 Java 并发 - 概述
Java 并发 - 概述
# Java 并发 - 概述

# 为什么要使用多线程
使用多线程,本质上就是提升程序性能。那么如何如何度量性能?
度量性能的指标有很多,但是有两个指标是最核心的,它们就是延迟和吞吐量。延迟指的是发出请求到收到响应这个过程的时间;延迟越短,意味着程序执行得越快,性能也就越好。 吞吐量指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好。这两个指标内部有一定的联系(同等条件下,延迟越短,吞吐量越大),但是由于它们隶属不同的维度(一个是时间维度,一个是空间维度),并不能互相转换。
我们所谓提升性能,从度量的角度,主要是降低延迟,提高吞吐量。这也是我们使用多线程的主要目的。那我们该怎么降低延迟,提高吞吐量呢?这个就要从多线程的应用场景说起了。
# 多线程的应用场景
要想“降低延迟,提高吞吐量”,对应的方法呢,基本上有两个方向,一个方向是优化算法,另一个方向是将硬件的性能发挥到极致。前者属于算法范畴,后者则是和并发编程息息相关了。那计算机主要有哪些硬件呢?主要是两类:一个是 I/O,一个是 CPU。简言之,在并发编程领域,提升性能本质上就是提升硬件的利用率,再具体点来说,就是提升 I/O 的利用率和 CPU 的利用率。
操作系统虽然已经解决了磁盘和网卡的利用率问题,利用中断机制还能避免 CPU 轮询 I/O 状态,也提升了 CPU 的利用率。但是操作系统解决硬件利用率问题的对象往往是单一的硬件设备,而我们的并发程序,往往需要 CPU 和 I/O 设备相互配合工作,也就是说,我们需要解决 CPU 和 I/O 设备综合利用率的问题。关于这个综合利用率的问题,操作系统虽然没有办法完美解决,但是却给我们提供了方案,那就是:多线程。
下面我们用一个简单的示例来说明:如何利用多线程来提升 CPU 和 I/O 设备的利用率?假设程序按照 CPU 计算和 I/O 操作交叉执行的方式运行,而且 CPU 计算和 I/O 操作的耗时是 1:1。
如下图所示,如果只有一个线程,执行 CPU 计算的时候,I/O 设备空闲;执行 I/O 操作的时候,CPU 空闲,所以 CPU 的利用率和 I/O 设备的利用率都是 50%。
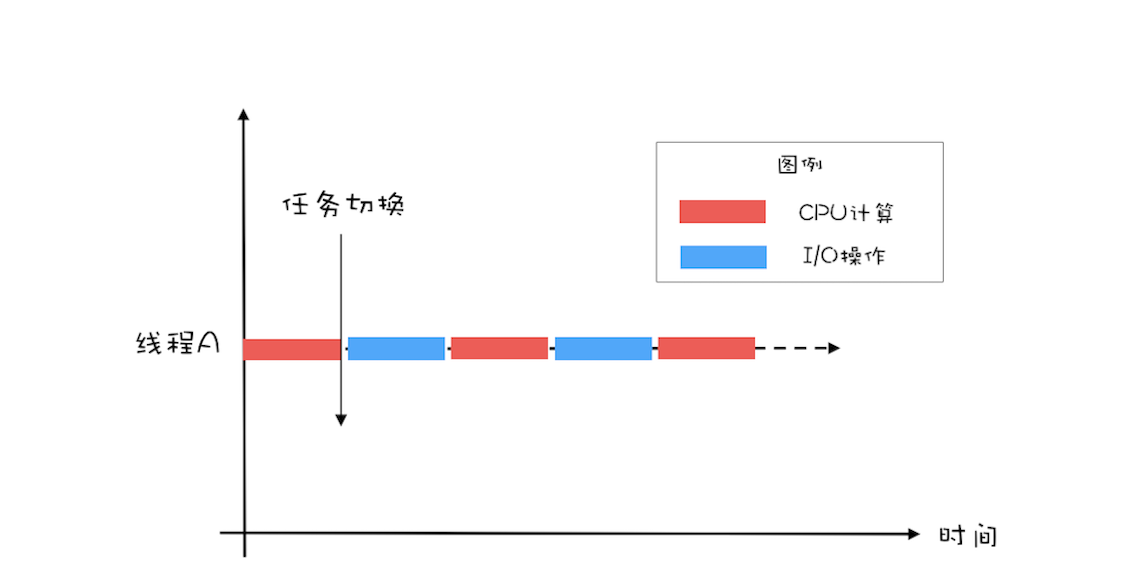
如果有两个线程,如下图所示,当线程 A 执行 CPU 计算的时候,线程 B 执行 I/O 操作;当线程 A 执行 I/O 操作的时候,线程 B 执行 CPU 计算,这样 CPU 的利用率和 I/O 设备的利用率就都达到了 100%。

我们将 CPU 的利用率和 I/O 设备的利用率都提升到了 100%,会对性能产生了哪些影响呢?通过上面的图示,很容易看出:单位时间处理的请求数量翻了一番,也就是说吞吐量提高了 1 倍。此时可以逆向思维一下,如果 CPU 和 I/O 设备的利用率都很低,那么可以尝试通过增加线程来提高吞吐量。
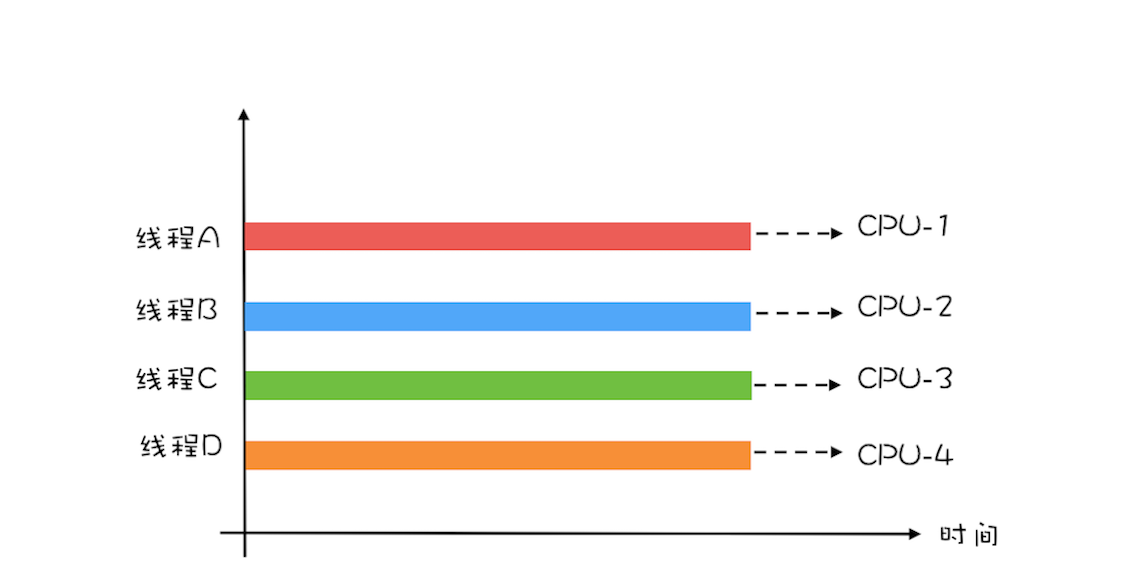
在单核时代,多线程主要就是用来平衡 CPU 和 I/O 设备的。如果程序只有 CPU 计算,而没有 I/O 操作的话,多线程不但不会提升性能,还会使性能变得更差,原因是增加了线程切换的成本。但是在多核时代,这种纯计算型的程序也可以利用多线程来提升性能。为什么呢?因为利用多核可以降低响应时间。
举个简单的例子说明一下:计算 1+2+… … +100 亿的值,如果在 4 核的 CPU 上利用 4 个线程执行,线程 A 计算[1,25 亿),线程 B 计算[25 亿,50 亿),线程 C 计算[50,75 亿),线程 D 计算[75 亿,100 亿],之后汇总,那么理论上应该比一个线程计算[1,100 亿]快将近 4 倍,响应时间能够降到 25%。一个线程,对于 4 核的 CPU,CPU 的利用率只有 25%,而 4 个线程,则能够将 CPU 的利用率提高到 100%。
# 创建多少线程合适(理论)
创建多少线程合适,要看多线程具体的应用场景。可分为 I/O 密集型程序和 CPU 密集型程序。CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序中 I/O 操作执行的时间相对于 CPU 计算来说都非常长。
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。

通过上面这个例子,我们会发现,对于 I/O 密集型计算场景,最佳的线程数是与程序中 CPU 计算和 I/O 操作的耗时比相关的,我们可以总结出这样一个公式:
最佳线程数 =1 +(I/O 耗时 / CPU 耗时)
不过上面这个公式是针对单核 CPU 的,至于多核 CPU,也很简单,只需要等比扩大就可以了,计算公式如下:
最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
对于 I/O 密集型计算场景,I/O 耗时和 CPU 耗时的比值是一个关键参数,不幸的是这个参数是未知的,而且是动态变化的,所以工程上,我们要估算这个参数,然后做各种不同场景下的压测来验证我们的估计。
详细可见:Java 进阶 - 线程池
# 并发编程需注意的问题
并发编程中我们需要注意的问题有很多,主要有三个方面,分别是:安全性问题、活跃性问题和性能问题。
# 安全性问题
相信你一定听说过类似这样的描述:这个方法不是线程安全的,这个类不是线程安全的等等。
那什么是线程安全呢?其实本质上就是正确性,而正确性的含义就是程序按照我们期望的执行,不要让我们感到意外。在 Java 并发 - 理论基础 中介绍几种诡异的 Bug,都是出乎我们预料的,它们都没有按照我们期望的执行。
那如何才能写出线程安全的程序呢? Java 并发 - 理论基础 中已经介绍了并发 Bug 的三个主要源头:原子性问题、可见性问题和有序性问题。也就是说,理论上线程安全的程序,就要避免出现原子性问题、可见性问题和有序性问题。
其实只有一种情况需要分析是否存在上面说的问题:存在共享数据并且该数据会发生变化,通俗地讲就是有多个线程会同时读写同一数据。那如果能够做到不共享数据或者数据状态不发生变化,不就能够保证线程的安全性了嘛。有不少技术方案都是基于这个理论的,例如线程本地存储(Thread Local Storage,TLS)、不变模式等等。
但现实生活中,必须共享会发生变化的数据,这样的应用场景还是很多的。当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发 Bug,对此还有一个专业的术语,叫做数据竞争(Data Race)。比如下面 add10K() 的方法,当多个线程调用时候就会发生数据竞争,如下所示:
public class Test {
private long count = 0;
void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
}
2
3
4
5
6
7
8
9
那是不是在访问数据的地方,我们加个锁保护一下就能解决所有的并发问题了呢?显然没有这么简单。例如,对于上面示例,我们稍作修改,增加两个被 synchronized 修饰的 get() 和 set() 方法, add10K() 方法里面通过 get() 和 set() 方法来访问 value 变量,修改后的代码如下所示。对于修改后的代码,所有访问共享变量 value 的地方,我们都增加了互斥锁,此时是不存在数据竞争的。但很显然修改后的 add10K() 方法并不是线程安全的。
public class Test {
private long count = 0;
synchronized long get(){
return count;
}
synchronized void set(long v){
count = v;
}
void add10K() {
int idx = 0;
while(idx++ < 10000) {
set(get()+1)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
假设 count=0,当两个线程同时执行 get() 方法时,get() 方法会返回相同的值 0,两个线程执行 get()+1 操作,结果都是 1,之后两个线程再将结果 1 写入了内存。你本来期望的是 2,而结果却是 1。
这种问题,有个官方的称呼,叫竞态条件(Race Condition)。所谓竞态条件,指的是程序的执行结果依赖线程执行的顺序。例如上面的例子,如果两个线程完全同时执行,那么结果是 1;如果两个线程是前后执行,那么结果就是 2。在并发环境里,线程的执行顺序是不确定的,如果程序存在竞态条件问题,那就意味着程序执行的结果是不确定的,而执行结果不确定这可是个大 Bug。
下面再结合一个例子来说明下竞态条件,就是前面文章中提到的转账操作。转账操作里面有个判断条件——转出金额不能大于账户余额,但在并发环境里面,如果不加控制,当多个线程同时对一个账号执行转出操作时,就有可能出现超额转出问题。假设账户 A 有余额 200,线程 1 和线程 2 都要从账户 A 转出 150,在下面的代码里,有可能线程 1 和线程 2 同时执行到第 6 行,这样线程 1 和线程 2 都会发现转出金额 150 小于账户余额 200,于是就会发生超额转出的情况。
class Account {
private int balance;
// 转账
void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
2
3
4
5
6
7
8
9
10
11
所以你也可以按照下面这样来理解竞态条件。在并发场景中,程序的执行依赖于某个状态变量,也就是类似于下面这样:
if (状态变量 满足 执行条件) {
执行操作
}
2
3
当某个线程发现状态变量满足执行条件后,开始执行操作;可是就在这个线程执行操作的时候,其他线程同时修改了状态变量,导致状态变量不满足执行条件了。当然很多场景下,这个条件不是显式的,例如前面 addOne 的例子中,set(get()+1) 这个复合操作,其实就隐式依赖 get()的结果。
那面对数据竞争和竞态条件问题,又该如何保证线程的安全性呢?其实这两类问题,都可以用互斥这个技术方案,而实现互斥的方案有很多,CPU 提供了相关的互斥指令,操作系统、编程语言也会提供相关的 API。从逻辑上来看,我们可以统一归为:锁。
# 活跃性问题
所谓活跃性问题,指的是某个操作无法执行下去。我们常见的“死锁”就是一种典型的活跃性问题,当然除了死锁外,还有两种情况,分别是“活锁”和“饥饿”。
死锁问题
发生“死锁”后线程会互相等待,而且会一直等待下去,在技术上的表现形式是线程永久地“阻塞”了。死锁详细介绍可见 Java 并发 - syschronized 应用及死锁问题
活锁问题
有时线程虽然没有发生阻塞,但仍然会存在执行不下去的情况,这就是所谓的“活锁”。可以类比现实世界里的例子,路人甲从左手边出门,路人乙从右手边进门,两人为了不相撞,互相谦让,路人甲让路走右手边,路人乙也让路走左手边,结果是两人又相撞了。这种情况,基本上谦让几次就解决了,因为人会交流啊。可是如果这种情况发生在编程世界了,就有可能会一直没完没了地“谦让”下去,成为没有发生阻塞但依然执行不下去的“活锁”。
解决“活锁”的方案很简单,谦让时,尝试等待一个随机的时间就可以了。例如上面的那个例子,路人甲和乙在发现前面有人时等待一个随机的时间再切换。由于路人甲和路人乙等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。“等待一个随机时间”的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
饥饿问题
那“饥饿”该怎么去理解呢?所谓“饥饿”指的是线程因无法访问所需资源而无法执行下去的情况。如果线程优先级“不均”,在 CPU 繁忙的情况下,优先级低的线程得到执行的机会很小,就可能发生线程“饥饿”;持有锁的线程,如果执行的时间过长,也可能导致“饥饿”问题。
解决“饥饿”问题的方案很简单,有三种方案:一是保证资源充足,二是公平地分配资源,三就是避免持有锁的线程长时间执行。这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。在并发编程里,主要是使用公平锁。所谓公平锁,是一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
# 性能性问题
使用“锁”要非常小心,但是如果小心过度,也可能出“性能问题”。“锁”的过度使用可能导致串行化的范围过大,这样就不能够发挥多线程的优势了,而我们之所以使用多线程搞并发程序,为的就是提升性能。
那怎么才能避免锁带来的性能问题呢?这个问题很复杂,Java SDK 并发包里之所以有那么多东西,有很大一部分原因就是要提升在某个特定领域的性能。
不过从方案层面,我们可以这样来解决这个问题:
- 既然使用锁会带来性能问题,那最好的方案自然就是使用无锁的算法和数据结构了。在这方面有很多相关的技术,例如线程本地存储 (Thread Local Storage, TLS)、写入时复制 (Copy-on-write)、乐观锁等;Java 并发包里面的原子类也是一种无锁的数据结构;Disruptor 则是一个无锁的内存队列,性能都非常好。
- 减少锁持有的时间。互斥锁本质上是将并行的程序串行化,所以要增加并行度,一定要减少持有锁的时间。这个方案具体的实现技术也有很多,例如使用细粒度的锁,一个典型的例子就是 Java 并发包里的 ConcurrentHashMap,它使用了所谓分段锁的技术(这个技术后面我们会详细介绍);还可以使用读写锁,也就是读是无锁的,只有写的时候才会互斥。
性能方面的度量指标有很多,有三个指标非常重要,就是:吞吐量、延迟和并发量。
- 吞吐量:指的是单位时间内能处理的请求数量。吞吐量越高,说明性能越好。
- 延迟:指的是从发出请求到收到响应的时间。延迟越小,说明性能越好。
- 并发量:指的是能同时处理的请求数量,一般来说随着并发量的增加、延迟也会增加。所以延迟这个指标,一般都会是基于并发量来说的。例如并发量是 1000 的时候,延迟是 50 毫秒。
# 其他
下面的宏观原则有助于写出“健壮”的并发程序。这些原则主要有以下三条。
- 优先使用成熟的工具类:Java SDK 并发包里提供了丰富的工具类,基本上能满足你日常的需要,建议你熟悉它们,用好它们,而不是自己再“发明轮子”,毕竟并发工具类不是随随便便就能发明成功的。
- 迫不得已时才使用低级的同步原语:低级的同步原语主要指的是 synchronized、Lock、Semaphore 等,这些虽然感觉简单,但实际上并没那么简单,一定要小心使用。
- 避免过早优化:安全第一,并发程序首先要保证安全,出现性能瓶颈后再优化。在设计期和开发期,很多人经常会情不自禁地预估性能的瓶颈,并对此实施优化,但残酷的现实却是:性能瓶颈不是你想预估就能预估的。