p/6720531.html
Using MRR
使用了 Multi-Range Read 优化策略。详见 “Multi-Range Read Optimization” (opens new window)
Using temporary
为了解决该查询,MySQL 需要创建一个临时表来保存结果。如果查询包含不同列的 GROUP BY和 ORDER BY 子句,通常会发生这种情况。
Using where
如果我们不是读取表的所有数据,或者不是仅仅通过索引就可以获取所有需要的数据,则会出现 using where 信息
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最好。说明:
- consts 单表中最多只有一个匹配行 (主键或者唯一索引),在优化阶段即可读取到数据
- ref 指的是使用普通的索引 (normal index)
- range 对索引进行范围检索
当 Extra 中出现如下,说明需要优化:
- Using filesort:当 Query 中包含 ORDER BY 操作,而且无法利用索引完成排序操作的时候,MySQL Query Optimizer 不得不选择相应的排序算法来实现。数据较少时从内存排序,否则从磁盘排序。Explain 不会显示的告诉客户端用哪种排序。官方解释:“MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配 WHERE 子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行”
- Using temporary:为了解决该查询,MySQL 需要创建一个临时表来保存结果。如果查询包含不同列的 GROUP BY 和 ORDER BY 子句,通常会发生这种情况。
# 1.3 优化实例 TODO
- count() 和 max() 优化
- 子查询优化
- group by 优化
- limit 优化
慢查询
mysql> EXPLAIN SELECT itemnumber,quantity,price,transdate -- 分析查询执行情况
-> FROM demo.trans
-> WHERE itemnumber=1 -- 通过商品编号筛选
-> AND transdate>'2020-06-18 09:00:00' -- 通过交易时间筛选
-> AND transdate<'2020-06-18 12:00:00';
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key |key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | trans | NULL | ALL | NULL | NULL | NULL | NULL | 4157166 | 1.11 | Using where | -- 没有索引,扫描4157166条记录
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
2
3
4
5
6
7
8
9
10
11
例子:
mysql> EXPLAIN SELECT *
-> FROM demo.goodsmaster a
-> WHERE a.itemnumber in
-> (
-> SELECTb.itemnumber
-> FROM demo.goodsmaster b
-> WHERE b.goodsname = '书'
-> UNION
-> SELECTc.itemnumber
-> FROM demo.goodsmaster c
-> WHERE c.goodsname = '笔'
-> );
+----+--------------------+------------+------------+--------+---------------+---------+---------+------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+------------+------------+--------+---------------+---------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | a | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | b | NULL | eq_ref | PRIMARY | PRIMARY | 4 | func | 1 | 50.00 | Using where |
| 3 | DEPENDENT UNION | c | NULL | eq_ref | PRIMARY | PRIMARY | 4 | func | 1 | 50.00 | Using where |
| NULL | UNION RESULT | <union2,3> | NULL | ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------------+------------+------------+--------+---------------+---------+---------+------+------+----------+-----------------+
4 rows in set, 1 warning (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
MySQL 会将其优化为:
SELECT *
FROM demo.goodsmaster a
WHERE EXISTS
(
SELECT b.id
FROM demo.goodsmaster b
WHERE b.goodsname = '书' AND a.itemnumber=b.itemnumber
UNION
SELECT c.id
FROM demo.goodsmaster c
WHERE c.goodsname = '笔' AND a.itemnumber=c.itemnumber
);
2
3
4
5
6
7
8
9
10
11
12
其中联合查询的子查询中 a.itemnumber=c.itemnumber 就用到了外部查询相关条件,所以 select_type 会变为 dependent union。
优化方案:用条件语句中的筛选字段 itemnumber 和 transdate 分别创建索引。
查询中使用 LIKE 关键字,只有右模糊查询才会使用索引(即LIKE ‘aa%’)
查询中使用 OR 关键字,只有 OR 前后的字段都添加索引,该查询才会使用索引
TODO:https://mp.weixin.qq.com/s/WyfRV-7sK_O8pxDZbPXQtQ
# 2. 索引优化
# 2.1 选择合适的列建立索引
- 在 where 从句,group by 从句,order by 从句,on 从句汇总出现的列
- 索引字段越小越好
- 离散度大的列放到联合索引的前面
# 2.2 避免重复及冗余索引
重复索引是指相同的列以相同的顺序建立的同类型的索引,如 primary key(id) 和 unique(id)
SQL 语句查找重复索引:
SELECT a.TABLE_SCHEMA, a.TABLE_NAME, a.COLUMN_NAME,
a.INDEX_NAME AS 'index1', b.INDEX_NAME AS 'index2'
FROM information_schema.STATISTICS a
JOIN information_schema.STATISTICS b
ON a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
AND a.COLUMN_NAME = b.COLUMN_NAME
WHERE a.SEQ_IN_INDEX = 1 AND a.INDEX_NAME <> b.INDEX_NAME
AND a.TABLE_SCHEMA = 'teedol';
2
3
4
5
6
7
8
9
10
使用 pt-duplicate-key-checker 查找重复索引:
pt-duplicate-key-checker -uroot -p123456 -h 127.0.0.1
查看索引使用情况:通过慢查询日志配合 pt-index-usage 工具来进行索引使用情况
pt-index-usage -uroot -p123456 mysql-slow.log
# 3. 数据结构优化
# 3.1 选择合适的数据类型
使用可以存下你的数据的最小的数据类型
使用简单的数据类型,int 要比 varchar 类型在 MySQL 中处理简单且占用空间小
如使用 int 存储日期时间:
CREATE TABLE test( id INT AUTO_INCREMENT NOT NULL, timestr INT, PRIMARY KEY(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; INSERT INTO test(timestr) VALUES (UNIX_TIMESTAMP('2022-01-01 12:12:12')); SELECT FROM_UNIXTIME(timestr) FROM test;1
2
3
4
5
6
7
8如使用 bigint 来存 IP 地址,利用 INET_ATON(),INET_NTOA() 两个函数来进行转换:
CREATE TABLE sessions( id INT AUTO_INCREMENT NOT NULL, ipaddress BIGINT, PRIMARY KEY(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; INSERT INTO sessions(ipaddress) VALUES (INET_ATON('192.168.0.1')); SELECT INET_NTOA(ipaddress) FROM sessions;1
2
3
4
5
6
7
8尽可能使用 not null 定义字段
尽量少使用 text 类型,费用不可时最好考虑分表
字段使用非空约束:节省存储空间;便于创建索引;
# 3.2 表的范式化与反范式化
范式化市值数据设计的规范,目前说到的范式化一般是指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖

存在传递函数依赖关系:(商品名称)-> (分类)-> (分类描述)也就是说存在非关键字段”分类描述“对关键字段”商品名称“的传递函数依赖。范式化后:
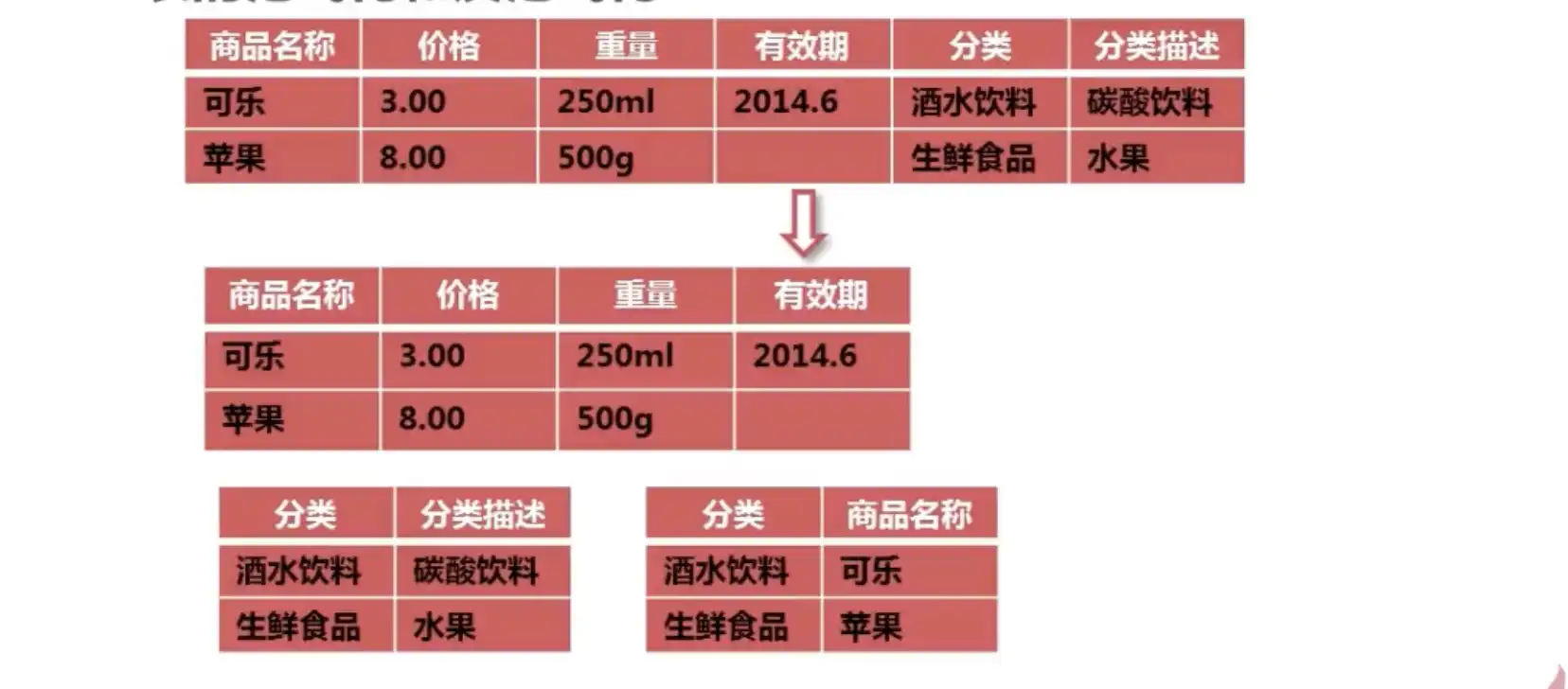
反范式化是指为了查询效率的考虑吧原本符合第三范式的表适当的增加冗余字段,已达到优化查询效率的目的(减少连接查询),反范式化时一种以空间来换取时间的操作,
需满足两个条件:(1)冗余字段不需要经常修改;(2)冗余字段在大部分查询中不可或缺;

添加冗余字段后:

# 3.3 表的垂直拆分
所谓垂直拆分,就是原来一个有很多列的表拆分成多个表,这样解决了表的宽度问题,通常垂直拆分可以按一下原则进行:
- 把不常用的字段单独存放到一个表中
- 把大字段独立存放到一个表中
- 把经常一起使用的字段放到一起
# 3.4 表的水平拆分
表的水平拆分时为了解决单表的数据量过大的问题,水平拆分的表每一个表的结构都是完成一致的。常用的水平拆分方法为:
- 对 id 进行 hash 运算,如果要拆分成 5 个表则使用 mod(customer_id, 5) 取出 0-4个值
- 针对不同的 hashID 把数据存到不同的表中
挑战:
- 跨 分区表进行数据查询
- 统计及后台报表操作
# 4. 系统配置优化
# 4.1 Linux 系统参数配置
网络方面的配置,要修改 /etc/sysctl.conf 文件:
## 增加 tcp 支持的队列数
net.ipv4.tcp_max_syn_backlog= 65535
## 减少断开连接时,资源回收
net.ipv4.tcp max tw buckets= 8000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
2
3
4
5
6
打开文件数的限制,可以使用 ulimit -a 查看目录的各位限制,可以修改 /etc/security/limits.conf 文件,增加以下内容以修改打开文件数量的限制
soft nofile 65535
hard nofile 65535
2
除此之外最好在 MySQL 服务器上关闭 ptables, selinux 等防火墙软件。
# 4.2 MySQL 参数配置
调整系统参数:innodb_buffer_pool_size
表示 InnoDB 存储引擎使用多少缓存来存储索引和数据。这个值越大,可以加载到缓存区的索引和数据量就越多,需要的磁盘读写就越少。
调整系统参数:innodb_buffer_pool_instances
innodb_buffer_pool_instances 表示将缓存池分成几个部分,可以提高 MySQL 的并行处理能力,默认只有一个。
调整系统查询:innodb_log_buffer_size
Innodb log 缓存的大小,由于日志最长每秒钟会刷星,所以一般不用太大
调整系统查询:innodb_flush_log_at_trx_commit
默认值为1表示每次事务提交都将数据写入日志,并把日志写入磁盘;若值为0表示每个1秒将数据写入日志,并把日志写入磁盘;若值为2表示每次提交事务将数据写入日志,而每个1秒将日志写入磁盘;
当系统在大并发场景下,可以将其值修改为2,减少日志写入磁盘的次数,降低CPU的使用率
调整读写线程数:innodb_read_io_threads 和 innodb_write_io_threads,默认都为4
表使用独立空间:innodb_file_per_table
控制 InnoDB 每一个表使用独立的表空间,默认为 OFF(也就是所有表都会建立在共享表空间)
调整表统计刷新:innodb_status_on_metadata
# 4.3 第三方配置工具
Percon Configuration Wizard:https://tools.percona.com/wizard
# 5. 参考
https://www.itmuch.com/mysql/explain/
https://dev.mysql.com/doc/refman/5.7/en/statement-optimization.html
https://dev.mysql.com/doc/refman/5.7/en/execution-plan-information.html
https://mp.weixin.qq.com/s/OpS_F5lG9CaFw4xqnofWLw
https://blog.csdn.net/poxiaonie/article/details/77757471
https://www.imooc.com/learn/194