 MySQL - Q/A
MySQL - Q/A
# MySQL Q/A
- 数据库范式和反范式
- MySQL 有哪些数据类型,以及使用策略
- MySQL 有哪些存储引擎,如何选择?MyISAM 和 InnoDB 的区别?
- InnoDB 引擎的 4 大特性
- MySQL 索引有几种?索引的基本原理、数据结构、算法
- MySQL 索引的设计原则
- 百万级别或以上的数据如何删除
MySQL 的 binlog 有几种录入方式?分别有什么区别?
问题一:select count(*) from t; t中有id(主键),name,age,sex 4个字段。假设数据10条,对sex添加索引。用explain 查看执行计划发现用了sex索引,为什么不是主键索引呢?主键索引应该更快的
解答:
- MySQL Innodb的主键索引是一个B+树,数据存储在叶子节点上,10条数据,就有10个叶子节点。
- sex索引是辅助索引,也是一个B+树,不同之处在于,叶子节点存储的是主键值,由于sex只有2个可能的值:男和女,因此,这个B+树只有2个叶子节点,比主键索引的B+树小的多
- 这个表有主键,因此不存在所有字段都为空的记录,所以COUNT(*)只要统计所有主键的值就可以了,不需要回表读取数据
- SELECT COUNT(*) FROM t,使用sex索引,只需要访问辅助索引的小B+树,而使用主键索引,要访问主键索引的那个大B+树,明细工作量大,这就是为什么,优化器使用辅助索引的原因
问题二:假设某中学高三年级有多位同学,分成多个班,我们有统一记录学生成绩的表(demo.student) 和班级信息表(demo.class),具体信息如下所示:学生成绩表,要求:写一个 SQL 查询语句,查出每个班级前三名的同学
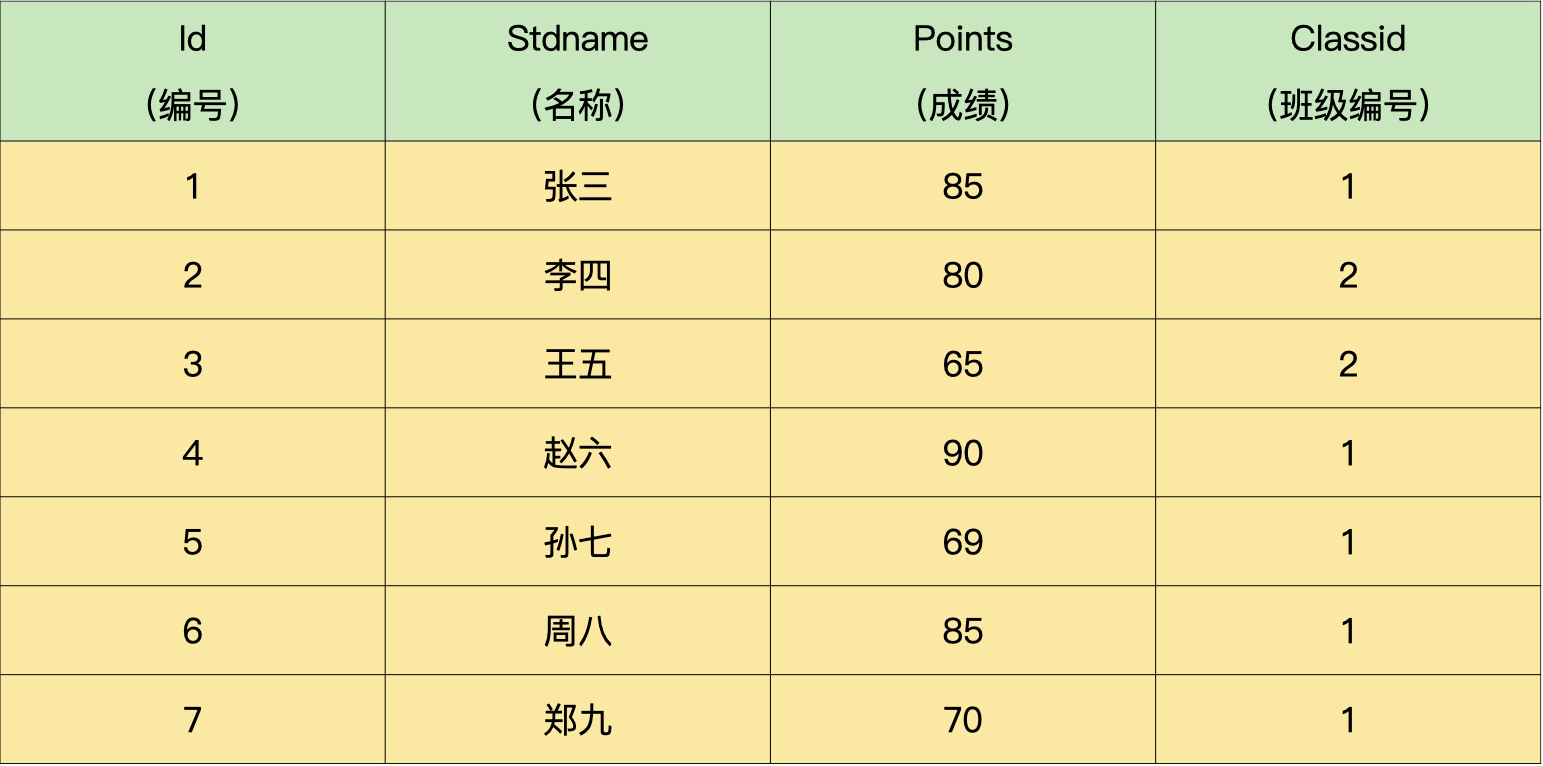
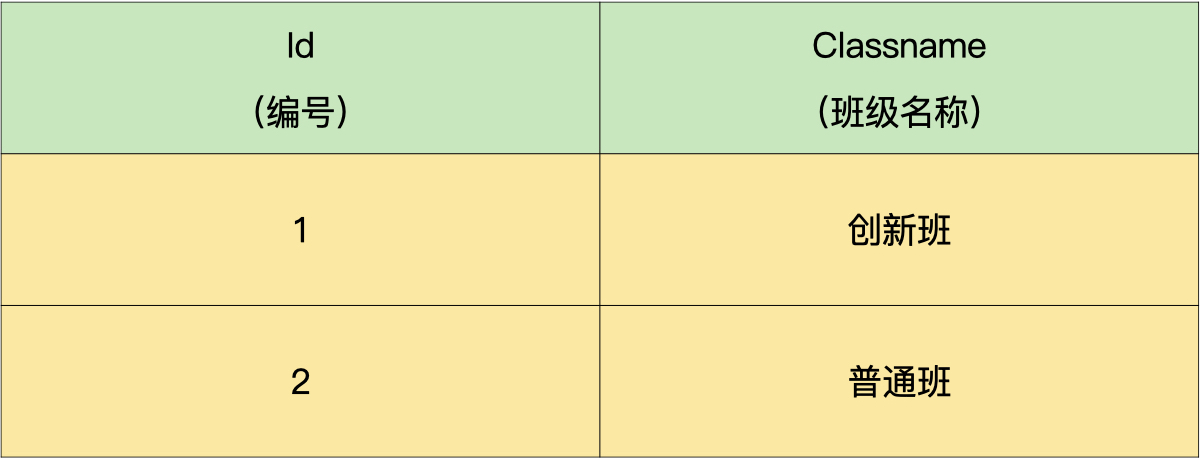
查询比某个成绩好的数量
SELECT COUNT(DISTNCT t.Points) as num FROM student as t WHERE 1 = 1 AND t.Points > x1
2
3
4查询每个班的前3名
SELECT b.stdname,b.points FROM student AS b WHERE 3 > ( SELECT COUNT(DISTINCT t.points) FROM student AS t WHERE 1 = 1 AND t.points > b.points AND t.classid = b.classid )1
2
3
4
5
6
7
8
9补全班级信息以及排序
SELECT c.classname,b.stdname,b.points FROM student AS b JOIN class AS c ON b.classid = c.id WHERE 3 > ( SELECT COUNT(DISTINCT t.points) FROM student AS t WHERE 1 = 1 AND t.points > b.points AND t.classid = b.classid ) ORDER BY c.id asc, b.points desc;1
2
3
4
5
6
7
8
9
10
11
问题三:MySQL 日志系统原则
MySQL 日志系统遵循WAL(Write-Ahead Logging)原则:
- 对数据的操作必须先写入日志文件,再实际更新数据库
- 日志是按照实际操作的顺序进行记录
- 事务提交后,必须在成功写入日志后,才能返回事务成功
事务事故需要用到回滚日志、二进制日志、重做日志。
问题四:MySQL 是否支持事务
InnoDB 存储引擎支持事务,而 MyISAM 则不支持。默认使用 InnoDB存储引擎,默认事务模式为Auto Commit,即每个SQL操作都为一个事务。
问题五:MySQL8 的新特性
窗口函数和公用表表达式
问题六:MySQL 空间数据
存储、函数等
问题七:WHERE 和 HAVING区别
- 如果需要通过连接从关联表中获取数据,WHERE是先筛选后连接,而HAVING是先连接后筛选,所以WHERE比HAVING效率更高
- WHERE 可以直接使用表中的字段作为筛选条件,不能使用分组中的计算函数,在GROUP BY 前。而HAVING必须要与GROUP BY配合使用,可以使用分组函数或分组字段作为筛选条件
- HAVING 通常用于数据分组统计时的复杂查询
上次更新: 2024-08-19